Computational Terminology: Exploring Bilingual and Monolingual Term Extraction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
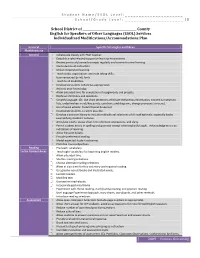
English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan
Student Name/ESOL Level:_____ __________ _ _ _ _ _ _ School/Grade Level: _____________________ | 1 School District of _____________________________________ County English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan General Specific Strategies and Ideas Modifications General Collaborate closely with ESOL teacher. Establish a safe/relaxed/supportive learning environment. Review previously learned concepts regularly and connect to new learning. Contextualize all instruction. Utilize cooperative learning. Teach study, organization, and note taking skills. Use manuscript (print) fonts. Teach to all modalities. Incorporate student culture (as appropriate). Activate prior knowledge. Allow extended time for completion of assignments and projects. Rephrase directions and questions. Simplify language. (Ex. Use short sentences, eliminate extraneous information, convert narratives to lists, underline key words/key points, use charts and diagrams, change pronouns to nouns). Use physical activity. (Total Physical Response) Incorporate students L1 when possible. Develop classroom library to include multicultural selections of all reading levels; especially books exemplifying students’ cultures. Articulate clearly, pause often, limit idiomatic expressions, and slang. Permit student errors in spelling and grammar except when explicitly taught. Acknowledge errors as indications of learning. Allow frequent breaks. Provide preferential seating. Model expected student outcomes. Prioritize course objectives. Reading Pre-teach vocabulary. in the Content Areas Teach sight vocabulary for beginning English readers. Allow extended time. Shorten reading selections. Choose alternate reading selections. Allow in-class time for free voluntary and required reading. Use graphic novels/books and illustrated novels. Leveled readers Modified text Use teacher read-alouds. Incorporate gestures/drama. Experiment with choral reading, duet (buddy) reading, and popcorn reading. -

Four Strands to Language Learning
International Journal of Innovation in English Language Teaching… ISSN: 2156-5716 Volume 1, Number 2 © 2012 Nova Science Publishers, Inc. APPLYING THE FOUR STRANDS TO LANGUAGE LEARNING Paul Nation1 and Azusa Yamamoto2 Victoria University of Wellington, New Zealand1 and Temple University Japan2 ABSTRACT The principle of the four strands says that a well balanced language course should have four equal strands of meaning focused input, meaning focused output, language focused learning, and fluency development. By applying this principle, it is possible to answer questions like How can I teach vocabulary? What should a well balanced listening course contain? How much extensive reading should we do? Is it worthwhile doing grammar translation? and How can I find out if I have a well balanced conversation course? The article describes the rationale behind such answers. The four strands principle is primarily a way of providing a balance of learning opportunities, and the article shows how this can be done in self regulated foreign language learning without a teacher. Keywords: Fluency learning, four strands, language focused learning, meaning focused input, meaning focused output. INTRODUCTION The principle of the four strands (Nation, 2007) states that a well balanced language course should consist of four equal strands – meaning focused input, meaning focused output, language focused learning, and fluency development. Each strand should receive a roughly equal amount of time in a course. The meaning focused input strand involves learning through listening and reading. This is largely incidental learning because the learners’ attention should be focused on comprehending what is being read or listened to. The meaning focused output strand involves learning through speaking and writing and in common with the meaning focused input strand involves largely incidental learning. -

A Comparison of Knowledge Extraction Tools for the Semantic Web
A Comparison of Knowledge Extraction Tools for the Semantic Web Aldo Gangemi1;2 1 LIPN, Universit´eParis13-CNRS-SorbonneCit´e,France 2 STLab, ISTC-CNR, Rome, Italy. Abstract. In the last years, basic NLP tasks: NER, WSD, relation ex- traction, etc. have been configured for Semantic Web tasks including on- tology learning, linked data population, entity resolution, NL querying to linked data, etc. Some assessment of the state of art of existing Knowl- edge Extraction (KE) tools when applied to the Semantic Web is then desirable. In this paper we describe a landscape analysis of several tools, either conceived specifically for KE on the Semantic Web, or adaptable to it, or even acting as aggregators of extracted data from other tools. Our aim is to assess the currently available capabilities against a rich palette of ontology design constructs, focusing specifically on the actual semantic reusability of KE output. 1 Introduction We present a landscape analysis of the current tools for Knowledge Extraction from text (KE), when applied on the Semantic Web (SW). Knowledge Extraction from text has become a key semantic technology, and has become key to the Semantic Web as well (see. e.g. [31]). Indeed, interest in ontology learning is not new (see e.g. [23], which dates back to 2001, and [10]), and an advanced tool like Text2Onto [11] was set up already in 2005. However, interest in KE was initially limited in the SW community, which preferred to concentrate on manual design of ontologies as a seal of quality. Things started changing after the linked data bootstrapping provided by DB- pedia [22], and the consequent need for substantial population of knowledge bases, schema induction from data, natural language access to structured data, and in general all applications that make joint exploitation of structured and unstructured content. -

Bilingual Dictionary Generation for Low-Resourced Language Pairs
Bilingual dictionary generation for low-resourced language pairs Varga István Yokoyama Shoichi Yamagata University, Yamagata University, Graduate School of Science and Engineering Graduate School of Science and Engineering [email protected] [email protected] choice and adaptation of the translation method Abstract to the problem of available translation resources between the chosen languages. Bilingual dictionaries are vital resources in One possible solution is bilingual corpus ac- many areas of natural language processing. quisition for statistical machine translation Numerous methods of machine translation re- (SMT). However, for highly accurate SMT sys- quire bilingual dictionaries with large cover- tems large bilingual corpora are required, which age, but less-frequent language pairs rarely are rarely available for less represented lan- have any digitalized resources. Since the need for these resources is increasing, but the hu- guages. Rule or sentence pattern based systems man resources are scarce for less represented are an attractive alternative, for these systems the languages, efficient automatized methods are need for a bilingual dictionary is essential. needed. This paper introduces a fully auto- Our paper targets bilingual dictionary genera- mated, robust pivot language based bilingual tion, a resource which can be used within the dictionary generation method that uses the frameworks of a rule or pattern based machine WordNet of the pivot language to build a new translation system. Our goal is to provide a low- bilingual dictionary. We propose the usage of cost, robust and accurate dictionary generation WordNet in order to increase accuracy; we method. Low cost and robustness are essential in also introduce a bidirectional selection method order to be re-implementable with any arbitrary with a flexible threshold to maximize recall. -

A Combined Method for E-Learning Ontology Population Based on NLP and User Activity Analysis
A Combined Method for E-Learning Ontology Population based on NLP and User Activity Analysis Dmitry Mouromtsev, Fedor Kozlov, Liubov Kovriguina and Olga Parkhimovich ITMO University, St. Petersburg, Russia [email protected], [email protected], [email protected], [email protected] Abstract. The paper describes a combined approach to maintaining an E-Learning ontology in dynamic and changing educational environment. The developed NLP algorithm based on morpho-syntactic patterns is ap- plied for terminology extraction from course tasks that allows to interlink extracted terms with the instances of the system’s ontology whenever some educational materials are changed. These links are used to gather statistics, evaluate quality of lectures’ and tasks’ materials, analyse stu- dents’ answers to the tasks and detect difficult terminology of the course in general (for the teachers) and its understandability in particular (for every student). Keywords: Semantic Web, Linked Learning, terminology extraction, education, educational ontology population 1 Introduction Nowadays reusing online educational resources becomes one of the most promis- ing approaches for e-learning systems development. A good example of using semantics to make education materials reusable and flexible is the SlideWiki system[1]. The key feature of an ontology-based e-learning system is the possi- bility for tutors and students to treat elements of educational content as named objects and named relations between them. These names are understandable both for humans as titles and for the system as types of data. Thus educational materials in the e-learning system thoroughly reflect the structure of education process via relations between courses, modules, lectures, tests and terms. -

The Impact of Using a Bilingual Dictionary (English-Arabic) for Reading and Writing in a Saudi High School
THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL By Ali Almaliki A Master’s Thesis/Project Capstone Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Education Teaching English to Speakers of Other Languages (TESOL) Department of Language, Learning and leadership State University of New York at Fredonia Fredonia, New York December 2017 THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL ABSTRACT The purpose of this study is to explore the impact of using a bilingual dictionary (English- Arabic) for reading and writing in a Saudi high school and also to explore the Saudi Arabian students’ attitudes and EFL teachers’ perceptions toward the use of bilingual dictionaries. This study involves 65 EFL students and 5 EFL teachers in one Saudi high school in the city of Alkobar. Mixed methods research is used in which both qualitative and quantitative data are collected. For participating students, pre-test, post-test, and surveys are used to collect quantitative data. For participating teachers and students, in-person interviews are conducted with select teachers and students so as to collect qualitative data. This study has produced eight findings; first is that the use of a bilingual dictionary has a significant effect on the reading and writing scores for both high and low proficiency EFL students. Other findings include that most EFL students feel that using a bilingual dictionary in EFL classrooms is very important to help them translate and learn new vocabulary words but their use of a bilingual dictionary is limited by the strategies for use that students know or are taught, and that both invoice and experienced EFL teachers agree that the use of a bilingual dictionary is important for learning word meaning and vocabulary, but they do not all agree about which grades should use bilingual dictionaries. -

Dictionaries in the ESL Classroom
7/22/2009 The need for dictionaries in the ESL classroom: Dictionaries empower students by making them responsible for their own learning. Once students are able to use a dictionary well, they are self-sufficient in Dictionaries: finding the information on their own. Use and Function in the ESL Dictionaries present a very useful tool in the ESL classroom. However, teachers need to EXPLICITLY teach students skills so that they can be Classroom utilized to maximum extent. Dictionary use can enhance vocabulary acquisition and comprehension. If the dictionary is sufficiently current, and idiomatic colloquialisms are included, the student can [also] see representations of contemporary culture as seen through language. Why teachers need to explicitly teach dictionary skills: “If we do not teach students how to use the dictionary, it is unlikely that they will demand that they be taught, since, while teachers do not believe that students have adequate dictionary skills, students believe that they do” (Bilash, Gregoret & Loewen, 1999, p.4). Dictionary use skills: Dictionaries are not self explanatory; directions need to be made clear so that students can disentangle information, and select the appropriate meaning for the task at hand. Students need to learn how a dictionary works, how a dictionary or reference resource can help them, and also how to become aware of what they need and what kind of dictionary will best respond to their needs. Teachers need to firstly make sure that students are acquainted and familiar with the alphabet and its order. Secondly, teachers need to orientate students as to what a dictionary As students become more familiar and comfortable with basic dictionary entails, its functions, and relative terminology. -

Information Extraction Using Natural Language Processing
INFORMATION EXTRACTION USING NATURAL LANGUAGE PROCESSING Cvetana Krstev University of Belgrade, Faculty of Philology Information Retrieval and/vs. Natural Language Processing So close yet so far Outline of the talk ◦ Views on Information Retrieval (IR) and Natural Language Processing (NLP) ◦ IR and NLP in Serbia ◦ Language Resources (LT) in the core of NLP ◦ at University of Belgrade (4 representative resources) ◦ LR and NLP for Information Retrieval and Information Extraction (IE) ◦ at University of Belgrade (4 representative applications) Wikipedia ◦ Information retrieval ◦ Information retrieval (IR) is the activity of obtaining information resources relevant to an information need from a collection of information resources. Searches can be based on full-text or other content-based indexing. ◦ Natural Language Processing ◦ Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages. As such, NLP is related to the area of human–computer interaction. Many challenges in NLP involve: natural language understanding, enabling computers to derive meaning from human or natural language input; and others involve natural language generation. Experts ◦ Information Retrieval ◦ As an academic field of study, Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collection (usually stored on computers). ◦ C. D. Manning, P. Raghavan, H. Schutze, “Introduction to Information Retrieval”, Cambridge University Press, 2008 ◦ Natural Language Processing ◦ The term ‘Natural Language Processing’ (NLP) is normally used to describe the function of software or hardware components in computer system which analyze or synthesize spoken or written language. -

A Terminology Extraction System for Technology Related Terms
TEST: A Terminology Extraction System for Technology Related Terms Murhaf Hossari Soumyabrata Dev John D. Kelleher ADAPT Centre, Trinity College ADAPT Centre, Trinity College ADAPT Centre, Technological Dublin Dublin University Dublin Dublin, Ireland Dublin, Ireland Dublin, Ireland [email protected] [email protected] [email protected] ABSTRACT of applications [6], ranging from e-mail spam filtering, advertising Tracking developments in the highly dynamic data-technology and marketing industry [4, 7], and social media. Particularly, in landscape are vital to keeping up with novel technologies and tools, these realm of online articles and blog articles, the growth in the in the various areas of Artificial Intelligence (AI). However, It is amount of information is almost in an exponential nature. Therefore, difficult to keep track of all the relevant technology keywords. In it is important for the researchers to develop a system that can this paper, we propose a novel system that addresses this problem. automatically parse the millions of documents, and identify the key This tool is used to automatically detect the existence of new tech- technological terms. Such system will greatly reduce the manual nologies and tools in text, and extract terms used to describe these work, and save several man-hours. new technologies. The extracted new terms can be logged as new In this paper, we develop a machine-learning based solution, AI technologies as they are found on-the-fly in the web. It can be that is capable of the discovery and extraction of information re- subsequently classified into the relevant semantic labels and AIdo- lated to AI technologies. -

Ontology Learning and Its Application to Automated Terminology Translation
Natural Language Processing Ontology Learning and Its Application to Automated Terminology Translation Roberto Navigli and Paola Velardi, Università di Roma La Sapienza Aldo Gangemi, Institute of Cognitive Sciences and Technology lthough the IT community widely acknowledges the usefulness of domain ontolo- A gies, especially in relation to the Semantic Web,1,2 we must overcome several bar- The OntoLearn system riers before they become practical and useful tools. Thus far, only a few specific research for automated ontology environments have ontologies. (The “What Is an Ontology?” sidebar on page 24 provides learning extracts a definition and some background.) Many in the and is part of a more general ontology engineering computational-linguistics research community use architecture.4,5 Here, we describe the system and an relevant domain terms WordNet,3 but large-scale IT applications based on experiment in which we used a machine-learned it require heavy customization. tourism ontology to automatically translate multi- from a corpus of text, Thus, a critical issue is ontology construction— word terms from English to Italian. The method can identifying, defining, and entering concept defini- apply to other domains without manual adaptation. relates them to tions. In large, complex application domains, this task can be lengthy, costly, and controversial, because peo- OntoLearn architecture appropriate concepts in ple can have different points of view about the same Figure 1 shows the elements of the architecture. concept. Two main approaches aid large-scale ontol- Using the Ariosto language processor,6 OntoLearn a general-purpose ogy construction. The first one facilitates manual extracts terminology from a corpus of domain text, ontology engineering by providing natural language such as specialized Web sites and warehouses or doc- ontology, and detects processing tools, including editors, consistency uments exchanged among members of a virtual com- checkers, mediators to support shared decisions, and munity. -

Translate's Localization Guide
Translate’s Localization Guide Release 0.9.0 Translate Jun 26, 2020 Contents 1 Localisation Guide 1 2 Glossary 191 3 Language Information 195 i ii CHAPTER 1 Localisation Guide The general aim of this document is not to replace other well written works but to draw them together. So for instance the section on projects contains information that should help you get started and point you to the documents that are often hard to find. The section of translation should provide a general enough overview of common mistakes and pitfalls. We have found the localisation community very fragmented and hope that through this document we can bring people together and unify information that is out there but in many many different places. The one section that we feel is unique is the guide to developers – they make assumptions about localisation without fully understanding the implications, we complain but honestly there is not one place that can help give a developer and overview of what is needed from them, we hope that the developer section goes a long way to solving that issue. 1.1 Purpose The purpose of this document is to provide one reference for localisers. You will find lots of information on localising and packaging on the web but not a single resource that can guide you. Most of the information is also domain specific ie it addresses KDE, Mozilla, etc. We hope that this is more general. This document also goes beyond the technical aspects of localisation which seems to be the domain of other lo- calisation documents. -

Generating Domain Terminologies Using Root- and Rule-Based Terms1
Generating Domain Terminologies using Root- and Rule-Based Terms1 Jacob Collard1, T. N. Bhat2, Eswaran Subrahmanian3,4, Ram D. Sriram3, John T. Elliot2, Ursula R. Kattner2, Carelyn E. Campbell2, Ira Monarch4,5 Independent Consultant, Ithaca, New York1, Materials Measurement Laboratory, National Institute of Standards and Technology, Gaithersburg, MD2, Information Technology Laboratory, National Institute of Standards and Technology, Gaithersburg, MD 3, Carnegie Mellon University, Pittsburgh, PA4, Independent Consultant, Pittsburgh, PA5 Abstract Motivated by the need for flexible, intuitive, reusable, and normalized terminology for guiding search and building ontologies, we present a general approach for generating sets of such terminologies from natural language documents. The terms that this approach generates are root- and rule-based terms, generated by a series of rules designed to be flexible, to evolve, and, perhaps most important, to protect against ambiguity and standardize semantically similar but syntactically distinct phrases to a normal form. This approach combines several linguistic and computational methods that can be automated with the help of training sets to quickly and consistently extract normalized terms. We discuss how this can be extended as natural language technologies improve and how the strategy applies to common use-cases such as search, document entry and archiving, and identifying, tracking, and predicting scientific and technological trends. Keywords dependency parsing; natural language processing; ontology generation; search; terminology generation; unsupervised learning. 1. Introduction 1.1 Terminologies and Semantic Technologies Services and applications on the world-wide web, as well as standards defined by the World Wide Web Consortium (W3C), the primary standards organization for the web, have been integrating semantic technologies into the Internet since 2001 (Koivunen and Miller 2001).