Identifying Novel Information Using Latent Semantic Analysis in the Wiqa Task at CLEF 2006
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KEENE, Carolyn
KEENE, Carolyn Harriet Stratemeyer Adams Geboren: 1892. Overleden: 1982 Zoals veel juniorenmysteries, is de Nancy Drew-serie bedacht en werd (althans in het begin) de plot geschetst door Edward Stratemeyer [> Franklin W. Dixon] van het Stratemeyer Concern. Zijn dochter, Harriet Stratemeyer Adams nam later de uitgeverij over en claimde lange tijd de schrijver te zijn van àlle Nancy Drew-verhalen vanaf 1930 tot 1982. Onderzoek bracht aan het licht dat dit niet het geval was. De Nancy-verhalen werden, evenals andere Stratemeyer-series, geschreven door een aantal voorheen anonieme professionele schrijvers, waarvan de belangrijkste Mildred A. Wirt Benson (zie onder) was tot het moment dat Harriet Adams in 1953 (vanaf nummer 30) inderdaad begon met het schrijven van nieuwe delen en ook de oude delen vanaf 1959 reviseerde. Opmerkelijk en uniek is de zorgvuldigheid waarmee geprobeerd werd alle sporen omtrent de ‘echte’ auteurs uit te wissen. Byzantijnse plotten en samenzweringen werden gesmeed om veranderde copyrights; dossiers van The Library of Congress verdwenen en niet bestaande overheidsambtenaren werden opgevoerd om de namen van de ware schrijvers uit de boeken te laten verdwijnen. (foto: Internet Book List) website: http://en.wikipedia.org/wiki/Carolyn_Keene en http://www.keeline.com/Ghostwriters.html Nederlandse website: http://ccw.110mb.com/beeldverhalen/publicaties/N/nancydrew/index.htm Mildred Augustine Wirt Benson Geboren: Ladora, Iowa, USA, 10 juli 1905. Overleden: Toledo, Ohio, 28 mei 2002 Mildred Benson schreef de eerste 25 Nancy Drew-titels en nr 30 (uitgezonderd de nrs 8, 9 en 10) en schreef daarnaast nog vele andere juniorentitels, voornamelijk avonturen voor meisjes: Ruth Fielding (o.ps. -

They're Reading the Series Books So Let's Use Them; Or, Who Is Shaun Cassidy?
if IRMO= 135111 . ID 155 844 CS 004 .113 ,* , , .!- AUTHOR, *' Abrahamsoi; Richard P. TITLE -They-fro Reading the Serifs Books So Lets: Use Thes;', or, Who Is Sham Cassidy? - ------ PUB BAIR, .Bay 78 I ROTE 17p.; Raper preheated at the innuel Meeting of thir International Reading,AssOciation 123rd; Mount**, 9 - Texas, Ray,1 -5, 1978) I -RDRS PRICE 'BF-10.83 HC -&1.67 Plus Postage. DESCRIPTORS Adolescent Literature; *EnglishInstructibig- *Learning Activities;Litits=i-tioi-sap--*Litarary N\ Perspective; Literatuie,App ion; *Reading IntereSts; Reading Bateriall; reational Bending; Senior Sigh Schools; Not atioe , IDENTIFIERS Series Books ;. ABSTRACT 4 Concerned with the need to=atimulate readiag Flamers fotolder adolescents, this documentcutlinee a high school reading uiit that capitalises on the perennial popuIirity of sesits bccits .such as Nancy Drpw, the Hardy Boys, and Tom Swift. Suggested' activities include having students reflect cn thoir.personal reading and write a fictional sketch about a favorite author; research a, : 'series author to discover the multi-asthoi-ttprcach of the series books; compare older versions. with newer revised books tc uncover sexiia, rapism, and stereotypes; -and stilted dialogue, one -, dimensional characters, and formula writing. The study of the series bookcan be extended to include the serial dine novels cfthi 1800s with their heavy moralising, poor characterisation,and--ritunted dialogue, ore historical approach to, the authorlioratio-Alger and his rags-to-riches novels, set in the later 1800e. (HI) / sii****************01**4scogeorn"***** * .Reproductions supplied by !DRS are the best that can be made / * . so, from the original docenent./ 1 * .) colosess*****mosmossoloscolossiosolossostmoshcolls ****scolcomos** p ea 114111011IPIT Of WEALTH 1110111KATIONS NAtIONAL 11STITVLII OP IDUCATIOR nos ooCusalw wAs seesREPRO mice° exam'. -

Author Melanie Rehak on Girl Sleuth: Nancy Drew and the Women Who Created Her, Interviewed by Jennifer Fisher Page 8
Drew Interview: Author Melanie Rehak on Girl Sleuth: Nancy Drew and the Women Who Created Her, Interviewed by Jennifer Fisher Page 8 A mystery solved! The mystery behind Nancy Drew and her creators is defined in Melanie Rehak’s new book, Girl Sleuth: Nancy Drew and the Women who Created Her. A revealing look at Stratemeyer Syndicate history, Rehak waxes nostalgically about the two women who had the most influence upon Nancy Drew: Mildred Wirt Benson and Harriet Stratemeyer Adams. Focusing on these two pioneering women and feminist history, she traces Nancy, Mildred, and Harriet’s footsteps through the decades and how each of them ultimately contributed to the popularity of America’s favorite teen sleuth. JF: Describe Nancy Drew in 5 words or less. MR: Resourceful, glamorous, classy, intelligent and bold. JF: What intrigued you in writing about Nancy Drew and her creators? MR: Of course I've loved Nancy since I read about her adventures as a child, so a chance to learn more about the teen detective was really appealing. Finding out that there were real-life women behind her, whose lives were in some ways as ground-breaking as Nancy's, only made her more interesting to me. I was amazed to learn that behind her fictional intrepid spirit, true struggles with power and independence were lurking. Also, the fact that these books were brought out by an organization that was made completely of women fascinated me. Even now that's rare, but certainly in the 30s and 40s it was practically unheard of. JF: Did you discover any interesting information that really stood out that most people wouldn't have a clue about in your research at the NYPL? MR: Yes, I did. -

The Secret Case of the Nancy Drew Ghostwriter and Journalist Missing Millie Benson
The Secret Case of the Nancy Drew Ghostwriter and Journalist MISSING MILLIE BENSON By Julie K. Rubini BIOGRAPHIES FOR YOUNG READERS Ohio University Press Athens Contents Author’s Note vii The First Clue Ghostwriter Reappears 1 The Case of the Missing Ghostwriter The Second Clue Little Ladora Girl with Big Dreams 10 The Case of the Wandering Feet The Third Clue College Days 20 The Case of the Hawkeye The Fourth Clue Next Steps 31 The Case of the Developing Writer The Fifth Clue New Name, New Character, New Beginning 39 The Case of the Ghostwriter The Sixth Clue Nancy Drew 48 The Case of the Young Detective The Seventh Clue Different Characters/Similar Lives 56 The Case of the Prolific Writer The Eighth Clue Sad Loss & New Beginning 65 The Case of the Budding Journalist v The Ninth Clue Take Off! 74 The Case of the Flying Reporter The Final Clues The Nancy Drew Conference, Recognition & Legacy 82 The Case of a Storied Life Extra Clues Millie’s Timeline 95 Millie’s Awards & Recognition 97 Millie’s Chronological List of Works 99 Glossary 107 Acknowledgments 109 Notes 111 Bibliography 119 vi Contents THE FIRST CLUE GHOSTWRITER REAPPEARS The Case of the Missing Ghostwriter or the first fifty years of the series, readers of the Nancy Drew FMystery Stories, whether of the originals with the dusty blue cloth covers or the newer books with the bright yellow spines, knew that all those mysteries were written by Carolyn Keene. But who was she? No one had ever met this talented writer, seen a photograph of her face, or heard her voice on the radio. -

Rose Wilder Lane, Laura Ingalls Wilder
A Reader’s Companion to A Wilder Rose By Susan Wittig Albert Copyright © 2013 by Susan Wittig Albert All rights reserved. No part of this book may be reproduced, scanned, or distributed in any printed or electronic form without permission. For information, write to Persevero Press, PO Box 1616, Bertram TX 78605. www.PerseveroPress.com Publisher’s Cataloging-in-Publication data Albert, Susan Wittig. A reader’s companion to a wilder rose / by Susan Wittig Albert. p. cm. ISBN Includes bibliographical references Wilder, Laura Ingalls, 1867-1957. 2. Lane, Rose Wilder, 1886-1968. 3. Authorship -- Collaboration. 4. Criticism. 5. Explanatory notes. 6. Discussion questions. 2 CONTENTS A Note to the Reader PART ONE Chapter One: The Little House on King Street: April 1939 Chapter Two: From Albania to Missouri: 1928 Chapter Three: Houses: 1928 Chapter Four: “This Is the End”: 1929 PART TWO Chapter Five: King Street: April 1939 Chapter Six: Mother and Daughter: 1930–1931 Chapter Seven: “When Grandma Was a Little Girl”: 1930–1931 Chapter Eight: Little House in the Big Woods: 1931 PART THREE Chapter Nine: King Street: April 1939 Chapter Ten: Let the Hurricane Roar: 1932 Chapter Eleven: A Year of Losses: 1933 PART FOUR Chapter Twelve: King Street: April 1939 Chapter Thirteen: Mother and Sons: 1933–1934 3 Chapter Fourteen: Escape and Old Home Town: 1935 Chapter Fifteen: “Credo”: 1936 Chapter Sixteen: On the Banks of Plum Creek: 1936–1937 Chapter Seventeen: King Street: April 1939 Epilogue The Rest of the Story: “Our Wild Rose at her Wildest ” Historical People Discussion Questions Bibliography 4 A Note to the Reader Writing novels about real people can be a tricky business. -

A Nancy for All Seasons
Tanja Blaschitz A Nancy For All Seasons DIPLOMARBEIT zur Erlangung des akademischen Grades Magistra der Philosophie Studium: Lehramt Unterrichtsfach Englisch/ Unterrichtsfach Italienisch Alpen-Adria-Universität Klagenfurt Fakultät für Kulturwissenschaften Begutachter: Ao.Univ.-Prof. Mag. Dr. Heinz Tschachler Institut: Anglistik und Amerikanistik April 2010 Ehrenwörtliche Erklärung Ich erkläre ehrenwörtlich, dass ich die vorliegende wissenschaftliche Arbeit selbststän- dig angefertigt und die mit ihr unmittelbar verbundenen Tätigkeiten selbst erbracht habe. Ich erkläre weiters, dass ich keine anderen als die angegebenen Hilfsmittel be- nutzt habe. Alle aus gedruckten, ungedruckten oder dem Internet im Wortlaut oder im wesentlichen Inhalt übernommenen Formulierungen und Konzepte sind gemäß den Re- geln für wissenschaftliche Arbeiten zitiert und durch Fußnoten bzw. durch andere genaue Quellenangaben gekennzeichnet. Die während des Arbeitsvorganges gewährte Unterstützung einschließlich signifikanter Betreuungshinweise ist vollständig angegeben. Die wissenschaftliche Arbeit ist noch keiner anderen Prüfungsbehörde vorgelegt wor- den. Diese Arbeit wurde in gedruckter und elektronischer Form abgegeben. Ich bestätige, dass der Inhalt der digitalen Version vollständig mit dem der gedruckten Ver- sion übereinstimmt. Ich bin mir bewusst, dass eine falsche Erklärung rechtliche Folgen haben wird. Tanja Blaschitz Völkermarkt, 30. April 2010 iii Acknowledgement I can no other answer make, but, thanks, and thanks. by William Shakespeare I would like to use this page to thank the following persons who made the com- pletion of my diploma thesis possible: At the very beginning I would like to thank Professor Heinz Tschachler for his kind support and stimulating advice in the supervision of my diploma thesis. I would also like to thank my dearest friends who have helped me with words and deeds throughout my education. -
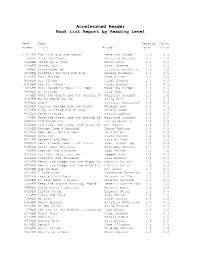
Accelerated Reader Book List Report by Reading Level
Accelerated Reader Book List Report by Reading Level Test Book Reading Point Number Title Author Level Value -------------------------------------------------------------------------- 27212EN The Lion and the Mouse Beverley Randell 1.0 0.5 330EN Nate the Great Marjorie Sharmat 1.1 1.0 6648EN Sheep in a Jeep Nancy Shaw 1.1 0.5 9338EN Shine, Sun! Carol Greene 1.2 0.5 345EN Sunny-Side Up Patricia Reilly Gi 1.2 1.0 6059EN Clifford the Big Red Dog Norman Bridwell 1.3 0.5 9454EN Farm Noises Jane Miller 1.3 0.5 9314EN Hi, Clouds Carol Greene 1.3 0.5 9318EN Ice Is...Whee! Carol Greene 1.3 0.5 27205EN Mrs. Spider's Beautiful Web Beverley Randell 1.3 0.5 9464EN My Friends Taro Gomi 1.3 0.5 678EN Nate the Great and the Musical N Marjorie Sharmat 1.3 1.0 9467EN Watch Where You Go Sally Noll 1.3 0.5 9306EN Bugs! Patricia McKissack 1.4 0.5 6110EN Curious George and the Pizza Margret Rey 1.4 0.5 6116EN Frog and Toad Are Friends Arnold Lobel 1.4 0.5 9312EN Go-With Words Bonnie Dobkin 1.4 0.5 430EN Nate the Great and the Boring Be Marjorie Sharmat 1.4 1.0 6080EN Old Black Fly Jim Aylesworth 1.4 0.5 9042EN One Fish, Two Fish, Red Fish, Bl Dr. Seuss 1.4 0.5 6136EN Possum Come a-Knockin' Nancy VanLaan 1.4 0.5 6137EN Red Leaf, Yellow Leaf Lois Ehlert 1.4 0.5 9340EN Snow Joe Carol Greene 1.4 0.5 9342EN Spiders and Webs Carolyn Lunn 1.4 0.5 9564EN Best Friends Wear Pink Tutus Sheri Brownrigg 1.5 0.5 9305EN Bonk! Goes the Ball Philippa Stevens 1.5 0.5 408EN Cookies and Crutches Judy Delton 1.5 1.0 9310EN Eat Your Peas, Louise! Pegeen Snow 1.5 0.5 6114EN Fievel's Big Showdown Gail Herman 1.5 0.5 6119EN Henry and Mudge and the Happy Ca Cynthia Rylant 1.5 0.5 9477EN Henry and Mudge and the Wild Win Cynthia Rylant 1.5 0.5 9023EN Hop on Pop Dr. -

Susan and Bill Albert's Book List
Susan and Bill Albert's Book List Susan and Bill had been writing together for some time before they began to write mysteries for adults. At the request of readers, book collectors, and librarians, here is a list of all their books, organized according to the name or pseudonym they used. Susan’s books (written independently) are listed first; their co-authored books are listed second. Bill's independent writing consists of the computer programs, documentation, and technical manuals he wrote in his previous incarnation as a systems analyst—he doesn’t think you'd be interested in that stuff. Susan Wittig Albert Nonfiction, Academic Studies Written as Susan Wittig Stylist and Narrative Structures in the Middle English Verse Romances, University of Texas, Austin, 1977 Steps to Structure, Winthrop Publishing Company, 1975. Structuralism: A Reader, Pickwick Press, 1976 The Participating Reader, Prentice-Hall, 1979 Young Adult and Middle Grades Fiction Written as Susan Blake Haunted Dollhouse, Twilight #22, Dell, 1984 Summer Breezes, Sweet Dreams #60, Bantam, 1984 The Last Word, Sweet Dreams #84, Bantam, 1985 Summer Secrets, Sweet Dreams #150, Bantam, 1988 Cross-Country Match, Sweet Dreams #152, Bantam, 1988 A Change of Heart, Sweet Dreams Special, Bantam, 1986 Trading Hearts, Sweet Dreams #162, Bantam, 1989 What They Don't Teach You in Junior High, Fifteen #4, NAL, 1986 All Out of Grape Jelly, Fifteen #6, NAL, 1986 Making It, Cheerleaders #19, Scholastic, 1986 Head Over Heels, First Kiss #1, Ballantine, 1988 All-Nighter, Roommates #1, Random House, 1987 Crash Course, Roommates #2, Random House, 1987 Major Changes, Roommates #3, Random House, 1987 Extra Credit, Roommates #4, Random House, 1989 Final Exams, Roommates #5, Random House, 1989 Multiple Choice, Roommates #6, Random House, 1989 Written as Ann Cole The Boy Next Door, Sisters #15, Fawcett, 1989 Written as Linda Cooney Perfect Strangers, Sunset High #8, Fawcett, 1986 Written as M. -

Audrey Tsang February 21, 2001 STS 145 Nancy
Audrey Tsang February 21, 2001 STS 145 Nancy Drew: Message in a Haunted Mansion A Investigation in Girl Games Introduction: I first encountered Nancy Drew in Third Grade, on the books-for-borrowing shelf stuffed in the back corner of my classroom, next to our cubbies. On the bottom shelf, bound in tattered and faded hardcovers was a complete set of Nancy Drew novels, from book 1 to maybe book 60. With no preconceptions of Nancy Drew, I pulled one title from the shelf, and judging a book by its cover, decided to read it. Mystery of Crocodile Island had a picture of young girl, facing a beady-eyed crocodile with its mouth gaping open – teeth, gums, drool, and everything. I think I read that book in a day, which was quite impressive for my Third Grade reading level. What kept the pages turning was the suspense, intrigue, and action. I wanted to be the eighteen year-old, competent, and attractive Nancy Drew. A decade and a half later, I’m finding myself reviewing Nancy Drew, not the books this time, but the “3D interactive mystery game” as it calls itself on the CD case. Granted, I’m not the wide-eyed eight year-old anymore, can “Nancy Drew: Message in a Haunted Mansion” live up to that day in Third Grade? Game Identification: “Nancy Drew: Message in a Haunted Mansion” was released as a PC game in November of 2000, designed and developed by Her Interactive and produced by Dream Catcher. “Message” is the fifth game put out by Her Interactive and the third in the company’s Nancy Drew series. -

75 of My Favorite Things by “Carolyn Keene” Page 35
75 of My Favorite Things by “Carolyn Keene” Page 35 1. Russell H. Tandy artwork 2. Storms 3. The Hidden Staircase 4. The Secret in the Old Attic 5. Hannah Gruen’s cooking 6. A baffling mystery 7. Original text melodrama from the 1930s and 1940s 8. The genius of Edward Stratemeyer 9. Curling up on the Drew’s davenport 10. Fabulous heels 11. Taylor’s Department Store 12. Those snooty Topham Sisters 13. A trusty flashlight 14. Dirk Valentine’s treasure 15. Buck Rodman 16. Ned Nickerson 17. Moon Lake 18. Bumbling villain Frank Semitt/Jemitt 19. Mildred Wirt Benson’s writing style and flair 20. Nancy Drew’s pluck 21. Nancy’s roadster 22. George Fayne’s bluntness Page 36 23. Bess Marvin’s dreaminess 24. Finding money in old books (The Phantom of Pine Hill) 25. Lilacs 26. Quaint roadside tearooms 27. The Nancy Drew silhouette 28. Harriet Stratemeyer Adam’s inclusion of knowledge to be learned in each book 29. A good cliffhanger 30. The perfect sleuthing frock 31. Lipstick S0S 32. Secret passageways 33. Travelogues 34. A suspenseful yarn 35. Red Gate Farm 36. The absurdity of The Flying Saucer Mystery 37. Nancy Drew aliases 38. Lucky coincidences 39. Spooky old inns and mansions 40. Hard headed sleuth–100's of knockouts and still going strong 41. Using science to outwit criminals (Archimedes’ lever in The Secret of the Old Clock) 42. Foiling villains 43. Learning about Nancy Drew’s ancestry 44. Drew home burglaries Page 37 45. Cheesy villain foibles like All-Purpose Assailant Rocks 46. -

The Ghost of Nancy Drew
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Iowa Research Online The Ghost of Nancy Drew GEOFFREY S. LAPIN "It would be a shame if all that money went to the Tophams! They will fly higher than ever!" Thus begins the first book in a series of titles that has whetted the literary appetites of young readers for well over fifty years. The Secret of the Old Clock by Carolyn Keene was to set the tone of juvenile adventure stories that is still leading young folks into the joys of reading the standard classics of literature. Carolyn Keene has been writing the series books chronicling the adventures of Nancy Drew and the Dana Girls since 1929. With over 175 titles published, the author is still going strong, presently producing over fifteen new books each year. Her titles have been translated into at least twelve different lan guages, and sales records state that the volumes sold number in the hundreds of millions. More than the mystery of the endurance of such unlikely literature is the question of who Carolyn Keene is and how one person could possibly be the author of such a record number of "best-sellers." Numerous literary histories offer conflicting information concerning the life of Ms Keene. The one common fact is that there exists no actual person by that name. Carolyn Keene is a pseudonym for the author of the series books. Carolyn Keene was Edward Stratemeyer. Another source says that she was Harriet Adams. Yet others say that she was Edna Squire, Walter Karig, James Duncan Lawrence, Nancy Axelrad, Margaret Scherf, Grace Grote, and a plethora of others. -

Magazines List
MAGAZINES LIST: Allure January 2002, pg. 62. “Fashion Report.” --Quote from Nancy Drew’s Guide to Life on spike heels. American Country Collectibles Summer 1996, pg. 26-27+. "The Girl Detective - Teenage Sleuth Nancy Drew Turns 66 This Year" by Doris Goldstein. American Girl August 2004, pg. 36. August Calendar. Features Nancy Drew on the 10 th —new Girl Detective books American Way, American Airlines mag September 15, 1998, pg. 54-57+. “Hot on the Trail of Nancy Drew, Dick and Jane, Tom Swift…” by Les Daly. (Mostly about collecting the old books…) Americana October 1986, pg. 56-58. “Nancy Drew’s New Look” by Gail Greco. Antiques & Collecting August 1993, pg. 29-31. "The Quest for Nancy Drew" by Bernadine Chapman. The Antiques Journal July 1975, pg. 46-48. “Nancy Drew Collectibles” by Mary Ellen Johnson & Bernadine Chapman. Architectural Digest Dec. 1993, pg. 88-99. “AD visits: Barbara Streisand” by Pilar Viladas. Streisand collects ND books—shows a maroon roadster she bought because ND rode around in one. The Atlantic October 2005, pg. 115-120. “The Secret of the Old Saw” by Sandra Tsing Loh. Biblio March 1998, pg. 16-21. “Nancy Drew, Mon Amour” by Bob Hicks. Book May/June 2002, pg. 27-28. “Sleuth or dare” by K.K. part of young readers section The Boston Globe Magazine June 6, 1993, pg. 18-23. “The Case of the Girl Detective” by Judy Polumbaum. Bust Dec/Jan 2006, pg. 88-91. “The Importance of Being Nancy” by Allison Devers. Calling All Girls October 1942, pg. 26-28+. Mystery at the Lookout, part 2? by Carolyn Keene.