Classical and Contemporary Cryptography: Chapter 2 Notes Monoalphabetic Ciphers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Simple Substitution and Caesar Ciphers
Spring 2015 Chris Christensen MAT/CSC 483 Simple Substitution Ciphers The art of writing secret messages – intelligible to those who are in possession of the key and unintelligible to all others – has been studied for centuries. The usefulness of such messages, especially in time of war, is obvious; on the other hand, their solution may be a matter of great importance to those from whom the key is concealed. But the romance connected with the subject, the not uncommon desire to discover a secret, and the implied challenge to the ingenuity of all from who it is hidden have attracted to the subject the attention of many to whom its utility is a matter of indifference. Abraham Sinkov In Mathematical Recreations & Essays By W.W. Rouse Ball and H.S.M. Coxeter, c. 1938 We begin our study of cryptology from the romantic point of view – the point of view of someone who has the “not uncommon desire to discover a secret” and someone who takes up the “implied challenged to the ingenuity” that is tossed down by secret writing. We begin with one of the most common classical ciphers: simple substitution. A simple substitution cipher is a method of concealment that replaces each letter of a plaintext message with another letter. Here is the key to a simple substitution cipher: Plaintext letters: abcdefghijklmnopqrstuvwxyz Ciphertext letters: EKMFLGDQVZNTOWYHXUSPAIBRCJ The key gives the correspondence between a plaintext letter and its replacement ciphertext letter. (It is traditional to use small letters for plaintext and capital letters, or small capital letters, for ciphertext. We will not use small capital letters for ciphertext so that plaintext and ciphertext letters will line up vertically.) Using this key, every plaintext letter a would be replaced by ciphertext E, every plaintext letter e by L, etc. -

Cryptanalysis of Mono-Alphabetic Substitution Ciphers Using Genetic Algorithms and Simulated Annealing Shalini Jain Marathwada Institute of Technology, Dr
Vol. 08 No. 01 2018 p-ISSN 2202-2821 e-ISSN 1839-6518 (Australian ISSN Agency) 82800801201801 Cryptanalysis of Mono-Alphabetic Substitution Ciphers using Genetic Algorithms and Simulated Annealing Shalini Jain Marathwada Institute of Technology, Dr. Babasaheb Ambedkar Marathwada University, India Nalin Chhibber University of Waterloo, Ontario, Canada Sweta Kandi Marathwada Institute of Technology, Dr. Babasaheb Ambedkar Marathwada University, India ABSTRACT – In this paper, we intend to apply the principles of genetic algorithms along with simulated annealing to cryptanalyze a mono-alphabetic substitution cipher. The type of attack used for cryptanalysis is a ciphertext-only attack in which we don’t know any plaintext. In genetic algorithms and simulated annealing, for ciphertext-only attack, we need to have the solution space or any method to match the decrypted text to the language text. However, the challenge is to implement the project while maintaining computational efficiency and a high degree of security. We carry out three attacks, the first of which uses genetic algorithms alone, the second which uses simulated annealing alone and the third which uses a combination of genetic algorithms and simulated annealing. Key words: Cryptanalysis, mono-alphabetic substitution cipher, genetic algorithms, simulated annealing, fitness I. Introduction II. Mono-alphabetic substitution cipher Cryptanalysis involves the dissection of computer systems by A mono-alphabetic substitution cipher is a class of substitution unauthorized persons in order to gain knowledge about the ciphers in which the same letters of the plaintext are replaced unknown aspects of the system. It can be used to gain control by the same letters of the ciphertext. -
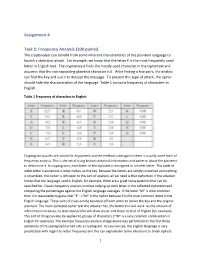
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

John F. Byrne's Chaocipher Revealed
John F. Byrne’s Chaocipher Revealed John F. Byrne’s Chaocipher Revealed: An Historical and Technical Appraisal MOSHE RUBIN1 Abstract Chaocipher is a method of encryption invented by John F. Byrne in 1918, who tried unsuccessfully to interest the US Signal Corp and Navy in his system. In 1953, Byrne presented Chaocipher-encrypted messages as a challenge in his autobiography Silent Years. Although numerous students of cryptanalysis attempted to solve the challenge messages over the years, none succeeded. For ninety years the Chaocipher algorithm was a closely guarded secret known only to a handful of persons. Following fruitful negotiations with the Byrne family during the period 2009-2010, the Chaocipher papers and materials have been donated to the National Cryptologic Museum in Ft. Meade, MD. This paper presents a comprehensive historical and technical evaluation of John F. Byrne and his Chaocipher system. Keywords ACA, American Cryptogram Association, block cipher encryption modes, Chaocipher, dynamic substitution, Greg Mellen, Herbert O. Yardley, John F. Byrne, National Cryptologic Museum, Parker Hitt, Silent Years, William F. Friedman 1 Introduction John Francis Byrne was born on 11 February 1880 in Dublin, Ireland. He was an intimate friend of James Joyce, the famous Irish writer and poet, studying together in Belvedere College and University College in Dublin. Joyce based the character named Cranly in Joyce’s A Portrait of the Artist as a Young Man on Byrne, used Byrne’s Dublin residence of 7 Eccles Street as the home of Leopold and Molly Bloom, the main characters in Joyce’s Ulysses, and made use of real-life anecdotes of himself and Byrne as the basis of stories in Ulysses. -

Shift Cipher Substitution Cipher Vigenère Cipher Hill Cipher
Lecture 2 Classical Cryptosystems Shift cipher Substitution cipher Vigenère cipher Hill cipher 1 Shift Cipher • A Substitution Cipher • The Key Space: – [0 … 25] • Encryption given a key K: – each letter in the plaintext P is replaced with the K’th letter following the corresponding number ( shift right ) • Decryption given K: – shift left • History: K = 3, Caesar’s cipher 2 Shift Cipher • Formally: • Let P=C= K=Z 26 For 0≤K≤25 ek(x) = x+K mod 26 and dk(y) = y-K mod 26 ʚͬ, ͭ ∈ ͔ͦͪ ʛ 3 Shift Cipher: An Example ABCDEFGHIJKLMNOPQRSTUVWXYZ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 • P = CRYPTOGRAPHYISFUN Note that punctuation is often • K = 11 eliminated • C = NCJAVZRCLASJTDQFY • C → 2; 2+11 mod 26 = 13 → N • R → 17; 17+11 mod 26 = 2 → C • … • N → 13; 13+11 mod 26 = 24 → Y 4 Shift Cipher: Cryptanalysis • Can an attacker find K? – YES: exhaustive search, key space is small (<= 26 possible keys). – Once K is found, very easy to decrypt Exercise 1: decrypt the following ciphertext hphtwwxppelextoytrse Exercise 2: decrypt the following ciphertext jbcrclqrwcrvnbjenbwrwn VERY useful MATLAB functions can be found here: http://www2.math.umd.edu/~lcw/MatlabCode/ 5 General Mono-alphabetical Substitution Cipher • The key space: all possible permutations of Σ = {A, B, C, …, Z} • Encryption, given a key (permutation) π: – each letter X in the plaintext P is replaced with π(X) • Decryption, given a key π: – each letter Y in the ciphertext C is replaced with π-1(Y) • Example ABCDEFGHIJKLMNOPQRSTUVWXYZ πBADCZHWYGOQXSVTRNMSKJI PEFU • BECAUSE AZDBJSZ 6 Strength of the General Substitution Cipher • Exhaustive search is now infeasible – key space size is 26! ≈ 4*10 26 • Dominates the art of secret writing throughout the first millennium A.D. -

Network Security
Cristina Nita-Rotaru CS6740: Network security Additional material: Cryptography 1: Terminology and classic ciphers Readings for this lecture Required readings: } Cryptography on Wikipedia Interesting reading } The Code Book by Simon Singh 3 Cryptography The science of secrets… } Cryptography: the study of mathematical techniques related to aspects of providing information security services (create) } Cryptanalysis: the study of mathematical techniques for attempting to defeat information security services (break) } Cryptology: the study of cryptography and cryptanalysis (both) 4 Cryptography Basic terminology in cryptography } cryptography } plaintexts } cryptanalysis } ciphertexts } cryptology } keys } encryption } decryption plaintext ciphertext plaintext Encryption Decryption Key_Encryption Key_Decryption 5 Cryptography Cryptographic protocols } Protocols that } Enable parties } Achieve objectives (goals) } Overcome adversaries (attacks) } Need to understand } Who are the parties and the context in which they act } What are the goals of the protocols } What are the capabilities of adversaries 6 Cryptography Cryptographic protocols: Parties } The good guys } The bad guys Alice Carl Bob Eve Introduction of Alice and Bob Check out wikipedia for a longer attributed to the original RSA paper. list of malicious crypto players. 7 Cryptography Cryptographic protocols: Objectives/Goals } Most basic problem: } Ensure security of communication over an insecure medium } Basic security goals: } Confidentiality (secrecy, confidentiality) } Only the -

Algorithms and Mechanisms Historical Ciphers
Algorithms and Mechanisms Cryptography is nothing more than a mathematical framework for discussing the implications of various paranoid delusions — Don Alvarez Historical Ciphers Non-standard hieroglyphics, 1900BC Atbash cipher (Old Testament, reversed Hebrew alphabet, 600BC) Caesar cipher: letter = letter + 3 ‘fish’ ‘ilvk’ rot13: Add 13/swap alphabet halves •Usenet convention used to hide possibly offensive jokes •Applying it twice restores the original text Substitution Ciphers Simple substitution cipher: a=p,b=m,c=f,... •Break via letter frequency analysis Polyalphabetic substitution cipher 1. a = p, b = m, c = f, ... 2. a = l, b = t, c = a, ... 3. a = f, b = x, c = p, ... •Break by decomposing into individual alphabets, then solve as simple substitution One-time Pad (1917) Message s e c r e t 18 5 3 17 5 19 OTP +15 8 1 12 19 5 7 13 4 3 24 24 g m d c x x OTP is unbreakable provided •Pad is never reused (VENONA) •Unpredictable random numbers are used (physical sources, e.g. radioactive decay) One-time Pad (ctd) Used by •Russian spies •The Washington-Moscow “hot line” •CIA covert operations Many snake oil algorithms claim unbreakability by claiming to be a OTP •Pseudo-OTPs give pseudo-security Cipher machines attempted to create approximations to OTPs, first mechanically, then electronically Cipher Machines (~1920) 1. Basic component = wired rotor •Simple substitution 2. Step the rotor after each letter •Polyalphabetic substitution, period = 26 Cipher Machines (ctd) 3. Chain multiple rotors Each rotor steps the next one when a full -

Lecture 3: Classical Cryptosystems (Vigenère Cipher)
CS408 Cryptography & Internet Security Lecture 3: Classical cryptosystems (Vigenère cipher) Reza Curtmola Department of Computer Science / NJIT Towards Poly-alphabetic Substitution Ciphers l Main weaknesses of mono-alphabetic substitution ciphers § each letter in the ciphertext corresponds to only one letter in the plaintext letter l Idea for a stronger cipher (1460’s by Alberti) § use more than one cipher alphabet, and switch between them when encrypting different letters l Developed into a practical cipher by Blaise de Vigenère (published in 1586) § Was known at the time as the “indecipherable cipher” CS 408 Lecture 3 / Spring 2015 2 1 The Vigenère Cipher Definition: n Given m (a positive integer), P = C = (Z26) , and K = (k1, k2, … , km) a key, we define: Encryption: ek(p1, p2…, pm) = (p1+k1, p2+k2…, pm+km) (mod 26) Decryption: dk(c1, c2…, cm) = (c1-k1, c2-k2 …, cm- km) (mod 26) Example: key = LUCK (m = 4) plaintext: C R Y P T O G R A P H Y key: L U C K L U C K L U C K ciphertext: N L A Z E I I B L J J I CS 408 Lecture 3 / Spring 2015 3 Security of Vigenère Cipher l Vigenère masks the frequency with which a character appears in a language: one letter in the ciphertext corresponds to multiple letters in the plaintext. Makes the use of frequency analysis more difficult. l Any message encrypted by a Vigenère cipher is a collection of as many shift ciphers as there are letters in the key. CS 408 Lecture 3 / Spring 2015 4 2 Vigenère Cipher: Cryptanalysis l Find the length of the key. -

Report Eric Camellini 4494164 [email protected]
1 IN4191 SECURITY AND CRYPTOGRAPHY 2015-2016 Assignment 1 - Report Eric Camellini 4494164 [email protected] Abstract—In this report, I explain how I deciphered a message library: this function finds existing words in the text using a encrypted with a simple substitution cipher. I focus on how I used dictionary of the selected language. frequency analysis to understand the substitution pattern and I With this approach I observed that after the frequency-based also give a brief explanation of the cipher used. letter replacement the language with more word matches (with a minimum word length of 3 characters) was Dutch, so I focused on it trying to compare its letter frequency with the I. INTRODUCTION one of the ciphertext. The letters in order of frequency were The objective of this work was to decipher an encrypted the following: message using frequency analysis or brute forcing, knowing that: Ciphertext: ”ranevzbgqhoutwyfsxjipcm” • It seemed to be encrypted using a simple cipher; Dutch language: ”enatirodslghvkmubpwjczfxyq” • It was probably written without spaces or punctuation; Looking at the two lists I observed the following pattern: • The language used could be English, Dutch, German or Turkish. • The first 3 most frequent letters in the text have (r, a, The ciphertext was the following: n) a 13 letters distance in the alphabet from the 3 most frequent ones in the Dutch language (e, n, a). VaqrprzoreoeratraWhyvhfraJnygreUbyynaqreqrgjrroebrefi • Other frequent letters preserve this 13 letters distance naRqvguZnetbganneNzfgreqnzNaarjvytenntzrrxbzraznnezbrga pattern: for example the letters ’e’ and ’v’ are in the 6 btrrarragvwqwrovwbznoyvwiraBznmnyurgzbrvyvwxuroorabz most frequent letters in the ciphertex, and they are 13 NaarabtrracnnejrxraqnnegrubhqrafpuevwsgRqvguSenaxvarra letters distant from ’r’ and ’i’ respectively, that are in oevrsnnaTregehqAnhznaauhaiebrtrerohhezrvfwrvaSenaxshegn the 6 most frequent ones in the Dutch language. -

A Complete Bibliography of Publications in Cryptologia
A Complete Bibliography of Publications in Cryptologia Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 04 September 2021 Version 3.64 Title word cross-reference 10016-8810 [?, ?]. 1221 [?]. 125 [?]. 15.00/$23.60.0 [?]. 15th [?, ?]. 16th [?]. 17-18 [?]. 18 [?]. 180-4 [?]. 1812 [?]. 18th (t; m)[?]. (t; n)[?, ?]. $10.00 [?]. $12.00 [?, ?, ?, ?, ?]. 18th-Century [?]. 1930s [?]. [?]. 128 [?]. $139.99 [?]. $15.00 [?]. $16.95 1939 [?]. 1940 [?, ?]. 1940s [?]. 1941 [?]. [?]. $16.96 [?]. $18.95 [?]. $24.00 [?]. 1942 [?]. 1943 [?]. 1945 [?, ?, ?, ?, ?]. $24.00/$34 [?]. $24.95 [?, ?]. $26.95 [?]. 1946 [?, ?]. 1950s [?]. 1970s [?]. 1980s [?]. $29.95 [?]. $30.95 [?]. $39 [?]. $43.39 [?]. 1989 [?]. 19th [?, ?]. $45.00 [?]. $5.95 [?]. $54.00 [?]. $54.95 [?]. $54.99 [?]. $6.50 [?]. $6.95 [?]. $69.00 2 [?, ?]. 200/220 [?]. 2000 [?]. 2004 [?, ?]. [?]. $69.95 [?]. $75.00 [?]. $89.95 [?]. th 2008 [?]. 2009 [?]. 2011 [?]. 2013 [?, ?]. [?]. A [?]. A3 [?, ?]. χ [?]. H [?]. k [?, ?]. M 2014 [?]. 2017 [?]. 2019 [?]. 20755-6886 [?, ?]. M 3 [?]. n [?, ?, ?]. [?]. 209 [?, ?, ?, ?, ?, ?]. 20th [?]. 21 [?]. 22 [?]. 220 [?]. 24-Hour [?, ?, ?]. 25 [?, ?]. -Bit [?]. -out-of- [?, ?]. -tests [?]. 25.00/$39.30 [?]. 25.00/839.30 [?]. 25A1 [?]. 25B [?]. 26 [?, ?]. 28147 [?]. 28147-89 000 [?]. 01Q [?, ?]. [?]. 285 [?]. 294 [?]. 2in [?, ?]. 2nd [?, ?, ?, ?]. 1 [?, ?, ?, ?]. 1-4398-1763-4 [?]. 1/2in [?, ?]. 10 [?]. 100 [?]. 10011-4211 [?]. 3 [?, ?, ?, ?]. 3/4in [?, ?]. 30 [?]. 310 1 2 [?, ?, ?, ?, ?, ?, ?]. 312 [?]. 325 [?]. 3336 [?, ?, ?, ?, ?, ?]. affine [?]. [?]. 35 [?]. 36 [?]. 3rd [?]. Afluisterstation [?, ?]. After [?]. Aftermath [?]. Again [?, ?]. Against 4 [?]. 40 [?]. 44 [?]. 45 [?]. 45th [?]. 47 [?]. [?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?]. Age 4in [?, ?]. [?, ?]. Agencies [?]. Agency [?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?]. -

The Vigenère Cipher
Introduction to Cryptography CS 355 Lecture 4 The Vigenère Cipher CS 355 Fall 2005 / Lecture 4 1 Lecture Outline • Vigenère cipher. • Attacks on Vigenere: – Kasisky Test – Index of Coincidence – Frequency analysis CS 355 Fall 2005 / Lecture 4 2 Towards the Polyalphabetic Substitution Ciphers • Main weaknesses of monoalphabetic substitution ciphers – each letter in the ciphertext corresponds to only one letter in the plaintext letter • Idea for a stronger cipher (1460’s by Alberti) – use more than one cipher alphabet, and switch between them when encrypting different letters • Developed into a practical cipher by Vigenère (published in 1586) CS 355 Fall 2005 / Lecture 4 3 The Vigenère Cipher Definition: n Given m, a positive integer, P = C = (Z26) , and K = (k1, k2, … , km) a key, we define: Encryption: ek(p1, p2… pm) = (p1+k1, p2+k2…pm+km) (mod 26) Decryption: dk(c1, c2… cm) = (c1-k1, c2-k2 … cm- km) (mod 26) Example: Plaintext: C R Y P T O G R A P H Y Key: L U C K L U C K L U C K Ciphertext: N L A Z E I I B L J J I CS 355 Fall 2005 / Lecture 4 4 Security of Vigenere Cipher • Vigenere masks the frequency with which a character appears in a language: one letter in the ciphertext corresponds to multiple letters in the plaintext. Makes the use of frequency analysis more difficult. • Any message encrypted by a Vigenere cipher is a collection of as many shift ciphers as there are letters in the key. CS 355 Fall 2005 / Lecture 4 5 Vigenere Cipher: Cryptanalysis • Find the length of the key. -

2. Classic Cryptography Methods 2.1. Spartan Scytale. One of the Oldest Known Examples Is the Spartan Scytale (Scytale /Skɪtəl
2. Classic Cryptography Methods 2.1. Spartan scytale. One of the oldest known examples is the Spartan scytale (scytale /skɪtəli/, rhymes with Italy, a baton). From indirect evidence, the scytale was first mentioned by the Greek poet Archilochus who lived in the 7th century B.C. (over 2500 years ago). The ancient Greeks, and the Spartans in particular, are said to have used this cipher to communicate during military campaigns.Sender and recipient each had a cylinder (called a scytale) of exactly the same radius. The sender wound a narrow ribbon of parchment around his cylinder, then wrote on it lengthwise. After the ribbon is unwound, the writing could be read only by a person who had a cylinder of exactly the same circumference. The following table illustrate the idea. Imagine that each column wraps around the dowel one time, that is that the bottom of one column is followed by the top of the next column. Original message: Kill king tomorrow midnight Wrapped message: k i l l k i n g t o m o r r o w m i d n i g h t Encoded message: ktm ioi lmd lon kri irg noh gwt The key parameter in using the scytale encryption is the number of letters that can be recorded on one wrap ribbon around the dowel. Above the maximum was 3, since there are 3 rows in the wrapped meassage. The last row was padded with blank spaces before the message was encoded. We'll call this the wrap parameter. If you don't know the wrap parameter you cannot decode a message.