A Spatial Microsimulation Analysis of Health Inequalities and Health Resilience Phil Mike Jones
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Your Doorstep Local Amenities, Travel Connections and Attractions NESTLED in the HEART of SOUTH YORKSHIRE
All on your doorstep Local amenities, travel connections and attractions NESTLED IN THE HEART OF SOUTH YORKSHIRE Edlington is a delightful town in South Yorkshire, located just 4 miles west of Doncaster. Once an industrial heartland it has transformed itself into a sought after destination for sport, music and culture. Like many of the former local mining towns and villages, Edlington Doncaster o!ers a wide selection of shopping and restaurants and has has now been transformed to meet the needs of 21st century living. recently undergone extensive regeneration. Doncaster Lakeside which Surrounded by woodland and open green spaces, including Edlington is also home to Doncaster Rovers has also undergone modernisation. Woods, (the largest area of deciduous woodland in South Yorkshire), Shopping opportunities abound with The Frenchgate Shopping Centre, Edlington also benefits from its proximity to Doncaster; o!ering some of Wheatley Shopping Centre and Waterdale Shopping Centre. Located the UKs best shopping, family attractions and nightlife; as well as excellent along the A6182 is Lakeside Village, a retail outlet with many high street local and national transport links. names, cafes and restaurants. Edlington consists of two parishes - the original parish town of Edlington, There are also several theatres, a cinema, bowling alley and The Dome known as ‘Old Edlington’ and to the north is ‘New Edlington’. Old Leisure Centre. Night life is vibrant and plentiful in Doncaster with Edlington didn’t grow until Edlington Main Colliery (later Yorkshire Main) a variety of clubs and bars mostly situated on Silver Street. was opened around 1910. Near a crest of a hill in Old Edlington, is St Peter’s As expected, the town also boasts a plethora of restaurants like Clam & Church which dates from the late 12th century. -

Local Environment Agency Plan
EA-NORTH EAST LEAPs local environment agency plan SOUTH YORKSHIRE AND NORTH EAST DERBYSHIRE CONSULTATION REPORT AUGUST 1997 BEVERLEY LEEDS HULL V WAKEFIELD ■ E n v ir o n m e n t A g e n c y Information Services Unit Please return or renew this item by the due date Due Date E n v ir o n m e n t A g e n c y YOUR VIEW S Welcome to the Consultation Report for the South Yorkshire and North East Derbyshire area which is the Agency's view of the state of the environment and the issues that we believe need to be addressed during the next five years. We should like to hear your views: • Have we identified all the major issues? • Have we identified realistic proposals for action? • Do you have any comments to make regarding the plan in general? During the consultation period for this report the Agency would be pleased to receive any comments in writing to: The Environment Planner South Yorkshire and North East Derbyshire LEAP The Environment Agency Olympia House Gelderd Road Leeds LSI 2 6DD All comments must be received by 31st December 1997. All comments received on the Consultation Report will be considered in preparing the next phase, the Action Plan. This Action Plan will focus on updating Section 4 of this Consultation Report by turning the proposals into actions with timescales and costs where appropriate. All written responses will be considered to be in the public domain unless consultees explicitly request otherwise. Note: Whilst every effort has been made to ensure the accuracy of information in this report it may contain some errors or omissions which we shall be pleased to note. -

Ton, Doncaster DN12 1EQ
Broomhouse Lane Industrial Estate, Broomhouse Lane Edlington, Doncaster DN12 1EQ From 1,184 - 6,130 SqFt (109.99 - 662.84 SqM) Brand new industrial/warehouses Established location High quality space Ample shared yards TO LET 4 Sidings Court, Doncaster DN4 5NU RATING The adopted rateable value(s) are to be assessed once the development is completed. VALUE ADDED TAX Unless otherwise stated, all rents and sale prices are quoted exclusive of VAT. Any prospective lessee or purchaser must independently satisfy himself or herself as to the incidence of VAT in respect of any transaction. ACCOMMODATION Unit Size Price per annum 32 1,430 sq ft £10,000 LOCATION 33 1,430 sq ft £10,000 Broomhouse Lane Industrial Estate is located just off 34 2,850 sq ft £20,000 Broomhouse Lane to the east of New Edlington which lies 35 2,315 sq ft £16,000 less than 4 miles to the west of Doncaster town centre. 36 3,065 sq ft £21,500 Motorways are easily accessible via Broomhouse Lane and 37 3,065 sq ft £21,500 Edlington Lane with junction 36 of the A1(M) being less 38 1,345 sq ft £9,500 than 2 miles to the north. 39 1,345 sq ft £9,500 40 4,455 sq ft £31,000 Doncaster is located in South Yorkshire approximately 30 41 1,184 sq ft £8,500 miles southeast of Leeds and 25 miles northeast of 42 1,184 sq ft £8,500 Sheffield. The town has fantastic motorway links with *indicates no longer available junctions 3 and 4 of the M18 providing easy access to the A1(M), M1, M180, and M62 Motorways. -

South Yorkshire
INDUSTRIAL HISTORY of SOUTH RKSHI E Association for Industrial Archaeology CONTENTS 1 INTRODUCTION 6 STEEL 26 10 TEXTILE 2 FARMING, FOOD AND The cementation process 26 Wool 53 DRINK, WOODLANDS Crucible steel 27 Cotton 54 Land drainage 4 Wire 29 Linen weaving 54 Farm Engine houses 4 The 19thC steel revolution 31 Artificial fibres 55 Corn milling 5 Alloy steels 32 Clothing 55 Water Corn Mills 5 Forging and rolling 33 11 OTHER MANUFACTUR- Windmills 6 Magnets 34 ING INDUSTRIES Steam corn mills 6 Don Valley & Sheffield maps 35 Chemicals 56 Other foods 6 South Yorkshire map 36-7 Upholstery 57 Maltings 7 7 ENGINEERING AND Tanning 57 Breweries 7 VEHICLES 38 Paper 57 Snuff 8 Engineering 38 Printing 58 Woodlands and timber 8 Ships and boats 40 12 GAS, ELECTRICITY, 3 COAL 9 Railway vehicles 40 SEWERAGE Coal settlements 14 Road vehicles 41 Gas 59 4 OTHER MINERALS AND 8 CUTLERY AND Electricity 59 MINERAL PRODUCTS 15 SILVERWARE 42 Water 60 Lime 15 Cutlery 42 Sewerage 61 Ruddle 16 Hand forges 42 13 TRANSPORT Bricks 16 Water power 43 Roads 62 Fireclay 16 Workshops 44 Canals 64 Pottery 17 Silverware 45 Tramroads 65 Glass 17 Other products 48 Railways 66 5 IRON 19 Handles and scales 48 Town Trams 68 Iron mining 19 9 EDGE TOOLS Other road transport 68 Foundries 22 Agricultural tools 49 14 MUSEUMS 69 Wrought iron and water power 23 Other Edge Tools and Files 50 Index 70 Further reading 71 USING THIS BOOK South Yorkshire has a long history of industry including water power, iron, steel, engineering, coal, textiles, and glass. -
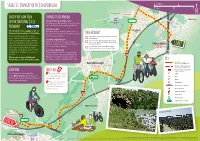
Doncaster to Conisbrough (PDF)
Kilometres 0 Miles 0.5 1 1.5 0 Kilometres 1 Stage 17: Doncaster to Conisbrough A638 0 Miles 0.5 1 Cusworth To Selby River Don Enjoy the Slow Tour Things to see and do Wheatley Cusworth Hall and Museum A Cusworth 19 on the National Cycle An imposing 18th century country house Hall set in extensive landscaped parklands. 30 Network! A6 Sprotborough A638 Richmond The Slow Tour is a guide to 21 of Sprotborough is a village which sits on Hill the best cycle routes in Yorkshire. the River Don and has locks which allow Take a Break! It’s been inspired by the Tour de boats to pass safely. Doncaster has plenty of cafés, pubs and restaurants. France Grand Départ in Yorkshire in A 1 Conisbrough Viaduct (M Doncaster ) 2014 and funded by Public Health The Boat Inn, Sprotborough does great A630 With its 21 arches the grand viaduct Teams in the region. All routes form food and is where Sir Walter Scott wrote spans the River Don and formed part of his novel Ivanhoe. Doncaster part of the National Cycle Network - start the Dearne Valley Railway. The Red Lion, Conisbrough is a Sam more than 14,000 miles of traffic- Smith pub and serves a range of food. River Don free paths, quiet lanes and on-road Conisbrough Castle A638 walking and cycling routes across This medieval fortification was initially the UK. built in the 11th century by William de Hyde Warenne, the Earl of Surrey, after the Park This route is part of National Hexthorpe A18 0 Norman conquest of England in 1066. -

NHS England Yorkshire & Humber Orthodontic Lots and Locations
NHS England Yorkshire & Humber Orthodontic Lots and Locations Total Number Postcodes Total No. of Locations within Postcodes Lot Name Servicing (including UOA's of UOA's (including but not exclusively) but not exclusively) Lots in Lot North Yorkshire & Humber Craven BD20, BD23, BD24 Crosshills, Settle, Skipton, Craven 6500 1 6500 Grassington Harrogate HG1, HG2, HG3, Harrogate, Knaresborough, Ripon, Harrogate 10318 1 10318 HG4, HG5, YO51, Boroughbridge, Marston Moor YO26 Ward Hambleton and DL6, DL7, DL8, Leeming, Leyburn, Thirsk, Hambleton and 8606 1 8606 Richmondshire DL9, DL10, DL11, Northallerton, Richmond, Richmondshire YO7, YO61 Easingwold Scarborough YO11, YO12, Scarborough, Scalby, Seamer Scarborough and and Ryedale YO13, YO14, Ward, East Ayton, Filey, 9682 1 9682 Ryedale YO17, YO18, Hunmanby, Malton, Pickering, YO62, YO21,YO60 Helmsley, Whitby Selby YO8,LS24, LS25, Selby, Sherburn in Elmet, Selby 6500 1 6500 Tadcaster York YO1, YO10, YO19, Acomb, Bishopthorpe, York 10376 1 10376 YO23, YO24, Dunnington, Haxby, Rawcliffe, YO26, YO30, YO32 East Riding - YO15, YO16,YO25, Bridlington, Flamborough, North East HU18, HU10, Holderness Ward, East Wolds and HU11, HU12, Coastal Ward, Hornsea, Mid East Riding 19699 2 9850 HU13, HU14, Holderness Ward, North HU16, HU17, Holderness Ward, Withernsea, HU18, HU19 Hessle, Beverley, Cottingham East Riding - YO25, YO41, Pocklington, Howdenshire Ward, West YO42, YO43, Goole, Hessle, Beverley, 9850 HU10, HU13, Cottingham, Driffield HU14, HU15, HU16, HU17, DN14 Hull East HU1, HU2, HU7, Branshome, Sutton -

26 Doncaster Main Urban Area 033: Land Adjacent 163 Sheffield Road, Warmsworth
Doncaster Metropolitan Borough Council Doncaster Green Belt Review Stage 3 Proposed Green Belt Sites for Assessment 26 Doncaster Main Urban Area 033: Land adjacent 163 Sheffield Road, Warmsworth Proposed Green Belt 033 Boundary of Proposed Green Belt Site Site Reference Site Name Land adjacent to 163 Sheffield Road, Warmsworth Site Size 4.4 Hectares Location of Site and The site lies adjacent to the settlement of Warmsworth, which forms part of the main Urban Area of Doncaster. relationships with inset settlement General Area containing Conisbrough 5 Site (from Stage 1 Assessment) Summary of General • As Warmsworth forms part of the Main Urban area of Doncaster, the Green Belt in the north east is considered to be contiguous with the 'large urban area of Doncaster'. Therefore, the existing Green Belt designation has a Area Assessment role in preventing sprawl which would only otherwise be prevented by features lacking in durability (Purpose 1, Score 4). • Conisbrough 5 supports a series of land gaps within and neighbouring the General Area. These include land gaps between Conisbrough and Maltby; Conisbrough and New Edlington/ the south of Warmsworth; New Edlington and Maltby; New Edlington and Balby; and New Edlington and Wadworth. Based on the number of land gaps and their role, the General Area was considered to have a mixed role in preventing neighbouring towns from merging (Purpose 2a, Score 4). The existing Green Belt boundary within Conisbrough has had a mixed role in preventing ribbon development (Purpose 2b, Score 3). • Due to the topography, extensive views and countryside character, development in this area would have a negative impact on the physical landform of the General Area. -

Doncaster Metropolitan Borough Council Planning
DONCASTER METROPOLITAN BOROUGH COUNCIL PLANNING COMMITTEE - 28th July 2015 Application 1 Application 14/02665/OUTM Application 9th February 2015 Number: Expiry Date: Application Outline Planning Major Type: Proposal Hybrid Planning Application: Description: Outline application for residential development comprising of up to 375 houses (Class C3) and public house (Class A4) with associated access, landscaping and public open space (Approval sought for Acess) Full application for creation of temporary access and enabling earthworks to create development platform At: Site At Former Yorkshire Main Colliery, Broomhouse Lane, Balby Doncaster For: Harworth Estates - FAO Mr S Ashton Third Party Reps: 2 Parish: Edlington Town Council Ward: Edlington And Warmsworth Author of Report Mark Sewell MAIN RECOMMENDATION: GRANT Subject to s106 1.0 Reason for Report 1.1 The submitted hybrid planning application seeks outline permission for a residential development of up to 375 houses, a public house and associated landscaping and public open space, as well as full permission for the creation of a temporary access and enabling earthworks to create a development platform. 1.2 The application is being presented to the Planning Committee as it represents a departure from the Development Plan. 2.0 Proposal and Background 2.1 The application site is located approximately 1 kilometre to the north east of the centre of New Edlington village and a similar distance to the south of Warmsworth. Together with the adjoining UK Coal land, it forms a roughly triangle in shape, bounded on the north side by the embankment of a disused railway, on the south east by Broomhouse Lane and on the west by Lord's Head Lane. -

Table of Contents
Report No: C434 Date: May 2021 PRELIMINARY INVESTIGATION of land at EDLINGTON COMMUNITY WOODLAND, EDLINGTON, DONCASTER, SOUTH YORKSHIRE Prepared for Edlington Town Council Prepared by G&M Consulting Ltd, The Chestnuts, Brackenhill Road, Haxey, Doncaster DN9 2LR REPORT C434 REPORT FINAL NUMBER: STATUS: REPORT Preliminary TYPE: Investigation REPORT May 2021 DATE: SITE: Land at Edlington Community Woodland, Edlington, Doncaster, South Yorkshire PREPARED Edlington Town FOR: Council PREPARED A Swinbourne BSc. Senior Engineering BY: (Hons), MIEnvSc, Geologist FGS, ACIEH. REVIEWED G Swinbourne Principal Engineering BSc. (Hons) MSc. Geologist BY: DIC, FGS This report is written for the sole use of Edlington Town Council or their representatives. No other third party may rely on or reproduce the contents of this report without the written approval of G&M. If any unauthorised third party comes into possession of this report, they rely upon it entirely at their own risk and the authors do not owe them any of Duty of Care or Skill. Report No C434 – Edlington Community Woodland Page 1 of 15 TABLE OF CONTENTS 1.0 INTRODUCTION. ................................................................................................................................ 2 2.0 SITE DESCRIPTION. .......................................................................................................................... 3 2.1 Site Location. ......................................................................................................................................... -

The Bulletin GP Newsletter
August 2019 The Bulletin GP Newsletter CCG awarded ‘Outstanding’ rating for third consecutive year NHS Doncaster CCG has received its official rating from NHS England for 2018-19 and its great news – we’ve been rated ‘outstanding’ for the third time. Doncaster CCG is now one of just nine CCGs nationally to achieve the top rating three years in a row. An area of significant improvement during 2018-19 is our approach to patient and public engagement, ensuring we communicate and engage with patients and members of the public at the right time, right place using effective methods. Since last year’s assessment, we have moved from Amber ‘requires improvement’ to ‘Green Star’. Only two CCGs in South Yorkshire and Bassetlaw received the top accolade for patient and public engagement; Doncaster and Barnsley. CCG 2018-19 Annual Report now available Our Annual Report for 2018-19 has been published and is available on our website, together with some short film versions. You can find further details here. Doctors ask local residents to use the Emergency Department wisely this summer Senior doctors in Doncaster are asking local people to choose their health services wisely as the summer holidays get under way. The warmer weather can often bring with it many health risks – from cuts and scrapes in the garden, to not drinking enough water whilst out in the sunshine, summer can be one of the busiest times for the Emergency Department (ED). This summer, the local NHS is asking for the people of Doncaster to think before they travel to hospital. -

On July 5 1948, the Brass Band from the Yorkshire Main Colliery Trooped up to the Doctor’S Surgery in Edlington, South Yorkshire and Began to Play
On July 5 1948, the brass band from the Yorkshire Main Colliery trooped up to the doctor’s surgery in Edlington, South Yorkshire and began to play. The doctor hung the union flag out of the window and gave them all a drink. The NHS had arrived. Re-enacting this historic event on Sunday 8 July, 2018 Background to today’s event The NHS was born on 5 July, 1948, when GP surgeries, hospitals, doctors, nurses and a numerous other workers came together to form a giant health organisation funded from taxes and free at the point of need. On that historic day, health minister Aneurin ‘Nye’ Bevan went into what’s now called Trafford Hospital, Manchester to meet patients and announce the launch of the NHS. As he was doing so, 70 miles away in the mining village of Edlington, Doncaster, the village was also heralding the birth of free healthcare for all with its own musical tribute. The brass band from Yorkshire Main Colliery triumphantly marched down the road to the village’s GP surgery – then based in a large detached house opposite the cemetery -and played a number of celebratory tunes. Dr James O’Donnell – affectionately known as Dr Jimmy - hung a Union Jack flag from his window and gave them all a drink – the NHS had arrived. And almost exactly 70 years on, Edlington is today remembering this historic event by re-enacting the parade made by the pit bandsmen. Yorkshire Main closed in 1986 and Dr Jimmy’s surgery is now a private home, see alongside. -

Maps -- by Region Or Country -- Eastern Hemisphere -- Europe
G5702 EUROPE. REGIONS, NATURAL FEATURES, ETC. G5702 Alps see G6035+ .B3 Baltic Sea .B4 Baltic Shield .C3 Carpathian Mountains .C6 Coasts/Continental shelf .G4 Genoa, Gulf of .G7 Great Alföld .P9 Pyrenees .R5 Rhine River .S3 Scheldt River .T5 Tisza River 1971 G5722 WESTERN EUROPE. REGIONS, NATURAL G5722 FEATURES, ETC. .A7 Ardennes .A9 Autoroute E10 .F5 Flanders .G3 Gaul .M3 Meuse River 1972 G5741.S BRITISH ISLES. HISTORY G5741.S .S1 General .S2 To 1066 .S3 Medieval period, 1066-1485 .S33 Norman period, 1066-1154 .S35 Plantagenets, 1154-1399 .S37 15th century .S4 Modern period, 1485- .S45 16th century: Tudors, 1485-1603 .S5 17th century: Stuarts, 1603-1714 .S53 Commonwealth and protectorate, 1660-1688 .S54 18th century .S55 19th century .S6 20th century .S65 World War I .S7 World War II 1973 G5742 BRITISH ISLES. GREAT BRITAIN. REGIONS, G5742 NATURAL FEATURES, ETC. .C6 Continental shelf .I6 Irish Sea .N3 National Cycle Network 1974 G5752 ENGLAND. REGIONS, NATURAL FEATURES, ETC. G5752 .A3 Aire River .A42 Akeman Street .A43 Alde River .A7 Arun River .A75 Ashby Canal .A77 Ashdown Forest .A83 Avon, River [Gloucestershire-Avon] .A85 Avon, River [Leicestershire-Gloucestershire] .A87 Axholme, Isle of .A9 Aylesbury, Vale of .B3 Barnstaple Bay .B35 Basingstoke Canal .B36 Bassenthwaite Lake .B38 Baugh Fell .B385 Beachy Head .B386 Belvoir, Vale of .B387 Bere, Forest of .B39 Berkeley, Vale of .B4 Berkshire Downs .B42 Beult, River .B43 Bignor Hill .B44 Birmingham and Fazeley Canal .B45 Black Country .B48 Black Hill .B49 Blackdown Hills .B493 Blackmoor [Moor] .B495 Blackmoor Vale .B5 Bleaklow Hill .B54 Blenheim Park .B6 Bodmin Moor .B64 Border Forest Park .B66 Bourne Valley .B68 Bowland, Forest of .B7 Breckland .B715 Bredon Hill .B717 Brendon Hills .B72 Bridgewater Canal .B723 Bridgwater Bay .B724 Bridlington Bay .B725 Bristol Channel .B73 Broads, The .B76 Brown Clee Hill .B8 Burnham Beeches .B84 Burntwick Island .C34 Cam, River .C37 Cannock Chase .C38 Canvey Island [Island] 1975 G5752 ENGLAND.