Odoo Development Cookbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Paper Title (Use Style: Paper Title)
A selection model of ERP system in mobile ERP design science research Case study: mobile ERP usability Khalil Omar Jorge Marx Gómez Department of Computing Science Department of Computing Science University of Oldenburg University of Oldenburg Oldenburg, Germany Oldenburg, Germany [email protected] [email protected] Abstract— Nowadays, mobile apps penetrate in every aspect Two complementary but distinct research paradigms of our daily life, due to the proliferation of mobile devices, the characterize much of the research in IS discipline namely: constant advances in mobile computing, and the enormous leaps behavioural science and design science [9]. The behavioural of mobile HCI. Thus, these factors have increased the demands to science paradigm has its roots in natural science research adopt the mobile ERP as a working model in enterprises. methods; it seeks to develop and verify theories that explain or Regardless of these demands, mobile ERP has several challenges predict human or organizational behaviour [9]. Whereas design and issues that need to be addressed through a problem the science paradigm is considered a problem-solving paradigm, design science research paradigm, since this paradigm is and it has its roots in engineering and the sciences of the considered a problem-solving paradigm and it has its roots in artificial [9]. The latter is accepted as a valid and valuable engineering and the sciences of the artificial. Accordingly, this research methodology by the engineering research culture, due paper aims to propose a model for selecting an appropriate ERP system within the mobile ERP’s design science research domain. -

Measuring Non Monetary Innovation in Software: a Case Study in Floss Firms from Argentina
International Journal of Innovation ISSN: 2318-9975 [email protected] Universidade Nove de Julho Brasil MEASURING NON MONETARY INNOVATION IN SOFTWARE: A CASE STUDY IN FLOSS FIRMS FROM ARGENTINA Motta, Jorge; Morero, Hernán Alejandro; Borrastero, Carina MEASURING NON MONETARY INNOVATION IN SOFTWARE: A CASE STUDY IN FLOSS FIRMS FROM ARGENTINA International Journal of Innovation, vol. 7, no. 1, 2019 Universidade Nove de Julho, Brasil Available in: https://www.redalyc.org/articulo.oa?id=499165584008 DOI: https://doi.org/10.5585/iji.v7i1.319 PDF generated from XML JATS4R by Redalyc Project academic non-profit, developed under the open access initiative MEASURING NON MONETARY INNOVATION IN SOFTWARE: A CASE STUDY IN FLOSS FIRMS FROM ARGENTINA ENSURANDO A INOVAÇÃO NÃO MONETÁRIA EM SOFTWARE: UM ESTUDO DE CASO EM EMPRESAS DE CÓDIGO ABERTO (FLOSS) DA ARGENTINA Jorge Moa [email protected] Universidad Nacional de Córdoba, Argentina hps://orcid.org/0000-0002-1430-7009 Hernán Alejandro Morero [email protected] Universidad Nacional de Córdoba-UNC, Argentina hps://orcid.org/0000-0002-6076-1915 Carina Borrastero [email protected] Universidad Nacional de Córdoba-UNC, Argentina International Journal of Innovation, vol. hps://orcid.org/0000-0002-8754-1381 7, no. 1, 2019 Universidade Nove de Julho, Brasil DOI: https://doi.org/10.5585/ iji.v7i1.319 Abstract: is paper presents a critical review of the design of innovation surveys that follow the Oslo Manual standards, based on a series of case studies in Free/Libre Redalyc: https://www.redalyc.org/ articulo.oa?id=499165584008 Open Source Soware (FLOSS) companies. e main objective of the article is to propose criteria for measuring innovation in soware that consider the specificities of the non-monetized innovation generated in the FLOSS community, helping to overcome relevant limitations of the current sectorial surveys based on the Oslo Manual. -
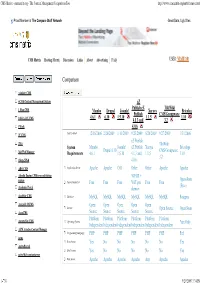
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

A Framework for Ontology-Based Library Data Generation, Access and Exploitation
Universidad Politécnica de Madrid Departamento de Inteligencia Artificial DOCTORADO EN INTELIGENCIA ARTIFICIAL A framework for ontology-based library data generation, access and exploitation Doctoral Dissertation of: Daniel Vila-Suero Advisors: Prof. Asunción Gómez-Pérez Dr. Jorge Gracia 2 i To Adelina, Gustavo, Pablo and Amélie Madrid, July 2016 ii Abstract Historically, libraries have been responsible for storing, preserving, cata- loguing and making available to the public large collections of information re- sources. In order to classify and organize these collections, the library commu- nity has developed several standards for the production, storage and communica- tion of data describing different aspects of library knowledge assets. However, as we will argue in this thesis, most of the current practices and standards available are limited in their ability to integrate library data within the largest information network ever created: the World Wide Web (WWW). This thesis aims at providing theoretical foundations and technical solutions to tackle some of the challenges in bridging the gap between these two areas: library science and technologies, and the Web of Data. The investigation of these aspects has been tackled with a combination of theoretical, technological and empirical approaches. Moreover, the research presented in this thesis has been largely applied and deployed to sustain a large online data service of the National Library of Spain: datos.bne.es. Specifically, this thesis proposes and eval- uates several constructs, languages, models and methods with the objective of transforming and publishing library catalogue data using semantic technologies and ontologies. In this thesis, we introduce marimba-framework, an ontology- based library data framework, that encompasses these constructs, languages, mod- els and methods. -

List of Software on the Register (As at 31 August 2021) √ √ √
List of Software on the Register (as at 31 August 2021) Please note that software owners and their products are listed below in alphabetical order. Software that are able to support the transmission of GST returns and transactions via IRAS API are denoted by "*". For more information, please refer here. Software that are able to support the transmission of Form C-S via IRAS API are denoted by “^”. For more information, please refer here. Recommended Features Name of software Reverse Overseas GST GST Filing GST that is compliant Period of Listing Business email S/No. Software owner Charge Vendor Registration Reminder Automated with IRAS' Mechanism Registration Reminder Blocked Input on IRAS ASR address requirements Regime Tax Claims 1. A2000 Solutions A2000ERP Version 1 Jan 2021 [email protected] Pte Ltd 12.X* to 31 Dec 2021 2. AccPro AAP R/4(R) - 1 Jan 2021 [email protected] Computer Accounting √ √ √ √ √ to 31 Dec 2021 Systems Pte Ltd Professional Version 10.0 3. ACMEFOCUS.NE WHIZIT ACCOUNTS 1 Jan 2021 [email protected] T PTE LTD ORGANIZER version to 31 Dec 2021 om PA1 1 Recommended Features Name of software Reverse Overseas GST GST Filing GST that is compliant Period of Listing Business email S/No. Software owner Charge Vendor Registration Reminder Automated with IRAS' on IRAS ASR address Mechanism Registration Reminder Blocked Input requirements Regime Tax Claims 4. AM8ZE Pte Ltd AM8ZE ERP Version 24 May 2021 [email protected] 10-13 to 31 Dec 2021 5. Asian Business (a) ABSS Premier 1 Jan 2021 [email protected] Software for Windows √ √ to 31 Dec 2021 m Solutions Pte Version 23.x Ltd (b) Financio Version 2.x 6. -

Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13
Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Flemish Public Libraries - Digital Library Systems Architecture Study Last update: 27 NOV 2013 Researchers: Jean-François Declercq Rosemie Callewaert François Vermaut Ordered by: Bibnet vzw Vereniging van de Vlaamse Provincies Vlaamse Gemeenschapscommissie van het Brussels Hoofdstedelijk Gewest 2013-11-27-DigitalLibrarySystemArchitecture p. 1 / 163 Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Table of contents 1 Introduction ............................................................................................................................... 6 1.1 Definition of a Digital Library ............................................................................................. 6 1.2 Study Objectives ................................................................................................................ 7 1.3 Study Approach ................................................................................................................. 7 1.4 Study timeline .................................................................................................................... 8 1.5 Study Steering Committee ................................................................................................. 9 2 ICT Systems Architecture Concepts ......................................................................................... 10 2.1 Enterprise Architecture Model ....................................................................................... -

Download Slide (PDF Document)
When Django is too bloated Specialized Web-Applications with Werkzeug EuroPython 2017 – Rimini, Italy Niklas Meinzer @NiklasMM Gotthard Base Tunnel Photographer: Patrick Neumann Python is amazing for web developers! ● Bottle ● BlueBream ● CherryPy ● CubicWeb ● Grok ● Nagare ● Pyjs ● Pylons ● TACTIC ● Tornado ● TurboGears ● web2py ● Webware ● Zope 2 Why would I want to use less? ● Learn how stuff works Why would I want to use less? ● Avoid over-engineering – Wastes time and resources – Makes updates harder – It’s a security risk. Why would I want to use less? ● You want to do something very specific ● Plan, manage and document chemotherapy treatments ● Built with modern web technology ● Used by hospitals in three European countries Patient Data Lab Data HL7 REST Pharmacy System Database Printers Werkzeug = German for “tool” ● Developed by pocoo team @ pocoo.org – Flask, Sphinx, Jinja2 ● A “WSGI utility” ● Very lightweight ● No ORM, No templating engine, etc ● The basis of Flask and others Werkzeug Features Overview ● WSGI – WSGI 1.0 compatible, WSGI Helpers ● Wrapping of requests and responses ● HTTP Utilities – Header processing, form data parsing, cookies ● Unicode support ● URL routing system ● Testing tools – Testclient, Environment builder ● Interactive Debugger in the Browser A simple Application A simple Application URL Routing Middlewares ● Separate parts of the Application as wsgi apps ● Combine as needed Request Static files DB Part of Application conn with DB access User Dispatcher auth Part of Application without DB access Response HTTP Utilities ● Work with HTTP dates ● Read and dump cookies ● Parse form data Using the test client Using the test client - pytest fixtures Using the test client - pytest fixtures Interactive debugger in the Browser Endless possibilities ● Connect to a database with SQLalchemy ● Use Jinja2 to render documents ● Use Celery to schedule asynchronous tasks ● Talk to 3rd party APIs with requests ● Make syscalls ● Remote control a robot to perform tasks at home Thank you! @NiklasMM NiklasMM Photographer: Patrick Neumann. -

Advances in Natural and Applied Sciences 2018 April; 12(4): Pages 16-21 DOI: 10.22587/Anas.2018.12.4.4 Research Article AENSI Publications
Advances In Natural And Applied Sciences 2018 April; 12(4): pages 16-21 DOI: 10.22587/anas.2018.12.4.4 Research Article AENSI Publications Integration Between ERP Software and Business Intelligence in Odoo ERP: Case Study A Distribution Company Yulia Kendengis and Leo Willyanto Santoso Correspondence Author: Yulia Kendengis, Informatics Department, Petra Christian University, Indonesia Received date: 12 January 2018, Accepted date: 10 March 2018, Online date: 2 April 2018 Copyright: © 2018 Yulia Kendengis and Leo Willyanto Santoso. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Abstract Odoo is an open-source ERP software. Odoo has advantage in price because it’s free. And from the functional side, Odoo has been equipped with more than 4500 modules, one of them is business intelligence (BI). BI is a solution and technique that helps company to understand about the business situation to make effective business decisions and meet their objectives. A study about the integration between Enterprise Resource Planning and BI in Odoo ERP will be explained in this paper. In the case study, we used sales data from a distribution company. Key words: Business Intelligence, ERP, Odoo INTRODUCTION BI transforms raw data into meaningful metrics reflective upon historical, current and predictive business operations and performance. In the past, the activities of BI were performed through gathering data from multiple sources manually, manipulating data in spreadsheets, with a static report output. The data should be gathered from some functional areas. -

Python 2018, Fulda, Germany Nationaler Akademietag in Fulda 2018
Python 2018, Fulda, Germany Nationaler Akademietag in Fulda 2018 Maciek Wichary, Sławek Wernikowski, OpenEDG Python Institute April 2018 Yes You can find me in this picture! My very first CCNA group back in 2002 All of my students have great jobs now. © 20172016 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 2 Agenda Overview of the How to make your Programming Essentials teaching job easier. 02 In Python course 04 Why Python? Use of Python Overview EDUBE A very important tool to What is Python actually make labs attractive and used for? easy. 01 03 We will do the lab now! © 2017 Cisco and/or its affiliates. All rights reserved. Cisco Confidential 3 Educationjobs.thelocal.comas the process Start Lectures, labs, quizes, chapter assesments What is Python actually used for? They were all written, to Battlefield 2, Battlefield 2142 and Battlefield Heroes a greater or lesser All the games use Python for logic and server controls extent, in Python. Other examples • Internet Applications (BitTorrent, Jogger Publishing Assistant, TheCircle, TwistedMatrix) • 3D CAD/CAM (FreeCAD, Fandango, Blender, Vintech RCAM) • Enterprise Applications (Odoo, Tryton, Picalo, LinOTP 2, RESTx) • Image Applications (Gnofract 4D, Gogh, imgSeek, MayaVi, VPython) • Mobile Applications (Aarlogic C05/3, AppBackup, Pyroute) • Office Applications (calibre, faces, Notalon, pyspread) • Personal Information Managers (BitPim, Narval, Prioritise, Task Coach, WikidPad) Generally, Python is a great choice for: • Web and Internet development (e.g., Django -

Application from the Bibliothèque Nationale De France (Bnf) for Gallica (Gallica.Bnf.Fr) and Data (Data.Bnf.Fr) TABLE of CONTENTS I
Stanford Prize for Innovation in Research Libraries (SPIRL) Application from the Bibliothèque nationale de France (BnF) for Gallica (gallica.bnf.fr) and Data (data.bnf.fr) TABLE OF CONTENTS I. Nominators’ statement ........................................................................................................... 1 II. Narrative description ............................................................................................................ 2 1. THE GALLICA DIGITAL LIBRARY: AN ONGOING INNOVATION .................................... 2 1.1 A BRIEF HISTORY OF GALLICA ..................................................................................... 2 Gallica today and tomorrow ................................................................................................... 6 1.2 GALLICA TRULY CARES ABOUT ITS END USERS ....................................................... 6 Smart search .......................................................................................................................... 6 Smart browsing ...................................................................................................................... 7 Gallica made mobile .............................................................................................................. 7 1.3 A LIBRARY DESIGNED FOR USE AND RE-USE ............................................................ 8 Terms of use .......................................................................................................................... 8 Off line -

Brainomics: Harnessing the Cubicweb Semantic
Brainomics: Harnessing the CubicWeb semantic framework to manage large neuromaging genetics shared resources David Goyard, Antoine Grigis, Dimitri Papadopoulos-Orfanos, Michel Vittot, Vincent Frouin, Adrien Di Mascio To cite this version: David Goyard, Antoine Grigis, Dimitri Papadopoulos-Orfanos, Michel Vittot, Vincent Frouin, et al.. Brainomics: Harnessing the CubicWeb semantic framework to manage large neuromaging genetics shared resources. Journées RITS 2015, Mar 2015, Dourdan, France. p34-35 Section imagerie génétique. inserm-01145600 HAL Id: inserm-01145600 https://www.hal.inserm.fr/inserm-01145600 Submitted on 24 Apr 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Actes des Journées Recherche en Imagerie et Technologies pour la Santé - RITS 2015 34 Brainomics: Harnessing the CubicWeb semantic framework to manage large neuromaging genetics shared resources 1 1 1 2 1 2 D. Goyard , A. Grigis , D. Papadopoulos Orfanos , V. Michel , V. Frouin ∗, A. Di Mascio 1 CEA DSV NeuroSpin, UNATI, 91 Gif sur Yvette, France. 2 Logilab, Paris, France. ∗ [email protected]. Abstract - In neurosciences or psychiatry, large mul- one workpackage devoted to this issue. The package was ticentric population studies are being acquired and the twofolds: (i) to develop specific Python modules using the corresponding data are made available to the acquisi- CubicWeb framework (Logilab, Paris) and (ii) to demon- tion partners or the scientific community. -

Erp Software Vendor Directory
ERP FOCUS ERP SOFTWARE VENDOR DIRECTORY C CONVERTED MEDIA ERP FOCUS M ERP Software Features Billing CRM Customer Service Financials & Accounting Planning & Scheduling 3S ERP Project Management Supply Chain Management 3S ERP is specifically designed for small to medium-sized manufacturing companies. The ERP is a fully-integrated Document Management system with a wide range of management modules that cater for production, manufacturing, and administration. The 3S ERP production module is particularly well-equipped for manufacturers, offering features for quality management, hazardous materials handling, tool management and product planning and configuration. It also VIEW SOFTWARE REVIEWS, interfaces with CAD. As 3S ERP is modular, users can build up from basic financial management with production, SCREENSHOTS & MORE distribution, CRM and much more. 3S ERP is easily customized and does not need any additional programming VIEW COMPLETE PROFILE knowledge. The security of 3S ERP data is managed at three levels – the operating system, the network and at the level to the database and applications. Access can be limited to the user level, meaning you can control access to restricted data across user groups. 3S ERP offers searchable one-time data entry, with advanced analytics features alongside this. It also helps support internal and external financial audits. 3S ERP is installed on-premise, with iOS and web apps available for increased mobility. System installation takes around seven days, and 3S offer user training during implementation. Users can access software updates and upgrades free of charge. ERP Software Features Billing Business Intelligence/Analytics Costing ABAS ERP CRM Financials & Accounting abas ERP is a software system for manufacturers, retailers, distributors and service providers.