Accelerating Data Science Productivity with Gpus: from Workstation to Cluster
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mastering Machine Learning with Scikit-Learn
www.it-ebooks.info Mastering Machine Learning with scikit-learn Apply effective learning algorithms to real-world problems using scikit-learn Gavin Hackeling BIRMINGHAM - MUMBAI www.it-ebooks.info Mastering Machine Learning with scikit-learn Copyright © 2014 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: October 2014 Production reference: 1221014 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-836-5 www.packtpub.com Cover image by Amy-Lee Winfield [email protected]( ) www.it-ebooks.info Credits Author Project Coordinator Gavin Hackeling Danuta Jones Reviewers Proofreaders Fahad Arshad Simran Bhogal Sarah -

Python on Gpus (Work in Progress!)
Python on GPUs (work in progress!) Laurie Stephey GPUs for Science Day, July 3, 2019 Rollin Thomas, NERSC Lawrence Berkeley National Laboratory Python is friendly and popular Screenshots from: https://www.tiobe.com/tiobe-index/ So you want to run Python on a GPU? You have some Python code you like. Can you just run it on a GPU? import numpy as np from scipy import special import gpu ? Unfortunately no. What are your options? Right now, there is no “right” answer ● CuPy ● Numba ● pyCUDA (https://mathema.tician.de/software/pycuda/) ● pyOpenCL (https://mathema.tician.de/software/pyopencl/) ● Rewrite kernels in C, Fortran, CUDA... DESI: Our case study Now Perlmutter 2020 Goal: High quality output spectra Spectral Extraction CuPy (https://cupy.chainer.org/) ● Developed by Chainer, supported in RAPIDS ● Meant to be a drop-in replacement for NumPy ● Some, but not all, NumPy coverage import numpy as np import cupy as cp cpu_ans = np.abs(data) #same thing on gpu gpu_data = cp.asarray(data) gpu_temp = cp.abs(gpu_data) gpu_ans = cp.asnumpy(gpu_temp) Screenshot from: https://docs-cupy.chainer.org/en/stable/reference/comparison.html eigh in CuPy ● Important function for DESI ● Compared CuPy eigh on Cori Volta GPU to Cori Haswell and Cori KNL ● Tried “divide-and-conquer” approach on both CPU and GPU (1, 2, 5, 10 divisions) ● Volta wins only at very large matrix sizes ● Major pro: eigh really easy to use in CuPy! legval in CuPy ● Easy to convert from NumPy arrays to CuPy arrays ● This function is ~150x slower than the cpu version! ● This implies there -

Introduction Shrinkage Factor Reference
Comparison study for implementation efficiency of CUDA GPU parallel computation with the fast iterative shrinkage-thresholding algorithm Younsang Cho, Donghyeon Yu Department of Statistics, Inha university 4. TensorFlow functions in Python (TF-F) Introduction There are some functions executed on GPU in TensorFlow. So, we implemented our algorithm • Parallel computation using graphics processing units (GPUs) gets much attention and is just using that functions. efficient for single-instruction multiple-data (SIMD) processing. 5. Neural network with TensorFlow in Python (TF-NN) • Theoretical computation capacity of the GPU device has been growing fast and is much higher Neural network model is flexible, and the LASSO problem can be represented as a simple than that of the CPU nowadays (Figure 1). neural network with an ℓ1-regularized loss function • There are several platforms for conducting parallel computation on GPUs using compute 6. Using dynamic link library in Python (P-DLL) unified device architecture (CUDA) developed by NVIDIA. (Python, PyCUDA, Tensorflow, etc. ) As mentioned before, we can load DLL files, which are written in CUDA C, using "ctypes.CDLL" • However, it is unclear what platform is the most efficient for CUDA. that is a built-in function in Python. 7. Using dynamic link library in R (R-DLL) We can also load DLL files, which are written in CUDA C, using "dyn.load" in R. FISTA (Fast Iterative Shrinkage-Thresholding Algorithm) We consider FISTA (Beck and Teboulle, 2009) with backtracking as the following: " Step 0. Take �! > 0, some � > 1, and �! ∈ ℝ . Set �# = �!, �# = 1. %! Step k. � ≥ 1 Find the smallest nonnegative integers �$ such that with �g = � �$&# � �(' �$ ≤ �(' �(' �$ , �$ . -

Installing Python Ø Basics of Programming • Data Types • Functions • List Ø Numpy Library Ø Pandas Library What Is Python?
Python in Data Science Programming Ha Khanh Nguyen Agenda Ø What is Python? Ø The Python Ecosystem • Installing Python Ø Basics of Programming • Data Types • Functions • List Ø NumPy Library Ø Pandas Library What is Python? • “Python is an interpreted high-level general-purpose programming language.” – Wikipedia • It supports multiple programming paradigms, including: • Structured/procedural • Object-oriented • Functional The Python Ecosystem Source: Fabien Maussion’s “Getting started with Python” Workshop Installing Python • Install Python through Anaconda/Miniconda. • This allows you to create and work in Python environments. • You can create multiple environments as needed. • Highly recommended: install Python through Miniconda. • Are we ready to “play” with Python yet? • Almost! • Most data scientists use Python through Jupyter Notebook, a web application that allows you to create a virtual notebook containing both text and code! • Python Installation tutorial: [Mac OS X] [Windows] For today’s seminar • Due to the time limitation, we will be using Google Colab instead. • Google Colab is a free Jupyter notebook environment that runs entirely in the cloud, so you can run Python code, write report in Jupyter Notebook even without installing the Python ecosystem. • It is NOT a complete alternative to installing Python on your local computer. • But it is a quick and easy way to get started/try out Python. • You will need to log in using your university account (possible for some schools) or your personal Google account. Basics of Programming Indentations – Not Braces • Other languages (R, C++, Java, etc.) use braces to structure code. # R code (not Python) a = 10 if (a < 5) { result = TRUE b = 0 } else { result = FALSE b = 100 } a = 10 if (a < 5) { result = TRUE; b = 0} else {result = FALSE; b = 100} Basics of Programming Indentations – Not Braces • Python uses whitespaces (tabs or spaces) to structure code instead. -

Prototyping and Developing GPU-Accelerated Solutions with Python and CUDA Luciano Martins and Robert Sohigian, 2018-11-22 Introduction to Python
Prototyping and Developing GPU-Accelerated Solutions with Python and CUDA Luciano Martins and Robert Sohigian, 2018-11-22 Introduction to Python GPU-Accelerated Computing NVIDIA® CUDA® technology Why Use Python with GPUs? Agenda Methods: PyCUDA, Numba, CuPy, and scikit-cuda Summary Q&A 2 Introduction to Python Released by Guido van Rossum in 1991 The Zen of Python: Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Interpreted language (CPython, Jython, ...) Dynamically typed; based on objects 3 Introduction to Python Small core structure: ~30 keywords ~ 80 built-in functions Indentation is a pretty serious thing Dynamically typed; based on objects Binds to many different languages Supports GPU acceleration via modules 4 Introduction to Python 5 Introduction to Python 6 Introduction to Python 7 GPU-Accelerated Computing “[T]the use of a graphics processing unit (GPU) together with a CPU to accelerate deep learning, analytics, and engineering applications” (NVIDIA) Most common GPU-accelerated operations: Large vector/matrix operations (Basic Linear Algebra Subprograms - BLAS) Speech recognition Computer vision 8 GPU-Accelerated Computing Important concepts for GPU-accelerated computing: Host ― the machine running the workload (CPU) Device ― the GPUs inside of a host Kernel ― the code part that runs on the GPU SIMT ― Single Instruction Multiple Threads 9 GPU-Accelerated Computing 10 GPU-Accelerated Computing 11 CUDA Parallel computing -

Tangent: Automatic Differentiation Using Source-Code Transformation for Dynamically Typed Array Programming
Tangent: Automatic differentiation using source-code transformation for dynamically typed array programming Bart van Merriënboer Dan Moldovan Alexander B Wiltschko MILA, Google Brain Google Brain Google Brain [email protected] [email protected] [email protected] Abstract The need to efficiently calculate first- and higher-order derivatives of increasingly complex models expressed in Python has stressed or exceeded the capabilities of available tools. In this work, we explore techniques from the field of automatic differentiation (AD) that can give researchers expressive power, performance and strong usability. These include source-code transformation (SCT), flexible gradient surgery, efficient in-place array operations, and higher-order derivatives. We implement and demonstrate these ideas in the Tangent software library for Python, the first AD framework for a dynamic language that uses SCT. 1 Introduction Many applications in machine learning rely on gradient-based optimization, or at least the efficient calculation of derivatives of models expressed as computer programs. Researchers have a wide variety of tools from which they can choose, particularly if they are using the Python language [21, 16, 24, 2, 1]. These tools can generally be characterized as trading off research or production use cases, and can be divided along these lines by whether they implement automatic differentiation using operator overloading (OO) or SCT. SCT affords more opportunities for whole-program optimization, while OO makes it easier to support convenient syntax in Python, like data-dependent control flow, or advanced features such as custom partial derivatives. We show here that it is possible to offer the programming flexibility usually thought to be exclusive to OO-based tools in an SCT framework. -
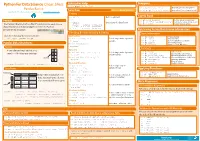
Cheat Sheet Pandas Python.Indd
Python For Data Science Cheat Sheet Asking For Help Dropping >>> help(pd.Series.loc) Pandas Basics >>> s.drop(['a', 'c']) Drop values from rows (axis=0) Selection Also see NumPy Arrays >>> df.drop('Country', axis=1) Drop values from columns(axis=1) Learn Python for Data Science Interactively at www.DataCamp.com Getting Sort & Rank >>> s['b'] Get one element -5 Pandas >>> df.sort_index() Sort by labels along an axis Get subset of a DataFrame >>> df.sort_values(by='Country') Sort by the values along an axis The Pandas library is built on NumPy and provides easy-to-use >>> df[1:] Assign ranks to entries Country Capital Population >>> df.rank() data structures and data analysis tools for the Python 1 India New Delhi 1303171035 programming language. 2 Brazil Brasília 207847528 Retrieving Series/DataFrame Information Selecting, Boolean Indexing & Setting Basic Information Use the following import convention: By Position (rows,columns) Select single value by row & >>> df.shape >>> import pandas as pd >>> df.iloc[[0],[0]] >>> df.index Describe index Describe DataFrame columns 'Belgium' column >>> df.columns Pandas Data Structures >>> df.info() Info on DataFrame >>> df.iat([0],[0]) Number of non-NA values >>> df.count() Series 'Belgium' Summary A one-dimensional labeled array a 3 By Label Select single value by row & >>> df.sum() Sum of values capable of holding any data type b -5 >>> df.loc[[0], ['Country']] Cummulative sum of values 'Belgium' column labels >>> df.cumsum() >>> df.min()/df.max() Minimum/maximum values c 7 Minimum/Maximum index -

Python Guide Documentation 0.0.1
Python Guide Documentation 0.0.1 Kenneth Reitz 2015 11 07 Contents 1 3 1.1......................................................3 1.2 Python..................................................5 1.3 Mac OS XPython.............................................5 1.4 WindowsPython.............................................6 1.5 LinuxPython...............................................8 2 9 2.1......................................................9 2.2...................................................... 15 2.3...................................................... 24 2.4...................................................... 25 2.5...................................................... 27 2.6 Logging.................................................. 31 2.7...................................................... 34 2.8...................................................... 37 3 / 39 3.1...................................................... 39 3.2 Web................................................... 40 3.3 HTML.................................................. 47 3.4...................................................... 48 3.5 GUI.................................................... 49 3.6...................................................... 51 3.7...................................................... 52 3.8...................................................... 53 3.9...................................................... 58 3.10...................................................... 59 3.11...................................................... 62 -

Hyperlearn Documentation Release 1
HyperLearn Documentation Release 1 Daniel Han-Chen Jun 19, 2020 Contents 1 Example code 3 1.1 hyperlearn................................................3 1.1.1 hyperlearn package.......................................3 1.1.1.1 Submodules......................................3 1.1.1.2 hyperlearn.base module................................3 1.1.1.3 hyperlearn.linalg module...............................7 1.1.1.4 hyperlearn.utils module................................ 10 1.1.1.5 hyperlearn.random module.............................. 11 1.1.1.6 hyperlearn.exceptions module............................. 11 1.1.1.7 hyperlearn.multiprocessing module.......................... 11 1.1.1.8 hyperlearn.numba module............................... 11 1.1.1.9 hyperlearn.solvers module............................... 12 1.1.1.10 hyperlearn.stats module................................ 14 1.1.1.11 hyperlearn.big_data.base module........................... 15 1.1.1.12 hyperlearn.big_data.incremental module....................... 15 1.1.1.13 hyperlearn.big_data.lsmr module........................... 15 1.1.1.14 hyperlearn.big_data.randomized module....................... 16 1.1.1.15 hyperlearn.big_data.truncated module........................ 17 1.1.1.16 hyperlearn.decomposition.base module........................ 18 1.1.1.17 hyperlearn.decomposition.NMF module....................... 18 1.1.1.18 hyperlearn.decomposition.PCA module........................ 18 1.1.1.19 hyperlearn.decomposition.PCA module........................ 18 1.1.1.20 hyperlearn.discriminant_analysis.base -

Pandas: Powerful Python Data Analysis Toolkit Release 0.25.3
pandas: powerful Python data analysis toolkit Release 0.25.3 Wes McKinney& PyData Development Team Nov 02, 2019 CONTENTS i ii pandas: powerful Python data analysis toolkit, Release 0.25.3 Date: Nov 02, 2019 Version: 0.25.3 Download documentation: PDF Version | Zipped HTML Useful links: Binary Installers | Source Repository | Issues & Ideas | Q&A Support | Mailing List pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. See the overview for more detail about whats in the library. CONTENTS 1 pandas: powerful Python data analysis toolkit, Release 0.25.3 2 CONTENTS CHAPTER ONE WHATS NEW IN 0.25.2 (OCTOBER 15, 2019) These are the changes in pandas 0.25.2. See release for a full changelog including other versions of pandas. Note: Pandas 0.25.2 adds compatibility for Python 3.8 (GH28147). 1.1 Bug fixes 1.1.1 Indexing • Fix regression in DataFrame.reindex() not following the limit argument (GH28631). • Fix regression in RangeIndex.get_indexer() for decreasing RangeIndex where target values may be improperly identified as missing/present (GH28678) 1.1.2 I/O • Fix regression in notebook display where <th> tags were missing for DataFrame.index values (GH28204). • Regression in to_csv() where writing a Series or DataFrame indexed by an IntervalIndex would incorrectly raise a TypeError (GH28210) • Fix to_csv() with ExtensionArray with list-like values (GH28840). 1.1.3 Groupby/resample/rolling • Bug incorrectly raising an IndexError when passing a list of quantiles to pandas.core.groupby. DataFrameGroupBy.quantile() (GH28113). -

Zmcintegral: a Package for Multi-Dimensional Monte Carlo Integration on Multi-Gpus
ZMCintegral: a Package for Multi-Dimensional Monte Carlo Integration on Multi-GPUs Hong-Zhong Wua,∗, Jun-Jie Zhanga,∗, Long-Gang Pangb,c, Qun Wanga aDepartment of Modern Physics, University of Science and Technology of China bPhysics Department, University of California, Berkeley, CA 94720, USA and cNuclear Science Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA Abstract We have developed a Python package ZMCintegral for multi-dimensional Monte Carlo integration on multiple Graphics Processing Units(GPUs). The package employs a stratified sampling and heuristic tree search algorithm. We have built three versions of this package: one with Tensorflow and other two with Numba, and both support general user defined functions with a user- friendly interface. We have demonstrated that Tensorflow and Numba help inexperienced scientific researchers to parallelize their programs on multiple GPUs with little work. The precision and speed of our package is compared with that of VEGAS for two typical integrands, a 6-dimensional oscillating function and a 9-dimensional Gaussian function. The results show that the speed of ZMCintegral is comparable to that of the VEGAS with a given precision. For heavy calculations, the algorithm can be scaled on distributed clusters of GPUs. Keywords: Monte Carlo integration; Stratified sampling; Heuristic tree search; Tensorflow; Numba; Ray. PROGRAM SUMMARY Manuscript Title: ZMCintegral: a Package for Multi-Dimensional Monte Carlo Integration on Multi-GPUs arXiv:1902.07916v2 [physics.comp-ph] 2 Oct 2019 Authors: Hong-Zhong Wu; Jun-Jie Zhang; Long-Gang Pang; Qun Wang Program Title: ZMCintegral Journal Reference: ∗Both authors contributed equally to this manuscript. Preprint submitted to Computer Physics Communications October 3, 2019 Catalogue identifier: Licensing provisions: Apache License Version, 2.0(Apache-2.0) Programming language: Python Operating system: Linux Keywords: Monte Carlo integration; Stratified sampling; Heuristic tree search; Tensorflow; Numba; Ray. -

Image Processing with Scikit-Image Emmanuelle Gouillart
Image processing with scikit-image Emmanuelle Gouillart Surface, Glass and Interfaces, CNRS/Saint-Gobain Paris-Saclay Center for Data Science Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features scikit-image http://scikit-image.org/ A module of the Scientific Python stack Language: Python Core modules: NumPy, SciPy, matplotlib Application modules: scikit-learn, scikit-image, pandas, ... A general-purpose image processing library open-source (BSD) not an application (ImageJ) less specialized than other libraries (e.g. OpenCV for computer vision) 1 Principle Principle Some features 1 First steps from skimage import data , io , filter image = data .