Emotion Perception and Recognition: an Exploration of Cultural Differences and Similarities
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
T/HIS 15.0 User Manual
For help and support from Oasys Ltd please contact: UK The Arup Campus Blythe Valley Park Solihull B90 8AE United Kingdom Tel: +44 121 213 3399 Email: [email protected] China Arup 39/F-41/F Huaihai Plaza 1045 Huaihai Road (M) Xuhui District Shanghai 200031 China Tel: +86 21 3118 8875 Email: [email protected] India Arup Ananth Info Park Hi-Tec City Madhapur Phase-II Hyderabad 500 081, Telangana India Tel: +91 40 44369797 / 98 Email: [email protected] Web:www.arup.com/dyna or contact your local Oasys Ltd distributor. LS-DYNA, LS-OPT and LS-PrePost are registered trademarks of Livermore Software Technology Corporation User manual Version 15.0, May 2018 T/HIS 0 Preamble 0.1 Text conventions used in this manual 0.1 1 Introduction 1.1 1.1 Program Limits 1.1 1.2 Running T/HIS 1.2 1.3 Command Line Options 1.4 2 Using Screen Menus 2.1 2.1 Basic screen menu layout 2.1 2.2 Mouse and keyboard usage for screen-menu interface 2.2 2.3 Dialogue input in the screen menu interface 2.4 2.4 Window management in the screen interface 2.4 2.5 Dynamic Viewing (Using the mouse to change views). 2.5 2.6 "Tool Bar" Options 2.6 3 Graphs and Pages 3.1 3.1 Creating Graphs 3.1 3.2 Page Size 3.2 3.3 Page Layouts 3.2 3.3.1 Automatic Page Layout 3.2 3.4 Pages 3.6 3.5 Active Graphs 3.6 4 Global Commands and Pages 4.1 4.1 Page Number 4.1 4.2 PLOT (PL) 4.1 4.3 POINT (PT) 4.2 4.4 CLEAR (CL) 4.2 4.5 ZOOM (ZM) 4.2 4.6 AUTOSCALE (AU) 4.2 4.7 CENTRE (CE) 4.2 4.8 MANUAL 4.2 4.9 STOP 4.2 4.10 TIDY 4.2 4.11 Additional Commands 4.3 5 Main Menu 5.1 5.0 Selecting Curves -
Classic Filters There Are 4 Classic Analogue Filter Types: Butterworth, Chebyshev, Elliptic and Bessel. There Is No Ideal Filter
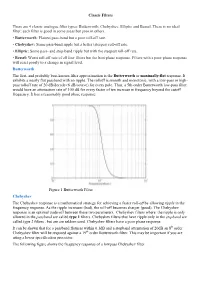
Classic Filters There are 4 classic analogue filter types: Butterworth, Chebyshev, Elliptic and Bessel. There is no ideal filter; each filter is good in some areas but poor in others. • Butterworth: Flattest pass-band but a poor roll-off rate. • Chebyshev: Some pass-band ripple but a better (steeper) roll-off rate. • Elliptic: Some pass- and stop-band ripple but with the steepest roll-off rate. • Bessel: Worst roll-off rate of all four filters but the best phase response. Filters with a poor phase response will react poorly to a change in signal level. Butterworth The first, and probably best-known filter approximation is the Butterworth or maximally-flat response. It exhibits a nearly flat passband with no ripple. The rolloff is smooth and monotonic, with a low-pass or high- pass rolloff rate of 20 dB/decade (6 dB/octave) for every pole. Thus, a 5th-order Butterworth low-pass filter would have an attenuation rate of 100 dB for every factor of ten increase in frequency beyond the cutoff frequency. It has a reasonably good phase response. Figure 1 Butterworth Filter Chebyshev The Chebyshev response is a mathematical strategy for achieving a faster roll-off by allowing ripple in the frequency response. As the ripple increases (bad), the roll-off becomes sharper (good). The Chebyshev response is an optimal trade-off between these two parameters. Chebyshev filters where the ripple is only allowed in the passband are called type 1 filters. Chebyshev filters that have ripple only in the stopband are called type 2 filters , but are are seldom used. -

Comparison of a Low-Frequency Butterworth Filter with a Symmetric SE-Filter
Comparison of a low-frequency Butterworth filter with a symmetric SE-filter K S Medvedeva1 1Saratov State University, Astrakhanskaya Street 83, Saratov, Russia, 410012 Abstract. The article compares two filters: a Butterworth filter and an asymmetric SE- filter.The experimental studydetermines their advantages and disadvantages.Also,experiments based on the peak signal-to-noise ratio(PSNR) metricshowvisual evaluation. The results of experimentsshow that a symmetric filter better restores images usinga small set of continuous function parametersthatare distorted by a low-frequency Gaussian filter. 1. Introduction Due to the imperfection of forming and recording systems, images recorded by systemsare distorted (fuzzy) copiesof the original images. The main causes of distortions that resultindegradation of clarity includethe limited resolution of the forming system, refocusing, the presence of a distorting medium (for example, the atmosphere), and movement of the camera on the object being registered. Eliminating or reducing distortion for clarity is the task of image recovery. Automatic control systems, measuring equipment, signal processing systems, and various filters with different characteristics are used to filter signalsin telecommunications. Depending on the frequency band associated with the bandwidth and the suppression band, there are odd, band, high- frequency, and low-frequency filters. Also, all-pass filters have a constant amplitude-frequency response in the required frequency range, and their phase-frequency response is a given frequency function [1]. The simplest way to restoreimage clarity is to process the observed image in the spatial frequency domain with an inverse filter [2].The drawbacks of this filter are the occurrence of edge effects, which take the form of an oscillating hindrance of high power that completely masksthe reconstructed image. -

Introduction to Signals & Systems
A very Brief Introduction to Signals & Systems Outline • Signals & Systems • Continuous and discrete time signals • Properties of Systems • Input- Output relation : Convolution • Frequency domain representation of signals & systems • Analog to digital Conversion • Sampling – Nyquist Sampling Theorem • Basic Filter Theory • Types of filters • Designing practical filters in Labview and Matlab • What is a signal? – A signal is a function defined on the continuum of time values • What is a system ? – a system is a black box that “takes in” one or more input signals and “produces” one or more output signals Continuous time Vs Discrete time Signals • Most of the modern day systems are discrete time systems. E.g., A computer. • A computer can’t directly process a continuous time signal but instead it needs a stream of numbers, which is a discrete time signal. • Discrete time signals are obtain by sampling the continuous time signals • How fast should we sample the signal? Examples • Signals – Unit Step function – Continuous time impulse function – Discrete time • Systems – A simple circuit Basic System Properties • Linearity – System is linear if the principle of superposition holds • Time- Invariance – The system does not change with time Convolution • Linear & Time invariant (LTI) sytems are characterized by their impulse response • Impulse response is the output of the system when the input to the system is an impulse function • For Continuous time signals • For Discrete time signals Frequency domain representation of signals • In most of -

Butterworth Filter
Experiment / Circuit Simulation 0 Butterworth Filters All pages have been marked “for evaluation only” to prevent unauthorized use while still allowing customers to evaluate them for suitability in their courses. Your patience in recognizing this necessity is sincerely appreciated. All stamps are removed before your custom manual is paginated and printed. Objectives © 2002, Formulations Media Inc. 1. To use basic filter circuits to design multi-order filter response. 2. To recognize the interchangeability of components to alter design and create high pass or low pass filters. 3. To apply Butterworth polynomial coefficients in the design of filters. 4. To control operational amplifier gain in filter circuits where the gain is often critical to proper design. 5. To cascade filters to create different characteristics than exist with the individual filters. 6. To simulate various multi-order filters using Electronics Workbench™ software running in a Macintosh™ or Windows™ environment, or other similar software. Equipment 8 Resistors: 680 W (2), 3.3 kW (2), 5.6 kW (2), 68 kW (2) 4 Capacitors: 47 nF (4) 2 LM741 Operational Amplifiers Information There are a number of different multi-order filter circuit configurations, one of which is Butterworth. Amulti-order filter is one which has slope rates exceeding ±20 dB/decade. Athird order filter, for example, will have a slope rate of ±60 dB/decade. At the filter break frequency or critical frequency, fc, the filter response may be peaked or attenuated, depending on the circuit damping factor, zeta (z). The effects of z will not be considered in this experiment as z will be set to 0.707, thus providing -3 dB response at the critical frequency. -

And Elliptic Filter for Speech Signal Analysis Design And
Design and Implementation of Butterworth, Chebyshev-I and Elliptic Filter for Speech Signal Analysis Prajoy Podder Md. Mehedi Hasan Md.Rafiqul Islam Department of ECE Department of ECE Department of EEE Khulna University of Khulna University of Khulna University of Engineering & Technology Engineering & Technology Engineering & Technology Khulna-9203, Bangladesh Khulna-9203, Bangladesh Khulna-9203, Bangladesh Mursalin Sayeed Department of EEE Khulna University of Engineering & Technology Khulna-9203, Bangladesh ABSTRACT and IIR filter. Analog electronic filters consisted of resistors, In the field of digital signal processing, the function of a filter capacitors and inductors are normally IIR filters [2]. On the is to remove unwanted parts of the signal such as random other hand, discrete-time filters (usually digital filters) based noise that is also undesirable. To remove noise from the on a tapped delay line that employs no feedback are speech signal transmission or to extract useful parts of the essentially FIR filters. The capacitors (or inductors) in the signal such as the components lying within a certain analog filter have a "memory" and their internal state never frequency range. Filters are broadly used in signal processing completely relaxes following an impulse. But after an impulse and communication systems in applications such as channel response has reached the end of the tapped delay line, the equalization, noise reduction, radar, audio processing, speech system has no further memory of that impulse. As a result, it signal processing, video processing, biomedical signal has returned to its initial state. Its impulse response beyond processing that is noisy ECG, EEG, EMG signal filtering, that point is exactly zero. -

Design, Implementation, Comparison, and Performance Analysis Between Analog Butterworth and Chebyshev-I Low Pass Filter Using Approximation, Python and Proteus
Design, Implementation, Comparison, and Performance analysis between Analog Butterworth and Chebyshev-I Low Pass Filter Using Approximation, Python and Proteus Navid Fazle Rabbi ( [email protected] ) Islamic University of Technology https://orcid.org/0000-0001-5085-2488 Research Article Keywords: Filter Design, Butterworth Filter, Chebyshev-I Filter Posted Date: February 16th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-220218/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Journal of Signal Processing Systems manuscript No. (will be inserted by the editor) Design, Implementation, Comparison, and Performance analysis between Analog Butterworth and Chebyshev-I Low Pass Filter Using Approximation, Python and Proteus Navid Fazle Rabbi Received: 24 January, 2021 / Accepted: date Abstract Filters are broadly used in signal processing and communication systems in noise reduction. Butterworth, Chebyshev-I Analog Low Pass Filters are developed and implemented in this paper. The filters are manually calculated using approximations and verified using Python Programming Language. Filters are also simulated in Proteus 8 Professional and implemented in the Hardware Lab using the necessary components. This paper also denotes the comparison and performance analysis of filters using Manual Computations, Hardware, and Software. Keywords Filter Design · Butterworth Filter · Chebyshev-I Filter 1 Introduction Filters play a crucial role in the field of digital and analog signal processing and communication networks. The standard analog filter architecture consists of two main components: the problem of approximation and the problem of synthesis. The primary purpose is to limit the signal to the specified frequency band or channel, or to model the input-output relationship of a specific device.[20][12] This paper revolves around the following two analog filters: – Butterworth Low Pass Filter – Chebyshev-I Low Pass Filter These filters play an essential role in alleviating unwanted signal parts. -

Designing Passive Filter Using Butterworth Filter Technique
International Journal of Electronic and Electrical Engineering. ISSN 0974-2174 Volume 8, Number 1 (2015), pp. 57-65 © International Research Publication House http://www.irphouse.com Designing Passive Filter Using Butterworth Filter Technique Zubair S. Nadaph* and Vijay Mohale# *UG Student, Electrical Engineering, Walchand College of Engineering, Vishrambag, Sangli, Maharashtra- 416415 , India) E-mail: [email protected] # Assitant Professor, Electrical Engineering, Walchand College of Engineering, Vishrambag, Sangli, Maharashtra-416415, India) E-mail: [email protected] Abstract— Harmonics and its mitigation technique are headache for most of the power engineers for the obvious reasons; its adverse effects on power system. In power system, various techniques exist for mitigation, but most of them are based on the study of harmonic pattern at the site. Beside this, there is no passive filter design for ASDs (Automatic Speed Drives). This paper focuses on filter design technique based on Butterworth filter. It does not need any prior study of harmonics at the site. It is applicable for both VFDs (Variable Frequency Drives) and PCCs (Point of Common Coupling). Butterworth filter provides perfect mitigation technique bringing THD (Total Harmonic Distortion) well fewer than 5%. This paper mostly focuses on mathematical tools of Butterworth filter. But it also provides software analysis of design. Keywords—Passive Filters, Power System Harmonics, Harmonic Distortion, Butterworth Filter I. INTRODUCTION During the last thirty years, much attention has been focused on power system harmonics. This is one of the most severe issue affecting power quality, because it affects both the utility company and consumers. Power system harmonics are considered to be one of the major concern with immediate effects, such as reduction of life of the electrical equipment and early aging of insulators [1]. -

Design and Implementation of Butterworth, Chebyshev-I Filters for Digital Signal Analysis
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 05 Issue: 03 | Mar-2018 www.irjet.net p-ISSN: 2395-0072 Design and Implementation of Butterworth, Chebyshev-I Filters for Digital Signal Analysis Modi Rishabhkumar N.1, Pramiti Parashar2 1,2 M.E, EC, L. D College of Engineering, Gujarat, India ---------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - Filters have become a very essential part in exhibited by the digital filters. On the basis of their the digital field emerging exponentially in today’s time. different characteristics, they can be classified into various Filters are responsible for removing the undesirable different types. components from a specific signal and help in extracting the required frequency range for the respective output. The two main classifications of the digital filters based on Filters have many applications in the signal processing their functioning and the response. The very first basic and communication systems, like, noise reduction, channel classification is done based on their magnitude equalization, circuit analysis, audio-video signal characteristics. They are: processing, radar field, data analysis. Also, the biomedical 1) Low pass filter: - As the name suggests, the low pass fields have the use of filters for filtering the noisy signals filters allow only the low frequencies required up to of the ECG, EEG and EMG. This paper explains the basic the cut-off frequency to pass through and the other functions of filters, their types, i.e. low pass, high pass, frequencies are attenuated. band pass, band stop, and all pass filters. The IIR filters have been studied theoretically and also designed using 2) High pass filter: - The high pass filter attenuates the Python software. -

Butterworth Filters
24 Butterworth Filters To illustrate some of the ideas developed in Lecture 23, we introduce in this lecture a simple and particularly useful class of filters referred to as Butter- worthfilters. Filters in this class are specified by two parameters, the cutoff frequency and the filter order. The frequency response of these filters is monotonic, and the sharpness of the transition from the passband to the stop- band is dictated by the filter order. For continuous-time Butterworth filters, the poles associated with the square of the magnitude of the frequency re- sponse are equally distributed in angle on a circle in the s-plane, concentric with the origin and having a radius equal to the cutoff frequency. When the cutoff frequency and the filter order have been specified, the poles character- izing the system function are readily obtained. Once the poles are specified, it is straightforward to obtain the differential equation characterizing the filter. In this lecture, we illustrate the design of a discrete-time filter through the use of the impulse-invariant design procedure applied to a Butterworth filter. The filter specifications are given in terms of the discrete-time frequen- cy variable and then mapped to a corresponding set of specifications for the continuous-time filter. A Butterworth filter meeting these specifications is de- termined. The resulting continuous-time system function is then mapped to the desired discrete-time system function. A limitation on the use of impulse invariance as a design procedure for discrete-time systems is the requirement that the continuous-time filter be bandlimited to avoid aliasing. -

Microstrip Butterworth Lowpass Filter Design
Owusu Prince Yeboah Microstrip Butterworth Lowpass Filter Design Metropolia University of Applied Sciences Bachelor of Engineering Electronics Engineering Bachelor’s Thesis 13th January 2020 Author Prince Yeboah Owusu Title Microstrip Butterworth Lowpass Filter Design Number of Pages 29 pages + 1 appendix Date 13th January 2020 Degree Bachelor of Engineering Degree Programme Electronics Engineering Professional Major Instructors Heikki Valmu, Principal Lecturer (Metropolia UAS) Lowpass filters of different kinds are almost ubiquitous in RF and microwave engineering applications. The design of filters therefore is crucial in the study of electronics. This thesis aims to explore the design of three different types of Lowpass Butterworth filter namely Lumped element, Stepped Impedance and Stubs designs, and then compare and contrast their various stimulated responses and actual responses. This paper gives a rather brief but succinct theoretical framework and, where necessary, some historical background to the subjects and focuses more on the design. There is a great amount of literature on the in-depth mathematical and design identities used in this paper. This thesis utilizes the available knowledge for the designs. The filters were designed with specific given parameters employing the NI AWR software for design and simulation. Finally, the designed layouts were printed using of a PCB printing machine and analyzed using a network analyzer. The results obtained weren’t as expected, the Lumped element design produced an unexpected accurate -

Simultaneous Low-Pass Filtering and Total Variation Denoising Ivan W
LAST EDIT: FEBRUARY 4, 2014 1 Simultaneous Low-Pass Filtering and Total Variation Denoising Ivan W. Selesnick, Harry L. Graber, Douglas S. Pfeil, and Randall L. Barbour Abstract—This paper seeks to combine linear time-invariant However, the signals arising in some applications are more (LTI) filtering and sparsity-based denoising in a principled way complex: they are neither isolated to a specific frequency band in order to effectively filter (denoise) a wider class of signals. nor do they admit a highly sparse representation. For such LTI filtering is most suitable for signals restricted to a known frequency band, while sparsity-based denoising is suitable for signals, neither LTI filtering nor sparsity-based denoising is signals admitting a sparse representation with respect to a known appropriate by itself. Can conventional LTI filtering and more transform. However, some signals cannot be accurately catego- recent sparsity-based denoising methods be combined in a rized as either band-limited or sparse. This paper addresses the principled way, to effectively filter (denoise) a wider class of problem of filtering noisy data for the particular case where the signals than either approach can alone? underlying signal comprises a low-frequency component and a sparse or sparse-derivative component. A convex optimization This paper addresses the problem of filtering noisy data approach is presented and two algorithms derived, one based where the underlying signal comprises a low-frequency com- on majorization-minimization (MM), the other based on the ponent and a sparse or sparse-derivative component. It is alternating direction method of multipliers (ADMM). It is shown assumed here that the noisy data y(n) can be modeled as that a particular choice of discrete-time filter, namely zero-phase non-causal recursive filters for finite-length data formulated in y(n) = f(n) + x(n) + w(n); n = 0;:::;N − 1 (1) terms of banded matrices, makes the algorithms effective and computationally efficient.