Toward a Computational Solution to the Inverse Problem of How Hypoxia Arises in Metabolically Heterogeneous Cancer Cell Populations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sandipan Dandapat
SUNANDAN CHAKRABORTY Assistant Professor Human-Centered Computing, School of Informatics and Computing Indiana University – Purdue University Indianapolis 535 W. Michigan Street Room 567, Indianapolis, IN 46202 Email: [email protected] Phone: 1 317 278 3512 RESEARCH INTERESTS Text and Data Mining, Machine Learning, Big Data Analytics, Computational Sustainability, Computation for Development (ICTD) EDUCATION • PhD (2015): Department of Computer Science, New York University, USA • MS (2008): Dept. of Computer Science and Engineering, Indian Institute of Technology (IIT) Kharagpur, INDIA • B.Tech (2004): Computer Science & Engineering, University of Kalyani, INDIA AWARDS AND PRIZES • Winner of Grand Prize of the Wildlife Crime Tech Challenge organized by USAID in 2015 [4 grand prize winners among 300 submissions] • Winner of Janet Fabri Prize from Courant Institute of Mathematical Science (2016) [Among ~20 other thesis submission] • Winner of Harold Grad Memorial (2013) from Courant Institute of Mathematical Sciences for outstanding performance and promise as a graduate student [Selected among ~16 other PhD students] • Awarded the ACM/SIGIR Travel Grant to attend International Conference on Information Retrieval (SIGIR) 2014, Gold Coast, Australia PROFESSIONAL EXPERIENCE • Assistant Professor, School of Informatics and Computing, Indiana University Purdue University Indianapolis (Aug 2017 - present) • Post-doctoral Researcher, Center for Data Science, New York University (Sep 2015 – present) • Tracking illegal wildlife trade on the Web: Building -

Saugata Basu Curriculum Vitae
Saugata Basu Curriculum Vitae Education 1991–1996 Phd, Courant Institute, New York University, New York. 1987–1991 B. Tech, Computer Science and Engineering, Indian Institute of Technology, Kharagpur. Phd thesis title Algorithms in Semi-algebraic Geometry supervisor Professor Richard Pollack Experience 2008–current Professor, Department of Mathematics and Department of Computer Science, Purdue University, West Lafayette, (Math 90%, Computer Science 10%). 2008–2010 Professor, School of Mathematics and College of Computing, Georgia Institute of Technology, Atlanta, (Math 75%, Computer Science 25%). (On leave) 2004–2008 Associate Professor, School of Mathematics and College of Computing, Georgia Institute of Technology, Atlanta, tenured (Math 75%, Computer Science 25%). 2000–2004 Assistant Professor, School of Mathematics and College of Computing, Georgia Institute of Technology, Atlanta, tenure-track (Math 75%, Computer Science 25%). 1998–2000 Assistant Professor, Department of Mathematics, University of Michigan, Ann Arbor, (non-tenure-track). 1997–1998 Post-doctoral Fellow (currently called Goldstine Fellowship), Mathematical Sciences Department, IBM T.J. Watson Research Center, Yorktown Heights. 1996–1997 Post-doctoral Fellow, Mathematical Sciences Research Institute, Berkeley. 150 N. University Street – West Lafayette, IN 47907-2067 – USA Ó +1 (765) 494 8798 • ƒ +1 (765) 494 0548 Q [email protected] • saugatabasu.org • 7 SaugataBasu4 Visiting positions and short visits Mar 19-23, Visiting Professor, Indian Statistical Institute, Stat-Math Unit, Kolkata, India. 2018 Jan-Feb, Visiting Professor, Institute Henri Poincaré, Paris, France, Trimester on Model 2018 theory, combinatorics and valued fields. Aug-Dec, Visiting Scientist, Simon’s Institute for the Theory of Computing, University of 2014 California, Berkeley, Program on Algorithms and Complexity in Algebraic Geometry. -

American Association for the Advancement of Science
Bridging Science and Society aaas annual report | 2010 The American Association for the Advancement of Science (AAAS) is the world’s largest general scientific society and publisher of the journal Science (www.sciencemag.org) as well as Science Translational Medicine (www.sciencetranslationalmedicine.org) and Science Signaling (www.sciencesignaling.org). AAAS was founded in 1848 and includes some 262 affiliated societies and academies of science, serving 10 million individuals. Science has the largest paid circulation of any peer- reviewed general science journal in the world, with an estimated total readership of 1 million. The non-profit AAAS (www.aaas.org) is open to all and fulfills its mission to “advance science and serve society” through initiatives in science policy; international programs; science education; and more. For the latest research news, log onto EurekAlert!, www.eurekalert.org, the premier science- news Web site, a service of AAAS. American Association for the Advancement of Science 1200 New York Avenue, NW Washington, DC 20005 USA Tel: 202-326-6440 For more information about supporting AAAS, Please e-mail [email protected], or call 202-326-6636. The cover photograph of bridge construction in Kafue, Zambia, was captured in August 2006 by Alan I. Leshner. Bridge enhancements were intended to better connect a grass airfield with the Kafue National Park to help foster industry by providing tourists with easier access to new ecotourism camps. [FSC MixedSources logo / Rainforest Alliance Certified / 100 percent green -

Acm the Association for Computing Machinery Advancing Computing As a Science & Profession
acm The Association for Computing Machinery Advancing Computing as a Science & Profession CONTACT: Virginia Gold 212-626-0505 [email protected] ACM NAMES 38 FELLOWS FOR COMPUTING AND IT INNOVATIONS IN INDUSTRY, EDUCATION, ENTERTAINMENT New York, NY, December 3, 2007 -- ACM has recognized 38 of its members for their contributions to computing technology that have brought advances in the way people live and work throughout the world. The 2007 ACM Fellows, from the world’s leading universities, industries, and research labs, created innovations in a range of computing disciplines that affect theory and practice, education and entertainment, industry and commerce. “These men and women are the inventors of technology that impacts our society in profound and tangible ways every day,” said ACM President Stuart Feldman. They have pushed the boundaries of their respective computing disciplines to create remarkable achievements that have the potential to make our world more accessible, more secure, and more advanced. Their selection as 2007 ACM Fellows offers us an opportunity to recognize their dedicated leadership in this dynamic field, and to honor their contributions to solving complex problems, expanding the impact of technology, and advancing the quality of life for people everywhere.” Within the corporate sector, the 2007 Fellows named from Microsoft Research, including one from Microsoft China, were cited for contributions ranging from computer graphics to video and image content analysis and retrieval. Other corporate entities with 2007 Fellows were Intel Corp., Yahoo!, and Bell Labs Research, Alcatel-Lucent. Their respective contributions include mathematical foundations for optimizing compilers, algorithms and Web technology, and data semantics for Web services. -

Curriculum Vitae Personal Scholastic Record
Curriculum Vitae Bhubaneswar Mishra Professor of Computer Science, Engineering, Mathematics, and Cell Biology June 7, 2021 251 Mercer Street, Room 405 NYU School of Medicine Courant Institute of Mathematical Sciences 550 First Avenue New York, N.Y. 10012. New York, N.Y. 10016. Tel: (212) 998-3464 Tel: (212) 263-7300 E-mail: [email protected] URL: http://cs.nyu.edu/mishra 16 Dunster Road, Great Neck, NY 11021 • Tel: (516) 487-7477 Personal Nationality Indian National & American Citizen Scholastic Record 1985 Ph.D. Carnegie-Mellon University, (Computer Science) Some Graph Theoretic Issues in VLSI Design, Thesis Committee: Prof. E.M. Clarke (advisor), Profs. R. Kannan, R. Statman and R.E. Tarjan. 1982 M.S. Carnegie-Mellon University, (Computer Science) Area Committee: Prof. E.M. Clarke (advisor), Profs. D. Siewiorek and Wm. A. Wulf . 1980 B.Tech.(Hons.) Indian Institute of Technology, Kharagpur, India, (Electronics and Electrical Communication Engg.) Advisor: Prof. S.C. DeSarkar. 1975 I.Sc.(Hons.) Utkal University, Bhubaneswar, India. 1 Honors and Achievements Acedemy Members/Fellows (December 2017:) National Academy of Inventors Fellow. Society Fellows (December 2010:) AAAS Fellow. (For contributions to engineering sciences.) (January 2009:) IEEE Fellow. (For contributions to mathematical models of robotic grasping.) (June 2008:) ACM Fellow. (For contributions to symbolic computation and computational biology.) Distinguished Professor, Scientist, Alumnus, etc. (May 2011:) Distinguished Alumnus Award (2011), Indian Institute of Technology (Kharagpur), India. (January 2009:) Invited Guest, Kavli Future Symposium: Envisioning the Extreme Machine, Muelle, Costa Rica. (January 2003) NYSTAR Distinguished Professor of 2001 , New York State Office of Science, Tech- nology & Academic Research, Albany, NY. -

Algorithmic Algebra/ Bhubaneswar Mishra P
Algorithmic Algebra Bhubaneswar Mishra Courant Institute of Mathematical Sciences Editor Karen Kosztolnyk Production Manager ?? Text Design ?? Cover Design ?? Copy Editor ?? Library of Congress Catalogue in Publication Data Mishra, Bhubaneswar, 1958- Algorithmic Algebra/ Bhubaneswar Mishra p. com. Bibliography: p. Includes Index ISBN ?-?????-???-? 1. Algorithms 2. Algebra 3. Symbolic Computation display systems. I.Title T??.??? 1993 ???.??????-???? 90-????? CIP Springer-Verlag Incorporated Editorial Office: ??? ??? Order from: ??? ??? c 1993 by ???? All rights reserved No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means—electronic, mechanical, recording or otherwise—without the prior permission of the publisher. ?? ?? ?? ?? ?? ? ? ? ? ? To my parents Purna Chandra & Baidehi Mishra Preface In the fall of 1987, I taught a graduate computer science course entitled “Symbolic Computational Algebra” at New York University. A rough set of class-notes grew out of this class and evolved into the following final form at an excruciatingly slow pace over the last five years. This book also benefited from the comments and experience of several people, some of whom used the notes in various computer science and mathematics courses at Carnegie-Mellon, Cornell, Princeton and UC Berkeley. The book is meant for graduate students with a training in theoretical computer science, who would like to either do research in computational algebra or understand the algorithmic underpinnings of various commer- cial symbolic computational systems: Mathematica, Maple or Axiom, for instance. Also, it is hoped that other researchers in the robotics, solid modeling, computational geometry and automated theorem proving com- munities will find it useful as symbolic algebraic techniques have begun to play an important role in these areas. -
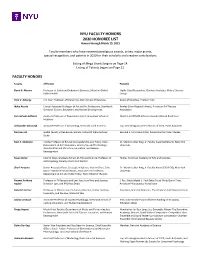
NYU FACULTY HONORS 2020 HONOREE LIST Honors Through March 15, 2021
NYU FACULTY HONORS 2020 HONOREE LIST Honors through March 15, 2021 Faculty members who have received prestigious awards, prizes, major grants, special recognition, and patents in 2020 for their scholarly and creative contributions. Listing of Mega Grants begins on Page 14. Listing of Patents begins on Page 21. FACULTY HONORS Faculty Affiliation Honor(s) David B. Abrams Professor of Social and Behavioral Sciences, School of Global Highly Cited Researcher, Clarivate Analytics, Web of Science Public Health Group Viral V. Acharya C.V. Starr Professor of Economics, Stern School of Business Board of Directors, Pratham USA Ikuko Acosta Clinical Associate Professor of Art and Art Professions, Steinhardt Rawley Silver Research Award, American Art Therapy School of Culture, Education, and Human Development Association Samrachana Adhikari Assistant Professor of Population Health, Grossman School of Women in STEM2D Scholars Award, Johnson & Johnson Medicine Aleksander Aleszczyk Assistant Professor of Accounting, Stern School of Business Top 50 Undergraduate Professors of 2020, Poets & Quants Nosheen Ali Global Faculty in Residence, Gallatin School of Individualized Bernard S. Cohn Book Prize, Association for Asian Studies Study Noel S. Anderson Clinical Professor of Educational Leadership and Policy; Chair, Dr. Martin Luther King, Jr. Faculty Award (2020-21), New York Department of Administration, Leadership, and Technology, University Steinhardt School of Culture, Education, and Human Development Susan Antón Interim Dean, Graduate School of Arts and Science; Professor of Fellow, American Academy of Arts and Sciences Anthropology, Faculty of Arts and Science Sheril Antonio Senior Associate Dean, Strategic Initiatives; Interim Chair, Clive Dr. Martin Luther King, Jr. Faculty Award (2019-20), New York Davis Institute of Record Music; Associate Arts Professor, University Department of Art and Public Policy, Tisch School of the Arts Kwame Anthony Professor of Philosophy and Law, Faculty of Arts and Science, J. -

Ms Niha Dingankar Assistant Professor and Dr Anita Chaware, Head PG Depa
Prepared by First Year MCA Students Compiled by – Ms Niha Dingankar Assistant Professor and Dr Anita Chaware, Head PG Department Of Computer Science, SNDT WU National Technology Day is celebrated on 11 May across India. This day marks the successfully tested Shakti-I nuclear missile at the Indian Army’s Pokhran Test Range in Rajasthan. This day will be focusing on rebooting the economy through Science and Technology. Shakti also knows as the Pokhran Nuclear Test was the first nuclear test code-named ‘Smiling Buddha’ was carried out in May 1974. This operation was administered by late president and aerospace engineer Dr APJ Abdul Kalam Kalam when Atal Bihari Vajpayee was the Prime Minister. The students of Post Graduate Department Of Computer Science,SNDT University have prepared a list of Computer Scientists from Maharashtra and Orissa. The song which is played in the background is Jayostute Shree Mahanmangale With Original Lyrics by Shree Veer Savarkar Sung By Lata Mangeshkar Chhatrapati Mukteswar Shivaji Temple,Odisha Maharaj Aravind Joshi Born: 5 August 1929 - 31 December 2017 Aravind Krishna Joshi was the Henry Salvatori Professor of Computer and Cognitive Science in the computer science department of the University of Pennsylvania. Joshi defined the tree-adjoining grammar formalism which is often used in computational linguistics and natural language processing. Awards: Guggenheim fellow, 1971–72 Fellow of the Institute of Electrical and Electronics Engineers (IEEE), 1976 Founding Fellow of the American Association for Artificial Intelligence (AAAI), 1990 Award Benjamin Franklin Medal Vijay P. Bhatkar Born: 11 October 1946,Mumbai,India Vijay Pandurang Bhatkar is an Indian computer scientist, IT leader and educationalist.