A Proposal of Community-Based Folksonomy with RDF Metadata
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Blogs and Websites Basics
P a g e | 1 Blogs and Websites Basics ABOUT THIS CLASS This class is designed to introduce you to the basic concepts and skills required for starting and maintaining a basic website in the form of a blog. Course Objectives By the end of this course, you will know: The difference between a blog and a website. The difference between hosted and non-hosted sites. What a blogging platform is and how to choose one for your site. How to choose a template (your blog’s appearance). How to post and add pages to your blog. How to avoid making common blogging/website mistakes. Best practices and essential things to know to make your blog/site as successful as possible. This booklet will serve as a guide as we progress through the class, but it can also be a valuable tool when you are working on your own. Any class instruction is only as effective as the time and effort you are willing to invest in it. I encourage you to practice soon after class. There will be additional computer classes in the near future, and I am usually available for questions during Tech Times on Tuesdays (10am-noon) and Thursdays (3pm-5pm). Feel free to call to verify that Tech Time is happening on the day that you’re planning to come. Meg Wempe, Adult Services Librarian P a g e | 2 Blogs vs. Websites What’s the difference between a blog and website? Blog: A blog (a combination of the term web log) is a discussion or informational site published on the World Wide Web and consisting of discrete entries ("posts") typically displayed in reverse chronological order (the most recent post appears first). -

How to Find the Best Hashtags for Your Business Hashtags Are a Simple Way to Boost Your Traffic and Target Specific Online Communities
CHECKLIST How to find the best hashtags for your business Hashtags are a simple way to boost your traffic and target specific online communities. This checklist will show you everything you need to know— from the best research tools to tactics for each social media network. What is a hashtag? A hashtag is keyword or phrase (without spaces) that contains the # symbol. Marketers tend to use hashtags to either join a conversation around a particular topic (such as #veganhealthchat) or create a branded community (such as Herschel’s #WellTravelled). HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 1 WAYS TO USE 3 HASHTAGS 1. Find a specific audience Need to reach lawyers interested in tech? Or music lovers chatting about their favorite stereo gear? Hashtags are a simple way to find and reach niche audiences. 2. Ride a trend From discovering soon-to-be viral videos to inspiring social movements, hashtags can quickly connect your brand to new customers. Use hashtags to discover trending cultural moments. 3. Track results It’s easy to monitor hashtags across multiple social channels. From live events to new brand campaigns, hashtags both boost engagement and simplify your reporting. HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 2 HOW HASHTAGS WORK ON EACH SOCIAL NETWORK Twitter Hashtags are an essential way to categorize content on Twitter. Users will often follow and discover new brands via hashtags. Try to limit to two or three. Instagram Hashtags are used to build communities and help users find topics they care about. For example, the popular NYC designer Jessica Walsh hosts a weekly Q&A session tagged #jessicasamamondays. -

N8ek Kf N?8Kêj L
:FM<IJKFIP Trackbacks in Drupal :fe]`^li`e^KiXZbYXZbj`e;ilgXc C<8M@E> 8o\cK\`Z_dXee#=fkfc`X KI8:BJ Trackbacks offer a simple means for bloggers to connect and share information. BY JAMES STANGER trackback is a way for a blogger With trackbacks, two seemingly unre- Several content management systems to automatically notify different lated conversations become more (CMSs) include trackback options. In N8EKKFBEFN 8blogs that he or she has either strongly associated. Each time an update Drupal [1], if you’ve enabled trackbacks, begun or extended a conversation with occurs in the conversation, the context a blogger on your system just has to another blogger. A trackback is one of becomes stronger and richer. Search en- enter the URL of a remote blogger who three main types of linkbacks (see the gines often rank pages higher if they are supports trackbacks, and the blogger N?8KÊJLGE<OK6 “Trackbacks and Linkbacks” box) that linked from other sites. Trackbacks thus will be notified. In this article, I describe bloggers use to keep track of each oth- promote higher ratings and perhaps how to set up trackbacks in Drupal with er’s postings and ensure that their read- more exposure for a project or product. examples based on the implementation ers can link to related content. Once a website has trackbacks enabled, one blogger can reach out to another on a separate site by sending a “ping” to that user. The ping simply says, “Here’s a topic that is related to what you’ve JL9J:I@9<KFC@ELO posted, check it out.” If a blogger on a separate site wants to D8>8Q@E<GI<M@<N# respond, the conversation between the two bloggers becomes stronger. -

Studying Social Tagging and Folksonomy: a Review and Framework
Studying Social Tagging and Folksonomy: A Review and Framework Item Type Journal Article (On-line/Unpaginated) Authors Trant, Jennifer Citation Studying Social Tagging and Folksonomy: A Review and Framework 2009-01, 10(1) Journal of Digital Information Journal Journal of Digital Information Download date 02/10/2021 03:25:18 Link to Item http://hdl.handle.net/10150/105375 Trant, Jennifer (2009) Studying Social Tagging and Folksonomy: A Review and Framework. Journal of Digital Information 10(1). Studying Social Tagging and Folksonomy: A Review and Framework J. Trant, University of Toronto / Archives & Museum Informatics 158 Lee Ave, Toronto, ON Canada M4E 2P3 jtrant [at] archimuse.com Abstract This paper reviews research into social tagging and folksonomy (as reflected in about 180 sources published through December 2007). Methods of researching the contribution of social tagging and folksonomy are described, and outstanding research questions are presented. This is a new area of research, where theoretical perspectives and relevant research methods are only now being defined. This paper provides a framework for the study of folksonomy, tagging and social tagging systems. Three broad approaches are identified, focusing first, on the folksonomy itself (and the role of tags in indexing and retrieval); secondly, on tagging (and the behaviour of users); and thirdly, on the nature of social tagging systems (as socio-technical frameworks). Keywords: Social tagging, folksonomy, tagging, literature review, research review 1. Introduction User-generated keywords – tags – have been suggested as a lightweight way of enhancing descriptions of on-line information resources, and improving their access through broader indexing. “Social Tagging” refers to the practice of publicly labeling or categorizing resources in a shared, on-line environment. -

Using RSS to Spread Your Blog
10_588486 ch04.qxd 3/4/05 11:33 AM Page 67 Chapter 4 Using RSS to Spread Your Blog In This Chapter ᮣ Understanding just what a blog is ᮣ Creating the blog and the feed ᮣ Using your RSS reader ᮣ Creating a blog using HTML ᮣ Maintaining your blog ᮣ Publicizing your blog with RSS hat’s a blog, after all? Blog, short for Web log, is just a Web site with Wa series of dated entries, with the most recent entry on top. Those entries can contain any type of content you want. Blogs typically include links to other sites and online articles with the blogger’s reactions and com- ments, but many blogs simply contain the blogger’s own ramblings. Unquestionably, the popularity of blogging has fueled the expansion of RSS feeds. According to Technorati, a company that offers a search engine for blogs in addition to market research services, about one-third of blogs have RSS feeds. Some people who maintain blogs are publishing an RSS feed with- out even knowing about it, because some of the blog Web sites automatically create feeds (more about how this happens shortly). If you think that blogs are only personal affairs, remember that Microsoft has hundreds of them, and businesses are using them more and more to keep employees, colleagues, and customersCOPYRIGHTED up to date. MATERIAL In this chapter, I give a quick overview of blogging and how to use RSS with your blog to gain more readers. If you want to start a blog, this chapter explains where to go next. -

Or “Reflective Blog”
Guide for writing a “journal blog” or “reflective blog” What is a reflective blog and why should you use one? (Adapted from Professor Wayne Iwaoka, the University of Hawaii at Manoa and UMaine’s SMS 491/EDW 472/SMS416). The blog is used in this class as a modern replacement to the more traditional journal. It is an instrument for practicing writing and thinking. Unlike your typical class notes in which you “passively” record data/information given to you by an instructor your blog should reflect upon lessons you have learned-- a personal record of your educational experience in the class. Maintaining a blog serves several purposes: • A means of communication, conversation (e.g., between material and yourself, yourself and instructors). • Provides regular feedback between you and instructors and helps to match expectations. • Platform for synthesis of new knowledge and ideas. • Helps to develop critical thinking. • Helps to elicit topics of interest, challenging topics that need improvement, etc. • Help to clarify troublesome concepts. The purpose of the blog is for you to self reflect about your own learning. How to set up a blog? You can set a blog with many different companies. Below we provide instruction on how to do it with Google blogger. Note: If you already have one or more other blogs, please set up a new one for this course. 1. Because Google blogger requires a google mail account, use your official UMaine email account. Note: an account in the form of [email protected] is a gmail account. 2. Go to www.blogger.com and enter your Gmail address and password as required 3. -

Introduction to Web 2.0 Technologies
Introduction to Web 2.0 Joshua Stern, Ph.D. Introduction to Web 2.0 Technologies What is Web 2.0? Æ A simple explanation of Web 2.0 (3 minute video): http://www.youtube.com/watch?v=0LzQIUANnHc&feature=related Æ A complex explanation of Web 2.0 (5 minute video): http://www.youtube.com/watch?v=nsa5ZTRJQ5w&feature=related Æ An interesting, fast-paced video about Web.2.0 (4:30 minute video): http://www.youtube.com/watch?v=NLlGopyXT_g Web 2.0 is a term that describes the changing trends in the use of World Wide Web technology and Web design that aim to enhance creativity, secure information sharing, increase collaboration, and improve the functionality of the Web as we know it (Web 1.0). These have led to the development and evolution of Web-based communities and hosted services, such as social-networking sites (i.e. Facebook, MySpace), video sharing sites (i.e. YouTube), wikis, blogs, etc. Although the term suggests a new version of the World Wide Web, it does not refer to any actual change in technical specifications, but rather to changes in the ways software developers and end- users utilize the Web. Web 2.0 is a catch-all term used to describe a variety of developments on the Web and a perceived shift in the way it is used. This shift can be characterized as the evolution of Web use from passive consumption of content to more active participation, creation and sharing. Web 2.0 Websites allow users to do more than just retrieve information. -

Microblogging Tool That Allows Users to Post Brief, 140-Character Messages -- Called "Tweets" -- and Follow Other Users' Activities
MICRO-BLOGGING AND PERFORMANCE APPS AND SITES Instagram lets users snap, edit, and share photos and 15-second videos, either publicly or with a private network of followers. It unites the most popular features of social media sites: sharing, seeing, and commenting on photos. It also lets you apply fun filters and effects to your photos, making them look high-quality and artistic. What parents need to know • Teens are on the lookout for "likes." Similar to the way they use Facebook, teens may measure the "success" of their photos -- even their self-worth -- by the number of likes or comments they receive. Posting a photo or video can be problematic if teens are posting to validate their popularity. • Public photos are the default. Photos and videos shared on Instagram are public unless privacy settings are adjusted. Hashtags and location information can make photos even more visible to communities beyond a teen's followers if his or her account is public. • Private messaging is now an option. Instagram Direct allows users to send "private messages" to up to 15 mutual friends. These pictures don't show up on their public feeds. Although there's nothing wrong with group chats, kids may be more likely to share inappropriate stuff with their inner circles. Tumblr is like a cross between a blog and Twitter: It's a streaming scrapbook of text, photos, and/or videos and audio clips. Users create and follow short blogs, or "tumblogs," that can be seen by anyone online (if made public). Many teens have tumblogs for personal use: sharing photos, videos, musings, and things they find funny with their friends. -

Handbook for Bloggers and Cyber-Dissidents
HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS REPORTERS WITHOUT BORDERS MARCH 2008 Файл загружен с http://www.ifap.ru HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS CONTENTS © 2008 Reporters Without Borders 04 BLOGGERS, A NEW SOURCE OF NEWS Clothilde Le Coz 07 WHAT’S A BLOG ? LeMondedublog.com 08 THE LANGUAGE OF BLOGGING LeMondedublog.com 10 CHOOSING THE BEST TOOL Cyril Fiévet, Marc-Olivier Peyer and LeMondedublog.com 16 HOW TO SET UP AND RUN A BLOG The Wordpress system 22 WHAT ETHICS SHOULD BLOGUEURS HAVE ? Dan Gillmor 26 GETTING YOUR BLOG PICKED UP BY SEARCH-ENGINES Olivier Andrieu 32 WHAT REALLY MAKES A BLOG SHINE ? Mark Glaser 36 P ERSONAL ACCOUNTS • SWITZERLAND: “” Picidae 40 • EGYPT: “When the line between journalist and activist disappears” Wael Abbas 43 • THAILAND : “The Web was not designed for bloggers” Jotman 46 HOW TO BLOG ANONYMOUSLY WITH WORDPRESS AND TOR Ethan Zuckerman 54 TECHNICAL WAYS TO GET ROUND CENSORSHIP Nart Villeneuve 71 ENS URING YOUR E-MAIL IS TRULY PRIVATE Ludovic Pierrat 75 TH E 2008 GOLDEN SCISSORS OF CYBER-CENSORSHIP Clothilde Le Coz 3 I REPORTERS WITHOUT BORDERS INTRODUCTION BLOGGERS, A NEW SOURCE OF NEWS By Clothilde Le Coz B loggers cause anxiety. Governments are wary of these men and women, who are posting news, without being professional journalists. Worse, bloggers sometimes raise sensitive issues which the media, now known as "tradition- al", do not dare cover. Blogs have in some countries become a source of news in their own right. Nearly 120,000 blogs are created every day. Certainly the blogosphere is not just adorned by gems of courage and truth. -
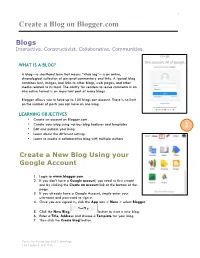
Create a Blog on Blogger.Com 1
1 Create a Blog on Blogger.com Blogs Interactive. Constructivist. Collaborative. Communities. WHAT IS A BLOG? A blog—a shorthand term that means “Web log”—is an online, chronological collection of personal commentary and links. A typical blog combines text, images, and links to other blogs, web pages, and other media related to its topic. The ability for readers to leave comments in an interactive format is an important part of many blogs. Blogger allows you to have up to 100 blogs per account. There is no limit on the number of posts you can have on one blog. LEARNING OBJECTIVES • Create an account on Blogger.com • Create your blog using various blog features and templates • Edit and publish your blog 1 • Learn about the different settings • Learn to create a collaborative blog with multiple authors Create a New Blog Using your Google Account 1. Login to www.blogger.com 2. If you don’t have a Google account, you need to first create one by clicking the Create an account link at the bottom of the page. 3. If you already have a Google Account, simply enter your username and password to sign in. 4. Once you are signed in, click the App icon > More > select Blogger. 5. Click the New Blog button to start a new blog. 6. Enter a Title, Address and choose a Template for your blog. 7. Then click the Create blog! button. Center for Instruction and Technology Last Updated: 4/5/2016 2 2 When your blog is created, click the Start posting link on the Dashboard page. -

Citizen Journalism Via Blogging: a Possible Resolution to Mainstream Media’S Ineptitude Heba Elshahed1* and Sally Tayie2
Research Article Global Media Journal 2019 Vol.17 No. ISSN 1550-7521 33:193 Citizen Journalism via Blogging: A Possible Resolution to Mainstream Media’s Ineptitude Heba Elshahed1* and Sally Tayie2 1Journalism and Mass Communication Department, The American University in Cairo, Egypt 2University Autònoma de Barcelona, Spain *Corresponding author: Heba Elshahed, Journalism and Mass Communication Department, The American University in Cairo, Egypt, Tel: +201001924654; E-mail: [email protected] Received date: Nov 02, 2019; Accepted date: Dec 02, 2019; Published date: Dec 09, 2019 Copyright: © 2019 Elshahed H, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Citation: Elshahed H, Tayie S. Citizen Journalism via Blogging: A Possible Resolution to Mainstream Media’s Ineptitude. Global Media Journal 2019, 17:33. Keywords: Blogosphere; Social media; Political activism; Abstract Facebook revolution Throughout the past years, the emergence of the Egyptian Introduction Blogosphere has been a definitive phenomenon. The Egyptian Blogosphere went through fluctuations and The introduction of a “Wireless World” in the mid 1990’s evolutionary phases, resulting in it becoming a powerful and early 2000’s reformed the entire media landscape, giving platform for cyber space political activism and citizen media an entirely new role in society. Today, the world is journalism, in attempts to compensate for the becoming entirely wireless. Informational videos, movies, mainstream media ’ s inadequacy. This paper explores music, pictures and even personas and figures can be accessed previous studies conducted on this topic. -

Using RSS and Weblogs for E-Learning: an Overview
May 19 2003 Strategies and Techniques for Designers, Developers, and Managers of eLearning THIS WEEK — DEVELOPMENT STRATEGIES New technologies are Using RSS and Weblogs for continually coming e-Learning: An Overview to the fore, and many of them have applica- BY BILL BRANDON tions to e-Learning. impler is better. There are a lot of “needs” in e-Learning, Weblogs and RSS and there’s often a limit to the time, talent, and money (an XML standard that can be thrown at them individually. For example, S for distribution of take facilitating communication across project teams during information) are design and development, or between instructors and learners making substantial when they are separated by time and space, or between learn- progress in 2003. ers while building a community. What if there was a way to use This overview will “public” infrastructure for this, reducing the cost of infrastruc- give you a taste of ture and software? Or what if there was a low-cost way to pub- what is being done lish learning objects for use by other developers, or to acquire with these by early learning resources for use in your own projects, or to make adopters. You may them available for direct use by learners? find some ideas that These challenges have at least two relat- two developments, and to some of the ed potential solutions that have been mak- more appropriate ways they are being will meet your needs ing rapid strides in the first half of 2003: applied to e-Learning. to do things more weblogs (or “blogs”) and RSS (an abbrevia- tion with more than one meaning, as you A fast overview simply and more will soon see).