Data Scouting for GALE/REFLEX
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Find the Best Hashtags for Your Business Hashtags Are a Simple Way to Boost Your Traffic and Target Specific Online Communities
CHECKLIST How to find the best hashtags for your business Hashtags are a simple way to boost your traffic and target specific online communities. This checklist will show you everything you need to know— from the best research tools to tactics for each social media network. What is a hashtag? A hashtag is keyword or phrase (without spaces) that contains the # symbol. Marketers tend to use hashtags to either join a conversation around a particular topic (such as #veganhealthchat) or create a branded community (such as Herschel’s #WellTravelled). HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 1 WAYS TO USE 3 HASHTAGS 1. Find a specific audience Need to reach lawyers interested in tech? Or music lovers chatting about their favorite stereo gear? Hashtags are a simple way to find and reach niche audiences. 2. Ride a trend From discovering soon-to-be viral videos to inspiring social movements, hashtags can quickly connect your brand to new customers. Use hashtags to discover trending cultural moments. 3. Track results It’s easy to monitor hashtags across multiple social channels. From live events to new brand campaigns, hashtags both boost engagement and simplify your reporting. HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 2 HOW HASHTAGS WORK ON EACH SOCIAL NETWORK Twitter Hashtags are an essential way to categorize content on Twitter. Users will often follow and discover new brands via hashtags. Try to limit to two or three. Instagram Hashtags are used to build communities and help users find topics they care about. For example, the popular NYC designer Jessica Walsh hosts a weekly Q&A session tagged #jessicasamamondays. -

BTLOOKSMART SIGNS TWO YEAR DEAL with BT OPENWORLD Submitted By: Prodigy Communications Monday, 23 September 2002
BTLOOKSMART SIGNS TWO YEAR DEAL WITH BT OPENWORLD Submitted by: Prodigy Communications Monday, 23 September 2002 Leading UK ISP Teams With BTLookSmart for Two More Years London, 23rd September 2002 BTLookSmart today announced a two year advertising and search syndication deal with leading UK Internet service provider (ISP) BT Openworld. BTLookSmart is the international joint venture between LookSmart (NASDAQ: LOOK; ASX: LOK), global leader in Search Targeted Marketing, and British Telecommunications (NYSE: BTY). The agreement is an extension of an existing contract with BTLookSmart providing web search and directory solutions to BT Openworld. The comprehensive advertising and syndication deal stems from the companies joint initiatives to support the development of new revenue streams and the optimal monetisation of search traffic. BTLookSmart will host and serve BT Openworld’s search and directory service. The agreement, including sales of space for BidSmart Featured Listings, Performance Listings and graphical advertising, will be controlled and operated by BTLookSmart. The mechanism will allow highly targeted advertising through cross-linking to keyword search and categories. Revenues generated will be shared between BT Openworld and BTLookSmart. “The extension of our contract with BT Openworld is an endorsement of BTLookSmart’s strengths and expertise in the provision of search and directory services. This syndication deal, coupled with our recent acquisition of UK Plus, shows that we are in a unique position to provide a total managed search solution for ISPs and Portals,” said Kevin Kerrigan, BTLookSmart COO. “We look forward to continue working with BTLookSmart to provide highly effective search results for our customers as well as effective monetisation of search traffic”, said Mehdi Salam, Director of Sales, BT Openworld. -

Consumer-Reports-Web
TRUST WORTHY 13/WNET (www.thirteen.org)* E*TRADE FINANCIAL* The New York Times Online (NYTimes.com) A. Briggs Passport & Visa Expeditors, Inc.* Eastman Kodak Company* North Jersey Media Group* Adobe.com eMedicine.com, Inc.* Orbitz Aetna InteliHealth (www.intelihealth.com)* Epiar Inc.* Pfaltzgraff.com Air Force Association (www.afa.org)* Evolving Systems, Inc. (evolve.net)* Quackwatch* Alliance Consulting Group Associates Inc.* Factiva (www.factiva.com)* REALAGE (www.realage.com)* AmSouth Bank (www.amsouth.com)* FAIR: Fairness & Accuracy in Reporting RealNetworks (www.fair.org)* Anvil Media, Inc.* Roll Call (www.rollcall.com)*; Federal Computer Week* RCjobs (www.rcjobs.com)* Aon Corporation (www.aon.com)* FM-CFS Canada* St. Petersburg Times (www.sptimes.com)* Bankrate.com Forbes.com Inc. (www.forbes.com)* Sallie Mae (www.salliemae.com)* Barnes&Noble.com (bn.com) Greater Philadelphia Tourism Marketing Scholastic (www.scholastic.com)* Beliefnet Corporation (www.gophila.com) Shopping.com Best Buy Company, Inc. (BestBuy.com)* Healthology* Show Business Weekly* Beyond Ink LLC* Hewlett-Packard (hp.com) Sleeve City (www.sleevetown.com)* bismarcktribune.com* Hilton Hotels Corporation (www.hilton.com)* SponsorAnything.com* BMI Gaming, Inc. (www.bmigaming.com)* Hispanic Radio Network* Suicide and Mental Health Association International* BurlingtonCoatFactory.com*; BabyDepot.com* HotJobs TapeandMedia.com* Business Technology Association* Hotwire Thrivent Financial for Lutherans* Cablevision* INGDIRECT.com (www.thrivent.com) CARFAX* Ingenio, Inc.* -

Or “Reflective Blog”
Guide for writing a “journal blog” or “reflective blog” What is a reflective blog and why should you use one? (Adapted from Professor Wayne Iwaoka, the University of Hawaii at Manoa and UMaine’s SMS 491/EDW 472/SMS416). The blog is used in this class as a modern replacement to the more traditional journal. It is an instrument for practicing writing and thinking. Unlike your typical class notes in which you “passively” record data/information given to you by an instructor your blog should reflect upon lessons you have learned-- a personal record of your educational experience in the class. Maintaining a blog serves several purposes: • A means of communication, conversation (e.g., between material and yourself, yourself and instructors). • Provides regular feedback between you and instructors and helps to match expectations. • Platform for synthesis of new knowledge and ideas. • Helps to develop critical thinking. • Helps to elicit topics of interest, challenging topics that need improvement, etc. • Help to clarify troublesome concepts. The purpose of the blog is for you to self reflect about your own learning. How to set up a blog? You can set a blog with many different companies. Below we provide instruction on how to do it with Google blogger. Note: If you already have one or more other blogs, please set up a new one for this course. 1. Because Google blogger requires a google mail account, use your official UMaine email account. Note: an account in the form of [email protected] is a gmail account. 2. Go to www.blogger.com and enter your Gmail address and password as required 3. -

Introduction to Web 2.0 Technologies
Introduction to Web 2.0 Joshua Stern, Ph.D. Introduction to Web 2.0 Technologies What is Web 2.0? Æ A simple explanation of Web 2.0 (3 minute video): http://www.youtube.com/watch?v=0LzQIUANnHc&feature=related Æ A complex explanation of Web 2.0 (5 minute video): http://www.youtube.com/watch?v=nsa5ZTRJQ5w&feature=related Æ An interesting, fast-paced video about Web.2.0 (4:30 minute video): http://www.youtube.com/watch?v=NLlGopyXT_g Web 2.0 is a term that describes the changing trends in the use of World Wide Web technology and Web design that aim to enhance creativity, secure information sharing, increase collaboration, and improve the functionality of the Web as we know it (Web 1.0). These have led to the development and evolution of Web-based communities and hosted services, such as social-networking sites (i.e. Facebook, MySpace), video sharing sites (i.e. YouTube), wikis, blogs, etc. Although the term suggests a new version of the World Wide Web, it does not refer to any actual change in technical specifications, but rather to changes in the ways software developers and end- users utilize the Web. Web 2.0 is a catch-all term used to describe a variety of developments on the Web and a perceived shift in the way it is used. This shift can be characterized as the evolution of Web use from passive consumption of content to more active participation, creation and sharing. Web 2.0 Websites allow users to do more than just retrieve information. -

2015 Valuation Handbook – Guide to Cost of Capital and Data Published Therein in Connection with Their Internal Business Operations
Market Results Through #DBDLADQ 2014 201 Valuation Handbook Guide to Cost of Capital Industry Risk Premia Company List Cover image: Duff & Phelps Cover design: Tim Harms Copyright © 2015 by John Wiley & Sons, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600, or on the Web at www.copyright.com. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748- 6008, or online at http://www.wiley.com/go/permissions. The forgoing does not preclude End-users from using the 2015 Valuation Handbook – Guide to Cost of Capital and data published therein in connection with their internal business operations. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. -

Looksmart to Bring Editorially-Reviewed Results to Infospace's Meta-Search Properties; Distribution Agreement Expanded and Extended to September 2003
LookSmart to Bring Editorially-Reviewed Results to InfoSpace's Meta-Search Properties; Distribution Agreement Expanded and Extended to September 2003 SAN FRANCISCO & BELLEVUE, Wash.--(BUSINESS WIRE)-- Business Editors SAN FRANCISCO & BELLEVUE, Wash.--Oct. 7, 2002--LookSmart (Nasdaq:LOOK) (ASX:LOK), a global leader in search marketing and InfoSpace, Inc. (Nasdaq:INSP), a provider of wireless and Internet software and application services, today announced that they have extended and expanded their search relationship. Under the expanded agreement, LookSmart will provide its editorially-reviewed Web site results, powered by its new, award- winning WiseNut search technology to InfoSpace's Web search properties, including Excite (www.excite.com), Dogpile (www.dogpile.com), WebCrawler (www.webcrawler.com) and MetaCrawler (www.metacrawler.com), as well as other InfoSpace search distribution relationships. In addition, LookSmart will continue to provide paid search listings to InfoSpace's meta-search network. The extended agreement runs to September 2003. "LookSmart's editorially-reviewed Web site results is another solid addition to our meta-search properties and further strengthens our business relationship with a leader in the Web search space," said York Baur, InfoSpace executive vice president, wireline and broadband. "Adding their new WiseNut powered editorially-reviewed search results to our meta-search properties underscores our commitment to providing the most relevant and comprehensive results to our users." "InfoSpace is an important strategic partner for LookSmart," said Brian Cowley, senior vice president of business development for LookSmart. "We look forward to continuing our work with InfoSpace and its leading meta-search capabilities to align the relevancy needs of search users with the targeting needs of advertisers." InfoSpace's next generation meta-search technology highlights the strengths of many of the Web's major search properties and is designed to identify the intent of each user's search. -

Microblogging Tool That Allows Users to Post Brief, 140-Character Messages -- Called "Tweets" -- and Follow Other Users' Activities
MICRO-BLOGGING AND PERFORMANCE APPS AND SITES Instagram lets users snap, edit, and share photos and 15-second videos, either publicly or with a private network of followers. It unites the most popular features of social media sites: sharing, seeing, and commenting on photos. It also lets you apply fun filters and effects to your photos, making them look high-quality and artistic. What parents need to know • Teens are on the lookout for "likes." Similar to the way they use Facebook, teens may measure the "success" of their photos -- even their self-worth -- by the number of likes or comments they receive. Posting a photo or video can be problematic if teens are posting to validate their popularity. • Public photos are the default. Photos and videos shared on Instagram are public unless privacy settings are adjusted. Hashtags and location information can make photos even more visible to communities beyond a teen's followers if his or her account is public. • Private messaging is now an option. Instagram Direct allows users to send "private messages" to up to 15 mutual friends. These pictures don't show up on their public feeds. Although there's nothing wrong with group chats, kids may be more likely to share inappropriate stuff with their inner circles. Tumblr is like a cross between a blog and Twitter: It's a streaming scrapbook of text, photos, and/or videos and audio clips. Users create and follow short blogs, or "tumblogs," that can be seen by anyone online (if made public). Many teens have tumblogs for personal use: sharing photos, videos, musings, and things they find funny with their friends. -

List of Section 13F Securities
List of Section 13F Securities 1st Quarter FY 2004 Copyright (c) 2004 American Bankers Association. CUSIP Numbers and descriptions are used with permission by Standard & Poors CUSIP Service Bureau, a division of The McGraw-Hill Companies, Inc. All rights reserved. No redistribution without permission from Standard & Poors CUSIP Service Bureau. Standard & Poors CUSIP Service Bureau does not guarantee the accuracy or completeness of the CUSIP Numbers and standard descriptions included herein and neither the American Bankers Association nor Standard & Poor's CUSIP Service Bureau shall be responsible for any errors, omissions or damages arising out of the use of such information. U.S. Securities and Exchange Commission OFFICIAL LIST OF SECTION 13(f) SECURITIES USER INFORMATION SHEET General This list of “Section 13(f) securities” as defined by Rule 13f-1(c) [17 CFR 240.13f-1(c)] is made available to the public pursuant to Section13 (f) (3) of the Securities Exchange Act of 1934 [15 USC 78m(f) (3)]. It is made available for use in the preparation of reports filed with the Securities and Exhange Commission pursuant to Rule 13f-1 [17 CFR 240.13f-1] under Section 13(f) of the Securities Exchange Act of 1934. An updated list is published on a quarterly basis. This list is current as of March 15, 2004, and may be relied on by institutional investment managers filing Form 13F reports for the calendar quarter ending March 31, 2004. Institutional investment managers should report holdings--number of shares and fair market value--as of the last day of the calendar quarter as required by Section 13(f)(1) and Rule 13f-1 thereunder. -

Handbook for Bloggers and Cyber-Dissidents
HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS REPORTERS WITHOUT BORDERS MARCH 2008 Файл загружен с http://www.ifap.ru HANDBOOK FOR BLOGGERS AND CYBER-DISSIDENTS CONTENTS © 2008 Reporters Without Borders 04 BLOGGERS, A NEW SOURCE OF NEWS Clothilde Le Coz 07 WHAT’S A BLOG ? LeMondedublog.com 08 THE LANGUAGE OF BLOGGING LeMondedublog.com 10 CHOOSING THE BEST TOOL Cyril Fiévet, Marc-Olivier Peyer and LeMondedublog.com 16 HOW TO SET UP AND RUN A BLOG The Wordpress system 22 WHAT ETHICS SHOULD BLOGUEURS HAVE ? Dan Gillmor 26 GETTING YOUR BLOG PICKED UP BY SEARCH-ENGINES Olivier Andrieu 32 WHAT REALLY MAKES A BLOG SHINE ? Mark Glaser 36 P ERSONAL ACCOUNTS • SWITZERLAND: “” Picidae 40 • EGYPT: “When the line between journalist and activist disappears” Wael Abbas 43 • THAILAND : “The Web was not designed for bloggers” Jotman 46 HOW TO BLOG ANONYMOUSLY WITH WORDPRESS AND TOR Ethan Zuckerman 54 TECHNICAL WAYS TO GET ROUND CENSORSHIP Nart Villeneuve 71 ENS URING YOUR E-MAIL IS TRULY PRIVATE Ludovic Pierrat 75 TH E 2008 GOLDEN SCISSORS OF CYBER-CENSORSHIP Clothilde Le Coz 3 I REPORTERS WITHOUT BORDERS INTRODUCTION BLOGGERS, A NEW SOURCE OF NEWS By Clothilde Le Coz B loggers cause anxiety. Governments are wary of these men and women, who are posting news, without being professional journalists. Worse, bloggers sometimes raise sensitive issues which the media, now known as "tradition- al", do not dare cover. Blogs have in some countries become a source of news in their own right. Nearly 120,000 blogs are created every day. Certainly the blogosphere is not just adorned by gems of courage and truth. -

2006 Software Industry Equity Report Summary
ABOUT OUR FIRM Software Equity Group is an investment bank and M&A advisory serving the software and technology sectors. Founded in 1992, our firm has advised and guided software companies and IT service providers in the United States, Canada, Europe, Asia Pacific, Africa and Israel. We represent successful private companies that seek to be acquired at a highly attractive valuation. We also provide buy-side M&A advisory services to major private equity firms and to public and private companies in search of strategic acquisitions. Our value proposition is unique and compelling. We are skilled and accomplished investment bankers with extraordinary software, internet and technology domain expertise. Our software industry experience spans virtually every technology, market and product category. We have profound understanding of software company finances, operations and valuation. We monitor and analyze every publicly disclosed software M&A transaction, as well as the market, economy and technology trends that impact these deals. We're formidable negotiators and savvy dealmakers who facilitate strategic combinations that enhance shareholder value. Perhaps most important, are the relationships we've built, and the industry reputation we enjoy. Software Equity Group is known and respected by publicly traded and privately owned software and technology companies worldwide, and we speak with them often. Our Quarterly and Annual Software Industry Equity Reports are read and relied upon by more than ten thousand industry executives, entrepreneurs and equity investors in twenty-six countries, and we have been quoted widely in such leading publications as Information Week, The Daily Deal, Barrons, U.S. News & World Report, Reuters, Mergers & Acquisitions, USA Today, Entrepreneur, Softletter, Software Success, Software CEO Online and Software Business Magazine. -
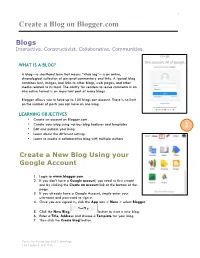
Create a Blog on Blogger.Com 1
1 Create a Blog on Blogger.com Blogs Interactive. Constructivist. Collaborative. Communities. WHAT IS A BLOG? A blog—a shorthand term that means “Web log”—is an online, chronological collection of personal commentary and links. A typical blog combines text, images, and links to other blogs, web pages, and other media related to its topic. The ability for readers to leave comments in an interactive format is an important part of many blogs. Blogger allows you to have up to 100 blogs per account. There is no limit on the number of posts you can have on one blog. LEARNING OBJECTIVES • Create an account on Blogger.com • Create your blog using various blog features and templates • Edit and publish your blog 1 • Learn about the different settings • Learn to create a collaborative blog with multiple authors Create a New Blog Using your Google Account 1. Login to www.blogger.com 2. If you don’t have a Google account, you need to first create one by clicking the Create an account link at the bottom of the page. 3. If you already have a Google Account, simply enter your username and password to sign in. 4. Once you are signed in, click the App icon > More > select Blogger. 5. Click the New Blog button to start a new blog. 6. Enter a Title, Address and choose a Template for your blog. 7. Then click the Create blog! button. Center for Instruction and Technology Last Updated: 4/5/2016 2 2 When your blog is created, click the Start posting link on the Dashboard page.