Assessing the Overhead of Offloading Compression Tasks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ROOT I/O Compression Improvements for HEP Analysis
EPJ Web of Conferences 245, 02017 (2020) https://doi.org/10.1051/epjconf/202024502017 CHEP 2019 ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, enhancing it by improving its performance and interaction with other data analysis ecosys- tems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased over the last couple of years. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly, because there are significant trade-offs between the increased CPU cost for reading and writing files and the reduces storage space. 1 Introduction In the past years, Large Hadron Collider (LHC) experiments are managing about an exabyte of storage for analysis purposes, approximately half of which is stored on tape storages for archival purposes, and half is used for traditional disk storage. Meanwhile for High Lumi- nosity Large Hadron Collider (HL-LHC) storage requirements per year are expected to be increased by a factor of 10 [1]. -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

Building and Installing Xen 4.X and Linux Kernel 3.X on Ubuntu and Debian Linux
Building and Installing Xen 4.x and Linux Kernel 3.x on Ubuntu and Debian Linux Version 2.3 Author: Teo En Ming (Zhang Enming) Website #1: http://www.teo-en-ming.com Website #2: http://www.zhang-enming.com Email #1: [email protected] Email #2: [email protected] Email #3: [email protected] Mobile Phone(s): +65-8369-2618 / +65-9117-5902 / +65-9465-2119 Country: Singapore Date: 10 August 2013 Saturday 4:56 A.M. Singapore Time 1 Installing Prerequisite Software sudo apt-get install ocaml-findlib sudo apt-get install bcc bin86 gawk bridge-utils iproute libcurl3 libcurl4-openssl-dev bzip2 module-init-tools transfig tgif texinfo texlive-latex-base texlive-latex-recommended texlive-fonts-extra texlive-fonts-recommended pciutils-dev mercurial build-essential make gcc libc6-dev zlib1g-dev python python-dev python-twisted libncurses5-dev patch libvncserver-dev libsdl-dev libjpeg62-dev iasl libbz2-dev e2fslibs-dev git-core uuid-dev ocaml libx11-dev bison flex sudo apt-get install gcc-multilib sudo apt-get install xz-utils libyajl-dev gettext sudo apt-get install git-core kernel-package fakeroot build-essential libncurses5-dev 2 Linux Kernel 3.x with Xen Virtualization Support (Dom0 and DomU) In this installation document, we will build/compile Xen 4.1.3-rc1-pre and Linux kernel 3.3.0-rc7 from sources. sudo apt-get install aria2 aria2c -x 5 http://www.kernel.org/pub/linux/kernel/v3.0/testing/linux-3.3-rc7.tar.bz2 tar xfvj linux-3.3-rc7.tar.bz2 cd linux-3.3-rc7 Page 1 of 25 (C) 2013 Teo En Ming (Zhang Enming) 3 Configuring the Linux kernel cp /boot/config-3.0.0-12-generic .config make oldconfig Accept the defaults for new kernel configuration options by pressing enter. -

Important Notice Regarding Software
Important Notice Regarding Software The software package installed in this product includes software licensed to Onkyo & Pioneer Corporation (hereinafter, called “O&P Corporation”) directly or indirectly by third party developers. Please be sure to read this notice regarding such software. Notice Regarding GNU GPL/LGPL-applicable Software This product includes the following software that is covered by GNU General Public License (hereinafter, called "GPL") or by GNU Lesser General Public License (hereinafter, called "LGPL"). O&P Corporation notifies you that, according to the attached GPL/LGPL, you have right to obtain, modify, and redistribute software source code for the listed software. ソフトウェアに関する重要なお知らせ 本製品に搭載されるソフトウェアには、オンキヨー & パイオニア株式会社(以下「弊社」とします)が 第三者より直接的に又は間接的に使用の許諾を受けたソフトウェアが含まれております。これらのソフト ウェアに関する本お知らせを必ずご一読くださいますようお願い申し上げます。 GNU GPL / LGPL 適用ソフトウェアに関するお知らせ 本製品には、以下の GNU General Public License(以下「GPL」とします)または GNU Lesser General Public License(以下「LGPL」とします)の適用を受けるソフトウェアが含まれております。 お客様は添付の GPL/LGPL に従いこれらのソフトウェアソースコードの入手、改変、再配布の権利があ ることをお知らせいたします。 Package List パッケージリスト alsa-conf-base glibc-gconv alsa-conf glibc-gconv-utf-16 alsa-lib glib-networking alsa-utils-alsactl gstreamer1.0-libav alsa-utils-alsamixer gstreamer1.0-plugins-bad-aiff alsa-utils-amixer gstreamer1.0-plugins-bad-bluez alsa-utils-aplay gstreamer1.0-plugins-bad-faac avahi-autoipd gstreamer1.0-plugins-bad-mms base-files gstreamer1.0-plugins-bad-mpegtsdemux base-passwd gstreamer1.0-plugins-bad-mpg123 bluez5 gstreamer1.0-plugins-bad-opus busybox gstreamer1.0-plugins-bad-rawparse -

UG1144 (V2020.1) July 24, 2020 Revision History
See all versions of this document PetaLinux Tools Documentation Reference Guide UG1144 (v2020.1) July 24, 2020 Revision History Revision History The following table shows the revision history for this document. Section Revision Summary 07/24/2020 Version 2020.1 Appendix H: Partitioning and Formatting an SD Card Added a new appendix. 06/03/2020 Version 2020.1 Chapter 2: Setting Up Your Environment Added the Installing a Preferred eSDK as part of the PetaLinux Tool section. Chapter 4: Configuring and Building Added the PetaLinux Commands with Equivalent devtool Commands section. Chapter 6: Upgrading the Workspace Added new sections: petalinux-upgrade Options, Upgrading Between Minor Releases (2020.1 Tool with 2020.2 Tool) , Upgrading the Installed Tool with More Platforms, and Upgrading the Installed Tool with your Customized Platform. Chapter 7: Customizing the Project Added new sections: Creating Partitioned Images Using Wic and Configuring SD Card ext File System Boot. Chapter 8: Customizing the Root File System Added the Appending Root File System Packages section. Chapter 10: Advanced Configurations Updated PetaLinux Menuconfig System. Chapter 11: Yocto Features Added the Adding Extra Users to the PetaLinux System section. Appendix A: Migration Added Tool/Project Directory Structure. UG1144 (v2020.1) July 24, 2020Send Feedback www.xilinx.com PetaLinux Tools Documentation Reference Guide 2 Table of Contents Revision History...............................................................................................................2 -

OSS Disclosure Document OSS Licenses Used in RN AIVI 1
OSS Disclosure Document Date: 08-10-2017 OSS Licenses used in RN_AIVI CM-CI1/PJ-CB Page 1 Project 1 Overview .................................................. 12 2 OSS Licenses used in the project .......................... 13 3 Package details for OSS Licenses usage .................... 14 AES - Advanced Encryption Standard – 1.0 ..................... 14 Alsa Libraries - 1.0.29 ...................................... 14 Alsa Plugins - 1.0.29 ........................................ 14 Alsa Utils - 1.0.29 .......................................... 14 APMD - 3.2.2 ................................................. 15 ATK - 2.8.0 .................................................. 15 Attr - 2.4.47 ................................................ 15 Audio File Library - 0.2.7 ................................... 15 Avahi - 0.6.31 ............................................... 15 Bash - 3.2.48 .............................................. 15 BidiReferenceCpp - 26 ...................................... 15 Bison - 2.5.2., 3.0.2, 3.0.4 ............................... 16 Blktrace - 1.0.5 ........................................... 16 BlueZ - 4.101, 5.33 ........................................ 16 BPSTL ...................................................... 16 Btrfs-progs – 4.1.2 ........................................ 16 Busybox - 1.23.2 ........................................... 16 Bzip2 - 1.0.6 .............................................. 16 Cairo Vector Graphics Library - 1.12.14, 1.12.16, 1.14.2 ... 17 Cairo-Pixman - 0.30.2,0.32.6 .............................. -

Improving Compression-Ratio in Backup
Institutionen för systemteknik Department of Electrical Engineering Examensarbete Improving compression ratio in backup Examensarbete utfört i Informationskodning/Bildkodning av Mattias Zeidlitz Författare Mattias Zeidlitz LITH-ISY-EX--12/4588--SE Linköping 2012 TEKNISKA HÖGSKOLAN LINKÖPINGS UNIVERSITET Department of Electrical Engineering Linköpings tekniska högskola Linköping University Institutionen för systemteknik S-581 83 Linköping, Sweden 581 83 Linköping Improving compression-ratio in backup ............................................................................ Examensarbete utfört i Informationskodning/Bildkodning vid Linköpings tekniska högskola av Mattias Zeidlitz ............................................................. LITH-ISY-EX--12/4588--SE Presentationsdatum Institution och avdelning 2012-06-13 Institutionen för systemteknik Publiceringsdatum (elektronisk version) Department of Electrical Engineering Datum då du ämnar publicera exjobbet Språk Typ av publikation ISBN (licentiatavhandling) Svenska Licentiatavhandling ISRN LITH-ISY-EX--12/4588--SE x Annat (ange nedan) x Examensarbete Serietitel (licentiatavhandling) C-uppsats D-uppsats Engelska Rapport Serienummer/ISSN (licentiatavhandling) Antal sidor Annat (ange nedan) 58 URL för elektronisk version http://www.ep.liu.se Publikationens titel Improving compression ratio in backup Författare Mattias Zeidlitz Sammanfattning Denna rapport beskriver ett examensarbete genomfört på Degoo Backup AB i Stockholm under våren 2012. Syftet var att designa en kompressionssvit -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -
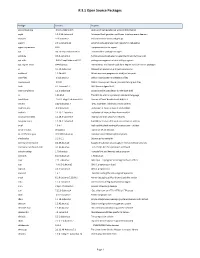
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -

Debian and Ubuntu
Debian and Ubuntu Lucas Nussbaum lucas@{debian.org,ubuntu.com} lucas@{debian.org,ubuntu.com} Debian and Ubuntu 1 / 28 Why I am qualified to give this talk Debian Developer and Ubuntu Developer since 2006 Involved in improving collaboration between both projects Developed/Initiated : Multidistrotools, ubuntu usertag on the BTS, improvements to the merge process, Ubuntu box on the PTS, Ubuntu column on DDPO, . Attended Debconf and UDS Friends in both communities lucas@{debian.org,ubuntu.com} Debian and Ubuntu 2 / 28 What’s in this talk ? Ubuntu development process, and how it relates to Debian Discussion of the current state of affairs "OK, what should we do now ?" lucas@{debian.org,ubuntu.com} Debian and Ubuntu 3 / 28 The Ubuntu Development Process lucas@{debian.org,ubuntu.com} Debian and Ubuntu 4 / 28 Linux distributions 101 Take software developed by upstream projects Linux, X.org, GNOME, KDE, . Put it all nicely together Standardization / Integration Quality Assurance Support Get all the fame Ubuntu has one special upstream : Debian lucas@{debian.org,ubuntu.com} Debian and Ubuntu 5 / 28 Ubuntu’s upstreams Not that simple : changes required, sometimes Toolchain changes Bugfixes Integration (Launchpad) Newer releases Often not possible to do work in Debian first lucas@{debian.org,ubuntu.com} Debian and Ubuntu 6 / 28 Ubuntu Packages Workflow lucas@{debian.org,ubuntu.com} Debian and Ubuntu 7 / 28 Ubuntu Packages Workflow Ubuntu Karmic Excluding specific packages language-(support|pack)-*, kde-l10n-*, *ubuntu*, *launchpad* Missing 4% : Newer upstream -

Porovnání Komprimaˇcních Program ˚U Na Textových Korpusech
MASARYKOVA UNIVERZITA FAKULTA}w¡¢£¤¥¦§¨ INFORMATIKY !"#$%&'()+,-./012345<yA| Porovnání komprimaˇcních program ˚una textových korpusech BAKALÁRSKÁˇ PRÁCE Jakub Foltas Brno, 2014 Prohlášení Prohlašuji, že tato bakaláˇrskápráce je mým p ˚uvodnímautorským dílem, které jsem vypracoval samostatnˇe.Všechny zdroje, prameny a literaturu, které jsem pˇrivypracování používal nebo z nich ˇcerpal, v práci ˇrádnˇecituji s uvedením úplného odkazu na pˇríslušnýzdroj. Jakub Foltas Vedoucí práce: RNDr. Miloš Jakubíˇcek ii Podˇekování Chtˇelbych podˇekovatvedoucímu mé bakaláˇrské práce RNDr. Mi- loši Jakubíˇckoviza odborné vedení, cenné rady a trpˇelivost,kterou se mnou mˇel.Také bych rád podˇekovalsvé rodinˇea pˇrátel˚umza podporu, kterou mi v dobˇepsaní bakaláˇrsképráce poskytovali. iii Shrnutí Bakaláˇrskápráce se zabývá porovnáním volnˇedostupných bezeztrá- tových komprimaˇcníchprogram ˚una textových korpusech. Hlavním cílem výzkumu bylo najít vhodný komprimaˇcníprogram, který by nahradil souˇcasnˇepoužívaný program XZ v Laboratoˇripro zpraco- vání pˇrirozeného jazyka pˇriMasarykovˇeuniverzitˇe. Testování na dvou odlišných textových korpusech se podrobilo celkem dvacet volnˇedostupných komprimaˇcníchprogram ˚u.Primár- ním kritériem porovnání byla urˇcenavelikost komprimace. Dále byla porovnávána doba bˇehuprogramu a programové vytížení pamˇeti. Dalším pˇredmˇetemzkoumání byly úˇcinkypˇredzpracováníkorpus ˚u pˇredsamotnou komprimací testovanými programy. Tˇriprogramy dokázaly korektnˇezkomprimovat oba zadané kor- pusy a významnˇepˇredˇcilysouˇcasnˇepoužívaný -

Build-Ship-Run Approach for a CORD-In-A-Box Deployment
Downloaded from orbit.dtu.dk on: Oct 02, 2021 Build-Ship-Run approach for a CORD-in-a-Box deployment Canellas, Ferran; Bonjorn, Nestor; Kentis, Angelos Mimidis; Soler, José Published in: Proceedings of 9th International Conference on Cloud Computing and Services Science Link to article, DOI: 10.5220/0007685402870291 Publication date: 2019 Document Version Peer reviewed version Link back to DTU Orbit Citation (APA): Canellas, F., Bonjorn, N., Kentis, A. M., & Soler, J. (2019). Build-Ship-Run approach for a CORD-in-a-Box deployment. In Proceedings of 9th International Conference on Cloud Computing and Services Science (pp. 287-291). IEEE. https://doi.org/10.5220/0007685402870291 General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. Users may download and print one copy of any publication from the public portal for the purpose of private study or research. You may not further distribute the material or use it for any profit-making activity or commercial gain You may freely distribute the URL identifying the publication in the public portal If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. Build-Ship-Run approach for a CORD-in-a-Box deployment Ferran Canellas1, Nestor Bonjorn1, Angelos Mimidis and Jose Soler1 1Denmarks Technical University, Building 343, Ørsteds Pl., Lyngby, Denmark [email protected] Keywords: CORD, CiaB, Cloudification Abstract: 5G is expected to provide high bandwidth and low latency communications, thus allowing Telco operators to provide new services to their end customers.