Statistical Approach to the Optimisation of the Technical Analysis Trading Tools: Trading Bands Strategies Marta Ryazanova Oleksiv
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Calibration of Bollinger Bands Parameters for Trading Strategy Development in the Baltic Stock Market
ISSN 1392 – 2785 Inzinerine Ekonomika-Engineering Economics, 2010, 21(3), 244-254 Calibration of Bollinger Bands Parameters for Trading Strategy Development in the Baltic Stock Market Audrius Kabasinskas, Ugnius Macys Kaunas University of Technology K. Donelaicio st. 73, LT-44029, Kaunas, Lithuania e-mail: [email protected], [email protected] In recent decades there was a robust boom in "Bollinger plotter" was developed using the most investment sector in Lithuania, as more people chose to popular mathematical toolbox MatLab in order to solve invest money in investment funds rather than keep money in stated problems. Application is capable of charting the closet. The Baltic States Market turnover has increased Bollinger Bands and 6 other technical indicators with from 721 MEUR in 2000 to 978 MEUR in 2008 (with peak desired period of time. This software is not a fully 2603 MEUR in 2005). When difficult period appeared in automated decision making system, as decisions are global markets, a lot of attention was dedicated towards the usually made based on value judgment. managing of investments. Investment management firms in Since the stock returns usually have distributions with Lithuania gain significance in personal as well as in fat tails, then less than 95% of data fit in the Bollinger business section increasingly; even though these firms are trading channels. However the Bollinger bands trading considerably young (the first one in Lithuania was signals were supported by additional indicators (e.g. %b), established in year 2000). so the loss of data is not significant. Successful investment begins with the financial Our calibration results show that short term investor analysis of stock, asset or index, which you are going to should apply 10 days moving average and use a trading invest. -

FOREX WAVE THEORY.Pdf
FOREX WAVE THEORY This page intentionally left blank FOREX WAVE THEORY A Technical Analysis for Spot and Futures Currency Traders JAMES L. BICKFORD McGraw-Hill New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Copyright © 2007 by The McGraw-Hill Companies. All rights reserved. Manufactured in the United States of America. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher. 0-07-151046-X The material in this eBook also appears in the print version of this title: 0-07-149302-6. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefit of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales pro- motions, or for use in corporate training programs. For more information, please contact George Hoare, Special Sales, at [email protected] or (212) 904-4069. TERMS OF USE This is a copyrighted work and The McGraw-Hill Companies, Inc. (“McGraw-Hill”) and its licen- sors reserve all rights in and to the work. Use of this work is subject to these terms. -

Modeling and Analyzing Stock Trends
Modeling and Analyzing Stock Trends A Major Qualifying Project Submitted to the Faculty of Worcester Polytechnic Institute in partial fulllment of the requirements for the Degree in Bachelor of Science Mathematical Sciences By Laura Cintron Garcia Date: 5/6/2021 Advisor: Dr. Mayer Humi This report represents work of WPI undergraduate students submitted to the faculty as evidence of a degree requirement. WPI routinely publishes these reports on its web site without editorial or peer review. For more information about the projects program at WPI, see http://www.wpi.edu/Academics/Projects 1 Abstract Abstract The goal of this project is to create and compare several dierent stock prediction models and nd a correlation between the predic- tions and volatility for each stock. The models were created using the historical data, DJI index, and moving averages. The most accurate prediction model had an average of 5.3 days spent within a predic- tion band. A correlation of -0.0438 was found between that model an a measure of volatility, indicating that more prediction days means lower volatility. 2 2 Acknowledgments Without the help of some people, it would have been signicantly more di- cult to complete this project without a group. I want to extend my gratitude to Worcester Polytechnic Institute and the WPI Math Department for their great eorts and success this year regarding school and projects during the pandemic. They did everything they could to ensure these projects was still a rich experience for the students despite everything. I would also like to thank my MQP advisor, Professor Mayer Humi for his assistance and guidance on this project, for allowing me to work indepen- dently while always being willing to meet with me or answer any questions, and for continuously encouraging me to do what I thought was best for the project. -

Earth & Sky Trading System
Earth & Sky Trading System By Pierre Du Plessis 1 Copyright © Forex Mentor Pro 2011. All rights reserved. Any redistribution or reproduction of part or all of the contents in any form is prohibited other than the following: You may print or download to a local hard disk copies for your personal and non- commercial use only; You may not, except with our express written permission, distribute or commercially exploit the content. Nor may you transmit it or store it in any other website or other form of electronic retrieval system. Risk Disclosure Statement The contents of this e-Book are for informational purposes only. No part of this publication is a solicitation or an offer to buy or sell any financial market. Examples are provided for illustration purposes only and should not be construed as investment advice or strategy. All trade examples are hypothetical. No representation is made that any account or trader will or is likely to achieve profits or loses similar to those discussed in this e-Book. By purchasing this e-Book, and/or subscribing to our mailing list you will be deemed to have accepted these and all other terms found on our web page ForexMentorPro.com in full. The information found in this e-Book is not intended for distribution to, or use by any person or entity in any jurisdiction or country where such distribution or use would be contrary to the law or regulation or which would subject us to any registration requirement within such jurisdiction or country. CFTC RULE 4.41 HYPOTHETICAL OR SIMULATED PERFORMANCE RESULTS HAVE CERTAIN LIMITATIONS. -

© 2012, Bigtrends
1 © 2012, BigTrends Congratulations! You are now enhancing your quest to become a successful trader. The tools and tips you will find in this technical analysis primer will be useful to the novice and the pro alike. While there is a wealth of information about trading available, BigTrends.com has put together this concise, yet powerful, compilation of the most meaningful analytical tools. You’ll learn to create and interpret the same data that we use every day to make trading recommendations! This course is designed to be read in sequence, as each section builds upon knowledge you gained in the previous section. It’s also compact, with plenty of real life examples rather than a lot of theory. While some of these tools will be more useful than others, your goal is to find the ones that work best for you. Foreword Technical analysis. Those words have come to have much more meaning during the bear market of the early 2000’s. As investors have come to realize that strong fundamental data does not always equate to a strong stock performance, the role of alternative methods of investment selection has grown. Technical analysis is one of those methods. Once only a curiosity to most, technical analysis is now becoming the preferred method for many. But technical analysis tools are like fireworks – dangerous if used improperly. That’s why this book is such a valuable tool to those who read it and properly grasp the concepts. The following pages are an introduction to many of our favorite analytical tools, and we hope that you will learn the ‘why’ as well as the ‘what’ behind each of the indicators. -

Technical-Analysis-Bloomberg.Pdf
TECHNICAL ANALYSIS Handbook 2003 Bloomberg L.P. All rights reserved. 1 There are two principles of analysis used to forecast price movements in the financial markets -- fundamental analysis and technical analysis. Fundamental analysis, depending on the market being analyzed, can deal with economic factors that focus mainly on supply and demand (commodities) or valuing a company based upon its financial strength (equities). Fundamental analysis helps to determine what to buy or sell. Technical analysis is solely the study of market, or price action through the use of graphs and charts. Technical analysis helps to determine when to buy and sell. Technical analysis has been used for thousands of years and can be applied to any market, an advantage over fundamental analysis. Most advocates of technical analysis, also called technicians, believe it is very likely for an investor to overlook some piece of fundamental information that could substantially affect the market. This fact, the technician believes, discourages the sole use of fundamental analysis. Technicians believe that the study of market action will tell all; that each and every fundamental aspect will be revealed through market action. Market action includes three principal sources of information available to the technician -- price, volume, and open interest. Technical analysis is based upon three main premises; 1) Market action discounts everything; 2) Prices move in trends; and 3) History repeats itself. This manual was designed to help introduce the technical indicators that are available on The Bloomberg Professional Service. Each technical indicator is presented using the suggested settings developed by the creator, but can be altered to reflect the users’ preference. -

A Linear Process Approach to Short-Term Trading Using the VIX Index As a Sentiment Indicator
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 29 July 2021 Article A Linear Process Approach to Short-term Trading Using the VIX Index as a Sentiment Indicator Yawo Mamoua Kobara 1,‡ , Cemre Pehlivanoglu 2,‡* and Okechukwu Joshua Okigbo 3,‡ 1 Western University; [email protected] 2 Cidel Financial Services; [email protected] 3 WorldQuant University; [email protected] * Correspondence: [email protected] ‡ These authors contributed equally to this work. 1 Abstract: One of the key challenges of stock trading is the stock prices follow a random walk 2 process, which is a special case of a stochastic process, and are highly sensitive to new information. 3 A random walk process is difficult to predict in the short-term. Many linear process models that 4 are being used to predict financial time series are structural models that provide an important 5 decision boundary, albeit not adequately considering the correlation or causal effect of market 6 sentiment on stock prices. This research seeks to increase the predictive capability of linear process 7 models using the SPDR S&P 500 ETF (SPY) and the CBOE Volatility (VIX) Index as a proxy for 8 market sentiment. Three econometric models are considered to forecast SPY prices: (i) Auto 9 Regressive Integrated Moving Average (ARIMA), (ii) Generalized Auto Regressive Conditional 10 Heteroskedasticity (GARCH), and (iii) Vector Autoregression (VAR). These models are integrated 11 into two technical indicators, Bollinger Bands and Moving Average Convergence Divergence 12 (MACD), focusing on forecast performance. The profitability of various algorithmic trading 13 strategies are compared based on a combination of these two indicators. -

Statistical Process Control Techniques in Technical Analysis
Statistical Process Control Techniques in Technical Analysis Leonard H. Smith, CMT SOT in a trending period. and quantifiable methodscan be used Abstract to take trending systemsout of the market during non-trending This paper addresses Statistical Process Control (SPC) tech- drawdownperiods, thereby improving mechanicalsystem timing. niques applied to Technical Analysis. The premise is that simple The challengefor the market technician is to determine whirh methods from manufacturing Statistical Process Control can be market behavior is worth trading with zdzattechnique. Statistical used to determine when a statistically significant tradable event methods can be applied to the market and lead to a trending or has occurred. non-trending conclusiononce a threshold probability assumption This paper proposes an Orderliness Indicator that has predic- is selected. A trading method can be selected once the market tire value on expected LACK of price change. has been categorized as trending or non-trending. One strateg) SPC-derived trading systems are shown that use: would be used for a random or non-trending market. X different Rule 1: Price movement outside a range of expected prices is trading strategy would be designed for trending markets. One usedas a trade setup, and application might be to sell options when the end of a trend is Rule 4: X moving average technique will be introduced, and signaled.The end of a trend usuall!; has high option premiums R Rule: Price change as an entry stop in combination with a and selling them with appropriate risk control could be quanti- simple exit rule. fied. SPC methods offer a simple way of evaluating market trend behaviors with statisticaltechniques. -

The SAVI Indicator
The SAVI Indicator The JSE introduces a new “Fear Factor” Investor greed and fear play a significant and often irrational role in any financial market. These market sentiments can be seen in the volatility of the market – high volatility with large market moves suggest a fearful market while low volatility with little market movement indicates a lack of fear. How can investors measure this market sentiment and use this in their investment decisions? A volatility index or “fear gauge” is a reference number that can be used to indicate market risk at a glance. The first volatility index known as the VIX was developed by the Chicago Board Options Exchange in 1993 to measure the volatility of the S&P500. In 2007, the JSE launched the South African Volatility Index or SAVI to measure equity risk in South Africa; this was the first of its kind in an emerging economy. The SAVI is similar to the VIX, with the difference being that the US index measures implied volatility over one month, while the SAVI looks forward three months. The Ultimate "Fear Gauge" For Beating the Crowds to Big Profits It may be as cliché as it gets, but it's true. Investors are motivated by two things and two things only: Fear and Greed. It's just that simple. So more often than not, they turn quite bullish when they think a stock is headed higher and quite bearish when they fear that all is lost. The trouble with this strategy though, is that for most retail investors, it is exactly at these extremes in sentiment that they often lose their shirts. -
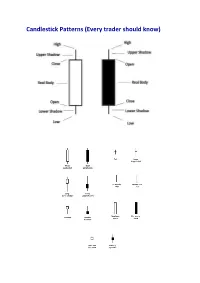
Candlestick Patterns (Every Trader Should Know)
Candlestick Patterns (Every trader should know) A doji represents an equilibrium between supply and demand, a tug of war that neither the bulls nor bears are winning. In the case of an uptrend, the bulls have by definition won previous battles because prices have moved higher. Now, the outcome of the latest skirmish is in doubt. After a long downtrend, the opposite is true. The bears have been victorious in previous battles, forcing prices down. Now the bulls have found courage to buy, and the tide may be ready to turn. For example = INET Doji Star A “long-legged” doji is a far more dramatic candle. It says that prices moved far higher on the day, but then profit taking kicked in. Typically, a very large upper shadow is left. A close below the midpoint of the candle shows a lot of weakness. Here’s an example of a long-legged doji. For example = K Long-legged Doji A “gravestone doji” as the name implies, is probably the most ominous candle of all, on that day, price rallied, but could not stand the altitude they achieved. By the end of the day. They came back and closed at the same level. Here ’s an example of a gravestone doji: A “Dragonfly” doji depicts a day on which prices opened high, sold off, and then returned to the opening price. Dragonflies are fairly infrequent. When they do occur, however, they often resolve bullishly (provided the stock is not already overbought as show by Bollinger bands and indicators such as stochastic). For example = DSGT The hangman candle , so named because it looks like a person who has been executed with legs swinging beneath, always occurs after an extended uptrend The hangman occurs because traders, seeing a sell-off in the shares, rush in to grab the stock a bargain price. -

Exchange Rate Forecasts with Candlestick Patterns and Expert Systems
Exchange Rate Forecasts with Candlestick Patterns and Expert Systems Masterarbeit zur Erlangung des akademischen Grades „Master of Science (M.Sc.)“ im Studiengang Wirt- schaftsingenieur der Fakultät für Elektrotechnik und Informatik, Fakultät für Maschinenbau und der Wirtschaftswissenschaftlichen Fakultät der Leibniz Universität Hannover vorgelegt von Name: Amelsberg Vorname: Nanno Prüfer: Prof. Dr. M. H. Breitner Hannover, den 20.08.2014 List of contents List of figures ......................................................................................................................... IV List of tables ............................................................................................................................. V List of abbreviations .............................................................................................................. VI 1 Introduction ....................................................................................................................... 1 1.1 Problem definitions ...................................................................................................... 1 1.2 Objectives .................................................................................................................... 1 1.3 Methodology ................................................................................................................ 2 2 Basics .................................................................................................................................. 4 2.1 Fundamental -

Luckscout Ultimate Wealth System
Candlesticks Signals and Patterns by LuckScout.com Team Copyright 2017 Version 1.1 www.LuckScout.com 1 Copyright and Disclaimer Copyright 2017 by LuckScout.com Team. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, mechanical or electronic, including photocopying and recording, or by any information storage and retrieval system, without permission in writing from the author (except by a reviewer, who may quote brief passages and/or short brief video clips in a review). Disclaimer: The authors make no representations or warranties with respect to the accuracy or completeness of the contents of this work and specially disclaim all warranties, including without limitation, warranties for a particular purpose. No warranty may be created or extended by sales or promotional materials. The advice and strategies contained herein may not be suitable for every situation. This work is sold with the understanding that the authors are not engaged in rendering legal, accounting, or other professional services. If professional assistance is required, this should be sought from applicable parties. The authors shall not be liable for damages arising herefrom. The fact that an organization or website is referred to in this work as a citation and/or a potential source of further information, does not mean that the authors endorse the information the organization/website may provide or recommendations it may make. Further, readers should be aware that Internet websites listed in this work may