TCP Behavior Over HFC Cable Modem Access Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Magnificent Seven: American Telephony's Deregulatory Shootout, 50 Hastings L.J
Hastings Law Journal Volume 50 | Issue 6 Article 5 1-1999 The aM gnificent Seven: American Telephony's Deregulatory Shootout Jim Chen Follow this and additional works at: https://repository.uchastings.edu/hastings_law_journal Part of the Law Commons Recommended Citation Jim Chen, The Magnificent Seven: American Telephony's Deregulatory Shootout, 50 Hastings L.J. 1503 (1999). Available at: https://repository.uchastings.edu/hastings_law_journal/vol50/iss6/5 This Article is brought to you for free and open access by the Law Journals at UC Hastings Scholarship Repository. It has been accepted for inclusion in Hastings Law Journal by an authorized editor of UC Hastings Scholarship Repository. The Magnificent Seven: American Telephony's Deregulatory Shootout by JIM CHEN* Table of Contents I. High N oon .................................................................................. 1504 II. The Gunslingers, Then and Now ...................... 1506 A. The Opening Round ........................................................... 1507 B. The Magnificent Seven ...................................................... 1511 (1) POTS and PANS, Hedgehogs and Foxes ................... 1511 (2) Lord Low Everything Else ................. 1513 III. The Legal Mothers of Merger Mania ...................................... 1514 A. Statutory Starters .............. ............ 1515 (1) Section 251 and Allied Provisions ............................... 1516 (2) Section 271: BOC Entry into InterLATA Carriage .1519 * Professor of Law and Vance K. Opperman Research -

Commonwealth of Massachusetts Department of Telecommunications and Energy Cable Television Division
COMMONWEALTH OF MASSACHUSETTS DEPARTMENT OF TELECOMMUNICATIONS AND ENERGY CABLE TELEVISION DIVISION MediaOne of Massachusetts, Inc., MediaOne Group, Inc., and AT&T Corp., Appellants, v. CTV 99-2 Board of Selectmen of the Town of North Andover, Appellee. OPPOSITION OF TOWN OF NORTH ANDOVER TO MOTION FOR EXPEDITED PROCESSING OF APPEAL The Town of North Andover ("North Andover") opposes the motion of MediaOne of Massachusetts, Inc, MediaOne Group, Inc., and AT&T Corp. (collectively, “Appellants”) to expedite the hearing or processing of this matter. For the reasons set forth below, the Massachusetts Department of Telecommunication and Energy, Cable Television Division (the "Division"), should deny the Appellants’ motion to expedite this proceeding and should schedule this matter for a full evidentiary hearing, giving appropriate consideration to the complex legal and factual matters at issue in the case. I. Introduction North Andover has moved that the Division consolidate any and all hearings with respect to the review of decisions by North Andover (CTV 99-2), Cambridge (CTV 99-4), Quincy (CTV 99-3) and Somerville (CTV 99-5) to deny or to conditionally approve the transfer of cable licenses from MediaOne Group, Inc. ("MediaOne") to AT&T Corp. ("AT&T") pursuant to M.G.L. c. 166A §7 and applicable regulations. Each of the decisions has as a common requirement that AT&T provide open or nondiscriminatory access to cable broadband for Internet and on-line services. The open access requirement, which preserves consumer choice and preserves competition among Internet and on-line service providers, should be reviewed by the Division in a consolidated evidentiary hearing that will allow for a complete and efficient presentation of this critical public policy question. -

US V. AT&T Corp. and Mediaone Group, Inc
IN THE UNITED STATES DISTRICT COURT FOR THE DISTRICT OF COLUMBIA ) United States of America ) Antitrust Division ) Department ofJustice ) 1:oocvo111G CASE NUMBER 140 I H Street ) c. Lamberth Washington, D.C. 20530, ) JUDGE: Royce Plaintiff, ) Antitrust ) DECK TYPE: v. ) os12s12000 DATE STAMP: ) AT&T Corp. and ) MediaOne Group, Inc., ) Defendants. ) COMPLAINT The United States of America, acting under the direction ofthe Attorney General ofthe United States, brings this civil action pursuant to Section 15 of the Clayton Act, as amended, 15 U.S.C. § 25, to enjoin defendant AT&T Corp. ("AT&T") from acquiring defendant MediaOne Group, Inc. ("MediaOne"), in order to prevent and restrain a violation of Section 7 of the Clayton Act, as amended, 15 U.S.C. § 18. Unless blocked, AT&T's acquisition of MediaOne's interest is likely to lessen competition substantially in the market for the aggregation, promotion, and distribution of broadband content. Road Runner is an Internet service provider that offers high-speed access to content through cable lines nationwide. Broadband service is technology that allows users to -1 used telephone dial-up services. Road Runner competes with Excite@Home, in which AT&T " - owns a substantial equity interest and voting control, in aggregating, promoting and distributing broadband content. MediaOne holds a significant equity and management interest in Road Runner. Excite@Home and Road Runner serve a significant majority of the nation's residential broadband Internet users. Through the proposed merger, concentration in the market for aggregation, promotion, and distribution of residential broadband content would be substantially increased. Competition between Excite@Home and Road Runner in the provision of these services may be substantially lessened or even eliminated. -

CPUC Data Request FCC Form 477
FIGURE G1: LIST OF CARRIERS SAMPLED VIA CPUC DATA REQUEST CPUC Data Request FCC Form 477 ILECs Included ILECs Included Citizens Telecommunications Company of Citizens Telecommunications Company California, Inc. of California Pacific Bell Pacific Bell Roseville Telephone Company Roseville Telephone Company Verizon California, Inc.(formerly GTE Verizon California, Inc.(formerly GTE California) California) Evans Telephone Company Kerman Telephone Co. Pinnacles Telephone Company Sierra Telephone Company Volcano Telephone Company CLECs/ IXCs Included CLECs Included AT&T Communications of California, Inc. AT&T Corp. Cox California Telecom, LLC Cox Communications Pac-West Telecommunications, Inc. ---------- Sprint Communications Company, L.P. Sprint Corporation Worldcom, Inc. MCI WorldCom, Inc./ WorldCom Inc. Adelphia Communications Corporation Advanced TelCom, Inc. Allegiance Telecom of California, Inc. AOL Time Warner/ Time Warner Cable/ Time Warner Communications Broadwing Communications Inc. Charter Communications Comcast Corporation/ Comcast Cable Communications, Inc. Focal Communications Corporation of California GST Telecom, Inc. ICG Telecom Group, Inc. Intermedia Communications Inc. Mediacom California LLC MediaOne Group, Inc. MGC Communications/ Mpower Communications Nextlink California, Inc./ XO California, Inc. Pacific Bell Company/ Pacific Bell Services [CLEC] RCN Telecom Services of CA, Inc. Seren Innovations Siskiyou Cablevision, Inc. Teligent Services, Inc. Qwest Interprise America, Inc. U.S. Telepacific Corp dba Telepacific Communications -

The Comcast Nbcuniversal Post-Retirement Health Care & Retiree Reimbursement Account Program Summary Plan Description
Comcast NBCUniversal Retiree Health Care Program The Comcast NBCUniversal Post-Retirement Health Care & Retiree Reimbursement Account Program Summary Plan Description Updated 2018 The Comcast NBCUniversal Post-Retirement Health Care & Retiree Reimbursement Account Summary Plan Description (SPD) is intended to be read in conjunction with the separate SPDs for the UHC Standard and Minimum Indemnity Plans and CVS/Caremark Prescription Drug Plan and Retiree IBC PPO Plan. Together, they form a complete SPD as required by the Employment Retirement Security Act of 1974, as amended, describing the Comcast NBCUniversal Post-Retirement Health Care and Retiree Reimbursement Account Program for retirees and eligible dependents. Comcast NBCUniversal Summary Plan Description 2018 Comcast NBCUniversal Retiree Health Care Program THE RETIREE HEALTH CARE PROGRAM The Comcast NBCUniversal Post-Retirement Health Care & Retiree Reimbursement Account Program coverage available to you depends on your age, when you were hired, your employment history with the Company, and whether you completed any actions that may have been or will be required of you to maintain your Retirement Reimbursement Account. Please be aware that the Comcast NBCUniversal Retiree Health Care Program Retiree Reimbursement Account is closed to new hires and re-hires hired on or after January 1, 2017. Employees who were rehired on or after January 1, 2017 due to inter-company transfers (e.g., Comcast to NBCUniversal or vice versa) and whose rehires occurred immediately after their terminations may still be eligible for the Retiree Reimbursement Account. If you retire from Comcast and your retirement date is after 2003, retire from NBCUniversal, are a former MediaOne retiree, or you retired from AT&T Broadband, refer to this Summary Plan Description for details about your retiree health care plan coverage. -

Cable Competition and the At&T-Comcast Merger
S. HRG. 107–893 DOMINANCE ON THE GROUND: CABLE COMPETITION AND THE AT&T-COMCAST MERGER HEARING BEFORE THE SUBCOMMITTEE ON ANTITRUST, BUSINESS RIGHTS, AND COMPETITION OF THE COMMITTEE ON THE JUDICIARY UNITED STATES SENATE ONE HUNDRED SEVENTH CONGRESS SECOND SESSION APRIL 23, 2002 Serial No. J–107–75 Printed for the use of the Committee on the Judiciary ( U.S. GOVERNMENT PRINTING OFFICE 85–889 PDF WASHINGTON : 2003 For sale by the Superintendent of Documents, U.S. Government Printing Office Internet: bookstore.gpo.gov Phone: toll free (866) 512–1800; DC area (202) 512–1800 Fax: (202) 512–2250 Mail: Stop SSOP, Washington, DC 20402–0001 VerDate Mar 21 2002 13:51 Apr 10, 2003 Jkt 085986 PO 00000 Frm 00001 Fmt 5011 Sfmt 5011 C:\HEARINGS\85889.TXT SJUD4 PsN: CMORC COMMITTEE ON THE JUDICIARY PATRICK J. LEAHY, Vermont, Chairman EDWARD M. KENNEDY, Massachusetts ORRIN G. HATCH, Utah JOSEPH R. BIDEN, JR., Delaware STROM THURMOND, South Carolina HERBERT KOHL, Wisconsin CHARLES E. GRASSLEY, Iowa DIANNE FEINSTEIN, California ARLEN SPECTER, Pennsylvania RUSSELL D. FEINGOLD, Wisconsin JON KYL, Arizona CHARLES E. SCHUMER, New York MIKE DEWINE, Ohio RICHARD J. DURBIN, Illinois JEFF SESSIONS, Alabama MARIA CANTWELL, Washington SAM BROWNBACK, Kansas JOHN EDWARDS, North Carolina MITCH MCCONNELL, Kentucky BRUCE A. COHEN, Majority Chief Counsel and Staff Director SHARON PROST, Minority Chief Counsel MAKAN DELRAHIM, Minority Staff Director SUBCOMMITTEE ON ANTITRUST, BUSINESS RIGHTS, AND COMPETITION HERBERT KOHL, Wisconsin, Chairman PATRICK J. LEAHY, Vermont MIKE DEWINE, Ohio RUSSELL D. FEINGOLD, Wisconsin ORRIN G. HATCH, Utah CHARLES E. SCHUMER, New York ARLEN SPECTER, Pennsylvania MARIA CANTWELL, Washington STROM THURMOND, South Carolina SAM BROWNBACK, Kansas VICTORIA BASSETTI, Majority Chief Counsel PETER LEVITAS, Minority Chief Counsel (II) VerDate Mar 21 2002 13:51 Apr 10, 2003 Jkt 085986 PO 00000 Frm 00002 Fmt 5904 Sfmt 5904 C:\HEARINGS\85889.TXT SJUD4 PsN: CMORC C O N T E N T S STATEMENTS OF COMMITTEE MEMBERS Page Brownback, Hon. -

Teresa Elder Joins Wideopenwest As CEO
12/14/2017 WideOpenWest, Inc. - Teresa Elder Joins WideOpenWest As CEO Teresa Elder Joins WideOpenWest As CEO December 14, 2017 Company Closes Sale of Chicago Fiber Network to Verizon Board Announces Stock Repurchase Program ENGLEWOOD, Colo.--(BUSINESS WIRE)-- WideOpenWest, Inc.(“WOW!” or the “Company”) (NYSE: WOW), a leading, fully integrated provider of residential and commercial high-speed data, video and telephony services to customers in the United States, today announced that Teresa Elder has joined the Company as Chief Executive Officer and a member of the Board of Directors of WOW!. Ms. Elder succeeds Steven Cochran, who is retiring from WOW! after 15 years with the Company. Mr. Cochran will stay on in an advisory role with WOW! through June 30, 2018, ensuring a seamless transition of leadership. Ms. Elder brings to WOW! more than 20 years of executive leadership at some of the leading telecommunications and cable companies in the world. She served as a founding President of Clearwire Wholesale (sold to Sprint), and prior to that as CEO of Vodafone Ireland and President of AT&T Broadband West (now Comcast). Ms. Elder currently serves on a number of boards and is Chair of the Management Board of the Stanford University Graduate School of Business. Jeff Marcus, chairman of the board of WOW!, said, “We are delighted that Teresa Elder has joined WOW! as CEO. She is a highly experienced executive with a demonstrated track record of operational success within the tech, telecom and cable industries. Her passion for building businesses and her knack for innovation, make Teresa the ideal executive to lead our company forward.” Mr. -

Federal Communications Commission DA 03-1161 Before the Federal Communications Commission Washington, D.C. 20554 in the Matter
Federal Communications Commission DA 03-1161 Before the Federal Communications Commission Washington, D.C. 20554 In the Matter of: ) ) Costa de Oro Television, Inc. ) ) v. ) ) Cox Communications, Inc. ) CSR 6050-M ) and ) ) Comcast Corporation ) CSR 6073-M ) Request for Mandatory Carriage ) of Television Station KJLA-TV, Ventura, ) California ) MEMORANDUM OPINION AND ORDER Adopted: April 15, 2003 Released: April 16, 2003 By the Deputy Chief, Policy Division, Media Bureau: I. INTRODUCTION 1. Costa de Oro Television, Inc. (“Costa”), licensee of television broadcast station KJLA- TV (Ind. Ch. 57), Ventura, California (“KJLA”), has filed must carry complaints with the Commission pursuant to Sections 76.7 and 76.61(a)(3) of the Commission’s rules, claiming that Cox Communications (“Cox”)1 and Comcast Corporation [formerly MediaOne] (“Comcast”)2 have failed to commence carriage 1 Cox’s Los Angeles cable system serves the following communities: (1) Rolling Hills; (2) Rancho Palos Verdes; (3) Palos Verdes Estates; (4) Los Angeles (portions thereof); (4) Rolling Hills Estates; (5) San Pedro Naval; and (6) Fort Macarthur AFB. Cox’s Orange County cable system serves the following communities: (1) Aegean Hills; (2) South Laguna; (3) Irvine; (3) Newport Beach; (4) San Clemente; (5) Tustin; (6) Laguna Beach; (7) Laguna Niguel; (8) San Juan Capistrano; (9) Dana Point; (10) Capistrano Beach; (11) Silverado Canyon; (12) Trabujo Canyon; (13) Modjeska Canyon; (14) Coto De Caza; (15) Lake Forest; (16) Emerald Bay; (17) Laguna Hills; (18) Rancho Santa Magarita; (19) Portola Hills; (20) Orange; (21) Foothill Ranch; (22) Mission Viejo; (23) El Toro; (24) Newport Coast; and (25) Aliso Viejo. -

Commonwealth of Massachusetts Department of Telecommunications and Energy Cable Television Division
COMMONWEALTH OF MASSACHUSETTS DEPARTMENT OF TELECOMMUNICATIONS AND ENERGY CABLE TELEVISION DIVISION ) MediaOne of Massachusetts, Inc., ) MediaOne Group, Inc. and AT&T Corp. ) ) Appellants, ) Docket Numbers: v. ) CTV 99-2 ) CTV 99-3 Board of Selectmen of the Town of North ) CTV 99-4 Andover, Mayor of the City of Quincy, ) CTV 99-5 Mayor of the City of Cambrige, and Mayor ) of the City of Somerville, ) ) Appellees. ) ) MEMORANDUM IN SUPPORT OF MOTION TO CONSOLIDATE HEARINGS The cities of Cambridge, Somerville and Quincy and the Town of North Andover (collectively, the "Issuing Authorities") submit this Memorandum in support of the Issuing Authorities' joint motion to consolidate the above captioned appeals in a single proceeding.1 The Issuing Authorities have moved that the Massachusetts Department of Telecommunication and Energy, Cable Television Division (the "Division") consolidate any and all hearings with respect to the review of the Issuing Authorities' decisions to deny or to conditionally approve the transfer of cable licenses from MediaOne Group, Inc. ("MediaOne") to AT&T Corp. ("AT&T") pursuant to M.G.L. c. 166A §7 and applicable regulations. Each of the decisions has as a common requirement that AT&T provide open or nondiscriminatory access to cable broadband for Internet services. The Division should 1 The Issuing Authorities' filed their Motion for a consolidated on or about December 7, 1999. This Memorandum supplements that submission. All of the Issuing Authorities join in the Motion to Consolidate. review evidence of the disputed issues of fact and law regarding the open access requirement, which preserves consumer choice and preserves competition among Internet service providers, in a consolidated hearing that will facilitate a complete and efficient presentation of this critical public policy question. -

Federal Communications Commission FCC 00-202 Before the Federal
Federal Communications Commission FCC 00-202 Before the Federal Communications Commission Washington, D.C. 20554 In the Matter of ) ) Applications for Consent to the ) Transfer of Control of Licenses and ) CS Docket No.99-251 Section 214 Authorizations from ) ) MediaOne Group, Inc., ) Transferor, ) ) To ) ) AT&T Corp. ) Transferee ) ) MEMORANDUM OPINION AND ORDER Adopted: June 5, 2000 Released: June 6, 2000 By the Commission: Chairman Kennard issuing a statement; Commissioner Furchtgott-Roth concurring in part, dissenting in part and issuing a statement; Commissioner Powell concurring and issuing a statement; and Commissioner Tristani concurring and issuing a statement. Table of Contents Paragraph I. INTRODUCTION…………………………………………………………………………………1 II. PUBLIC INTEREST FRAMEWORK.........................................................................................8 III. BACKGROUND.......................................................................................................................14 A. The Applicants..............................................................................................................14 B. The Merger Transaction and the Application to Transfer Licenses .................................30 IV. ANALYSIS OF POTENTIAL PUBLIC INTEREST HARMS ..................................................35 A. Video Programming ......................................................................................................36 1. Diversity and Competition in Video Program Purchasing...................................39 -
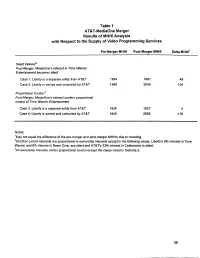
Table 1 AT&T-Mediaone Merger Results of MHHI Analysis With
Table 1 AT&T-MediaOne Merger Results of MHHI Analysis with Respect to the Supply of Video Programming Services Pre-Merger MHHI Post-Merger MHHI Delta MHHI1 Silent Interest2 Post-Merger, MediaOne's interest in Time Warner Entertainment becomes silent Case 1: Liberty is a separate entity from AT&T 1934 1981 48 Case 2: Liberty is owned and controlled by AT&T 1940 2045 104 Proportional Control 3 Post-Merger, MediaOne's interest confers proportional control of Time Warner Entertainment Case 3: Liberty is a separate entity from AT&T 1934 1937 4 Case 4: Liberty is owned and controlled by AT&T 1940 2059 118 Notes: 1May not equal the difference of the pre-merger and post-merger MHHls due to rounding. 2All other control interests are proportional to ownership interests except in the following cases: Liberty's 9% interest in Time Warner and 8% interest in News Corp. are silent and AT&rs 33% interest in Cablevision is silent. 3AII ownership interests confer proportional control except the cases noted in footnote 2. 58 Table 2 AT&T-MediaOne Merger Results of MHHI Analysis 1 with Respect to the Purchase of Video Programming Services Pre-Merger MHHI Post-Merger MHHI Delta MHHI2 Silent Interest3 Post-Merger, MediaOne's interest in Time Warner Entertainment becomes silent Case 1: Liberty is a separate entity from AT&T 1051 1304 254 Case 2: Liberty is owned and controlled by AT&T 1069 1328 258 Proportional Control4 Post-Merger, MediaOne's interest confers proportional control of Time Warner Entertainment Case 3: Liberty is a separate entity from AT&T 1051 1432 381 Case 4: Liberty is owned and controlled by AT&T 1069 1452 383 Notes: 'AT&T sells 735,000 subscribers to Comcast post-merger. -

Federal Communications Commission FCC 08-66 1 Before the Federal
Federal Communications Commission FCC 08-66 Before the Federal Communications Commission Washington, D.C. 20554 In the Matter of ) ) NEWS CORPORATION and ) MB Docket No. 07-18 THE DIRECTV GROUP, INC., Transferors, ) ) and ) ) LIBERTY MEDIA CORPORATION, Transferee, ) ) For Authority to Transfer Control MEMORANDUM OPINION AND ORDER Adopted: February 25, 2008 Released: February 26, 2008 By the Commission: Commissioner Copps concurring and issuing a statement; Commissioner Adelstein approving in part, dissenting in part and issuing a statement. TABLE OF CONTENTS Heading Paragraph # I. INTRODUCTION.................................................................................................................................. 1 II. DESCRIPTION OF THE PARTIES ...................................................................................................... 6 A. The DIRECTV Group, Inc............................................................................................................... 6 B. Liberty Media Corporation .............................................................................................................. 8 C. News Corporation .......................................................................................................................... 13 III. THE PROPOSED TRANSACTION.................................................................................................... 16 A. Description....................................................................................................................................