A Framework for Ontology-Based Library Data Generation, Access and Exploitation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Realising the Potential of Algal Biomass Production Through Semantic Web and Linked Data
LEAPS: Realising the Potential of Algal Biomass Production through Semantic Web and Linked data ∗ Monika Solanki Johannes Skarka Craig Chapman KBE Lab Karlsruhe Institute of KBE Lab Birmingham City University Technology (ITAS) Birmingham City University [email protected] [email protected] [email protected] ABSTRACT In order to derive fuels from biomass, algal operation plant Recently algal biomass has been identified as a potential sites are setup that facilitate biomass cultivation and con- source of large scale production of biofuels. Governments, version of the biomass into end use products, some of which environmental research councils and special interests groups are biofuels. Microalgal biomass production in Europe is are funding several efforts that investigate renewable energy seen as a promising option for biofuels production regarding production opportunities in this sector. However so far there energy security and sustainability. Since microalgae can be has been no systematic study that analyses algal biomass cultivated in photobioreactors on non-arable land this tech- potential especially in North-Western Europe. In this paper nology could significantly reduce the food vs. fuel dilemma. we present a spatial data integration and analysis frame- However, until now there has been no systematic analysis work whereby rich datasets from the algal biomass domain of the algae biomass potential for North-Western Europe. that include data about algal operation sites and CO2 source In [20], the authors assessed the resource potential for mi- sites amongst others are semantically enriched with ontolo- croalgal biomass but excluded all areas not between 37◦N gies specifically designed for the domain and made available and 37◦S, thus most of Europe. -

From Cataloguing Cards to Semantic Web 1
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Scientific Open-access Literature Archive and Repository Archeologia e Calcolatori 20, 2009, 111-128 REPRESENTING KNOWLEDGE IN ARCHAEOLOGY: FROM CATALOGUING CARDS TO SEMANTIC WEB 1. Introduction Representing knowledge is the basis of any catalogue. The Italian Ca- talogue was based on very valuable ideas, developed in the late 1880s, with the basic concept of putting objects in their context. Initially cataloguing was done manually, with typewritten cards. The advent of computers led to some early experimentations, and subsequently to the de�nition of a more formalized representation schema. The web produced a cultural revolution, and made the need for technological and semantic interoperability more evi- dent. The Semantic Web scenario promises to allow a sharing of knowledge, which will make the knowledge that remained unexpressed in the traditional environments available to any user, and allow objects to be placed in their cultural context. In this paper we will brie�y recall the principles of cataloguing and lessons learned by early computer experiences. Subsequently we will descri- be the object model for archaeological items, discussing its strong and weak points. In section 5 we present the web scenario and approaches to represent knowledge. 2. Cataloguing: history and principles The Italian Catalogue of cultural heritage has its roots in the experiences and concepts, developed in the late 1880s and early 1900s, by the famous art historian Adolfo Venturi, who was probably one of the �rst scholars to think explicitly in terms of having a frame of reference to describe works of art, emphasizing as the main issue the context in which the work had been produced. -

LINGI2172 Databases 2013-2014
Université Catholique de Louvain - DESCRIPTIF DE COURS 2013-2014 - LINGI2172 LINGI2172 Databases 2013-2014 6.0 crédits 30.0 h + 30.0 h 2q Enseignants: Lambeau Bernard ; Langue Français d'enseignement: Lieu du cours Louvain-la-Neuve Ressources en ligne: > http://icampus.uclouvain.be/claroline/course/index.php?cid=lingi2172 Préalables : Basic knowledge of database management, good abilities in programming. Thèmes abordés : * Data Base Management Systems (objectives, requirements, architecture). * The Relational data model (formal theory, first-order logic, constraints). * Conceptual models (entity-relationship, object role modeling). * Logical database design (normal forms & mp; normalization, ER-To-Relational) * Physical database design and storage (tables and keys, indexes, file structures). * Querying databases (Relational Algebra, Relational Calculus, Tutorial D, SQL) * ACID properties (Atomicity, Consistency, Isolation, Durability), Concurrency Control, Recovery techniques. * Programming database applications (JDBC, Database Cursors, Object-Relational Mapping, Relations as First-class Citizen). * Recent or more advanced trends in the database field (object-oriented databases, Big Data, NoSQL, NewSQL) Acquis Students completing this course successfully will be able to : * Explain the scenarios in which using a database is more convenient than programming with data files; d'apprentissage * Explain the characteristics of the database approach, where they come from and contrast them with current trends in the database field-- Identify and describe the main functions of a database management system; * Categorize conceptual, logical and physical data models based on the concepts they provide to describe the database structure; * Understand the main principles and mathematical theory of the relational approach to database management; * Design databases using a systematic approach, from a conceptual model through a logical level (i.e., a relational schema) into a physical model (i.e., tables and indexes); * Use SQL (DDL) to implement a relational database schema. -

Download Slides
a platform for all that we know savas parastatidis http://savas.me savasp transition from web to apps increasing focus on information (& knowledge) rise of personal digital assistants importance of near-real time processing http://aptito.com/blog/wp-content/uploads/2012/05/smartphone-apps.jpg today... storing computing computers are huge amounts great tools for of data managing indexing example google and microsoft both have copies of the entire web (and more) for indexing purposes tomorrow... storing computing computers are huge amounts great tools for of data managing indexing acquisition discovery aggregation organization we would like computers to of the world’s information also help with the automatic correlation analysis and knowledge interpretation inference data information knowledge intelligence wisdom expert systems watson freebase wolframalpha rdbms google now web indexing data is symbols (bits, numbers, characters) information adds meaning to data through the introduction of relationship - it answers questions such as “who”, “what”, “where”, and “when” knowledge is a description of how the world works - it’s the application of data and information in order to answer “how” questions G. Bellinger, D. Castro, and A. Mills, “Data, Information, Knowledge, and Wisdom,” Inform. pp. 1–4, 2004 web – the data platform web – the information platform web – the knowledge platform foundation for new experiences “wisdom is not a product of schooling but of the lifelong attempt to acquire it” representative examples wolframalpha watson source: -

Knowledge Extraction for Hybrid Question Answering
KNOWLEDGEEXTRACTIONFORHYBRID QUESTIONANSWERING Von der Fakultät für Mathematik und Informatik der Universität Leipzig angenommene DISSERTATION zur Erlangung des akademischen Grades Doctor rerum naturalium (Dr. rer. nat.) im Fachgebiet Informatik vorgelegt von Ricardo Usbeck, M.Sc. geboren am 01.04.1988 in Halle (Saale), Deutschland Die Annahme der Dissertation wurde empfohlen von: 1. Professor Dr. Klaus-Peter Fähnrich (Leipzig) 2. Professor Dr. Philipp Cimiano (Bielefeld) Die Verleihung des akademischen Grades erfolgt mit Bestehen der Verteidigung am 17. Mai 2017 mit dem Gesamtprädikat magna cum laude. Leipzig, den 17. Mai 2017 bibliographic data title: Knowledge Extraction for Hybrid Question Answering author: Ricardo Usbeck statistical information: 10 chapters, 169 pages, 28 figures, 32 tables, 8 listings, 5 algorithms, 178 literature references, 1 appendix part supervisors: Prof. Dr.-Ing. habil. Klaus-Peter Fähnrich Dr. Axel-Cyrille Ngonga Ngomo institution: Leipzig University, Faculty for Mathematics and Computer Science time frame: January 2013 - March 2016 ABSTRACT Over the last decades, several billion Web pages have been made available on the Web. The growing amount of Web data provides the world’s largest collection of knowledge.1 Most of this full-text data like blogs, news or encyclopaedic informa- tion is textual in nature. However, the increasing amount of structured respectively semantic data2 available on the Web fosters new search paradigms. These novel paradigms ease the development of natural language interfaces which enable end- users to easily access and benefit from large amounts of data without the need to understand the underlying structures or algorithms. Building a natural language Question Answering (QA) system over heteroge- neous, Web-based knowledge sources requires various building blocks. -

Datatone: Managing Ambiguity in Natural Language Interfaces for Data Visualization Tong Gao1, Mira Dontcheva2, Eytan Adar1, Zhicheng Liu2, Karrie Karahalios3
DataTone: Managing Ambiguity in Natural Language Interfaces for Data Visualization Tong Gao1, Mira Dontcheva2, Eytan Adar1, Zhicheng Liu2, Karrie Karahalios3 1University of Michigan, 2Adobe Research 3University of Illinois, Ann Arbor, MI San Francisco, CA Urbana Champaign, IL fgaotong,[email protected] fmirad,[email protected] [email protected] ABSTRACT to be both flexible and easy to use. General purpose spread- Answering questions with data is a difficult and time- sheet tools, such as Microsoft Excel, focus largely on offer- consuming process. Visual dashboards and templates make ing rich data transformation operations. Visualizations are it easy to get started, but asking more sophisticated questions merely output to the calculations in the spreadsheet. Asking often requires learning a tool designed for expert analysts. a “visual question” requires users to translate their questions Natural language interaction allows users to ask questions di- into operations on the spreadsheet rather than operations on rectly in complex programs without having to learn how to the visualization. In contrast, visual analysis tools, such as use an interface. However, natural language is often ambigu- Tableau,1 creates visualizations automatically based on vari- ous. In this work we propose a mixed-initiative approach to ables of interest, allowing users to ask questions interactively managing ambiguity in natural language interfaces for data through the visualizations. However, because these tools are visualization. We model ambiguity throughout the process of often intended for domain specialists, they have complex in- turning a natural language query into a visualization and use terfaces and a steep learning curve. algorithmic disambiguation coupled with interactive ambigu- Natural language interaction offers a compelling complement ity widgets. -

Directions in AI Research and Applications at Siemens Corporate
AI Magazine Volume 11 Number 1 (1991)(1990) (© AAAI) Research in Progress of linguistic phenomena. The com- Directions in AI Research putational work concerns questions of adequate processing models and algorithms, as embodied in the and Applications at actual interfaces being developed. These topics are explored in the Siemens Corporate Research framework of three projects: The nat- ural language consulting dialogue and Development project (Wisber) takes up research- oriented topics (descriptive grammar formalisms and linguistically adequate grammar specification, handling of Wolfram Buettner, Klaus Estenfeld, discourse, and so on), the data-access Hans Haugeneder, and Peter Struss project (Sepp) focuses on the practi- cal application of state-of-the-art technology, and the work on gram- mar-development environments ■ Many barriers exist today that prevent particular, Prolog extensions; and (4) (Ape) centers on the problem of ade- effective industrial exploitation of current design and analysis of neural networks. quate tools for specifying linguistic and future AI research. These barriers can The lab’s 26 researchers are orga- knowledge sources and efficient pro- only be removed by people who are work- nized into four groups corresponding cessing methods. ing at the scientific forefront in AI and to these areas. Together, they provide Wisber is jointly funded by the know potential industrial needs. Siemens with innovative software The Knowledge Processing Laboratory’s German government and several research and development concentrates in technologies, appropriate applications, industrial and academic partners. the following areas: (1) natural language prototypical implementations of AI The goal of the project is to develop interfaces to knowledge-based systems and systems, and evaluations of new a knowledge-based advice-giving databases; (2) theoretical and experimen- techniques and trends. -
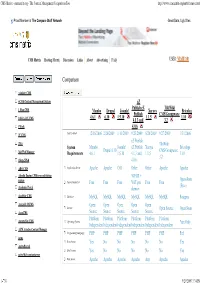
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13
Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Flemish Public Libraries - Digital Library Systems Architecture Study Last update: 27 NOV 2013 Researchers: Jean-François Declercq Rosemie Callewaert François Vermaut Ordered by: Bibnet vzw Vereniging van de Vlaamse Provincies Vlaamse Gemeenschapscommissie van het Brussels Hoofdstedelijk Gewest 2013-11-27-DigitalLibrarySystemArchitecture p. 1 / 163 Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Table of contents 1 Introduction ............................................................................................................................... 6 1.1 Definition of a Digital Library ............................................................................................. 6 1.2 Study Objectives ................................................................................................................ 7 1.3 Study Approach ................................................................................................................. 7 1.4 Study timeline .................................................................................................................... 8 1.5 Study Steering Committee ................................................................................................. 9 2 ICT Systems Architecture Concepts ......................................................................................... 10 2.1 Enterprise Architecture Model ....................................................................................... -

Download Slide (PDF Document)
When Django is too bloated Specialized Web-Applications with Werkzeug EuroPython 2017 – Rimini, Italy Niklas Meinzer @NiklasMM Gotthard Base Tunnel Photographer: Patrick Neumann Python is amazing for web developers! ● Bottle ● BlueBream ● CherryPy ● CubicWeb ● Grok ● Nagare ● Pyjs ● Pylons ● TACTIC ● Tornado ● TurboGears ● web2py ● Webware ● Zope 2 Why would I want to use less? ● Learn how stuff works Why would I want to use less? ● Avoid over-engineering – Wastes time and resources – Makes updates harder – It’s a security risk. Why would I want to use less? ● You want to do something very specific ● Plan, manage and document chemotherapy treatments ● Built with modern web technology ● Used by hospitals in three European countries Patient Data Lab Data HL7 REST Pharmacy System Database Printers Werkzeug = German for “tool” ● Developed by pocoo team @ pocoo.org – Flask, Sphinx, Jinja2 ● A “WSGI utility” ● Very lightweight ● No ORM, No templating engine, etc ● The basis of Flask and others Werkzeug Features Overview ● WSGI – WSGI 1.0 compatible, WSGI Helpers ● Wrapping of requests and responses ● HTTP Utilities – Header processing, form data parsing, cookies ● Unicode support ● URL routing system ● Testing tools – Testclient, Environment builder ● Interactive Debugger in the Browser A simple Application A simple Application URL Routing Middlewares ● Separate parts of the Application as wsgi apps ● Combine as needed Request Static files DB Part of Application conn with DB access User Dispatcher auth Part of Application without DB access Response HTTP Utilities ● Work with HTTP dates ● Read and dump cookies ● Parse form data Using the test client Using the test client - pytest fixtures Using the test client - pytest fixtures Interactive debugger in the Browser Endless possibilities ● Connect to a database with SQLalchemy ● Use Jinja2 to render documents ● Use Celery to schedule asynchronous tasks ● Talk to 3rd party APIs with requests ● Make syscalls ● Remote control a robot to perform tasks at home Thank you! @NiklasMM NiklasMM Photographer: Patrick Neumann. -

Relational Database Management System
Relational database management system A relational database management system (RDBMS) is a database management system (DBMS) based on the relational model invented by Edgar F. Codd, of IBM's San Jose Research Laboratory fame. Most databases in widespread use today are based on his relational database model.[1] RDBMSs have been a common choice for the storage of information in databases used for financial records, manufacturing and logistical information, personnel data, and other applications since the 1980s. Relational databases have often replaced legacy hierarchical databases and network databases because, they were easier to implement and administer. Nonetheless, relational databases received continued, The general structure of a relational unsuccessful challenges by object database management systems in the 1980s and database. 1990s, (which were introduced in an attempt to address the so-called object- relational impedance mismatch between relational databases and object-oriented application programs), as well as by XML database management systems in the 1990s. However, due to the expanse of technologies, such as horizontal scaling of computer clusters, NoSQL databases have recently begun to peck away at the market share of RDBMSs.[2] Contents Market share History Historical usage of the term See also References Market share According to DB-Engines, in May 2017, the most widely used systems are Oracle, MySQL (open source), Microsoft SQL Server, PostgreSQL (open source), IBM DB2, Microsoft Access, and SQLite (open source).[3] According to research company Gartner, in 2011, the five leading commercial relational database vendors by revenue were Oracle (48.8%), IBM (20.2%), Microsoft (17.0%), SAP including Sybase (4.6%), and Teradata (3.7%).[4] History In 1974, IBM began developing System R, a research project to develop a prototype RDBMS.[5][6] However, the first commercially available RDBMS was Oracle, released in 1979 by Relational Software, now Oracle Corporation.[7] Other examples of an RDBMS include DB2, SAP Sybase ASE, and Informix. -

Collecting Activity Data Using the Open Mhealth Platform an Exploratory Study on Integrating Objective Data with Sport Monitoring Systems
Collecting activity data using the Open mHealth platform An exploratory study on integrating objective data with sport monitoring systems Daniel Gynnild-Johnsen , Lars-Erik Holte Master’s Thesis Spring 2017 Collecting activity data using the Open mHealth platform Daniel Gynnild-Johnsen Lars-Erik Holte May 2, 2017 Abstract Football players works together as a unit to perform on an elite competi- tive level, and the most minor abnormalities can determine the outcome of a match. Success can often be the result of healthy, uninjured and rejuve- nated players working together as a collective. Even though it is impossible to control all outcomes and scenarios, the risk of failure might be mini- mized by monitoring players closely on an individual level. If we monitor players over a longer period of time we might discover patterns or abnor- malities in their training. This information can be used to avoid multiple scenarios related to fatigue, injuries and overtraining. In this thesis we present a proof of concept for expanding an existing self- reporting monitoring system called pmSys, and look at how football teams and players can utilize modern technology like phones and wearable de- vices to capture objective data. This system will collect and store the data, which can be processed into useful visualised feedback, and help a team to evaluate their players. This way the coaches can make mitigating mea- sures to improve certain aspect that might be lacking on a player or team level. By eliminating the use of pen and paper, pmSys introduces a simpler way of reporting the players’ health status.