Extending Czech Wordnet Using a Bilingual Dictionary
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
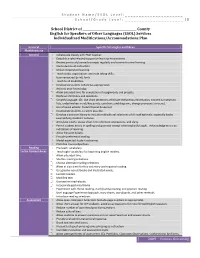
English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan
Student Name/ESOL Level:_____ __________ _ _ _ _ _ _ School/Grade Level: _____________________ | 1 School District of _____________________________________ County English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan General Specific Strategies and Ideas Modifications General Collaborate closely with ESOL teacher. Establish a safe/relaxed/supportive learning environment. Review previously learned concepts regularly and connect to new learning. Contextualize all instruction. Utilize cooperative learning. Teach study, organization, and note taking skills. Use manuscript (print) fonts. Teach to all modalities. Incorporate student culture (as appropriate). Activate prior knowledge. Allow extended time for completion of assignments and projects. Rephrase directions and questions. Simplify language. (Ex. Use short sentences, eliminate extraneous information, convert narratives to lists, underline key words/key points, use charts and diagrams, change pronouns to nouns). Use physical activity. (Total Physical Response) Incorporate students L1 when possible. Develop classroom library to include multicultural selections of all reading levels; especially books exemplifying students’ cultures. Articulate clearly, pause often, limit idiomatic expressions, and slang. Permit student errors in spelling and grammar except when explicitly taught. Acknowledge errors as indications of learning. Allow frequent breaks. Provide preferential seating. Model expected student outcomes. Prioritize course objectives. Reading Pre-teach vocabulary. in the Content Areas Teach sight vocabulary for beginning English readers. Allow extended time. Shorten reading selections. Choose alternate reading selections. Allow in-class time for free voluntary and required reading. Use graphic novels/books and illustrated novels. Leveled readers Modified text Use teacher read-alouds. Incorporate gestures/drama. Experiment with choral reading, duet (buddy) reading, and popcorn reading. -

Four Strands to Language Learning
International Journal of Innovation in English Language Teaching… ISSN: 2156-5716 Volume 1, Number 2 © 2012 Nova Science Publishers, Inc. APPLYING THE FOUR STRANDS TO LANGUAGE LEARNING Paul Nation1 and Azusa Yamamoto2 Victoria University of Wellington, New Zealand1 and Temple University Japan2 ABSTRACT The principle of the four strands says that a well balanced language course should have four equal strands of meaning focused input, meaning focused output, language focused learning, and fluency development. By applying this principle, it is possible to answer questions like How can I teach vocabulary? What should a well balanced listening course contain? How much extensive reading should we do? Is it worthwhile doing grammar translation? and How can I find out if I have a well balanced conversation course? The article describes the rationale behind such answers. The four strands principle is primarily a way of providing a balance of learning opportunities, and the article shows how this can be done in self regulated foreign language learning without a teacher. Keywords: Fluency learning, four strands, language focused learning, meaning focused input, meaning focused output. INTRODUCTION The principle of the four strands (Nation, 2007) states that a well balanced language course should consist of four equal strands – meaning focused input, meaning focused output, language focused learning, and fluency development. Each strand should receive a roughly equal amount of time in a course. The meaning focused input strand involves learning through listening and reading. This is largely incidental learning because the learners’ attention should be focused on comprehending what is being read or listened to. The meaning focused output strand involves learning through speaking and writing and in common with the meaning focused input strand involves largely incidental learning. -

Automatic Wordnet Mapping Using Word Sense Disambiguation*
Automatic WordNet mapping using word sense disambiguation* Changki Lee Seo JungYun Geunbae Leer Natural Language Processing Lab Natural Language Processing Lab Dept. of Computer Science and Engineering Dept. of Computer Science Pohang University of Science & Technology Sogang University San 31, Hyoja-Dong, Pohang, 790-784, Korea Sinsu-dong 1, Mapo-gu, Seoul, Korea {leeck,gblee }@postech.ac.kr seojy@ ccs.sogang.ac.kr bilingual Korean-English dictionary. The first Abstract sense of 'gwan-mog' has 'bush' as a translation in English and 'bush' has five synsets in This paper presents the automatic WordNet. Therefore the first sense of construction of a Korean WordNet from 'gwan-mog" has five candidate synsets. pre-existing lexical resources. A set of Somehow we decide a synset {shrub, bush} automatic WSD techniques is described for among five candidate synsets and link the sense linking Korean words collected from a of 'gwan-mog' to this synset. bilingual MRD to English WordNet synsets. As seen from this example, when we link the We will show how individual linking senses of Korean words to WordNet synsets, provided by each WSD method is then there are semantic ambiguities. To remove the combined to produce a Korean WordNet for ambiguities we develop new word sense nouns. disambiguation heuristics and automatic mapping method to construct Korean WordNet based on 1 Introduction the existing English WordNet. There is no doubt on the increasing This paper is organized as follows. In section 2, importance of using wide coverage ontologies we describe multiple heuristics for word sense for NLP tasks especially for information disambiguation for sense linking. -

Bilingual Dictionary Generation for Low-Resourced Language Pairs
Bilingual dictionary generation for low-resourced language pairs Varga István Yokoyama Shoichi Yamagata University, Yamagata University, Graduate School of Science and Engineering Graduate School of Science and Engineering [email protected] [email protected] choice and adaptation of the translation method Abstract to the problem of available translation resources between the chosen languages. Bilingual dictionaries are vital resources in One possible solution is bilingual corpus ac- many areas of natural language processing. quisition for statistical machine translation Numerous methods of machine translation re- (SMT). However, for highly accurate SMT sys- quire bilingual dictionaries with large cover- tems large bilingual corpora are required, which age, but less-frequent language pairs rarely are rarely available for less represented lan- have any digitalized resources. Since the need for these resources is increasing, but the hu- guages. Rule or sentence pattern based systems man resources are scarce for less represented are an attractive alternative, for these systems the languages, efficient automatized methods are need for a bilingual dictionary is essential. needed. This paper introduces a fully auto- Our paper targets bilingual dictionary genera- mated, robust pivot language based bilingual tion, a resource which can be used within the dictionary generation method that uses the frameworks of a rule or pattern based machine WordNet of the pivot language to build a new translation system. Our goal is to provide a low- bilingual dictionary. We propose the usage of cost, robust and accurate dictionary generation WordNet in order to increase accuracy; we method. Low cost and robustness are essential in also introduce a bidirectional selection method order to be re-implementable with any arbitrary with a flexible threshold to maximize recall. -

Universal Or Variation? Semantic Networks in English and Chinese
Universal or variation? Semantic networks in English and Chinese Understanding the structures of semantic networks can provide great insights into lexico- semantic knowledge representation. Previous work reveals small-world structure in English, the structure that has the following properties: short average path lengths between words and strong local clustering, with a scale-free distribution in which most nodes have few connections while a small number of nodes have many connections1. However, it is not clear whether such semantic network properties hold across human languages. In this study, we investigate the universal structures and cross-linguistic variations by comparing the semantic networks in English and Chinese. Network description To construct the Chinese and the English semantic networks, we used Chinese Open Wordnet2,3 and English WordNet4. The two wordnets have different word forms in Chinese and English but common word meanings. Word meanings are connected not only to word forms, but also to other word meanings if they form relations such as hypernyms and meronyms (Figure 1). 1. Cross-linguistic comparisons Analysis The large-scale structures of the Chinese and the English networks were measured with two key network metrics, small-worldness5 and scale-free distribution6. Results The two networks have similar size and both exhibit small-worldness (Table 1). However, the small-worldness is much greater in the Chinese network (σ = 213.35) than in the English network (σ = 83.15); this difference is primarily due to the higher average clustering coefficient (ACC) of the Chinese network. The scale-free distributions are similar across the two networks, as indicated by ANCOVA, F (1, 48) = 0.84, p = .37. -

The Impact of Using a Bilingual Dictionary (English-Arabic) for Reading and Writing in a Saudi High School
THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL By Ali Almaliki A Master’s Thesis/Project Capstone Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Education Teaching English to Speakers of Other Languages (TESOL) Department of Language, Learning and leadership State University of New York at Fredonia Fredonia, New York December 2017 THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL ABSTRACT The purpose of this study is to explore the impact of using a bilingual dictionary (English- Arabic) for reading and writing in a Saudi high school and also to explore the Saudi Arabian students’ attitudes and EFL teachers’ perceptions toward the use of bilingual dictionaries. This study involves 65 EFL students and 5 EFL teachers in one Saudi high school in the city of Alkobar. Mixed methods research is used in which both qualitative and quantitative data are collected. For participating students, pre-test, post-test, and surveys are used to collect quantitative data. For participating teachers and students, in-person interviews are conducted with select teachers and students so as to collect qualitative data. This study has produced eight findings; first is that the use of a bilingual dictionary has a significant effect on the reading and writing scores for both high and low proficiency EFL students. Other findings include that most EFL students feel that using a bilingual dictionary in EFL classrooms is very important to help them translate and learn new vocabulary words but their use of a bilingual dictionary is limited by the strategies for use that students know or are taught, and that both invoice and experienced EFL teachers agree that the use of a bilingual dictionary is important for learning word meaning and vocabulary, but they do not all agree about which grades should use bilingual dictionaries. -

Dictionaries in the ESL Classroom
7/22/2009 The need for dictionaries in the ESL classroom: Dictionaries empower students by making them responsible for their own learning. Once students are able to use a dictionary well, they are self-sufficient in Dictionaries: finding the information on their own. Use and Function in the ESL Dictionaries present a very useful tool in the ESL classroom. However, teachers need to EXPLICITLY teach students skills so that they can be Classroom utilized to maximum extent. Dictionary use can enhance vocabulary acquisition and comprehension. If the dictionary is sufficiently current, and idiomatic colloquialisms are included, the student can [also] see representations of contemporary culture as seen through language. Why teachers need to explicitly teach dictionary skills: “If we do not teach students how to use the dictionary, it is unlikely that they will demand that they be taught, since, while teachers do not believe that students have adequate dictionary skills, students believe that they do” (Bilash, Gregoret & Loewen, 1999, p.4). Dictionary use skills: Dictionaries are not self explanatory; directions need to be made clear so that students can disentangle information, and select the appropriate meaning for the task at hand. Students need to learn how a dictionary works, how a dictionary or reference resource can help them, and also how to become aware of what they need and what kind of dictionary will best respond to their needs. Teachers need to firstly make sure that students are acquainted and familiar with the alphabet and its order. Secondly, teachers need to orientate students as to what a dictionary As students become more familiar and comfortable with basic dictionary entails, its functions, and relative terminology. -

NL Assistant: a Toolkit for Developing Natural Language: Applications
NL Assistant: A Toolkit for Developing Natural Language Applications Deborah A. Dahl, Lewis M. Norton, Ahmed Bouzid, and Li Li Unisys Corporation Introduction scale lexical resources have been integrated with the toolkit. These include Comlex and WordNet We will be demonstrating a toolkit for as well as additional, internally developed developing natural language-based applications resources. The second strategy is to provide easy and two applications. The goals of this toolkit to use editors for entering linguistic information. are to reduce development time and cost for natural language based applications by reducing Servers the amount of linguistic and programming work needed. Linguistic work has been reduced by Lexical information is supplied by four external integrating large-scale linguistics resources--- servers which are accessed by the natural Comlex (Grishman, et. al., 1993) and WordNet language engine during processing. Syntactic (Miller, 1990). Programming work is reduced by information is supplied by a lexical server based automating some of the programming tasks. The on the 50K word Comlex dictionary available toolkit is designed for both speech- and text- from the Linguistic Data Consortium. Semantic based interface applications. It runs in a information comes from two servers, a KB Windows NT environment. Applications can server based on the noun portion of WordNet run in either Windows NT or Unix. (70K concepts), and a semantics server containing case frame information for 2500 System Components English verbs. A denotations server using unique concept names generated for each The NL Assistant toolkit consists of WordNet synset at ISI links the words in the lexicon to the concepts in the KB. -

Similarity Detection Using Latent Semantic Analysis Algorithm Priyanka R
International Journal of Emerging Research in Management &Technology Research Article August ISSN: 2278-9359 (Volume-6, Issue-8) 2017 Similarity Detection Using Latent Semantic Analysis Algorithm Priyanka R. Patil Shital A. Patil PG Student, Department of Computer Engineering, Associate Professor, Department of Computer Engineering, North Maharashtra University, Jalgaon, North Maharashtra University, Jalgaon, Maharashtra, India Maharashtra, India Abstract— imilarity View is an application for visually comparing and exploring multiple models of text and collection of document. Friendbook finds ways of life of clients from client driven sensor information, measures the S closeness of ways of life amongst clients, and prescribes companions to clients if their ways of life have high likeness. Roused by demonstrate a clients day by day life as life records, from their ways of life are separated by utilizing the Latent Dirichlet Allocation Algorithm. Manual techniques can't be utilized for checking research papers, as the doled out commentator may have lacking learning in the exploration disciplines. For different subjective views, causing possible misinterpretations. An urgent need for an effective and feasible approach to check the submitted research papers with support of automated software. A method like text mining method come to solve the problem of automatically checking the research papers semantically. The proposed method to finding the proper similarity of text from the collection of documents by using Latent Dirichlet Allocation (LDA) algorithm and Latent Semantic Analysis (LSA) with synonym algorithm which is used to find synonyms of text index wise by using the English wordnet dictionary, another algorithm is LSA without synonym used to find the similarity of text based on index. -

Introduction to Wordnet: an On-Line Lexical Database
Introduction to WordNet: An On-line Lexical Database George A. Miller, Richard Beckwith, Christiane Fellbaum, Derek Gross, and Katherine Miller (Revised August 1993) WordNet is an on-line lexical reference system whose design is inspired by current psycholinguistic theories of human lexical memory. English nouns, verbs, and adjectives are organized into synonym sets, each representing one underlying lexical concept. Different relations link the synonym sets. Standard alphabetical procedures for organizing lexical information put together words that are spelled alike and scatter words with similar or related meanings haphazardly through the list. Unfortunately, there is no obvious alternative, no other simple way for lexicographers to keep track of what has been done or for readers to ®nd the word they are looking for. But a frequent objection to this solution is that ®nding things on an alphabetical list can be tedious and time-consuming. Many people who would like to refer to a dictionary decide not to bother with it because ®nding the information would interrupt their work and break their train of thought. In this age of computers, however, there is an answer to that complaint. One obvious reason to resort to on-line dictionariesÐlexical databases that can be read by computersÐis that computers can search such alphabetical lists much faster than people can. A dictionary entry can be available as soon as the target word is selected or typed into the keyboard. Moreover, since dictionaries are printed from tapes that are read by computers, it is a relatively simple matter to convert those tapes into the appropriate kind of lexical database. -

Web Search Result Clustering with Babelnet
Web Search Result Clustering with BabelNet Marek Kozlowski Maciej Kazula OPI-PIB OPI-PIB [email protected] [email protected] Abstract 2 Related Work In this paper we present well-known 2.1 Search Result Clustering search result clustering method enriched with BabelNet information. The goal is The goal of text clustering in information retrieval to verify how Babelnet/Babelfy can im- is to discover groups of semantically related docu- prove the clustering quality in the web ments. Contextual descriptions (snippets) of docu- search results domain. During the evalua- ments returned by a search engine are short, often tion we tested three algorithms (Bisecting incomplete, and highly biased toward the query, so K-Means, STC, Lingo). At the first stage, establishing a notion of proximity between docu- we performed experiments only with tex- ments is a challenging task that is called Search tual features coming from snippets. Next, Result Clustering (SRC). Search Results Cluster- we introduced new semantic features from ing (SRC) is a specific area of documents cluster- BabelNet (as disambiguated synsets, cate- ing. gories and glosses describing synsets, or Approaches to search result clustering can be semantic edges) in order to verify how classified as data-centric or description-centric they influence on the clustering quality (Carpineto, 2009). of the search result clustering. The al- The data-centric approach (as Bisecting K- gorithms were evaluated on AMBIENT Means) focuses more on the problem of data clus- dataset in terms of the clustering quality. tering, rather than presenting the results to the user. Other data-centric methods use hierarchical 1 Introduction agglomerative clustering (Maarek, 2000) that re- In the previous years, Web clustering engines places single terms with lexical affinities (2-grams (Carpineto, 2009) have been proposed as a solu- of words) as features, or exploit link information tion to the issue of lexical ambiguity in Informa- (Zhang, 2008). -

Sethesaurus: Wordnet in Software Engineering
This is the author's version of an article that has been published in this journal. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TSE.2019.2940439 IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 14, NO. 8, AUGUST 2015 1 SEthesaurus: WordNet in Software Engineering Xiang Chen, Member, IEEE, Chunyang Chen, Member, IEEE, Dun Zhang, and Zhenchang Xing, Member, IEEE, Abstract—Informal discussions on social platforms (e.g., Stack Overflow, CodeProject) have accumulated a large body of programming knowledge in the form of natural language text. Natural language process (NLP) techniques can be utilized to harvest this knowledge base for software engineering tasks. However, consistent vocabulary for a concept is essential to make an effective use of these NLP techniques. Unfortunately, the same concepts are often intentionally or accidentally mentioned in many different morphological forms (such as abbreviations, synonyms and misspellings) in informal discussions. Existing techniques to deal with such morphological forms are either designed for general English or mainly resort to domain-specific lexical rules. A thesaurus, which contains software-specific terms and commonly-used morphological forms, is desirable to perform normalization for software engineering text. However, constructing this thesaurus in a manual way is a challenge task. In this paper, we propose an automatic unsupervised approach to build such a thesaurus. In particular, we first identify software-specific terms by utilizing a software-specific corpus (e.g., Stack Overflow) and a general corpus (e.g., Wikipedia). Then we infer morphological forms of software-specific terms by combining distributed word semantics, domain-specific lexical rules and transformations.