Mémoire Présenté Devant L'institut De Science Financière Et D'assurances
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Article Is Structured As Follows
Nat. Hazards Earth Syst. Sci., 14, 2867–2882, 2014 www.nat-hazards-earth-syst-sci.net/14/2867/2014/ doi:10.5194/nhess-14-2867-2014 © Author(s) 2014. CC Attribution 3.0 License. A catalog of high-impact windstorms in Switzerland since 1859 P. Stucki1, S. Brönnimann1, O. Martius1,2, C. Welker1, M. Imhof3, N. von Wattenwyl1, and N. Philipp1 1Oeschger Centre for Climate Change Research and Institute of Geography, University of Bern, Bern, Switzerland 2Mobiliar Lab for Natural Risks, Bern, Switzerland 3Interkantonaler Rückversicherungsverband, Bern, Switzerland Correspondence to: P. Stucki ([email protected]) Received: 17 April 2014 – Published in Nat. Hazards Earth Syst. Sci. Discuss.: 28 May 2014 Revised: 12 September 2014 – Accepted: 23 September 2014 – Published: 4 November 2014 Abstract. In recent decades, extremely hazardous wind- The damage to buildings and forests from recent, extreme storms have caused enormous losses to buildings, infrastruc- windstorms, such as Vivian (February 1990) and Lothar (De- ture and forests in Switzerland. This has increased societal cember 1999), have been perceived as unprecedented and and scientific interest in the intensity and frequency of his- unanticipated (Bründl and Rickli, 2002; Holenstein, 1994; torical high-impact storms. However, high-resolution wind Schüepp et al., 1994; Brändli, 1996; WSL, 2001). data and damage statistics mostly span recent decades only. Public perception of a potentially increasing windstorm For this study, we collected quantitative (e.g., volumes of hazard (Schmith et al., 1998) motivated several studies on windfall timber, losses relating to buildings) and descriptive the intensity and occurrence frequency of high-impact storms (e.g., forestry or insurance reports) information on the impact (e.g., Pfister, 1999). -

Monitoring Black Grouse Tetrao Tetrix in Isère, Northern French Alps: Cofactors, Population Trends and Potential Biases
Animal Biodiversity and Conservation 42.2 (2019) 227 Monitoring black grouse Tetrao tetrix in Isère, northern French Alps: cofactors, population trends and potential biases L. Dumont, E. Lauer, S. Zimmermann, P. Roche, P. Auliac, M. Sarasa Dumont, L., Lauer, E., Zimmermann, S., Roche, P., Auliac, P., Sarasa, M., 2019. Monitoring black grouse Tetrao tetrix in Isère, northern French Alps: cofactors, population trends and potential biases. Animal Biodiversity and Conservation, 42.2: 227–244, Doi: https://doi.org/10.32800/abc.2019.42.0227 Abstract Monitoring black grouse Tetrao tetrix in Isère, northern French Alps: cofactors, population trends and potential biases. Wildlife management benefits from studies that verify or improve the reliability of monitoring protocols. In this study in Isère, France, we tested for potential links between the abundance of black grouse (Tetrao tetrix) in lek–count surveys and cofactors (procedural, geographical and meteorological cofactors) between 1989 and 2016. We also examined the effect of omitting or considering the important cofactors on the long–term population trend that can be inferred from lek–count data. Model selections for data at hand highlighted that the abundance of black grouse was mainly linked to procedural cofactors, such as the number of observers, the time of first observation of a displaying male, the day, and the year of the count. Some additional factors relating to the surface of the census sector, temperature, northing, altitude and wind conditions also appeared depending on the spatial or temporal scale of the analysis. The inclusion of the important cofactors in models modulated the estimates of population trends. The results of the larger dataset highlighted a mean increase of +17 % (+5.3 %; +29 %) of the abundance of black grouse from 1997 to 2001, and a mean increase in population of +47 % (+16 %; +87 %) throughout the study period (1989–2016). -
Disasters from 1970–2009 by Cost
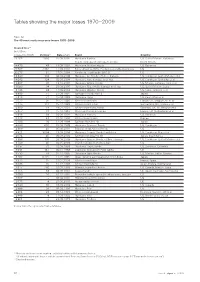
Tables showing the major losses 1970 –2009 Table 12 The 40 most costly insurance losses 1970–2009 Insured loss10 (in USD m, indexed to 2009) Victims11 Date (start) Event Country 71 163 1 836 25.08.2005 Hurricane Katrina; US, Gulf of Mexico, Bahamas, floods, dams burst, damage to oil rigs North Atlantic 24 479 43 23.08.1992 Hurricane Andrew; floods US, Bahamas 22 767 2 982 11.09.2001 Terror attack on WTC, Pentagon and other buildings US 20 276 61 17.01.1994 Northridge earthquake (M 6.6) US 19 940 136 06.09.2008 Hurricane Ike; floods, offshore damage US, Caribbean: Gulf of Mexico et al 14 642 124 02.09.2004 Hurricane Ivan; damage to oil rigs US, Caribbean; Barbados et al 13 807 35 19.10.2005 Hurricane Wilma; floods US, Mexico, Jamaica, Haiti et al 11 089 34 20.09.2005 Hurricane Rita; floods, damage to oil rigs US, Gulf of Mexico, Cuba 9 148 24 11.08.2004 Hurricane Charley; floods US, Cuba, Jamaica et al 8 899 51 27.09.1991 Typhoon Mireille/No 19 Japan 7 916 71 15.09.1989 Hurricane Hugo US, Puerto Rico et al 7 672 95 25.01.1990 Winter storm Daria France, UK, Belgium, NL et al 7 475 110 25.12.1999 Winter storm Lothar Switzerland, UK, France et al 6 309 54 18.01.2007 Winter storm Kyrill; floods Germany, UK, NL, Belgium et al 5 857 22 15.10.1987 Storm and floods in Europe France, UK, Netherlands et al 5 848 38 26.08.2004 Hurricane Frances US, Bahamas 5 242 64 25.02.1990 Winter storm Vivian Europe 5 206 26 22.09.1999 Typhoon Bart/No 18 Japan 4 649 600 20.09.1998 Hurricane Georges; floods US, Caribbean 4 369 41 05.06.2001 Tropical storm Allison; -

The Case Study of Windstorm VIVIAN, Switzerland, February 27, 1990
1 Published in Climate Dynamics 18: 145-168, 2001 S. Goyette á M. Beniston á D. Caya á R. Laprise P. Jungo Numerical investigation of an extreme storm with the Canadian Regional Climate Model: the case study of windstorm VIVIAN, Switzerland, February 27, 1990 Received: 6 July 2000 / Accepted: 13 February 2001 Abstract The windstorm VIVIAN that severely aected progress towards ®ner scales in the horizontal, the ver- Switzerland in February 1990 has been investigated tical and the nesting frequency enhancement helps to using the Canadian Regional Climate Model (CRCM). simulate windspeed variability. However, the variability This winter stormwas characterised by a deep cyclone in within the larger domain is limited by the archival fre- the North Atlantic and by strong geopotential and quency of reanalysis data that cannot resolve distur- baroclinic north-south gradients in the troposphere over bances with time scale shorter than 12 h. Results show Western Europe resulting in high windspeeds in Swit- that while the model simulates well the synoptic-scale zerland. Our principal emphasis is to demonstrate the ¯ow at 60-kmresolution, cascade self-nesting is neces- ability of the CRCM to simulate the wind®eld intensity sary to capture ®ne-scale features of the topography that and patterns. In order to simulate winds at very high modulate the ¯ow that generate localised wind resolution we operate an optimal multiple self-nesting enhancement over Switzerland. with the CRCM in order to increase the horizontal and vertical resolution. The simulation starts with down- scaling NCEP-NCAR reanalyses at 60 kmwith 20 ver- tical levels, followed by an intermediate 5-km simulation 1 Introduction with 30 vertical levels nested in the former. -

Living with Storm Damage to Forests
What Science Living with Storm Can Tell Us Damage to Forests Barry Gardiner, Andreas Schuck, Mart-Jan Schelhaas, Christophe Orazio, Kristina Blennow and Bruce Nicoll (editors) What Science Can Tell Us 3 2013 What Science Can Tell Us Lauri Hetemäki, Editor-In-Chief Minna Korhonen, Managing Editor The editorial office can be contacted at [email protected] Layout: Kopijyvä Oy / Jouni Halonen Printing: Painotalo Seiska Oy Disclaimer: The views expressed in this publication are those of the authors and do not necessarily represent those of the European Forest Institute. ISBN: 978-952-5980-08-0 (printed) ISBN: 978-952-5980-09-7 (pdf) Living with Storm What Science Can Tell Us Damage to Forests Barry Gardiner, Andreas Schuck, Mart-Jan Schelhaas, Christophe Orazio, Kristina Blennow and Bruce Nicoll (editors) To the memory of Marie-Pierre Reviron Contents Contributing Authors and Drafting Committee .............................................................. 7 Foreword .............................................................................................................................9 Introduction ......................................................................................................................11 Barry Gardiner 1. Storm damage in Europe – an overview ......................................................................15 Andreas Schuck and Mart-Jan Schelhaas 2. Susceptibility to Wind Damage .................................................................................. 25 2.1. Airflow over forests ........................................................................................ -

Natural Catastrophes and Man-Made Disasters in 2016: a Year of Widespread Damages
No 2 /2017 Natural catastrophes and 01 Executive summary 02 Catastrophes in 2016: man-made disasters in 2016: global overview a year of widespread damages 06 Regional overview 13 Floods in the US – an underinsured risk 18 Tables for reporting year 2016 40 Terms and selection criteria Executive summary There were a number of expansive In terms of devastation wreaked, there were a number of large-scale disasters across disaster events in 2016 … the world in 2016, including earthquakes in Japan, Ecuador, Tanzania, Italy and New Zealand. There were also a number of severe floods in the US and across Europe and Asia, and a record high number of weather events in the US. The strongest was Hurricane Matthew, which became the first Category 5 storm to form over the North Atlantic since 2007, and which caused the largest loss of life – more than 700 victims, mostly in Haiti – of a single event in the year. Another expansive, and expensive, disaster was the wildfire that spread through Alberta and Saskatchewan in Canada from May to July. … leading to the highest level of overall In total, in sigma criteria terms, there were 327 disaster events in 2016, of which losses since 2012. 191 were natural catastrophes and 136 were man-made. Globally, approximately 11 000 people lost their lives or went missing in disasters. At USD 175 billion, total economic losses1 from disasters in 2016 were the highest since 2012, and a significant increase from USD 94 billion in 2015. As in the previous four years, Asia was hardest hit. The earthquake that hit Japan’s Kyushu Island inflicted the heaviest economic losses, estimated to be between USD 25 billion and USD 30 billion. -

The UK Wind Regime - Observational Trends and Extreme Event Analysis and Modelling
The UK wind regime - Observational trends and extreme event analysis and modelling Nick Earl This thesis is submitted in fulfilment of the requirements for the degree of Doctor of Philosophy at the University of East Anglia. School of Environmental Sciences June 2013 © This copy of the thesis has been supplied on condition that anyone who consults it is understood to recognise that its copyright rests with the author and that use of any information derived there from must be in accordance with current UK Copyright Law. In addition, any quotation or extract must include full attribution. 2 The UK wind regime - Observational trends and extreme event analysis and modelling Abstract The UK has one of the most variable wind climates; NW Europe as a whole is a challenging region for forecast- and climate-modelling alike. In Europe, strong winds within extra-tropical cyclones (ETCs) remain on average the most economically significant weather peril when averaged over multiple years, so an understanding how ETCs cause extreme surface winds and how these extremes vary over time is crucial. An assessment of the 1980-2010 UK wind regime is presented based on a unique 40- station network of 10m hourly mean windspeed and daily maximum gustspeed (DMGS) surface station measurements. The regime is assessed, in the context of longer- and larger-scale wind variability, in terms of temporal trends, seasonality, spatial variation, distribution and extremes. Annual mean windspeed ranged from 4.4 to 5.4 ms-1 (a 22% difference) with 2010 recording the lowest annual network mean windspeed over the period, attracting the attention of the insurance and wind energy sectors, both highly exposed to windspeed variations. -

Assessment of Impacts of Extreme Winter Storms on the Forest Resources in Baden-Württemberg - a Combined Spatial and System Dynamics Approach
Assessment of Impacts of Extreme Winter Storms on the Forest Resources in Baden-Württemberg - A Combined Spatial and System Dynamics Approach Zur Erlangung des akademischen Grades eines Doktors der Wirtschaftswissenschaften (Dr. rer. pol.) von der Fakultät für Wirtschaftswissenschaften des Karlsruher Instituts für Technologie (KIT) genehmigte DISSERTATION von (M.Sc.) Syed Monjur Murshed ______________________________________________________________ Tag der mündlichen Prüfung: 08.07.2016 Referent: Prof. Dr. Ute Werner Korreferent: Prof. Dr. Ute Karl Karlsruhe 21.11.2016 This document is licensed under the Creative Commons Attribution – Share Alike 3.0 DE License (CC BY-SA 3.0 DE): http://creativecommons.org/licenses/by-sa/3.0/de/ Acknowledgement First of all, I would like to express my profound gratitude to my thesis supervisor Prof. Dr. Ute Werner for her excellent guidance, patience, granting the consent to explore the research topics on my own, as well as providing thoughtful advice throughout the long journey of this thesis. I am also grateful to Prof. Dr. Ute Karl for providing suggestions on the improvement of the manuscript and agreeing to co‐ supervise the thesis. I wish to further thank numerous present and past colleagues in the European Institute for Energy Research (EIFER) and Électricité de France (EDF SA) for their encouragement and support. My particular gratitude towards Ludmilla Gauter, Nurten Avci, Andreas Koch, Jean Copreaux, Pablo Viejo for their belief in me and allowing me to attend seminars at the university, as well as allocating dedicated time to work on the thesis. Susanne Schmidt, Francisco Marzabal gave valuable insights into the system dynamics modelling approach and its formulation, for which I am extremely grateful. -

Sigma 2/2017
No 2 /2017 Natural catastrophes and 01 Executive summary 02 Catastrophes in 2016: man-made disasters in 2016: global overview a year of widespread damages 06 Regional overview 13 Floods in the US – an underinsured risk 18 Tables for reporting year 2016 40 Terms and selection criteria Executive summary There were a number of expansive In terms of devastation wreaked, there were a number of large-scale disasters across disaster events in 2016 … the world in 2016, including earthquakes in Japan, Ecuador, Tanzania, Italy and New Zealand. There were also a number of severe floods in the US and across Europe and Asia, and a record high number of weather events in the US. The strongest was Hurricane Matthew, which became the first Category 5 storm to form over the North Atlantic since 2007, and which caused the largest loss of life – more than 700 victims, mostly in Haiti – of a single event in the year. Another expansive, and expensive, disaster was the wildfire that spread through Alberta and Saskatchewan in Canada from May to July. … leading to the highest level of overall In total, in sigma criteria terms, there were 327 disaster events in 2016, of which losses since 2012. 191 were natural catastrophes and 136 were man-made. Globally, approximately 11 000 people lost their lives or went missing in disasters. At USD 175 billion, total economic losses1 from disasters in 2016 were the highest since 2012, and a significant increase from USD 94 billion in 2015. As in the previous four years, Asia was hardest hit. The earthquake that hit Japan’s Kyushu Island inflicted the heaviest economic losses, estimated to be between USD 25 billion and USD 30 billion. -

Dead Wood in Managed Forests
DEAD WOOD IN MANAGED FORESTS: HOW MUCH AND HOW MUCH IS ENOUGH? Development of a Snag Quantification Method by Remote Sensing & GIS and Snag Targets Based on Three-toed Woodpeckers' Habitat Requirements THÈSE NO 2761 (2003) PRÉSENTÉE À LA FACULTÉ ENVIRONNEMENT NATUREL, ARCHITECTURAL ET CONSTRUIT Institut des sciences et technologies de l'environnement SECTION DES SCIENCES ET DE L'INGÉNIERIE DE L'ENVIRONNEMENT ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE POUR L'OBTENTION DU GRADE DE DOCTEUR ÈS SCIENCES PAR Rita BÜTLER SAUVAIN Sekundarlehrer-Diplom mathematisch-naturwissenschaftlicher Richtung, Pädagogische Hochschule St.Gallen de nationalité suisse et originaire de Hünenberg (ZG) et Grandval (BE) acceptée sur proposition du jury: Prof. R. Schlaepfer, directeur de thèse Prof. P. Angelstam, rapporteur Dr M. Bolliger, rapporteur Prof. H. Harms, rapporteur Dr C. Neet, rapporteur Lausanne, EPFL 2003 Another point of view on PhD research…. • Number of field days 104 • Number of measured dead trees 1812 • Fully inventoried forest area (each tree) 61 ha • Number of photo-interpreted and digitised dead trees 8’222 • Distance walked in order to reach sampling points for 478 km measurements • Working files 2’569 Mo i Contents Preface iv Abstract vi Version abrégée viii Kurzfassung xi PART A : SYNTHESIS 1. STUDY BACKGROUND 1 1.1. Sustainable management, biodiversity, criteria and indicators 1 1.2. “Dead wood” indicator not yet operational 3 2. AIMS OF THE STUDY 5 2.1. Conceptual and methodological design 5 2.2. Axioms and postulates 8 2.3. Specific objectives 9 3. MATERIAL AND METHODS 11 3.1. Study sites 11 3.2. Gathering of dead-wood data 11 3.3. -

The Spatial Structure of European Wind Storms As Characterized by Bivariate Extreme-Value Copulas
Nat. Hazards Earth Syst. Sci., 12, 1769–1782, 2012 www.nat-hazards-earth-syst-sci.net/12/1769/2012/ Natural Hazards doi:10.5194/nhess-12-1769-2012 and Earth © Author(s) 2012. CC Attribution 3.0 License. System Sciences The spatial structure of European wind storms as characterized by bivariate extreme-value Copulas A. Bonazzi, S. Cusack, C. Mitas, and S. Jewson Risk Management Solutions, Peninsular House, 30 Monument Street, London, UK Correspondence to: A. Bonazzi ([email protected]) Received: 20 October 2011 – Revised: 4 March 2012 – Accepted: 30 March 2012 – Published: 29 May 2012 Abstract. The winds associated with extra-tropical cy- Re’s NATHAN database trended to 2008 values by Barredo, clones are amongst the costliest natural perils in Europe. 2010). Barredo (2010) and Klawa and Ulbrich (2003) show Re/insurance companies typically have insured exposure at evidence that this storm severity is combined with a fre- multiple locations and hence the losses they incur from any quency to produce large average annual losses. These sig- individual storm crucially depend on that storm’s spatial nificant impacts from European windstorms generate much structure. Motivated by this, this study investigates the spa- interest in risk management. tial structure of the most extreme windstorms in Europe. The Probabilistic risk assessment is generally based on the con- data consists of a carefully constructed set of 135 of the most volution of hazard, vulnerability, and economic or insured damaging storms in the period 1972–2010. Extreme value exposure (Petak and Atkisson, 1982). Applications of risk copulas are applied to this data to investigate the spatial de- management require information on extreme events to an- pendencies of gusts. -

Assessing Forest Windthrow Damage Using Single-Date, Post-Event Airborne Laser Scanning Data
Forestry An International Journal of Forest Research Forestry 2018; 91,27–37, doi:10.1093/forestry/cpx029 Advance Access publication 6 July 2017 Assessing forest windthrow damage using single-date, post-event airborne laser scanning data Gherardo Chirici1,2, Francesca Bottalico1, Francesca Giannetti1*, Barbara Del Perugia1, Davide Travaglini1, Susanna Nocentini1,2, Erico Kutchartt3, Enrico Marchi1, Cristiano Foderi1, Marco Fioravanti1, Lorenzo Fattorini4, Lorenzo Bottai5, Ronald E. McRoberts6, Erik Næsset7, Piermaria Corona8 and Bernardo Gozzini5 1Dipartimento di Gestione dei Sistemi Agrari, Alimentari e Forestali – GESAAF, Università degli Studi di Firenze, Via San Bonaventura, 13, 50145 Firenze, Italy 2Accademia Italiana di Scienze Forestali, P.zza Edison 11, 50133 Firenze, Italy 3Department of Forest Management and Applied Geoinformatics – FMAG, Mendel University, Zemìdìlská 3, 61300 Brno, Czech Republic 4Department of Economics and Statistics, University of Siena, P.za S. Francesco, 8, 53100 Siena, Italy 5Consorzio LaMMA, Via Madonna del Piano, 10, 50019 Sesto Fiorentino (FI), Italy 6Northern Research Station, Forest Inventory & Analysis, U.S. Forest Service, 1992 Folwell Ave, Saint Paul, MN 55108, USA 7Department of Ecology and Natural Resource Management, Norwegian University of Life Sciences, P.O. Box 5003, 1432 Ås, Norway 8Consiglio per la ricerca in agricoltura e l’analisi dell’economia agraria, Forestry Research Centre (CREA-SEL), Viale Santa Margherita 80, 50100 Arezzo, Italy *Corresponding author. E-mail: francesca.giannetti@unifi.it Received 20 November 2016 One of many possible climate change effects in temperate areas is the increase of frequency and severity of windstorms; thus, fast and cost efficient new methods are needed to evaluate wind-induced damages in for- ests.