A Multi-Level Approach to Waste Object Segmentation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Determining the Online Measurable Input Variables in Human Joint Moment Intelligent Prediction Based on the Hill Muscle Model
sensors Article Determining the Online Measurable Input Variables in Human Joint Moment Intelligent Prediction Based on the Hill Muscle Model Baoping Xiong 1,2 , Nianyin Zeng 3,*, Yurong Li 4 , Min Du 1,5,*, Meilan Huang 1, Wuxiang Shi 1, Guojun Mao 2 and Yuan Yang 6,* 1 College of Physics and Information Engineering, Fuzhou University, Fuzhou City 350116, Fujian Province, China; [email protected] (B.X.); [email protected] (M.H.); [email protected] (W.S.) 2 Department of Mathematics and Physics, Fujian University of Technology, Fuzhou City 350118, Fujian Province, China; [email protected] 3 Department of Instrumental and Electrical Engineering, Xiamen University, Fujian 361005, China 4 Fujian Key Laboratory of Medical Instrumentation & Pharmaceutical Technology, Fuzhou University, Fuzhou City 350116, Fujian Province, China; [email protected] 5 Fujian provincial key laboratory of eco-industrial green technology, Wuyi University, Wuyishan City 354300, Fujian Province, China 6 Department of Physical Therapy and Human Movement Sciences, Northwestern University, Chicago, IL 60208, USA * Correspondence: [email protected] (N.Z.); [email protected] (M.D.); [email protected] (Y.Y.) Received: 15 January 2020; Accepted: 19 February 2020; Published: 21 February 2020 Abstract: Introduction: Human joint moment is a critical parameter to rehabilitation assessment and human-robot interaction, which can be predicted using an artificial neural network (ANN) model. However, challenge remains as lack of an effective approach to determining the input variables for the ANN model in joint moment prediction, which determines the number of input sensors and the complexity of prediction. Methods: To address this research gap, this study develops a mathematical model based on the Hill muscle model to determining the online input variables of the ANN for the prediction of joint moments. -

Cross-Complementary Subsets in Paratopological Groups
Hacettepe Journal of Hacet. J. Math. Stat. Volume 49 (1) (2020), 1 – 7 Mathematics & Statistics DOI : 10.15672/HJMS.2018.647 Research Article Cross-complementary subsets in paratopological groups Weihua Lin1,2, Lianhua Fang3, Li-Hong Xie∗4 1 College of Mathematics and Informatics, Fujian Normal University, Fuzhou 350007, P.R. China 2 School of Mathematics and Statistics Minnan Normal University, Zhangzhou 363000, P.R. China 3 General Education Center, Quanzhou University of Information Engineering, Quanzhou, 362000, P.R. China 4 School of Mathematics and Computational Science, Wuyi University, Jiangmen 529020, P.R. China Abstract The following general question is considered by A.V. Arhangel’skiˇı[Perfect mappings in topological groups, cross-complementary subsets and quotients, Comment. Math. Univ. Carolin. 2003]. Suppose that G is a topological group, and F, M are subspaces of G such that G = MF . Under these general assumptions, how are the properties of F and M related to the properties of G? Also, A.V. Arhangel’skiˇıand M. Tkachenko [Topological Groups and Related Structures, Atlantis Press, World Sci., 2008] asked what is about the above question in paratopological groups [Open problem 4.6.9, Topological Groups and Related Structures, Atlantis Press, World Sci. 2008]. In this paper, we mainly consider this question and some positive answers to this question are given. In particular, we find many A.V. Arhangel’skiˇı’sresults hold for k-gentle paratopological groups. Mathematics Subject Classification (2010). 22A05, 54H11, 54D35, 54D60 Keywords. paratopological groups, k-gentle paratopological groups, perfect mappings, paracompact p-spaces, metrizable groups, countable tightnesses 1. Introduction Recall that a semitopological group is a group with a topology such that the multi- plication in the group is separately continuous. -

ICISCE 2018 Program Committee
ICISCE 2018 Program Committee Ankur Singh Bist, Mohla pahari darwaga, Dhampur-District Bijnor (U.P.), India Basabi Chakraborty, Iwate Pref. University, Japan Bing Xie, Peking University, China Binqi Li, Jimei University, China Bo Fan, Henan University of Science and Technology, China Bofeng Zhang, Shanghai University, China Changjing Lu, Sanming University, China Chaokun Yu, Minjiang University, China Chen Wang, Huazhong University of Science and Technology, China Chunmin Gao, Hunan University, China Dagmar Habe, Fraunhofer Institute for Industrial Engineering, Germany Daniel Tse, City University of Hong Kong, Hong Kong David Ramamonjisoa, Iwate Pref. University, Japan David Tein-Yaw Chung, Yuan Ze University, Taiwan Davide Ciucci, Italy Duansheng Chen, Huaqiao University, China Feng Liu, University of Wisconsin, Madison, USA Feng Zhao, Huazhong University of Science and Technology, China Feng Zhu, Zhangzhou Normal University, China Gabor Kiss, Obuda University, Hungary Gansen Zhao, South China Normal University, China Gaoping Wang, Henan University of Technology, China Georg Peters, Germany Gongde Guo, Fujian Normal University, China Goutam Chakraborty, Iwate Pref. University, Japan Guangtao Wang, Xi’an Jiaotong University, China Guolong Chen, Fuzhou University, China Guo-Ruei Wu, Toko University, Taiwan Hai Huang, Zhejiang Science Technology University, China Haibin Zhu, Nipissing University, Canada Haifeng Zhao, Anhui University, China Harry H. Cheng, University of California, Davis, USA Heng-Da Cheng, Utah State University, USA Hiromi -

A Complete Collection of Chinese Institutes and Universities For
Study in China——All China Universities All China Universities 2019.12 Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities Anhui 安徽 【www.studyinanhui.com】 1. Anhui University 安徽大学 http://ahu.admissions.cn 2. University of Science and Technology of China 中国科学技术大学 http://ustc.admissions.cn 3. Hefei University of Technology 合肥工业大学 http://hfut.admissions.cn 4. Anhui University of Technology 安徽工业大学 http://ahut.admissions.cn 5. Anhui University of Science and Technology 安徽理工大学 http://aust.admissions.cn 6. Anhui Engineering University 安徽工程大学 http://ahpu.admissions.cn 7. Anhui Agricultural University 安徽农业大学 http://ahau.admissions.cn 8. Anhui Medical University 安徽医科大学 http://ahmu.admissions.cn 9. Bengbu Medical College 蚌埠医学院 http://bbmc.admissions.cn 10. Wannan Medical College 皖南医学院 http://wnmc.admissions.cn 11. Anhui University of Chinese Medicine 安徽中医药大学 http://ahtcm.admissions.cn 12. Anhui Normal University 安徽师范大学 http://ahnu.admissions.cn 13. Fuyang Normal University 阜阳师范大学 http://fynu.admissions.cn 14. Anqing Teachers College 安庆师范大学 http://aqtc.admissions.cn 15. Huaibei Normal University 淮北师范大学 http://chnu.admissions.cn Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities 16. Huangshan University 黄山学院 http://hsu.admissions.cn 17. Western Anhui University 皖西学院 http://wxc.admissions.cn 18. Chuzhou University 滁州学院 http://chzu.admissions.cn 19. Anhui University of Finance & Economics 安徽财经大学 http://aufe.admissions.cn 20. Suzhou University 宿州学院 http://ahszu.admissions.cn 21. -

Exploring a New Chinese Model of Tourism and Hospitality Education
2017 International Conference on Energy, Environment and Sustainable Development (EESD 2017) ISBN: 978-1-60595-452-3 Exploring a New Chinese Model of Tourism and Hospitality Education: Lessons Learned from American Counterparts Jin-lin WU1, Zong-qing ZHOU2, Hong-bin XIE3 and Fei CHENG3 1Department of Tourism, Minjiang University, China 2College of Hospitality Management, Niagara University, USA 3Institute of Tourism Research, Fujian Normal University, China Keywords: College-enterprise cooperation, Tourism talents training mode, Experiences of America, China. Abstract. College-enterprise cooperation has become one of the important modes of tourism management education in colleges and universities of China. This article probed on experiences of college-enterprise cooperation in tourism colleges of America, and then presented the situation of college-enterprise cooperation in tourism college of China, and further analyzed its main reasons. Referring to the experiences of America, this article discussed personnel training modes which conform to both the international popular training practices and Chinese characteristics in order to train tourism talents. Introduction College-enterprise cooperation is a kind of "win-win" cooperative mode for colleges and enterprises to train talents, which means the students acquire their theoretical knowledge in college and practical experiences in enterprise, meanwhile the colleges and enterprises share common human resources and information. At present, the cooperation between colleges and enterprises has become one of the important modes for training professional talents of tourism management in colleges of China. Compared to America, which have rich experiences on college-enterprise cooperation, the tourism education in China started later with problems about the depth of college-enterprise cooperation and the modes of training students' comprehensive ability. -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -

Content • June 2016 • Issue 13 Research on Optimal Placement Of
Content • June 2016 • Issue 13 Research on Optimal Placement of Sensors in the Vibration Test of Hydropower House 5 Wang Liqing, Zhang Yanping, Henan Vocational College of Water and Environment, Zhengzhou, Henan, China Improvement of the Volume Data Segmentation and Visualization 11 Qian Xua, Zhengxu Zhao, Yang Guo, Shijiazhuang Tiedao University, Shijiazhuang, Hebei, China Feature Research on Aerobic Granular Sludge to Remove Saliferous Organic Wastewater 16 Gaoli Guo, Hubei University of Technology Engineering and Technology College, China; Bihua Xiong, Hubei Sunshine 100 Real Estate Co., Ltd; Hubei University of Technology Engineering and Technology College, China Research on the Modern Agricultural Informationization Construction Mode and Application in Sichuan Province, China 22 Jiangke Cheng, [email protected]; Shengnan Wang; Panzhihua University, Panzhihua, Sichuan Province, China Collaborative Strategies and Applied Research of Costume Design Supply Chains Based on Cloud Computing 28 Ran Duan, [email protected]; Xiaogang Liu; Fashion and Art Design Institute, Donghua University, Shanghai, China Research on the Relationship Between Pore Structure of PHCP Concrete and Its Sulfate Erosion Resistance 33 Yanyan Hu, [email protected]; Tingshu He; Collage of Materials and Mineral Resources, Xi’an University of Architecture and Technology, Xi’an, Shaanxi Province, China Evaluation of Undesirable Output of Regional Multi-airport Productivity 38 Wei Wei; College of Air Transportation, Shanghai University of Engineering Science, Shanghai, -
1 Please Read These Instructions Carefully
PLEASE READ THESE INSTRUCTIONS CAREFULLY. MISTAKES IN YOUR CSC APPLICATION COULD LEAD TO YOUR APPLICATION BEING REJECTED. Visit http://studyinchina.csc.edu.cn/#/login to CREATE AN ACCOUNT. • The online application works best with Firefox or Internet Explorer (11.0). Menu selection functions may not work with other browsers. • The online application is only available in Chinese and English. 1 • Please read this page carefully before clicking on the “Application online” tab to start your application. 2 • The Program Category is Type B. • The Agency No. matches the university you will be attending. See Appendix A for a list of the Chinese university agency numbers. • Use the + by each section to expand on that section of the form. 3 • Fill out your personal information accurately. o Make sure to have a valid passport at the time of your application. o Use the name and date of birth that are on your passport. Use the name on your passport for all correspondences with the CLIC office or Chinese institutions. o List Canadian as your Nationality, even if you have dual citizenship. Only Canadian citizens are eligible for CLIC support. o Enter the mailing address for where you want your admission documents to be sent under Permanent Address. Leave Current Address blank. Contact your home or host university coordinator to find out when you will receive your admission documents. Contact information for you home university CLIC liaison can be found here: http://clicstudyinchina.com/contact-us/ 4 • Fill out your Education and Employment History accurately. o For Highest Education enter your current degree studies. -

2. Chinese University Scholarships
1. Chinese Government Silk Road Scholarships Scholarships: CSC scholarships are one of the most common scholarships awarded to international students. Provided by the Chinese Scholarship Council, this type of government scholarship is a initiative of the Chinese Ministry of Education to promote education, cultural exchange, political cooperation and mutual understanding between other countries and China. CSC scholarships can be partially or full-funded. The Chinese government also offers other scholarships such as the Confucius Institute scholarships, CAS- TWAS Scholarships, Chinese Provincial Government Scholarships and many more scholarships to international students. Undergraduate, master’s and doctoral students who qualify for a government scholarship receive a monthly stipend, free tuition and free accommodation during their study. The Chinese CSC Scholarship is a Fully Funded award that covers Full Tuition Fees, Living Allowances, Accommodation Expenses, and Health Insurance. The benefits of the CSC Scholarship: Undergraduate Program: CNY 2500 RMB Monthly Stipend, Tuition, and Accommodation are both Free Master Program: CNY 3000 RMB Monthly Stipend, the tuition is free and a room is provided at no charges. Doctoral Program: CNY 3500 RMB Monthly Stipend with free tuition and as well as the free room. 2. Chinese university scholarships: The majority of universities in China offer scholarships for students. These scholarships can cover your tuition fees, as well as the cost of your accommodation. Xiamen University for instance, is offering five different scholarships for international students so they can study in China. Undergraduate Program: CNY 500 RMB Monthly Stipend, Tuition, and Accommodation are both Free Master Program: CNY 1200 RMB Monthly Stipend, the tuition is free and a room is provided at no charges. -

Risk Assessment Based on Nitrogen and Phosphorus Forms in Watershed Sediments: a Case Study of the Upper Reaches of the Minjiang Watershed
sustainability Article Risk Assessment Based on Nitrogen and Phosphorus Forms in Watershed Sediments: A Case Study of the Upper Reaches of the Minjiang Watershed Hongmeng Ye 1,2,3, Hao Yang 1, Nian Han 3, Changchun Huang 1 , Tao Huang 1, Guoping Li 2, Xuyin Yuan 2,3,* and Hong Wang 1,* 1 School of Geography Science, Nanjing Normal University, Nanjing 210023, China; [email protected] (H.Y.); [email protected] (H.Y.); [email protected] (C.H.); [email protected] (T.H.) 2 Fujian Provincial Key Laboratory of Eco-Industrial Green Technology, College of Ecology and Resource Engineering of Wuyi University, Wuyishan 354300, China; [email protected] 3 College of Environmental, Hohai University, Nanjing 210098, China; [email protected] * Correspondence: [email protected] (X.Y.); [email protected] (H.W.) Received: 14 July 2019; Accepted: 26 September 2019; Published: 10 October 2019 Abstract: In order to achieve effective eutrophication control and ecosystem restoration, it is of great significance to investigate the distribution characteristics of nutrient elements in sediments, and to perform ecological risk assessments. In the current grading criteria for nutrient elements in sediments, only the overall or organic components of carbon, nitrogen and phosphorus are considered, while the specific species distributions and bioavailability characteristics are rarely taken into account. Hence, using the current grading criteria, the differences in the release, migration and biological activity of nutrient elements in sediments cannot be accurately reflected. Taking the upper reaches of the Minjiang River watershed as an example, we analyzed the overall distributions and the ratio of nutrient elements in sediments, the spatial changes of nitrogen and phosphorus forms, the bioavailability, and the environmental significance. -
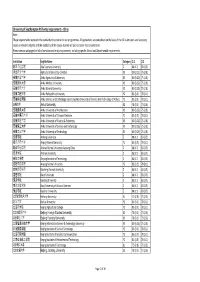
University of Southampton PGT Entry Requirements ‐ China Note: These Requirements Represent the Standard Entry Criteria for Our Programmes
University of Southampton PGT entry requirements ‐ China Note: These requirements represent the standard entry criteria for our programmes. All applications are considered on the basis of the full submission, and so strong scores in relevant subjects and the suitability of the course studied will also be taken into consideration. Please see our webpages for full information and entry requirements, including specific School and Departmental requirements. Institution English Name Category 2:1 2:2 阿坝师范学院 Aba Teachers University Z 88 (3.7) 83 (3.5) 河北农业大学 Agricultural University of Hebei X3 80 (3.25) 75 (2.8) 安徽农业大学 Anhui Agricultural University X3 80 (3.25) 75 (2.8) 安徽医科大学 Anhui Medical University X3 80 (3.25) 75 (2.8) 安徽师范大学 Anhui Normal University X3 80 (3.25) 75 (2.8) 安徽工程大学 Anhui Polytechnic University Y2 83 (3.5) 78 (3.1) 安徽科技学院 Anhui Science and Technology University (AKA University of Science And Technology of Anhui) Y2 83 (3.5) 78 (3.1) 安徽大学 Anhui University X2 78 (3.1) 73 (2.6) 安徽建筑大学 Anhui University of Architecture X3 80 (3.25) 75 (2.8) 安徽中医药大学 Anhui University of Chinese Medicine Y2 83 (3.5) 78 (3.1) 安徽财经大学 Anhui University of Finance & Economics X3 80 (3.25) 75 (2.8) 安徽理工大学 Anhui University of Science and Technology X3 80 (3.25) 75 (2.8) 安徽工业大学 Anhui University of Technology X3 80 (3.25) 75 (2.8) 安康学院 Ankang University Z 88 (3.7) 83 (3.5) 安庆师范大学 Anqing Normal University Y2 83 (3.5) 78 (3.1) 鞍山师范学院 Anshan Normal University Liaoning China Z 88 (3.7) 83 (3.5) 安顺学院 Anshun University Z 88 (3.7) 83 (3.5) 安阳工学院 Anyang Institute of Technology -

Analysis on the Talent Training Program and Educational Administration by Fujian and Taiwan Cooperation Projects
Advances in Social Science, Education and Humanities Research (ASSEHR), volume 65 2016 International Conference on Education, Management Science and Economics (ICEMSE-16) Analysis on the Talent Training Program and Educational Administration by Fujian and Taiwan Cooperation Projects Baoxiu Li The Youth League Committee Minjiang University Fuzhou, Fujian, China [email protected] Abstract—Fujian and Taiwan joint training project gives full of Fujian and Taiwan colleges. The number of college play to the advantages of professional teachers and majors of students to learn in Taiwan colleges has been increasing. In universities in Fujian and Taiwan, which is of great 2013, our province sent 226 batches, that is 3,315 students significance in promoting the reform and development of higher in various forms to Taiwan university (not including the education in Fujian province. However, the cross-straits different diploma students to study in Taiwan). Along with the political, economic and educational management mechanism, result in obvious differences in the concept of deepening of cooperation between Fujian and Taiwan running school, talent training mode and student education education, obvious differences emerged in terms of management. This paper selects five representative cross- educational philosophy, talent training mode and Strait Universities as examples, to give a detailed analysis of the educational administration of the students because of the advantages and disadvantages on the cooperative talent training different political, economic