SIEVE: Secure In-Vehicle Automatic Speech Recognition Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Car Electronics Resource Center
Car Electronics Resource Center Satellite Radio Installation Guide Difficulty Level: Easy to Moderate Average Installation Time: 1-2 Hours Tools and Supplies Needed: In This Guide: Satellite radio installa- tion involves installing an antenna and satellite radio tuner. Receivers that are “Sirius XM Ready” provide the control of the tuner. Otherwise, a separate control panel can be installed to Sockets or Open Zip Ties Side Cutters control the satellite tuner independent End Wrenches of the receiver. Use an FM transmit- ter, AUX input, or a direct connection method to connect the tuner’s audio output to the vehicle’s sound system. Panel Removal Tools Utility Knife Phillips Screwdriver Electrical Tape Important Blue Painter’s Tape Before You Begin (protects dash surfaces) This content has not been verified by Amazon for accuracy, completeness, or otherwise. Consult your vehicle’s owner’s manual and the product’s Product Owner’s Manual manual before attempting an installation. Contact Installation Manual(s) the product’s manufacturer or consult a Mobile 1 2 3 Electronics Certified Professional installer if you are uncertain about how to properly install your product. Amazon attempts to be as accurate Towel as possible, however, because of the number of (protects console) vehicles and products available to consumers, it is not possible to provide detailed installation steps that apply universally to all vehicles and products. Amazon does not warrant that product descriptions or other content of this site is accurate, complete, reliable, current, or error-free. Read all instructions carefully Disconnect the negative battery cable Protect interior surfaces Further, Amazon disclaims any warranties, express or implied, as further set forth in the ‘Conditions of Use’ for Amazon.com. -

AUDIO and CONNECTIVITY AUDIO and CONNECTIVITY Learn How to Operate the Vehicle’S Audio System
AUDIO AND CONNECTIVITY AUDIO AND CONNECTIVITY Learn how to operate the vehicle’s audio system. Basic Audio Operation Connect audio devices and operate buttons and displays for the audio system. USB Port Connect a USB flash drive or other audio device, such as an iPod or iPhone®. Install the flash drive or cable connector to the USB port. iPod and iPhone are trademarks of Apple, Inc. State or local laws may prohibit the operation of handheld electronic devices while operating a vehicle. Auxiliary Input Jack Connect standard audio devices with a 1/8-inch (3.5 mm) stereo miniplug. 1. Open the AUX cover. 2. Insert the miniplug attached to the audio device into the jack. The audio system switches to AUX mode. Use the device to control the audio. AC Power Outlet* The outlet can supply power for appliances up to 115 volts that are rated 150 watts or less when the engine is running. 1. Open the socket cover located on the driver’s side rear door. 2. Slightly plug in the appliance, turn it 90 degrees clockwise, then push it in all the way. NOTICE Do not use the AC power outlet for electric appliances that require high initial peak wattage or medical equipment devices. *if equipped AUDIO AND CONNECTIVITY Accessory Power Sockets Open the socket cover to use power when the vehicle is on. Power sockets are located in the front console and the driver’s side rear cargo area. NOTICE Do not insert an automotive type cigarette lighter element. This can overheat the power socket. -

Class D14 Recording, Communication, Or Information Retrieval D14 - 1 Equipment
CLASS D14 RECORDING, COMMUNICATION, OR INFORMATION RETRIEVAL D14 - 1 EQUIPMENT D14 RECORDING, COMMUNICATION, OR INFORMATION RETRIEVAL EQUIPMENT 300 COMPUTER, DATA PROCESSOR 346 ..And keypad EQUIPMENT 347 ...Housing flared at one end 301 .Mainframe, central data 348 .Hard drive for personal computer processing or server type 349 ..Tower type 302 ..Freestanding console 350 ...And wheels 303 ...And paper printout 351 ...Flared or protruding base 304 ...Provision for seated operator 352 ....Footed (e.g., extended foot 305 ....And monitor members) 306 .....Plural 353 ..Housing includes texture 307 ...And monitor 354 ...Vertical 308 ..Cabinet 355 ...Horizontal 309 ...Drum unit 356 .Peripheral equipment 310 ...Plural identical units 357 ..Converter or interface 311 ...And horizontal louver detail 358 ..Transmitter or receiving unit 312 ...And vertical louver detail 359 ..Perforated media reader or 313 ..Rack mounted or stacked type perforator 314 .Desktop type 360 ...Tape specific 315 ..Laptop type 361 ..Tape reader or drive 316 ...Swivel display support 362 ...Desk top type 317 ...Combined with camera 363 ..Disc drive or reader 318 ...And touch type cursor pad 364 ...Library cabinet type 319 ...Provision for compact disc 365 ...Desk top (e.g., CD-ROM, etc.) 366 ....And distended tray or 320 ...Distended or keyboard type compartment 321 ...Front loading 367 ....Module type 322 ....Screen attached at rear edge 368 ....Front loading 323 ...Side loading 369 .....Provision for plural disc 324 ....And handle or extending 370 ..Media loader or copier -

An FFT-Ifft Combination Based Transfer Function Approach to Improve Effectiveness of Vehicle In- Cab Sound Quality Assessment
An FFT-iFFT combination based transfer function approach to improve effectiveness of vehicle in- cab sound quality assessment. Rajeev Kumar B R Robert Bosch Engineering and Business Solutions Pvt Ltd, India. Sumanth Hegde Robert Bosch Engineering and Business Solutions Pvt Ltd, India. Ganesh R Iyer Robert Bosch Engineering and Business Solutions Pvt Ltd, India. Guruthangaraj Radhakrishnan Robert Bosch Engineering and Business Solutions Pvt Ltd, India. Summary Customer comfort related to a pleasing sound quality is key-towards achieving a competitive edge, specifically in the automotive industry today. This is more critical for vehicles falling into passenger car segments, specifically in the M1, M2 and M3 vehicle categories. With more focus towards NVH, it is important to also consider the “design for NVH” aspect in addition to fulfilling the primary requirements of performance, durability and legislative needs. With increasing focus towards electrification, the focus is also shifting towards improving the overall vehicle sound quality, be it, powertrain noise, operational sounds (such as door closure), or even improving the sound quality of the car-multimedia systems. The study conducted in this paper, details how in cab sound quality can be front-loaded much earlier into the design. This has been illustrated with use of a simplified FFT-iFFT based approach to improve sound quality of vehicle multimedia systems. The audio quality tuning for car-multimedia system requires engineers to tune the hardware/amplifiers through rigorous audio jury tests within the cabin for different audio filter (Equalizer) settings. There is a huge dependency on vehicle cabin, as the cabin acoustic properties significantly affects the sound quality perception for a specific car multimedia audio filter settings. -

Acoustical Classification of the Urban Road Traffic with Large Arrays Of
Acoustical Classification of the Urban Road Traffic with Large Arrays of Microphones Raphaël Leiba, François Ollivier, Régis Marchiano, Nicolas Misdariis, Jacques Marchal, Pascal Challande To cite this version: Raphaël Leiba, François Ollivier, Régis Marchiano, Nicolas Misdariis, Jacques Marchal, et al.. Acous- tical Classification of the Urban Road Traffic with Large Arrays of Microphones. Acta Acustica united with Acustica, Hirzel Verlag, 2019, 105 (6), pp.1067-1077. 10.3813/AAA.919385. hal-02457922 HAL Id: hal-02457922 https://hal.sorbonne-universite.fr/hal-02457922 Submitted on 28 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ACTA ACUSTICA UNITED WITH ACUSTICA Vol. 105 (2019) 1067 –1077 DOI 10.3813/AAA.919385 Acoustical Classification of the Urban Road Traffic with Large Arrays of Microphones Raphaël Leiba1,2),François Ollivier1),Régis Marchiano1),Nicolas Misdariis2),Jacques Marchal1), Pascal Challande1) 1) Sorbonne Université, CNRS, Institut Jean Le Rond ∂’Alembert, 75005 Paris, France. [email protected] 2) STMS Ircam-CNRS-SU Colour Figures: Figures in colour aregiven in the online version Summary This work is part of astudy dealing with city-dwellers’ quality of life. Noise is known to be an important fac- tor influencing the quality of life. -
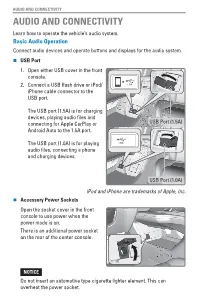
AUDIO and CONNECTIVITY AUDIO and CONNECTIVITY Learn How to Operate the Vehicle’S Audio System
AUDIO AND CONNECTIVITY AUDIO AND CONNECTIVITY Learn how to operate the vehicle’s audio system. Basic Audio Operation Connect audio devices and operate buttons and displays for the audio system. n USB Port 1. Open either USB cover in the front console. 2. Connect a USB flash drive or iPod/ iPhone cable connector to the USB port. The USB port (1.5A) is for charging devices, playing audio files and connecting for Apple CarPlay or USB Port (1.5A) Android Auto to the 1.5A port. The USB port (1.0A) is for playing audio files, connecting a phone and charging devices. USB Port (1.0A) iPod and iPhone are trademarks of Apple, Inc. n Accessory Power Sockets Open the socket cover in the front console to use power when the power mode is on. There is an additional power socket on the rear of the center console. NOTICE Do not insert an automotive type cigarette lighter element. This can overheat the power socket. AUDIO AND CONNECTIVITY n Audio Remote Controls You can operate certain functions of the audio system using the steering wheel controls. button: Press until the audio (+ (- Bar screen is displayed in the Driver ENTER Button Information Interface. Button + / - bar: Press the ends of the bar to Button adjust audio volume. Button ENTER button: Make audio selections Button in the Driver Information Interface. button: Go back to the previous Button command or cancel a command. t / u buttons: Change presets, tracks, albums, or folders. From the audio screen in the Driver Information Interface: FM/AM/SiriusXM® Radio* Press t or u for the next or previous preset station. -

Historical Development of Magnetic Recording and Tape Recorder 3 Masanori Kimizuka
Historical Development of Magnetic Recording and Tape Recorder 3 Masanori Kimizuka ■ Abstract The history of sound recording started with the "Phonograph," the machine invented by Thomas Edison in the USA in 1877. Following that invention, Oberlin Smith, an American engineer, announced his idea for magnetic recording in 1888. Ten years later, Valdemar Poulsen, a Danish telephone engineer, invented the world's frst magnetic recorder, called the "Telegraphone," in 1898. The Telegraphone used thin metal wire as the recording material. Though wire recorders like the Telegraphone did not become popular, research on magnetic recording continued all over the world, and a new type of recorder that used tape coated with magnetic powder instead of metal wire as the recording material was invented in the 1920's. The real archetype of the modern tape recorder, the "Magnetophone," which was developed in Germany in the mid-1930's, was based on this recorder.After World War II, the USA conducted extensive research on the technology of the requisitioned Magnetophone and subsequently developed a modern professional tape recorder. Since the functionality of this tape recorder was superior to that of the conventional disc recorder, several broadcast stations immediately introduced new machines to their radio broadcasting operations. The tape recorder was soon introduced to the consumer market also, which led to a very rapid increase in the number of machines produced. In Japan, Tokyo Tsushin Kogyo, which eventually changed its name to Sony, started investigating magnetic recording technology after the end of the war and soon developed their original magnetic tape and recorder. In 1950 they released the frst Japanese tape recorder. -

A Guide to Audio-Frequency Induction Loop Systems Contents
A Guide to Audio-Frequency Induction Loop Systems Contents About this guide .................................................................................................................. 3 What is an audio frequency induction loop system?...................................................... 4 How does an induction loop system work? .................................................................... 5 Why we have induction loop systems .............................................................................. 6 Where are ‘aids to communication’ required? ................................................................ 7 Which induction loop system should I use? .................................................................. 9 1.2m2 PL1 Portable Induction Loop System .................................................................................... 10 1.2m2 ML1/K Counter Induction Loop System ................................................................................ 11 1.2m2 PDA102C Counter Induction Loop System .......................................................................... 12 1.2m2 VL1 Vehicle Induction Loop System ......................................................................................13 50m2 PDA102L/R/S Small Room Induction Loop System .............................................................. 14 50m2 DL50/K Domestic Induction Loop System ..............................................................................15 120m2 ‘AK’ Range Induction Loop Kits / PDA200E Amplifier............................................................16 -

Automotive Audio Testing Any Car Audio System, Any Measurement
Automotive Audio Automotive Audio Testing Any Car Audio System, Any Measurement • Microphone Array • Active Noise • Head Unit Cancellation (ANC) • Speakers • Bluetooth Performance • Infotainment • Hands Free • Telematics • Voice Recognition Audio Test and Measurement System SoundCheck® algorithms and powerful post processing options Any Car Audio, allow a wide choice of analyses and mathematical Any Measurement operations. SoundCheck offers simple, fast and accurate For example, using a common 6 measurement testing of vehicle audio quality, from individual microphone array, it is possible to measure speaker components to complete in-vehicle sound power, time delays, spatial envelopment infotainment and telematics systems. With and both tonal and stereo balance. Alternatively, interfaces to connect via Bluetooth, Lightning, the response of a telematics microphone USB and with individual MEMs devices, as well array to a person in the driver’s seat both as analog connections, with and without background noise can be SoundCheck can handle evaluated. Documentation options range from the complexity and comprehensive Microsoft Word or Excel reports demands of testing in to simple pass/fail outputs or automatic database today’s vehicles. writing. Measurements include: Repeatable, automated tests are quickly and easily • Speaker/system response created, modified and saved using the simple • Speaker/panel buzz, squeak and rattle point-and-click interface. Complex sequences can • Bluetooth audio performance be developed to meet specific automotive test • Head unit and amplifier response & THD+N requirements, for example performance of active • Microphone/microphone array response road noise cancellation, microphone directivity • Active noise cancellation effectiveness and spatial reproduction. • Spatial reproduction accuracy The System SoundCheck’s modular combination of hardware and software is cost-effective, flexible and expandable. -

GX-A604/GX-A602/GX-A3001 Power Amplifi Er
GX-A604/GX-A602/GX-A3001 power amplifi er OWNER'S MANUAL INTRODUCTION THANK YOU for purchasing a JBL® GX-series amplifier. So we can better serve you should you require warranty service, please retain your original sales receipt and register your amplifier online at www.jbl.com. INCLUDED ITEMS Speaker-level input harness GX-Series Amplifier (x 1) (GX-A602, GX-A3001 x 1) (GX-A604 x 2) LOCATION AND MOUNTING Although these instructions explain how to install GX-series amplifiers in a general sense, they do not show specific installation methods that may be required for your particular vehicle. If you do not have the necessary tools or experience, do not attempt the installation yourself. Instead, please ask your authorized JBL car audio dealer about professional installation. INSTALLATION WARNINGS AND TIPS IMPORTANT: Disconnect the vehicle’s negative (–) battery terminal before beginning the installation. • Always wear protective eyewear when using tools. • Check clearances on both sides of a planned mounting surface. Be sure that screws or wires will not puncture brake lines, fuel lines or wiring harnesses, and that wire routing will not interfere with the safe operation of the vehicle. • When making electrical connections, make sure they are secure and properly insulated. • If you must replace any of the amplifier's fuses, be sure to use the same type of fuse and current rating as that of the original. 2 English INSTALLATION LOCATION Amplifiers need air circulation to stay cool. Select a location that provides enough air for the amp to cool itself. • Suitable locations are under a seat (provided the amplifier doesn’t interfere with the seat adjustment mechanism), in the trunk, or in any other location that provides enough cooling air. -

Introduction to Active Sound Management Technology
DENSO TEN Technical Review Vol.1 Introduction to Active Sound Management Technology Sanjay Singh Takehiro WAKAMATSU Keizo ISHIMURA Abstract Active Sound Management is a technology that enables to control sound effectively leveraging the existing audio system. More recently, it has been expanding to be applied as a technology to provide in-cabin acoustic environment with comfort, such as eliminating uncomfortable low frequency“boom” sound resulting from powertrains and enhancing powerful engine sound. In this article, the system developed by DENSO TEN, which includes the DSP with Active Sound Management algorithm by Müller BBM GmbH coded, is discussed. Based on the existing audio system, configuration parts added microphone, speaker, and others, system design requirement such as signal processing of CAN-BUS, and analysis of tuning results on actual vehicles (reduction of boom sound and enhancement of engine sound) are introduced. 1. Introduction 1.1 Active Sound Management Technology 1.2 Active Noise Cancellation (ANC) Active Sound Management enables OEMs to Loud engine/powertrain sounds can result from control sound effectively, leveraging the existing mass reduction of components that result in increased audio system. It allows providing a wide range of vibration. Uncomfortable sounds also result from acoustic options. For the past decade, Noise Vibration early torque converter lock, cylinder deactivation, (NV) teams have used Active Sound Management to transition from electric to Internal Combustion reduce driver fatigue by eliminating uncomfortable Engine (ICE), as well as Continuously Variable low frequency “boom” sound resulting from Transmission (CVT) drivetrain. Technologies powertrains. More recently it is also used to create designed to improve fuel efficiency typically have in-cabin acoustic brand images such as refined a side effect of causing uncomfortable sounds and luxury, familiar comfort, and sporty excitement. -

• Police Department
• POLICE DEPARTMENT AlAN NI, APAKAWA COUNTY OF MAUI GARY YA8UTA MAYOR 55 MAHALANI STREET CHIEF A.OF POLICE WAILUKU, HAWAII 96793 OUR REFERENCE (808) 244-6400 CLAYTON Ns.w. TOM FAX (808) 244-6411 DEPUTY CHIEF OF POLICE YOUR REFERENCE Febmaiy 4, 2011 The Honorable Joseph M. Sôuki, Chair and Members of the Committee on Transportation House of Representatives State Capitol Honolulu, Hawaii 96813 RE: House Bill No. I 178,Relating to Vehicle Audio Equipment Dear Chair Souki and Members of.the Committee: The Maui Police Department support~ KB. No. 1178. The Law Enforcement frequently receives public nuisance calls for service for excessive amplified music in neighborhoods and public parks Most of those vehicles have aftermarket audio equipment. This bill will address the Installation of aftermarket motor vehicle audio equipment by prohibiting excessive sound amplification. I recommend raising the minimum fine of $25 to an amount that would mdi ate that the abuse of such equipment is a real problem in our communities~ The Maui Police Department asks for your support on H.B. No. 1178. Thank you for the opportunity to testi&. Sincerely, GARY A. YABUTA Chief of Policp a uqiRMUU CUWtOUI5~ GROUP ~C. The State of Hawaii Attn.: House of Representatives Twenty Sixth Legislature, 2011 To whom it may concern: I am writing you today to register my opposition to the proposed House Bill 1178 (Amended Chapter 291) in which aftermarket audio equipment in a vehicle is the focus. I ani a consultant in the Automotive and Consumer Electronics industries with clientele in Hawaii engaged in the retail sales and installation of aftermarket audio equipment.