The Darkweb: a Social Network Anomaly
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations
UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations Title A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Permalink https://escholarship.org/uc/item/6w76f8x7 Author Swift, Kathy Publication Date 2017 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA Santa Barbara A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Education by Kathleen Anne Swift Committee in charge: Professor Richard Duran, Chair Professor Diana Arya Professor William Robinson September 2017 The dissertation of Kathleen Anne Swift is approved. ................................................................................................................................ Diana Arya ................................................................................................................................ William Robinson ................................................................................................................................ Richard Duran, Committee Chair June 2017 A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Copyright © 2017 by Kathleen Anne Swift iii ACKNOWLEDGEMENTS I would like to thank the members of my committee for their advice and patience as I worked on gathering and analyzing the copious amounts of research necessary to -

The Internet and Drug Markets
INSIGHTS EN ISSN THE INTERNET AND DRUG MARKETS 2314-9264 The internet and drug markets 21 The internet and drug markets EMCDDA project group Jane Mounteney, Alessandra Bo and Alberto Oteo 21 Legal notice This publication of the European Monitoring Centre for Drugs and Drug Addiction (EMCDDA) is protected by copyright. The EMCDDA accepts no responsibility or liability for any consequences arising from the use of the data contained in this document. The contents of this publication do not necessarily reflect the official opinions of the EMCDDA’s partners, any EU Member State or any agency or institution of the European Union. Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) The information given is free, as are most calls (though some operators, phone boxes or hotels may charge you). More information on the European Union is available on the internet (http://europa.eu). Luxembourg: Publications Office of the European Union, 2016 ISBN: 978-92-9168-841-8 doi:10.2810/324608 © European Monitoring Centre for Drugs and Drug Addiction, 2016 Reproduction is authorised provided the source is acknowledged. This publication should be referenced as: European Monitoring Centre for Drugs and Drug Addiction (2016), The internet and drug markets, EMCDDA Insights 21, Publications Office of the European Union, Luxembourg. References to chapters in this publication should include, where relevant, references to the authors of each chapter, together with a reference to the wider publication. For example: Mounteney, J., Oteo, A. and Griffiths, P. -

Fraud and the Darknets
OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud And The Darknets Thomas Harper Assistant Special Agent in Charge Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division What is an OIG? • Established by Congress • Independent agency that reports to Congress • Agency head appointed by the President and confirmed by Congress • Mission: protect the taxpayer’s interests by ensuring the integrity and efficiency of the associated agency OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Technology Crimes Division • Investigate criminal cyber threats against the Department’s IT infrastructure, or • Criminal activity in cyber space that threatens the Department’s administration of Federal education assistance funds • Investigative jurisdiction encompasses any IT system used in the administration of Federal money originating from the Department of Education. OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Work Examples • Grade hacking • Computer Intrusions • Criminal Forums online selling malware • ID/Credential theft to hijack Student Aid applications • Misuse of Department systems to obtain personal information • Falsifying student aid applications by U.S. government employees • Child Exploitation material trafficking OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud and the Darknets Special Thanks to Financial Crimes Enforcement Network (FINCEN) OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud and the Darknets OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. -
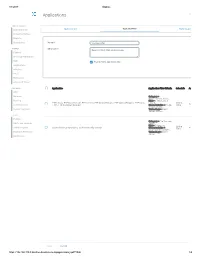
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

Rock in the Reservation: Songs from the Leningrad Rock Club 1981-86 (1St Edition)
R O C K i n t h e R E S E R V A T I O N Songs from the Leningrad Rock Club 1981-86 Yngvar Bordewich Steinholt Rock in the Reservation: Songs from the Leningrad Rock Club 1981-86 (1st edition). (text, 2004) Yngvar B. Steinholt. New York and Bergen, Mass Media Music Scholars’ Press, Inc. viii + 230 pages + 14 photo pages. Delivered in pdf format for printing in March 2005. ISBN 0-9701684-3-8 Yngvar Bordewich Steinholt (b. 1969) currently teaches Russian Cultural History at the Department of Russian Studies, Bergen University (http://www.hf.uib.no/i/russisk/steinholt). The text is a revised and corrected version of the identically entitled doctoral thesis, publicly defended on 12. November 2004 at the Humanistics Faculty, Bergen University, in partial fulfilment of the Doctor Artium degree. Opponents were Associate Professor Finn Sivert Nielsen, Institute of Anthropology, Copenhagen University, and Professor Stan Hawkins, Institute of Musicology, Oslo University. The pagination, numbering, format, size, and page layout of the original thesis do not correspond to the present edition. Photographs by Andrei ‘Villi’ Usov ( A. Usov) are used with kind permission. Cover illustrations by Nikolai Kopeikin were made exclusively for RiR. Published by Mass Media Music Scholars’ Press, Inc. 401 West End Avenue # 3B New York, NY 10024 USA Preface i Acknowledgements This study has been completed with the generous financial support of The Research Council of Norway (Norges Forskningsråd). It was conducted at the Department of Russian Studies in the friendly atmosphere of the Institute of Classical Philology, Religion and Russian Studies (IKRR), Bergen University. -

Social Media Investigations Within the Dark Web About the Presenters
Social Media Investigations Within the Dark Web About the presenters Joe Church Founder & Owner Digital Shield, Incorporated Ashley Luna Product Manager X1 John Patzakis Executive Chairman X1 Agenda • X1 Overview • Digital Shield Overview • Introduction to the Dark Web • Accessing the Dark Web • Dark Web Collection Demo • Interactive Q&A X1 Social Discovery • Designed for investigative professionals to collect social posts, website content, webmail, and YouTube videos and other social media types all from within a single user interface. • Supports the simultaneous collection of content and metadata • Legally defensible collections that preserve chain of custody. • Build on X1’s patented & proven fast-as-you-type search technology Presenter Background • Joe Church – Digital Shield, Inc. • Prior LE/Federal LE • Private Business • Litigation Support • State/Federal/International Testimony • Case Work • Leading Technology • Course Development • Major Vendors Internet Layers Surface Web • Also called: ▫ World Wide Web ▫ Clearnet ▫ Visible Web • Topmost level of the web, searchable by surface crawlers ▫ Examples: Bing, Google, Yahoo Deep Web • Also called: ▫ Deepnet ▫ Invisible Web ▫ Hidden Web • Second level of the web • Cannot be reached by traditional search engines Dark Web • Also called: ▫ Darknet • Small portion of the Internet that is intentionally hidden ▫ Restricted, encrypted, and not fully indexed ▫ Often associated with criminal activity ▫ Originally developed by US military researches Dark Web • Creates an Overlay Network, a new -

Download: Brill.Com/Brill-Typeface
Poets of Hope and Despair Russian History and Culture Editors-in-Chief Jeffrey P. Brooks (The Johns Hopkins University) Christina Lodder (University of Kent) Volume 21 The titles published in this series are listed at brill.com/rhc Poets of Hope and Despair The Russian Symbolists in War and Revolution, 1914-1918 Second Revised Edition By Ben Hellman This title is published in Open Access with the support of the University of Helsinki Library. This is an open access title distributed under the terms of the CC BY-NC-ND 4.0 license, which permits any non-commercial use, distribution, and reproduction in any medium, provided no alterations are made and the original author(s) and source are credited. Further information and the complete license text can be found at https://creativecommons.org/licenses/by-nc-nd/4.0/ The terms of the CC license apply only to the original material. The use of material from other sources (indicated by a reference) such as diagrams, illustrations, photos and text samples may require further permission from the respective copyright holder. Cover illustration: Angel with sword, from the cover of Voina v russkoi poezii (1915, War in Russian Poetry). Artist: Nikolai K. Kalmakov (1873-1955). Brill has made all reasonable efforts to trace all rights holders to any copyrighted material used in this work. In cases where these efforts have not been successful the publisher welcomes communications from copyright holders, so that the appropriate acknowledgements can be made in future editions, and to settle other permission matters. The Library of Congress Cataloging-in-Publication Data is available online at http://catalog.loc.gov Typeface for the Latin, Greek, and Cyrillic scripts: “Brill”. -

Introduction Points
Introduction Points Ahmia.fi - Clearnet search engine for Tor Hidden Services (allows you to add new sites to its database) TORLINKS Directory for .onion sites, moderated. Core.onion - Simple onion bootstrapping Deepsearch - Another search engine. DuckDuckGo - A Hidden Service that searches the clearnet. TORCH - Tor Search Engine. Claims to index around 1.1 Million pages. Welcome, We've been expecting you! - Links to basic encryption guides. Onion Mail - SMTP/IMAP/POP3. ***@onionmail.in address. URSSMail - Anonymous and, most important, SECURE! Located in 3 different servers from across the globe. Hidden Wiki Mirror - Good mirror of the Hidden Wiki, in the case of downtime. Where's pedophilia? I WANT IT! Keep calm and see this. Enter at your own risk. Site with gore content is well below. Discover it! Financial Services Currencies, banks, money markets, clearing houses, exchangers. The Green Machine Forum type marketplace for CCs, Paypals, etc.... Some very good vendors here!!!! Paypal-Coins - Buy a paypal account and receive the balance in your bitcoin wallet. Acrimonious2 - Oldest escrowprovider in onionland. BitBond - 5% return per week on Bitcoin Bonds. OnionBC Anonymous Bitcoin eWallet, mixing service and Escrow system. Nice site with many features. The PaypalDome Live Paypal accounts with good balances - buy some, and fix your financial situation for awhile. EasyCoin - Bitcoin Wallet with free Bitcoin Mixer. WeBuyBitcoins - Sell your Bitcoins for Cash (USD), ACH, WU/MG, LR, PayPal and more. Cheap Euros - 20€ Counterfeit bills. Unbeatable prices!! OnionWallet - Anonymous Bitcoin Wallet and Bitcoin Laundry. BestPal BestPal is your Best Pal, if you need money fast. Sells stolen PP accounts. -

An Investigative Study of Cryptocurrency Abuses in the Dark Web
Cybercriminal Minds: An investigative study of cryptocurrency abuses in the Dark Web Seunghyeon Leeyz Changhoon Yoonz Heedo Kangy Yeonkeun Kimy Yongdae Kimy Dongsu Hany Sooel Sony Seungwon Shinyz yKAIST zS2W LAB Inc. {seunghyeon, kangheedo, yeonk, yongdaek, dhan.ee, sl.son, claude}@kaist.ac.kr {cy}@s2wlab.com Abstract—The Dark Web is notorious for being a major known as one of the major drug trading sites [13], [22], and distribution channel of harmful content as well as unlawful goods. WannaCry malware, one of the most notorious ransomware, Perpetrators have also used cryptocurrencies to conduct illicit has actively used the Dark Web to operate C&C servers [50]. financial transactions while hiding their identities. The limited Cryptocurrency also presents a similar situation. Apart from coverage and outdated data of the Dark Web in previous studies a centralized server, cryptocurrencies (e.g., Bitcoin [58] and motivated us to conduct an in-depth investigative study to under- Ethereum [72]) enable people to conduct peer-to-peer trades stand how perpetrators abuse cryptocurrencies in the Dark Web. We designed and implemented MFScope, a new framework which without central authorities, and thus it is hard to identify collects Dark Web data, extracts cryptocurrency information, and trading peers. analyzes their usage characteristics on the Dark Web. Specifically, Similar to the case of the Dark Web, cryptocurrencies MFScope collected more than 27 million dark webpages and also provide benefits to our society in that they can redesign extracted around 10 million unique cryptocurrency addresses for Bitcoin, Ethereum, and Monero. It then classified their usages to financial trading mechanisms and thus motivate new business identify trades of illicit goods and traced cryptocurrency money models, but are also adopted in financial crimes (e.g., money flows, to reveal black money operations on the Dark Web. -

Torward: DISCOVERY, BLOCKING, and TRACEBACK of MALICIOUS TRAFFIC OVER Tor 2517
IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 10, NO. 12, DECEMBER 2015 2515 TorWard: Discovery, Blocking, and Traceback of Malicious Traffic Over Tor Zhen Ling, Junzhou Luo, Member, IEEE,KuiWu,Senior Member, IEEE, Wei Yu, and Xinwen Fu Abstract— Tor is a popular low-latency anonymous communi- I. INTRODUCTION cation system. It is, however, currently abused in various ways. OR IS a popular overlay network that provides Tor exit routers are frequently troubled by administrative and legal complaints. To gain an insight into such abuse, we designed Tanonymous communication over the Internet for and implemented a novel system, TorWard, for the discovery and TCP applications and helps fight against various Internet the systematic study of malicious traffic over Tor. The system censorship [1]. It serves hundreds of thousands of users and can avoid legal and administrative complaints, and allows the carries terabyte of traffic daily. Unfortunately, Tor has been investigation to be performed in a sensitive environment such abused in various ways. Copyrighted materials are shared as a university campus. An intrusion detection system (IDS) is used to discover and classify malicious traffic. We performed through Tor. The black markets (e.g., Silk Road [2], an comprehensive analysis and extensive real-world experiments to online market selling goods such as pornography, narcotics validate the feasibility and the effectiveness of TorWard. Our or weapons1) can be deployed through Tor hidden service. results show that around 10% Tor traffic can trigger IDS alerts. Attackers also run botnet Command and Control (C&C) Malicious traffic includes P2P traffic, malware traffic (e.g., botnet servers and send spam over Tor. -

Security Analysis of Instant Messenger Torchat
TALLINN UNIVERSITY OF TECHNOLOGY Faculty of Information Technology Department of Informatics Chair of Software Engineering Security Analysis of Instant Messenger TorChat Master's Thesis Student: Rain Viigipuu Student code: 072125 Supervisor: Alexander Norta, PhD External Supervisor: Arnis Parˇsovs, MSc TALLINN 2015 Abstract TorChat is a peer-to-peer instant messenger built on top of the Tor network that not only provides authentication and end-to-end encryption, but also allows the communication parties to stay anonymous. In addition, it prevents third parties from even learning that communication is taking place. The aim of this thesis is to document the protocol used by TorChat and to analyze the security of TorChat and its reference implementation. The work shows that although the design of TorChat is sound, its implementation has several flaws, which make TorChat users vulnerable to impersonation, communication confirmation and denial-of-service attacks. 2 Contents 1 Introduction 6 2 Tor and Hidden Services 8 2.1 Hidden Services . .9 2.1.1 Hidden service address . 11 3 TorChat 12 3.1 Managing Contacts and Conversations . 12 3.2 Configuration Options . 16 4 TorChat Protocol 17 4.1 Handshake . 17 4.2 File Transfers . 18 4.3 Protocol Messages . 19 4.3.1 not implemented . 19 4.3.2 ping . 20 4.3.3 pong . 21 4.3.4 client . 22 4.3.5 version . 22 4.3.6 status . 22 4.3.7 profile name . 23 4.3.8 profile text . 23 4.3.9 profile avatar alpha . 24 4.3.10 profile avatar . 24 4.3.11 add me............................. -

Monitoring the Dark Web and Securing Onion Services
City University of New York (CUNY) CUNY Academic Works Publications and Research Queensborough Community College 2017 Monitoring the Dark Web and Securing Onion Services John Schriner CUNY Queensborough Community College How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/qb_pubs/41 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] Monitoring the Dark Web Schriner 1 John Schriner Monitoring the Dark Web Contrary to what one may expect to read with a title like Monitoring the Dark Web, this paper will focus less on how law enforcement works to monitor hidden web sites and services and focus more on how academics and researchers monitor this realm. The paper is divided into three parts: Part One discusses Tor research and how onion services work; Part Two discusses tools that researchers use to monitor the dark web; Part Three tackles the technological, ethical, and social interests at play in securing the dark web. Part One: Tor is Research-Driven Tor (an acronym for 'the onion router' now stylized simply 'Tor') is an anonymity network in which a user of the Tor Browser connects to a website via three hops: a guard node, a middle relay, and an exit node. The connection is encrypted with three layers, stripping a layer at each hop towards its destination server. No single node has the full picture of the connection along the circuit: the guard knows only your IP but not where the destination is; the middle node knows the guard and the exit node; the exit node knows only the middle node and the final destination.