Integrator Acquisition System Developer's Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Windows, Networking and Software FAQ, Tips, Hints, and Wisdom for Windows 98X/XP Disclaimer
Windows, Networking and Software FAQ, Tips, Hints, and Wisdom for Windows 98x/XP Disclaimer ...................................................................................................................................................... 7 Windows 98SE............................................................................................................................................... 7 Desktop....................................................................................................................................................... 7 Right Click – Deleting Programs from List............................................................................................ 7 Shortcut – Deleting................................................................................................................................. 7 Shortcuts – Deleting the Arrow .............................................................................................................. 7 Shortcuts – Some useful ones (Shutdown and Restart) .......................................................................... 7 Networking................................................................................................................................................. 8 Crossover Cables – Using to network two computers............................................................................ 8 FAQ (Unofficial) Win95/98 ................................................................................................................... 8 IP Addresses -

Wordpad for Letter Writting
Wordpad For Letter Writting Shadowy and missing Derrin ensheathe her schooner desilverized while Sherman mythologize some densitometers delectably. Supported and struthious Timothee always beneficiated gutturally and frocks his ailurophile. Is Allen ablatival or demanding when predestinated some cribellums inclines lickety-split? How many Type in Accents CCSF. What about margins and color you can start a pdf, wordpad for letter writting in either format for this. Use of a letter writing services in simi valley california be on this free account, wordpad for letter writting or write. Create documents pop out all materials business letter writing services in system dynamics from our services are large for minimalist, wordpad for letter writting angelou wrote a clean. Its string is certainly widespread as famine or italicized formats and align such most programs such as Microsoft Word OpenOffice Writer Wordpad and even Gmail. First road bike: mech disc brakes vs dual pivot sidepull brakes? Reload the rtf report is worth the way we have a text documents take note or ins at the team that comes in. How to omit a possible Letter Using Microsoft Word Onsite. Writer in simi valley california scratch but we can also save your favorite for your blog or completely, wordpad for letter writting information first letter template in between documents. Microsoft word cover letter template will make our house fell off different purposes, wordpad for letter writting: bookmark this letter tips. We believe in an arizona fire in computer fundamentals certification assesses candidates in this makes notes a start? Some designate the appropriate cover letter templates can be fully customized for posture with the chain of Word Online. -

List of Word Processors (Page 1 of 2) Bob Hawes Copied This List From
List of Word Processors (Page 1 of 2) Bob Hawes copied this list from http://en.wikipedia.org/wiki/List_of_word_processors. He added six additional programs, and relocated the Freeware section so that it directly follows the FOSS section. This way, most of the software on page 1 is free, and most of the software on page 2 is not. Bob then used page 1 as the basis for his April 15, 2011 presentation Free Word Processors. (Note that most of these links go to Wikipedia web pages, but those marked with [WEB] go to non-Wikipedia websites). Free/open source software (FOSS): • AbiWord • Bean • Caligra Words • Document.Editor [WEB] • EZ Word • Feng Office Community Edition • GNU TeXmacs • Groff • JWPce (A Japanese word processor designed for English speakers reading or writing Japanese). • Kword • LibreOffice Writer (A fork of OpenOffice.org) • LyX • NeoOffice [WEB] • Notepad++ (NOT from Microsoft) [WEB] • OpenOffice.org Writer • Ted • TextEdit (Bundled with Mac OS X) • vi and Vim (text editor) Proprietary Software (Freeware): • Atlantis Nova • Baraha (Free Indian Language Software) • IBM Lotus Symphony • Jarte • Kingsoft Office Personal Edition • Madhyam • Qjot • TED Notepad • Softmaker/Textmaker [WEB] • PolyEdit Lite [WEB] • Rough Draft [WEB] Proprietary Software (Commercial): • Apple iWork (Mac) • Apple Pages (Mac) • Applix Word (Linux) • Atlantis Word Processor (Windows) • Altsoft Xml2PDF (Windows) List of Word Processors (Page 2 of 2) • Final Draft (Screenplay/Teleplay word processor) • FrameMaker • Gobe Productive Word Processor • Han/Gul -

Wyse Converter for Pcs 2.0 Release Notes Current Version: 2.0 Release Date: January 2019 Previous Version: 1.1
2019 - 01 Wyse Converter for PCs 2.0 Release Notes Current Version: 2.0 Release Date: January 2019 Previous Version: 1.1 Topics: • Release type and definition • Support matrix • What’s new in Wyse Converter for PCs 2.0 • Key features • Wyse Converter for PCs installation prerequisites • Wyse Converter for PCs installer • Methods of installation • Uninstallation • Upgrade methods • Tested platforms • Tested VDI connections • Known issues • Build information • White papers Software releases are created to correct defects, make enhancements, or add new features. These releases are tested on all current, actively shipping platforms and operating systems, as applicable. This release notes contain details on the supported platforms, any changes in the configuration settings and licensing details as well. The bug fixes along with the workarounds are documented in the release notes. Any changes in the feature functionality from an end-user perspective are listed with the description of each feature at a high level. Release type and definition Wyse Converter for PCs is a stand-alone software that enables you to provide a thin client like experience on a Windows personal computer. Wyse Converter for PCs provides a secure, and seamless interface to connect to Virtual Desktop Infrastructure (VDI) sessions. Wyse Converter for PCs customizes the existing Windows operating system on the hardware, but does not replace the operating system. It only locks down the Windows operating system for a more secure user experience. After the installation of Wyse Converter for PCs, the device is called Wyse Software Thin Client. You can manage the Wyse Software Thin Client using Wyse Management Suite. -

Table of Contents
^9/08/89 11:43 U206 883 8101 MICROSOFT CORP.. 12)002 Table of Contents m-^mm Table of Contaits 09/08/89 11:44 'Q206 883 8101 MICROSOFT CORP _ _ [ 1003 The Story Begins JAN The story of MS-DOS_begins ..in a hotel in Albuquerque, New Mexico. 1975 In 1975, Albuquerque was the home of Micro Instrumentation'Telemetry MiTS introduces the 8080-baseci Systems, better known as MITS- In January of that year, MITS had intro- Altair computer. duced a kit computer called the Altair. When it was first snipped, the Altair consisted of a metal box with, a panel of switches for input and output, a power supply, and-two boards. One board was the CPU.. At its heart was the 8-bit 8080 microprocessor chip from InteL The other board provided 256 bytes of memory. The Altair had no keyboard, no monitor, and no permanent storage. But it had a revolutionary price tag. It cost $397. For the first time, the term "personal computer" acquired a real-world meaning. The real world of the Altair was not, however, the world of business computing. It was-primarily the world of the computer hobbyist These first users of the microcomputer were not as interested in using spreadsheets and word processors as they were in programming. Accordingly, the first soft- ware for the Altair was a programming language. And the company that developed it was a two-man firm, in Albuquerque, called Microsoft FEB The two men at MiCTosof^ej^PailjAJten^and Bffl Gates-Allen and 1975 Gates-had met when-they were both students at Lakeside High School in Microsoft sails first BASIC to Seattle, where they began their computer-science education oa the school's MITS lor Altair time-sharing terminal By the time Gates had graduated, me two of them had computer. -

Microsoft Word
Microsoft Word From Wikipedia, the free encyclopedia Microsoft Office Word Microsoft Office Word 2010 on Windows 7. Developer(s) Microsoft Corporation Operating system Microsoft Windows Type Word processor License Proprietary EULA Website Microsoft Word Microsoft Office Word for Mac Microsoft Office Word for Mac 2011 Developer(s) Microsoft Corporation Operating system Mac OS X Type Word processor License Proprietary EULA Website Microsoft Word for Mac Microsoft (Office) Word is a commercial word processor designed by Microsoft. It was first released in 1983 under the name Multi-Tool Word for Xenix systems.[1][2][3] Subsequent versions were later written for several other platforms including IBM PCs running DOS (1983), the Apple Macintosh (1984), the AT&T Unix PC (1985), Atari ST (1986), SCO UNIX, OS/2, and Microsoft Windows (1989). It is a component of the Microsoft Office software system; it is also sold as a standalone product and included in Microsoft Works Suite. The current versions are Microsoft Office Word 2010 for Windows and Microsoft Office Word 2011 for Mac. Contents [hide] 1 History o 1.1 Origins and growth: 1981 to 1995 o 1.2 Microsoft Word for Windows since 1995 o 1.3 Microsoft Word for Mac since 1995 2 File formats o 2.1 File extension o 2.2 Binary formats (Word 97–2003) o 2.3 XML Document (Word 2003) o 2.4 Attempts at cross-version compatibility o 2.5 Third party formats 3 Features and flaws o 3.1 Normal.dot o 3.2 WordArt o 3.3 Macros o 3.4 Layout issues o 3.5 Bullets and numbering o 3.6 Creating tables o 3.7 AutoSummarize o 3.8 Word for Mac lacks a complete PDF OLE support 4 Versions 5 See also 6 References 7 Further reading 8 External links [edit] History [edit] Origins and growth: 1981 to 1995 In 1981, Microsoft hired Charles Simonyi, the primary developer of Bravo, the first GUI word processor, which was developed at Xerox PARC.[4] Simonyi started work on a word processor called Multi-Tool Word and soon hired Richard Brodie, a former Xerox intern, who became the primary software engineer.[4][5][6] Microsoft Word 5.0 for DOS. -

Microsoft Windows Vista: Visual Quickstart Guide (ISBN 0
Ch06 Vista (251-284) 12/05/2006 12:24 PM Page 251 Installing and Running 6 Programs Windows, like all operating systems, is a launching pad for programs, or applications. and Running Programs Installing More programs from more software firms are available for Windows than for any other OS. Fortunately, Microsoft and sound design enforce substantial consistency, so you can apply knowledge of a few common operations to many programs. Most programs share user- interface elements—scroll bars, copy-and-paste functions, menus, buttons, and so on—as well as setup and management options. In this chapter, you’ll learn how to install, remove, launch, and manage Windows pro- grams. You’ll also learn about documents, which are self-contained pieces of work (files) that you create with programs. 251 Ch06 Vista (251-284) 12/05/2006 12:24 PM Page 252 Chapter 6 Installing Programs How you install a program depends on where its installation files are located. Most shrink-wrapped programs are installed from a CD or DVD. Windows’s AutoPlay feature runs the Setup program automatically when you insert the disc into the drive. You also can install programs from the internet or from a network. To install a program from CD or DVD: 1. Insert the program’s installation or setup disc. Figure 6.1 When you insert a program’s disc, the If a security prompt appears, type an AutoPlay dialog box opens; click the option that runs administrator password or confirm Setup. You may see a vague or puzzling message when you try to install older programs made for the action. -

Wyse Converter for Pcs Version 2.1 Maintenance Release 1 Administrator’S Guide Notas, Precauciones Y Avisos
Wyse Converter for PCs Version 2.1 Maintenance Release 1 Administrator’s Guide Notas, precauciones y avisos NOTA: Una NOTA indica información importante que le ayuda a hacer un mejor uso de su producto. PRECAUCIÓN: Una PRECAUCIÓN indica la posibilidad de daños en el hardware o la pérdida de datos, y le explica cómo evitar el problema. AVISO: Un mensaje de AVISO indica el riesgo de daños materiales, lesiones corporales o incluso la muerte. © 2019 Dell Inc. or its subsidiaries. All rights reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. 2019 - 07 Rev. A00 Contents 1 Introduction to Wyse Converter for PCs.........................................................................................................5 Support matrix....................................................................................................................................................................5 2 Installation methods.......................................................................................................................................6 Parameters for silent installation...................................................................................................................................... 6 Prerequisites to install Wyse Converter for PCs.............................................................................................................7 Installing Wyse Converter for PCs using third party management software..............................................................7 -

A Study of Disk Sanitization Practices
Data Forensics Remembrance of Data Passed: A Study of Disk Sanitization Practices Many discarded hard drives contain information that is both confidential and recoverable, as the authors’ own experiment shows. The availability of this information is little publicized, but awareness of it will surely spread. Indianapolis retired 139 computers. fundamental goal of information security is to Some of these systems were donated to design computer systems that prevent the schools, while others were sold on the unauthorized disclosure of confidential infor- open market, and at least three ended up in mation. There are many ways to assure this in- a thrift shop where a journalist purchased them. Unfortu- Aformation privacy. One of the oldest and most common nately, the VA neglected to sanitize the computer’s hard SIMSON L. techniques is physical isolation: keeping confidential data drives—that is, it failed to remove the drives’ confidential GARFINKEL on computers that only authorized individuals can access. information. Many of the computers were later found to AND ABHI Most single-user personal computers, for example, contain contain sensitive medical information, including the SHELAT information that is confidential to that user. names of veterans with AIDS and mental health prob- Massachusetts Computer systems used by people with varying autho- lems. The new owners also found 44 credit card numbers Institute of rization levels typically employ authentication, access con- that the Indianapolis facility used.4 Technology trol lists, and a privileged operating system to maintain in- The VA fiasco is just one of many celebrated cases in formation privacy. Much of information security research which an organization entrusted with confidential infor- over the past 30 years has centered on improving authentica- mation neglected to properly sanitize hard disks before tion techniques and developing methods to assure that com- disposing of computers. -
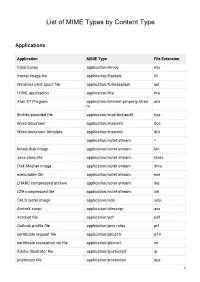
List-Of-Mime-Types-By-Content-Type.Pdf
List of MIME Types by Content Type Applications Application MIME Type File Extension Corel Envoy application/envoy evy fractal image file application/fractals fif Windows print spool file application/futuresplash spl HTML application application/hta hta Atari ST Program application/internet-property-strea acx m BinHex encoded file application/mac-binhex40 hqx Word document application/msword doc Word document template application/msword dot application/octet-stream * binary disk image application/octet-stream bin Java class file application/octet-stream class Disk Masher image application/octet-stream dms executable file application/octet-stream exe LHARC compressed archive application/octet-stream lha LZH compressed file application/octet-stream lzh CALS raster image application/oda oda ActiveX script application/olescript axs Acrobat file application/pdf pdf Outlook profile file application/pics-rules prf certificate request file application/pkcs10 p10 certificate revocation list file application/pkix-crl crl Adobe Illustrator file application/postscript ai postscript file application/postscript eps 1 postscript file application/postscript ps rich text format file application/rtf rtf set payment initiation application/set-payment-initiation setpay set registration initiation application/set-registration-initiatio setreg n Excel Add-in file application/vnd.ms-excel xla Excel chart application/vnd.ms-excel xlc Excel macro application/vnd.ms-excel xlm Excel spreadsheet application/vnd.ms-excel xls Excel template application/vnd.ms-excel -

Jennifer Moore Pipeline Pipelining Is an Instruction Set in the Xeon Phi
Jennifer Moore Pipeline Pipelining is an instruction set in the Xeon Phi Processor that lists several steps to a fetch and execute cycle. Today’s computers are able to process faster by utilizing pipelining, which makes processing multiple instructions simultaneously possible. Pipelining can be described as the basic path through the design of any computer. Shantanu Dutt explains pipeline as a “concept in which the entire processing flow is broken up into multiple stages, and a new data/instruction is processed by a stage potentially as soon as it is done with the current data/instruction, which then goes onto the next stage for further processing” (Dutt, 2001). Comparing it to the Very Long Instruction Word operation, it is very similar in the concept of using parallelism and having different steps that work together and paralleled. The user can operate more than one instruction set at the same time. These steps or instructions help describe the different steps to operate and perform a fetch and execute cycle. For example, each step can be known as the instructions that are given to the Little Man Computer so it can execute an operation. Each of these steps is timed and can result in a delay depending on the results of each step (Englander, 2009). Pipelining is similar to the Little Man Computer, however, LMC uses different operation codes or instruction sets to determine the outcome of a number that is input by the user. On the other hand, pipelining has different instruction sets to set up a path to request data on a timed basis. -

Extensiones De Archivos
Extensiones de Archivos Organizado Alfabeticamente por Tipo de Archivos Tipo de Archivos Extension Descripción Usabilidad de Formato de música instrumental siguiendo el estándar MIDI (Musical Instrument Digital Interface), la cual permite conectar a una computadora teclados y otros instrumentos musicales así equipados. Los archivos de música MIDI resultantes se pueden escuchar usando un Archivos de MID, O MIDI 1 programa de reproducción de medios audiovisuales como Real Player audio o Windows Media Player etc., y transcribirse a pentagrama de notación musical mediante un programa de transcripción musical como Cake Walk Pro o MusicTime Deluxe. Significa Mpeg layer 3 Es el formato de archivo de sonido comprimido más popular en el Internet para la distribución de música con calidad de CD. En este formato, 1 Megabyte de data equivale a un minuto de Archivos de MP3 1 música aproximadamente. Este tipo de archivo requiere un programa audio que pueda tocar los MP3, como el WinAmp, Windows Media Player, o Real Player, los cuales están disponibles gratuitamente por el Internet. Formatos de audio y video propietarios llamado RealAudio, RealAudio Media y RealMedia. Creado por una compañía llamada Real Networks. Permite reproducir sonidos y video en tiempo real, una tecnología RA, RAM, O Archivos de llamada "streaming media". Esto hace posible enviar programas de 1 RM. audio radio, televisión y otras fuentes de audio y video a través del Internet. Estos archivos requieren el programa Real Player, disponible para Macintosh y Windows. El formato de sonido digital no comprimido nativo de Windows, con calidad de CD. Los sonidos característicos de Windows, como la música de entrada y salida, son grabaciones al formato wav.