Can Machines Talk? Comparison of Eliza with Modern Dialogue Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Can Machines Think?
Sandringham School Faculty of Computer Science Can Machines Think? This is a question posed by famous English Computer Scientist Alan Turing in Intelligent machines and programmes are judged. 1950. His ‘Turing Test’ has become the benchmark by which Artificially Recently, the Turing Test hit the news when a programme that simulated a 13 year old Ukrainian boy (called Eugene Goostman) managed to convince a third of testers that they were talking to a real human. http://www.bbc.co.uk/news/technology-27762088 http://www.reading.ac.uk/news-and-events/releases/PR583836.aspx http://www.alicebot.org/chatbots3/Eugene.pdf Your summer assignment is as follows: 1. 2. DesigningInvestigate a who fully Alan functional Turing Chatbot was and that explain can process in detail human what the language ‘Turing is oneTest’ of is the and most how difficult it is important tasks in in Computer the world Science. of Artificial Why Intelligence is this, what are the challenges? How did the Eugene Goostman bot overcome these? 3. Time to write your own Chatbot. In any language you choose (e.g. Python, Scratch, Java etc.), write a simple Chatbot. Clearly you will have to limit the questions that your bot can ask and the responses that it will Chatbot called Eliza at : https://groklearning.com/csedweek/hoc-eliza/ 4. What‘understand’! are the positiveIf you are implications totally stuck, for see the getting development started ofwith Artificial a simple Intelligence? What are the dangers to society of truly intelligent machines? Your assignment should be at least 4 pages of A4, excluding the programme listing. -

Language Technologies Past Present, and Future
Language technologies past present, and future Christopher Potts CSLI Summer Internship Program July 21, 2017 Many slides joint work with Bill MacCartney: http://web.stanford.edu/class/cs224u/ Hype and hand-wringing • Jürgen Schmidhuber: “We are on the verge not of another industrial revolution, but a new form of life, more like the big bang.” [link] • Elon Musk: “AI is a fundamental existential risk for human civilization, and I don't think people fully appreciate that.” [link] • October 2016: “Microsoft has made a major breakthrough in speech recognition, creating a technology that recognizes the words in a conversation as well as a person does.” [link] Two perspectives Overview • What is understanding? • A brief history of language technologies • Language technologies of the past • Language technologies of today • Current approaches and prospects • Predictions about the future! Readings and other background • Percy Liang: Talking to computers in natural language • Levesque: On our best behaviour • Mitchell: Reading the Web: A breakthrough goal for AI • Podcast: The challenge and promise of artificial intelligence • Podcast: Hal Daume on Talking Machines • Stanford CS224u, Natural language understanding What is understanding? To understand a statement is to: • determine its truth (with justification) • calculate its entailments • take appropriate action in light of it • translate it into another language • … The Turing Test (Turing 1950) Turing replaced “Can machines think?”, which he regarded as “too meaningless to deserve discussion” (p. 442), with the question whether an interrogator could be tricked into thinking that a machine was a human using only conversation (no visuals, no demands for physical performance, etc.). Some of the objections Turing anticipates • “Thinking is a function of man’s immortal soul. -

Lessons from a Restricted Turing Test
Lessons from a Restricted Turing Test Stuart M. Shieber Aiken Computation Laboratory Division of Applied Sciences Harvard University March 28, 1994 (Revision 6) Abstract We report on the recent Loebner prize competition inspired by Turing’s test of intelligent behavior. The presentation covers the structure of the competition and the outcome of its first instantiation in an actual event, and an analysis of the purpose, design, and appropriateness of such a competition. We argue that the competition has no clear purpose, that its design prevents any useful outcome, and that such a competition is inappropriate given the current level of technology. We then speculate as to suitable alternatives to the Loebner prize. arXiv:cmp-lg/9404002v1 4 Apr 1994 This paper is to appear in Communications of the Association for Comput- ing Machinery, and is available from the Center for Research in Computing Technology, Harvard University, as Technical Report TR-19-92 and from the Computation and Language e-print server as cmp-lg/9404002. The Turing Test and the Loebner Prize The English logician and mathematician Alan Turing, in an attempt to develop a working definition of intelligence free of the difficulties and philosophical pitfalls of defining exactly what constitutes the mental process of intelligent reasoning, devised a test, instead, of intelligent behavior. The idea, codified in his cel- ebrated 1950 paper “Computing Machinery and Intelligence” (Turing, 1950), was specified as an “imitation game” in which a judge attempts to distinguish which of two agents is a human and which a computer imitating human re- sponses by engaging each in a wide-ranging conversation of any topic and tenor. -

I V Anthropomorphic Attachments in U.S. Literature, Robotics, And
Anthropomorphic Attachments in U.S. Literature, Robotics, and Artificial Intelligence by Jennifer S. Rhee Program in Literature Duke University Date:_______________________ Approved: ___________________________ Kenneth Surin, Supervisor ___________________________ Mark Hansen ___________________________ Michael Hardt ___________________________ Katherine Hayles ___________________________ Timothy Lenoir Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Literature in the Graduate School of Duke University 2010 i v ABSTRACT Anthropomorphic Attachments in U.S. Literature, Robotics, and Artificial Intelligence by Jennifer S. Rhee Program in Literature Duke University Date:_______________________ Approved: ___________________________ Kenneth Surin, Supervisor ___________________________ Mark Hansen ___________________________ Michael Hardt ___________________________ Katherine Hayles ___________________________ Timothy Lenoir An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Literature in the Graduate School of Duke University 2010 Copyright by Jennifer S. Rhee 2010 Abstract “Anthropomorphic Attachments” undertakes an examination of the human as a highly nebulous, fluid, multiple, and often contradictory concept, one that cannot be approached directly or in isolation, but only in its constitutive relationality with the world. Rather than trying to find a way outside of the dualism between human and not- human, -

Philosophy of Artificial Intelligence: a Course Outline
Teaching Philosophy 9:2, June 1986 103 Philosophy of Artificial Intelligence: A Course Outline WILLIAM J. RAPAPORT State University ofNew York, Buffalo In the Fall of 1983, I offered a junior/senior-level course in Philosophy of Artificial Intelligence, in the Department of Philosophy at SUNY· Fredonia, after retuming there from a year's leave to study and do research in computer science and artificial intelligence (AI) at SUNY Buffalo. Of the 30 students enrolled, most were computer-science majors, about a third had no <;omputer background, and only a handful had studied any philosophy. (I might note that enrollments have subsequently increased in the Philosophy Department's AI-related courses, such as logic, philosophy of mind, and epistemology, and that several computer science students have added philosophy as a second major.) This article describes that course, provides material for use in such a course, and offers a bibliography of relevant articles in the AI, cognitive science, and philosophical literature. Course Organization and Texts My original intention, inspired in part by Moulton and Voytek 1980, was to spend the first half of the semester discussing working AI programs, in order to get the students excited about what computers could do, using the first edition of Patrick Henry Winston's Artificial Intelligence (Winston 1977) as the text. During the second half of the semester, my plan was to discuss Hubert L. Dreyfus's What Computers Can't Do (Dreyfus 1979), as a sort of antidote and source of philosophical reflection. While I still think that this might have been a good course, I chose instead to use lohn Haugeland's anthology, Mind Design (Haugeland 1981), for the philosophical half of the course, since it offers a wider-and fairer-spectrum ofphilosophical essays, besides including the most important section ofDreyfus's book. -

Oliver Knill: March 2000 Literature: Peter Norvig, Paradigns of Artificial Intelligence Programming Daniel Juravsky and James Martin, Speech and Language Processing
ENTRY ARTIFICIAL INTELLIGENCE [ENTRY ARTIFICIAL INTELLIGENCE] Authors: Oliver Knill: March 2000 Literature: Peter Norvig, Paradigns of Artificial Intelligence Programming Daniel Juravsky and James Martin, Speech and Language Processing Adaptive Simulated Annealing [Adaptive Simulated Annealing] A language interface to a neural net simulator. artificial intelligence [artificial intelligence] (AI) is a field of computer science concerned with the concepts and methods of symbolic knowledge representation. AI attempts to model aspects of human thought on computers. Aspectrs of AI: computer vision • language processing • pattern recognition • expert systems • problem solving • roboting • optical character recognition • artificial life • grammars • game theory • Babelfish [Babelfish] Online translation system from Systran. Chomsky [Chomsky] Noam Chomsky is a pioneer in formal language theory. He is MIT Professor of Linguistics, Linguistic Theory, Syntax, Semantics and Philosophy of Language. Eliza [Eliza] One of the first programs to feature English output as well as input. It was developed by Joseph Weizenbaum at MIT. The paper appears in the January 1966 issue of the "Communications of the Association of Computing Machinery". Google [Google] A search engine emerging at the end of the 20'th century. It has AI features, allows not only to answer questions by pointing to relevant webpages but can also do simple tasks like doing arithmetic computations, convert units, read the news or find pictures with some content. GPS [GPS] General Problem Solver. A program developed in 1957 by Alan Newell and Herbert Simon. The aim was to write a single computer program which could solve any problem. One reason why GPS was destined to fail is now at the core of computer science. -

The Points of Viewing Theory for Engaged Learning with Digital Media
The Points of Viewing Theory for Engaged Learning with Digital Media Ricki Goldman New York University John Black Columbia University John W. Maxwell Simon Fraser University Jan J. L. Plass New York University Mark J. Keitges University of Illinois, Urbana Champaign - 1 - Introduction Theories are dangerous things. All the same we must risk making one this afternoon since we are going to discuss modern tendencies. Directly we speak of tendencies or movements we commit to, the belief that there is some force, influence, outer pressure that is strong enough to stamp itself upon a whole group of different writers so that all their writing has a certain common likeness. — Virginia Woolff, The Leaning Tower, lecture delivered to the Workers' Educational Association, Brighton (May 1940). With full acknowledgement of the warning from the 1940 lecture by Virginia Woolf, this chapter begins by presenting a theory of mind, knowing only too well, that “a whole group of different” learning theorists cannot find adequate coverage under one umbrella. Nor should they. However, there is a movement occurring, a form of social activism created by the affordances of social media, an infrastructure that was built incrementally during two to three decades of hard scholarly research that brought us to this historic time and place. To honor the convergence of theories and technologies, this paper proposes the Points of Viewing Theory to provide researchers, teachers, and the public with an opportunity to discuss and perhaps change the epistemology of education from its formal structures to more do-it-yourself learning environments that dig deeper and better into content knowledge. -

Much Has Been Written About the Turing Test in the Last Few Years, Some of It
1 Much has been written about the Turing Test in the last few years, some of it preposterously off the mark. People typically mis-imagine the test by orders of magnitude. This essay is an antidote, a prosthesis for the imagination, showing how huge the task posed by the Turing Test is, and hence how unlikely it is that any computer will ever pass it. It does not go far enough in the imagination-enhancement department, however, and I have updated the essay with a new postscript. Can Machines Think?1 Can machines think? This has been a conundrum for philosophers for years, but in their fascination with the pure conceptual issues they have for the most part overlooked the real social importance of the answer. It is of more than academic importance that we learn to think clearly about the actual cognitive powers of computers, for they are now being introduced into a variety of sensitive social roles, where their powers will be put to the ultimate test: In a wide variety of areas, we are on the verge of making ourselves dependent upon their cognitive powers. The cost of overestimating them could be enormous. One of the principal inventors of the computer was the great 1 Originally appeared in Shafto, M., ed., How We Know (San Francisco: Harper & Row, 1985). 2 British mathematician Alan Turing. It was he who first figured out, in highly abstract terms, how to design a programmable computing device--what we not call a universal Turing machine. All programmable computers in use today are in essence Turing machines. -

Passing the Turing Test Does Not Mean the End of Humanity
Cogn Comput (2016) 8:409–419 DOI 10.1007/s12559-015-9372-6 Passing the Turing Test Does Not Mean the End of Humanity 1 1 Kevin Warwick • Huma Shah Received: 18 September 2015 / Accepted: 20 November 2015 / Published online: 28 December 2015 Ó The Author(s) 2015. This article is published with open access at Springerlink.com Abstract In this paper we look at the phenomenon that is we do wish to dispel, however, is the assumption which the Turing test. We consider how Turing originally intro- links passing the Turing test with the achievement for duced his imitation game and discuss what this means in a machines of human-like or human-level intelligence. practical scenario. Due to its popular appeal we also look Unfortunately the assumed chain of events which means into different representations of the test as indicated by that passing the Turing test sounds the death knell for numerous reviewers. The main emphasis here, however, is humanity appears to have become engrained in the thinking to consider what it actually means for a machine to pass the in certain quarters. One interesting corollary of this is that Turing test and what importance this has, if any. In par- when it was announced in 2014 that the Turing test had ticular does it mean that, as Turing put it, a machine can been finally passed [39] there was an understandable ‘‘think’’. Specifically we consider claims that passing the response from those same quarters that it was not possible Turing test means that machines will have achieved for such an event to have occurred, presumably because we human-like intelligence and as a consequence the singu- were still here in sterling health to both make and debate larity will be upon us in the blink of an eye. -

Summer, 1974 Number 4
newstetten Iouusiana psyctuatic \ssociatuon A district branch of the American Psychiatric Association Robert L. Newman, Jr., M.D., Editor DISTRICT BRANCH Mary Coyle, Assistant Editor Volume 12 Summer, 1974 Number 4 CHAPTER OFFICERS ELECTED New officers have been elected by the four LPA chapters to serve during 197 4-7 5. George Bishop is President of the Baton Rouge Psychiatric Society, with Ray Manson as Vice President and Eugene James Hill as Secretary-Treasurer. Serving a second term as President of the New Orleans Area Psychiatric Association is Al Koy, and President-Elect is Al Olinde. Charles Steck is Secretary, Lindsay Graham is Treasurer, and the two Councillors are Ernie Svenson and Walter Prickett, President of the North Louisiana Chapter is Fred Marceau, with John Richie as President-Elect and Edward Leatherman as Secretary. Sidney Dupuy will head the Acadiana Psychiatric Association. The names of other officers had not been received when the NEWSLETTER went to press. Robert G. Heath, M.D. William M. Easson, M.D. HEATH RECEIVES LPA FALL MEETING LSU SEATS NEW CHAIRMAN FROMM-REICHMANN AWARD Dick Brunstetter and Remi Gonzalez Dr. William M. Easson assumed his are making plans now for the LPA Fall duties June 3, 1974 as Professor and Dr. Robert G. Heath, Professor and Meeting, tentatively scheduled for Sep- Chairman of the Department of Psychia- Chairman of the Department of Psychia- tember 13-14 in New Orleans. try and Biobehavioral Sciences, LSU try and Neurology at the Tulane School During the weekend a "Town Hall" School of Medicine in New Orleans. He of Medicine, has received the Frieda meeting will be held in which members comes to Louisiana from Minneapolis Fromm-Reichmann Award of the Ameri- are invited to express their ideas, corn- where he served as Professor and Direc- can Academy of Psychoanalysis. -
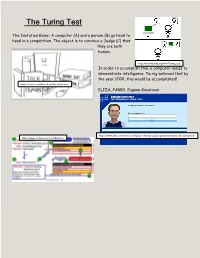
The Turing Test
The Turing Test The Imitation Game: A computer (A) and a person (B) go head to head in a competition. The object is to convince a Judge (C) that they are both human. https://en.wikipedia.org/wiki/Turing_test In order to accomplish this, a computer needs to demonstrate intelligence. Turing believed that by the year 2000, this would be accomplished! https://classic.csunplugged.org/the-turing-test/ ELIZA, PARRY, Eugene Goostman https://www.zdnet.com/article/computer-chatbot-eugene-goostman-passes-the-turing-test/ https://www.codeproject.com/Articles/ 12454/Developing-AI-chatbots But what about Deep Blue & Watson…? Both programs were created by IBM. Deep Blue was able to defeat an international chess champion, while Watson defeated two Jeopardy champions at the same time. https://en.wikipedia.org/wiki/Watson_(computer) Bibliography Artificial Intelligence: The Turing Test. Accessed March 17, 2018. http://www.psych.utoronto.ca/users/reingold/courses/ai/turing.html. Bansa, Shubhan, “Turing Test in Artificial Intelligence." GeeksforGeeks. February 07, 2018. Accessed March 14, 2018. https://www.geeksforgeeks.org/turing-test-artificial- intelligence/. Bell, Steven. "Promise and Peril of AI for Academic Librarians | From the Bell Tower." Library Journal. April 14, 2016. Accessed March 15, 2018. https://lj.libraryjournal.com/2016/04/opinion/steven-bell/promise-and-peril-of-ai-for- academic-librarians-from-the-bell-tower/#_. "Computer AI Passes Turing Test in 'world First'." BBC News. June 09, 2014. Accessed March 17, 2018. http://www.bbc.com/news/technology-27762088. "Eliza, the Computer Therapist." Eliza, Computer Therapist. Accessed March 17, 2018. https://www.cyberpsych.org/eliza/. -

An Overview of Artificial Intelligence and Robotics
AN OVERVIEW OF ARTIFICIAL INTELLIGENCE AND ROBOTICS VOLUME1—ARTIFICIAL INTELLIGENCE PART A—THE CORE INGREDIENTS January 1984 Prepared for National Aeronautics and Space Administration Headquarters Washington, D.C. 20546 NATIONAL E'j • OF STA. IDALL L LIBRARY qc ~iy?f NBSIR 83-2687 AN OVERVIEW OF ARTIFICIAL INTELLIGENCE AND ROBOTICS VOLUME1 —ARTIFICIAL INTELLIGENCE PART A—THE CORE INGREDIENTS William B. Gevarter* U.S. DEPARTMENT OF COMMERCE National Bureau of Standards National Engineering Laboratory Center for Manufacturing Engineering Industrial Systems Division Metrology Building, Room A127 Washington, DC 20234 January 1984 Prepared for: National Aeronautics and Space Administration Headquarters Washington, DC 20546 U.S. DEPARTMENT OF COMMERCE, Malcolm Baldrige, Secretary NATIONAL BUREAU OF STANDARDS. Ernest Ambler, Director •Research Associate at the National Bureau of Standards Sponsored by NASA Headquarters PREFACE Artificial Intelligence (AI) is a field with over a quarter of a century of history. However, it wasn’t until the dawn of the decade of the 80’s that AI really burst forth—finding economic and popular acclaim. Intelligent computer programs are now emerging from the laboratory into prac- tical applications. This report endeavors to indicate what AI is, the foundations on which it rests, the techniques utilized, the applications, the participants and finally its state-of-the-art and future trends. Due to the scope of AI, this volume is issued in three parts: Part A: The Core Ingredients I. Artificial Intelligence—What It Is II. The Rise, Fall and Rebirth of AI III. Basic Elements of AI IV. Applications V. The Principal Participants VI. State-of-the-Art VII.