Word2vec and Its Application to Examining the Changes in Word Contexts Over Time
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Harmless Overfitting: Using Denoising Autoencoders in Estimation of Distribution Algorithms
Journal of Machine Learning Research 21 (2020) 1-31 Submitted 10/16; Revised 4/20; Published 4/20 Harmless Overfitting: Using Denoising Autoencoders in Estimation of Distribution Algorithms Malte Probst∗ [email protected] Honda Research Institute EU Carl-Legien-Str. 30, 63073 Offenbach, Germany Franz Rothlauf [email protected] Information Systems and Business Administration Johannes Gutenberg-Universit¨atMainz Jakob-Welder-Weg 9, 55128 Mainz, Germany Editor: Francis Bach Abstract Estimation of Distribution Algorithms (EDAs) are metaheuristics where learning a model and sampling new solutions replaces the variation operators recombination and mutation used in standard Genetic Algorithms. The choice of these models as well as the correspond- ing training processes are subject to the bias/variance tradeoff, also known as under- and overfitting: simple models cannot capture complex interactions between problem variables, whereas complex models are susceptible to modeling random noise. This paper suggests using Denoising Autoencoders (DAEs) as generative models within EDAs (DAE-EDA). The resulting DAE-EDA is able to model complex probability distributions. Furthermore, overfitting is less harmful, since DAEs overfit by learning the identity function. This over- fitting behavior introduces unbiased random noise into the samples, which is no major problem for the EDA but just leads to higher population diversity. As a result, DAE-EDA runs for more generations before convergence and searches promising parts of the solution space more thoroughly. We study the performance of DAE-EDA on several combinatorial single-objective optimization problems. In comparison to the Bayesian Optimization Al- gorithm, DAE-EDA requires a similar number of evaluations of the objective function but is much faster and can be parallelized efficiently, making it the preferred choice especially for large and difficult optimization problems. -

More Perceptron
More Perceptron Instructor: Wei Xu Some slides adapted from Dan Jurfasky, Brendan O’Connor and Marine Carpuat A Biological Neuron https://www.youtube.com/watch?v=6qS83wD29PY Perceptron (an artificial neuron) inputs Perceptron Algorithm • Very similar to logistic regression • Not exactly computing gradient (simpler) vs. weighted sum of features Online Learning • Rather than making a full pass through the data, compute gradient and update parameters after each training example. Stochastic Gradient Descent • Updates (or more specially, gradients) will be less accurate, but the overall effect is to move in the right direction • Often works well and converges faster than batch learning Online Learning • update parameters for each training example Initialize weight vector w = 0 Create features Loop for K iterations Loop for all training examples x_i, y_i … update_weights(w, x_i, y_i) Perceptron Algorithm • Very similar to logistic regression • Not exactly computing gradient Initialize weight vector w = 0 Loop for K iterations Loop For all training examples x_i if sign(w * x_i) != y_i Error-driven! w += y_i * x_i Error-driven Intuition • For a given example, makes a prediction, then checks to see if this prediction is correct. - If the prediction is correct, do nothing. - If the prediction is wrong, change its parameters so that it would do better on this example next time around. Error-driven Intuition Error-driven Intuition Error-driven Intuition Exercise Perceptron (vs. LR) • Only hyperparameter is maximum number of iterations (LR also needs learning rate) • Guaranteed to converge if the data is linearly separable (LR always converge) objective function is convex What if non linearly separable? • In real-world problems, this is nearly always the case. -

Measuring Overfitting and Mispecification in Nonlinear Models
WP 11/25 Measuring overfitting and mispecification in nonlinear models Marcel Bilger Willard G. Manning August 2011 york.ac.uk/res/herc/hedgwp Measuring overfitting and mispecification in nonlinear models Marcel Bilger, Willard G. Manning The Harris School of Public Policy Studies, University of Chicago, USA Abstract We start by proposing a new measure of overfitting expressed on the untransformed scale of the dependent variable, which is generally the scale of interest to the analyst. We then show that with nonlinear models shrinkage due to overfitting gets confounded by shrinkage—or expansion— arising from model misspecification. Out-of-sample predictive calibration can in fact be expressed as in-sample calibration times 1 minus this new measure of overfitting. We finally argue that re-calibration should be performed on the scale of interest and provide both a simulation study and a real-data illustration based on health care expenditure data. JEL classification: C21, C52, C53, I11 Keywords: overfitting, shrinkage, misspecification, forecasting, health care expenditure 1. Introduction When fitting a model, it is well-known that we pick up part of the idiosyncratic char- acteristics of the data as well as the systematic relationship between a dependent and explanatory variables. This phenomenon is known as overfitting and generally occurs when a model is excessively complex relative to the amount of data available. Overfit- ting is a major threat to regression analysis in terms of both inference and prediction. When models greatly over-explain the data at hand they can even show relations which reflect chance only. Consequently, overfitting casts doubt on the true statistical signif- icance of the effects found by the analyst as well as the magnitude of the response. -
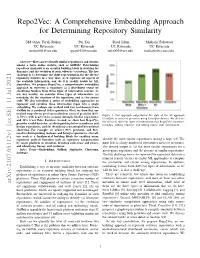
A Comprehensive Embedding Approach for Determining Repository Similarity
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -

Over-Fitting in Model Selection with Gaussian Process Regression
Over-Fitting in Model Selection with Gaussian Process Regression Rekar O. Mohammed and Gavin C. Cawley University of East Anglia, Norwich, UK [email protected], [email protected] http://theoval.cmp.uea.ac.uk/ Abstract. Model selection in Gaussian Process Regression (GPR) seeks to determine the optimal values of the hyper-parameters governing the covariance function, which allows flexible customization of the GP to the problem at hand. An oft-overlooked issue that is often encountered in the model process is over-fitting the model selection criterion, typi- cally the marginal likelihood. The over-fitting in machine learning refers to the fitting of random noise present in the model selection criterion in addition to features improving the generalisation performance of the statistical model. In this paper, we construct several Gaussian process regression models for a range of high-dimensional datasets from the UCI machine learning repository. Afterwards, we compare both MSE on the test dataset and the negative log marginal likelihood (nlZ), used as the model selection criteria, to find whether the problem of overfitting in model selection also affects GPR. We found that the squared exponential covariance function with Automatic Relevance Determination (SEard) is better than other kernels including squared exponential covariance func- tion with isotropic distance measure (SEiso) according to the nLZ, but it is clearly not the best according to MSE on the test data, and this is an indication of over-fitting problem in model selection. Keywords: Gaussian process · Regression · Covariance function · Model selection · Over-fitting 1 Introduction Supervised learning tasks can be divided into two main types, namely classifi- cation and regression problems. -

On Overfitting and Asymptotic Bias in Batch Reinforcement Learning With
Journal of Artificial Intelligence Research 65 (2019) 1-30 Submitted 06/2018; published 05/2019 On Overfitting and Asymptotic Bias in Batch Reinforcement Learning with Partial Observability Vincent François-Lavet [email protected] Guillaume Rabusseau [email protected] Joelle Pineau [email protected] School of Computer Science, McGill University University Street 3480, Montreal, QC, H3A 2A7, Canada Damien Ernst [email protected] Raphael Fonteneau [email protected] Montefiore Institute, University of Liege Allée de la découverte 10, 4000 Liège, Belgium Abstract This paper provides an analysis of the tradeoff between asymptotic bias (suboptimality with unlimited data) and overfitting (additional suboptimality due to limited data) in the context of reinforcement learning with partial observability. Our theoretical analysis formally characterizes that while potentially increasing the asymptotic bias, a smaller state representation decreases the risk of overfitting. This analysis relies on expressing the quality of a state representation by bounding L1 error terms of the associated belief states. Theoretical results are empirically illustrated when the state representation is a truncated history of observations, both on synthetic POMDPs and on a large-scale POMDP in the context of smartgrids, with real-world data. Finally, similarly to known results in the fully observable setting, we also briefly discuss and empirically illustrate how using function approximators and adapting the discount factor may enhance the tradeoff between asymptotic bias and overfitting in the partially observable context. 1. Introduction This paper studies sequential decision-making problems that may be modeled as Markov Decision Processes (MDP) but for which the state is partially observable. -

Overfitting Princeton University COS 495 Instructor: Yingyu Liang Review: Machine Learning Basics Math Formulation
Machine Learning Basics Lecture 6: Overfitting Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation • Given training data 푥푖, 푦푖 : 1 ≤ 푖 ≤ 푛 i.i.d. from distribution 퐷 1 • Find 푦 = 푓(푥) ∈ 퓗 that minimizes 퐿 푓 = σ푛 푙(푓, 푥 , 푦 ) 푛 푖=1 푖 푖 • s.t. the expected loss is small 퐿 푓 = 피 푥,푦 ~퐷[푙(푓, 푥, 푦)] Machine learning 1-2-3 • Collect data and extract features • Build model: choose hypothesis class 퓗 and loss function 푙 • Optimization: minimize the empirical loss Machine learning 1-2-3 Feature mapping Maximum Likelihood • Collect data and extract features • Build model: choose hypothesis class 퓗 and loss function 푙 • Optimization: minimize the empirical loss Occam’s razor Gradient descent; convex optimization Overfitting Linear vs nonlinear models 2 푥1 2 푥2 푥1 2푥1푥2 푦 = sign(푤푇휙(푥) + 푏) 2푐푥1 푥2 2푐푥2 푐 Polynomial kernel Linear vs nonlinear models • Linear model: 푓 푥 = 푎0 + 푎1푥 2 3 푀 • Nonlinear model: 푓 푥 = 푎0 + 푎1푥 + 푎2푥 + 푎3푥 + … + 푎푀 푥 • Linear model ⊆ Nonlinear model (since can always set 푎푖 = 0 (푖 > 1)) • Looks like nonlinear model can always achieve same/smaller error • Why one use Occam’s razor (choose a smaller hypothesis class)? Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Figure from Machine Learning and Pattern Recognition, Bishop Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Regression using polynomial of degree M Figure from Machine Learning and Pattern Recognition, Bishop Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Figure from Machine Learning -

Practice with Python
CSI4108-01 ARTIFICIAL INTELLIGENCE 1 Word Embedding / Text Processing Practice with Python 2018. 5. 11. Lee, Gyeongbok Practice with Python 2 Contents • Word Embedding – Libraries: gensim, fastText – Embedding alignment (with two languages) • Text/Language Processing – POS Tagging with NLTK/koNLPy – Text similarity (jellyfish) Practice with Python 3 Gensim • Open-source vector space modeling and topic modeling toolkit implemented in Python – designed to handle large text collections, using data streaming and efficient incremental algorithms – Usually used to make word vector from corpus • Tutorial is available here: – https://github.com/RaRe-Technologies/gensim/blob/develop/tutorials.md#tutorials – https://rare-technologies.com/word2vec-tutorial/ • Install – pip install gensim Practice with Python 4 Gensim for Word Embedding • Logging • Input Data: list of word’s list – Example: I have a car , I like the cat → – For list of the sentences, you can make this by: Practice with Python 5 Gensim for Word Embedding • If your data is already preprocessed… – One sentence per line, separated by whitespace → LineSentence (just load the file) – Try with this: • http://an.yonsei.ac.kr/corpus/example_corpus.txt From https://radimrehurek.com/gensim/models/word2vec.html Practice with Python 6 Gensim for Word Embedding • If the input is in multiple files or file size is large: – Use custom iterator and yield From https://rare-technologies.com/word2vec-tutorial/ Practice with Python 7 Gensim for Word Embedding • gensim.models.Word2Vec Parameters – min_count: -

Gensim Is Robust in Nature and Has Been in Use in Various Systems by Various People As Well As Organisations for Over 4 Years
Gensim i Gensim About the Tutorial Gensim = “Generate Similar” is a popular open source natural language processing library used for unsupervised topic modeling. It uses top academic models and modern statistical machine learning to perform various complex tasks such as Building document or word vectors, Corpora, performing topic identification, performing document comparison (retrieving semantically similar documents), analysing plain-text documents for semantic structure. Audience This tutorial will be useful for graduates, post-graduates, and research students who either have an interest in Natural Language Processing (NLP), Topic Modeling or have these subjects as a part of their curriculum. The reader can be a beginner or an advanced learner. Prerequisites The reader must have basic knowledge about NLP and should also be aware of Python programming concepts. Copyright & Disclaimer Copyright 2020 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected] ii Gensim Table of Contents About the Tutorial .......................................................................................................................................... -

Software Framework for Topic Modelling with Large
Software Framework for Topic Modelling Radim Řehůřek and Petr Sojka NLP Centre, Faculty of Informatics, Masaryk University, Brno, Czech Republic {xrehurek,sojka}@fi.muni.cz http://nlp.fi.muni.cz/projekty/gensim/ the available RAM, in accordance with While an intuitive interface is impor- Although evaluation of the quality of NLP Framework for VSM the current trends in NLP (see e.g. [3]). tant for software adoption, it is of course the obtained similarities is not the subject rather trivial and useless in itself. We have of this paper, it is of course of utmost Large corpora are ubiquitous in today’s Intuitive API. We wish to minimise the therefore implemented some of the popular practical importance. Here we note that it world and memory quickly becomes the lim- number of method names and interfaces VSM methods, Latent Semantic Analysis, is notoriously hard to evaluate the quality, iting factor in practical applications of the that need to be memorised in order to LSA and Latent Dirichlet Allocation, LDA. as even the preferences of different types Vector Space Model (VSM). In this paper, use the package. The terminology is The framework is heavily documented of similarity are subjective (match of main we identify a gap in existing implementa- NLP-centric. and is available from http://nlp.fi. topic, or subdomain, or specific wording/- tions of many of the popular algorithms, Easy deployment. The package should muni.cz/projekty/gensim/. This plagiarism) and depends on the motivation which is their scalability and ease of use. work out-of-the-box on all major plat- website contains sections which describe of the reader. -

Word2vec and Beyond Presented by Eleni Triantafillou
Word2vec and beyond presented by Eleni Triantafillou March 1, 2016 The Big Picture There is a long history of word representations I Techniques from information retrieval: Latent Semantic Analysis (LSA) I Self-Organizing Maps (SOM) I Distributional count-based methods I Neural Language Models Important take-aways: 1. Don't need deep models to get good embeddings 2. Count-based models and neural net predictive models are not qualitatively different source: http://gavagai.se/blog/2015/09/30/a-brief-history-of-word-embeddings/ Continuous Word Representations I Contrast with simple n-gram models (words as atomic units) I Simple models have the potential to perform very well... I ... if we had enough data I Need more complicated models I Continuous representations take better advantage of data by modelling the similarity between the words Continuous Representations source: http://www.codeproject.com/Tips/788739/Visualization-of- High-Dimensional-Data-using-t-SNE Skip Gram I Learn to predict surrounding words I Use a large training corpus to maximize: T 1 X X log p(w jw ) T t+j t t=1 −c≤j≤c; j6=0 where: I T: training set size I c: context size I wj : vector representation of the jth word Skip Gram: Think of it as a Neural Network Learn W and W' in order to maximize previous objective Output layer y1,j W'N×V Input layer Hidden layer y2,j xk WV×N hi W'N×V N-dim V-dim W'N×V yC,j C×V-dim source: "word2vec parameter learning explained." ([4]) CBOW Input layer x1k WV×N Output layer Hidden layer x W W' 2k V×N hi N×V yj N-dim V-dim WV×N xCk C×V-dim source: -

Generative Adversarial Networks for Text Using Word2vec Intermediaries
Generative Adversarial Networks for text using word2vec intermediaries Akshay Budhkar1, 2, 4, Krishnapriya Vishnubhotla1, Safwan Hossain1, 2 and Frank Rudzicz1, 2, 3, 5 1Department of Computer Science, University of Toronto fabudhkar, vkpriya, [email protected] 2Vector Institute [email protected] 3St Michael’s Hospital 4Georgian Partners 5Surgical Safety Technologies Inc. Abstract the information to improve, however, if at the cur- rent stage of training it is not doing that yet, the Generative adversarial networks (GANs) have gradient of G vanishes. Additionally, with this shown considerable success, especially in the loss function, there is no correlation between the realistic generation of images. In this work, we apply similar techniques for the generation metric and the generation quality, and the most of text. We propose a novel approach to han- common workaround is to generate targets across dle the discrete nature of text, during training, epochs and then measure the generation quality, using word embeddings. Our method is ag- which can be an expensive process. nostic to vocabulary size and achieves compet- W-GAN (Arjovsky et al., 2017) rectifies these itive results relative to methods with various issues with its updated loss. Wasserstein distance discrete gradient estimators. is the minimum cost of transporting mass in con- 1 Introduction verting data from distribution Pr to Pg. This loss forces the GAN to perform in a min-max, rather Natural Language Generation (NLG) is often re- than a max-min, a desirable behavior as stated in garded as one of the most challenging tasks in (Goodfellow, 2016), potentially mitigating mode- computation (Murty and Kabadi, 1987).