Overview of Datasets for the Sign Languages of Europe
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Survey of Orthographic Information in Machine Translation 3
Machine Translation Journal manuscript No. (will be inserted by the editor) A Survey of Orthographic Information in Machine Translation Bharathi Raja Chakravarthi1 ⋅ Priya Rani 1 ⋅ Mihael Arcan2 ⋅ John P. McCrae 1 the date of receipt and acceptance should be inserted later Abstract Machine translation is one of the applications of natural language process- ing which has been explored in different languages. Recently researchers started pay- ing attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine transla- tion systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthog- raphy’s influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic in- formation can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under- resourced languages. We discuss different types of machine translation and demon- strate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cog- nates information at different levels of machine translation and the lessons that can Bharathi Raja Chakravarthi [email protected] Priya Rani [email protected] Mihael Arcan [email protected] John P. -

Word Representation Or Word Embedding in Persian Texts Siamak Sarmady Erfan Rahmani
1 Word representation or word embedding in Persian texts Siamak Sarmady Erfan Rahmani (Abstract) Text processing is one of the sub-branches of natural language processing. Recently, the use of machine learning and neural networks methods has been given greater consideration. For this reason, the representation of words has become very important. This article is about word representation or converting words into vectors in Persian text. In this research GloVe, CBOW and skip-gram methods are updated to produce embedded vectors for Persian words. In order to train a neural networks, Bijankhan corpus, Hamshahri corpus and UPEC corpus have been compound and used. Finally, we have 342,362 words that obtained vectors in all three models for this words. These vectors have many usage for Persian natural language processing. and a bit set in the word index. One-hot vector method 1. INTRODUCTION misses the similarity between strings that are specified by their characters [3]. The Persian language is a Hindi-European language The second method is distributed vectors. The words where the ordering of the words in the sentence is in the same context (neighboring words) may have subject, object, verb (SOV). According to various similar meanings (For example, lift and elevator both structures in Persian language, there are challenges that seem to be accompanied by locks such as up, down, cannot be found in languages such as English [1]. buildings, floors, and stairs). This idea influences the Morphologically the Persian is one of the hardest representation of words using their context. Suppose that languages for the purposes of processing and each word is represented by a v dimensional vector. -

ELECTRONIC DICTIONARY Press Y to Select Alphabet Character Input Or Press N to Selecting a Menu Item 12 Select Japanese Input
ELECTRONIC DICTIONARY Press Y to select alphabet character input or press N to Selecting a menu item 12 select Japanese input. PW-AC890 The date/time settings screen is displayed. Press メニュー . QUICK REFERENCE 1 13 Select the date items using or , and then enter “年” Use or to select a category menu item. (year), “月” (month) and “日” (day) (e.g. June 23th, 2009 → 2 Or, use the numeric keys to enter the category number to Layout 09 06 23) using the number buttons on the handwriting pad. select the item. Utility keys for Display(Main display) dictionaries / functions Confirm that the cursor is on “AM(午前)” or “PM(午後)”, The individual menu for the selected category menu item is displayed. / touch pad and then select one of them using or . In the individual menu, use or to select the content/ Library key 3 Selection keys Press , select the time items using or and then function and then press 検索/決定 . for contents / functions enter “時” (hour) and “分” (minute) (e.g. 9:00 → 09 00). Or, use the numeric keys ( 1 to 9 ) to enter the number Charge lamp Stylus holder(side) Confirm that the information entered is correct and press in front of the content/function ( 1 to 9 ). Global search keys 14 検索/決定 . The selected content/function screen is displayed. Power ON/OFF key The menu display appears. ● The selected content/function screen can also be selected by touching the relevant item on the category menu or the individual menu. Menu key Function key Selecting a content in the menu display Touch operations AC adapter connector (side) Character size (large/small) The PW-AC890 can be operated by touching the main screen with the stylus. -

Concepticon: a Resource for the Linking of Concept Lists
Concepticon: A Resource for the Linking of Concept Lists Johann-Mattis List1, Michael Cysouw2, Robert Forkel3 1CRLAO/EHESS and AIRE/UPMC, Paris, 2Forschungszentrum Deutscher Sprachatlas, Marburg, 3Max Planck Institute for the Science of Human History, Jena [email protected], [email protected], [email protected] Abstract We present an attempt to link the large amount of different concept lists which are used in the linguistic literature, ranging from Swadesh lists in historical linguistics to naming tests in clinical studies and psycholinguistics. This resource, our Concepticon, links 30 222 concept labels from 160 conceptlists to 2495 concept sets. Each concept set is given a unique identifier, a unique label, and a human-readable definition. Concept sets are further structured by defining different relations between the concepts. The resource can be used for various purposes. Serving as a rich reference for new and existing databases in diachronic and synchronic linguistics, it allows researchers a quick access to studies on semantic change, cross-linguistic polysemies, and semantic associations. Keywords: concepts, concept list, Swadesh list, naming test, word norms, cross-linguistically linked data 1. Introduction in the languages they were working on, or that they turned In 1950, Morris Swadesh (1909 – 1967) proposed the idea out to be not as stable and universal as Swadesh had claimed that certain parts of the lexicon of human languages are uni- (Matisoff, 1978; Alpher and Nash, 1999). Up to today, versal, stable over time, and rather resistant to borrowing. dozens of different concept lists have been compiled for var- As a result, he claimed that this part of the lexicon, which ious purposes. -

Language Resource Management System for Asian Wordnet Collaboration and Its Web Service Application
Language Resource Management System for Asian WordNet Collaboration and Its Web Service Application Virach Sornlertlamvanich1,2, Thatsanee Charoenporn1,2, Hitoshi Isahara3 1Thai Computational Linguistics Laboratory, NICT Asia Research Center, Thailand 2National Electronics and Computer Technology Center, Pathumthani, Thailand 3National Institute of Information and Communications Technology, Japan E-mail: [email protected], [email protected], [email protected] Abstract This paper presents the language resource management system for the development and dissemination of Asian WordNet (AWN) and its web service application. We develop the platform to establish a network for the cross language WordNet development. Each node of the network is designed for maintaining the WordNet for a language. Via the table that maps between each language WordNet and the Princeton WordNet (PWN), the Asian WordNet is realized to visualize the cross language WordNet between the Asian languages. We propose a language resource management system, called WordNet Management System (WNMS), as a distributed management system that allows the server to perform the cross language WordNet retrieval, including the fundamental web service applications for editing, visualizing and language processing. The WNMS is implemented on a web service protocol therefore each node can be independently maintained, and the service of each language WordNet can be called directly through the web service API. In case of cross language implementation, the synset ID (or synset offset) defined by PWN is used to determined the linkage between the languages. English PWN. Therefore, the original structural 1. Introduction information is inherited to the target WordNet through its sense translation and sense ID. The AWN finally Language resource becomes crucial in the recent needs for cross cultural information exchange. -

Lexical Resource Reconciliation in the Xerox Linguistic Environment
Lexical Resource Reconciliation in the Xerox Linguistic Environment Ronald M. Kaplan Paula S. Newman Xerox Palo Alto Research Center Xerox Palo Alto Research Center 3333 Coyote Hill Road 3333 Coyote Hill Road Palo Alto, CA, 94304, USA Palo Alto, CA, 94304, USA kapl an~parc, xerox, com pnewman©parc, xerox, tom Abstract This paper motivates and describes the morpho- logical and lexical adaptations of XLE. They evolved This paper motivates and describes those concurrently with PARGRAM, a multi-site XLF_~ aspects of the Xerox Linguistic Environ- based broad-coverage grammar writing effort aimed ment (XLE) that facilitate the construction at creating parallel grammars for English, French, of broad-coverage Lexical Functional gram- and German (see Butt et. al., forthcoming). The mars by incorporating morphological and XLE adaptations help to reconcile separately con- lexical material from external resources. structed linguistic resources with the needs of the Because that material can be incorrect, in- core grammars. complete, or otherwise incompatible with The paper is divided into three major sections. the grammar, mechanisms are provided to The next section sets the stage by providing a short correct and augment the external material overview of the overall environmental features of the to suit the needs of the grammar developer. original LFG GWB and its provisions for morpho- This can be accomplished without direct logical and lexicon processing. The two following modification of the incorporated material, sections describe the XLE extensions in those areas. which is often infeasible or undesirable. Externally-developed finite-state morpho- 2 The GWB Data Base logical analyzers are reconciled with gram- mar requirements by run-time simulation GWB provides a computational environment tai- of finite-state calculus operations for com- lored especially for defining and testing grammars bining transducers. -

Wordnet As an Ontology for Generation Valerio Basile
WordNet as an Ontology for Generation Valerio Basile To cite this version: Valerio Basile. WordNet as an Ontology for Generation. WebNLG 2015 1st International Workshop on Natural Language Generation from the Semantic Web, Jun 2015, Nancy, France. hal-01195793 HAL Id: hal-01195793 https://hal.inria.fr/hal-01195793 Submitted on 9 Sep 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. WordNet as an Ontology for Generation Valerio Basile University of Groningen [email protected] Abstract a structured database of words in a format read- able by electronic calculators. For each word in In this paper we propose WordNet as an the database, WordNet provides a list of senses alternative to ontologies for the purpose of and their definition in plain English. The senses, natural language generation. In particu- besides having a inner identifier, are represented lar, the synset-based structure of WordNet as synsets, i.e., sets of synonym words. Words proves useful for the lexicalization of con- in general belong to multiple synsets, as they cepts, by providing ready lists of lemmas have more than one sense, so the relation between for each concept to generate. -

'Face' in Vietnamese
Body part extensions with mặt ‘face’ in Vietnamese Annika Tjuka 1 Introduction In many languages, body part terms have multiple meanings. The word tongue, for example, refers not only to the body part but also to a landscape or object feature, as in tongue of the ocean or tongue of flame. These examples illustrate that body part terms are commonly mapped to concrete objects. In addition, body part terms can be transferred to abstract domains, including the description of emotional states (e.g., Yu 2002). The present study investigates the mapping of the body part term face to the concrete domain of objects. Expressions like mouth of the river and foot of the bed reveal the different analogies for extending human body parts to object features. In the case of mouth of the river, the body part is extended on the basis of the function of the mouth as an opening. In contrast, the expression foot of the bed refers to the part of the bed where your feet are if you lie in it. Thus, the body part is mapped according to the spatial alignment of the body part and the object. Ambiguous words challenge our understanding of how the mental lexicon is structured. Two processes could lead to the activation of a specific meaning: i) all meanings of a word are stored in one lexical entry and the relevant one is retrieved, ii) only a core meaning is stored and the other senses are generated by lexical rules (for a description of both models, see, Pustejovsky 1991). In the following qualitative analysis, I concentrate on the different meanings of the body part face and discuss the implications for its representation in the mental lexicon. -
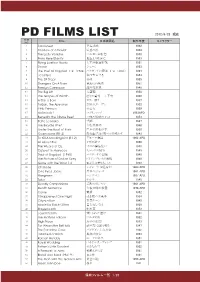
Pd Films List 0824
PD FILMS LIST 2012/8/23 現在 FILM Title 日本映画名 制作年度 キャラクター NO 1 Sabouteur 逃走迷路 1942 2 Shadow of a Doubt 疑惑の影 1943 3 The Lady Vanishe バルカン超特急 1938 4 From Here Etanity 地上より永遠に 1953 5 Flying Leather Necks 太平洋航空作戦 1951 6 Shane シェーン 1953 7 The Thief Of Bagdad 1・2 (1924) バクダッドの盗賊 1・2 (1924) 1924 8 I Confess 私は告白する 1953 9 The 39 Steps 39夜 1935 10 Strangers On A Train 見知らぬ乗客 1951 11 Foreign Correspon 海外特派員 1940 12 The Big Lift 大空輸 1950 13 The Grapes of Wirath 怒りの葡萄 上下有 1940 14 A Star Is Born スター誕生 1937 15 Tarzan, the Ape Man 類猿人ターザン 1932 16 Little Princess 小公女 1939 17 Mclintock! マクリントック 1963APD 18 Beneath the 12Mile Reef 12哩の暗礁の下に 1953 19 PePe Le Moko 望郷 1937 20 The Bicycle Thief 自転車泥棒 1948 21 Under The Roof of Paris 巴里の屋根の根 下 1930 22 Ossenssione (R1.2) 郵便配達は2度ベルを鳴らす 1943 23 To Kill A Mockingbird (R1.2) アラバマ物語 1962 APD 24 All About Eve イヴの総て 1950 25 The Wizard of Oz オズの魔法使い 1939 26 Outpost in Morocco モロッコの城塞 1949 27 Thief of Bagdad (1940) バクダッドの盗賊 1940 28 The Picture of Dorian Grey ドリアングレイの肖像 1949 29 Gone with the Wind 1.2 風と共に去りぬ 1.2 1939 30 Charade シャレード(2種有り) 1963 APD 31 One Eyed Jacks 片目のジャック 1961 APD 32 Hangmen ハングマン 1987 APD 33 Tulsa タルサ 1949 34 Deadly Companions 荒野のガンマン 1961 APD 35 Death Sentence 午後10時の殺意 1974 APD 36 Carrie 黄昏 1952 37 It Happened One Night 或る夜の出来事 1934 38 Cityzen Ken 市民ケーン 1945 39 Made for Each Other 貴方なしでは 1939 40 Stagecoach 駅馬車 1952 41 Jeux Interdits 禁じられた遊び 1941 42 The Maltese Falcon マルタの鷹 1952 43 High Noon 真昼の決闘 1943 44 For Whom the Bell tolls 誰が為に鐘は鳴る 1947 45 The Paradine Case パラダイン夫人の恋 1942 46 I Married a Witch 奥様は魔女 -

Modeling and Encoding Traditional Wordlists for Machine Applications
Modeling and Encoding Traditional Wordlists for Machine Applications Shakthi Poornima Jeff Good Department of Linguistics Department of Linguistics University at Buffalo University at Buffalo Buffalo, NY USA Buffalo, NY USA [email protected] [email protected] Abstract Clearly, descriptive linguistic resources can be This paper describes work being done on of potential value not just to traditional linguis- the modeling and encoding of a legacy re- tics, but also to computational linguistics. The source, the traditional descriptive wordlist, difficulty, however, is that the kinds of resources in ways that make its data accessible to produced in the course of linguistic description NLP applications. We describe an abstract are typically not easily exploitable in NLP appli- model for traditional wordlist entries and cations. Nevertheless, in the last decade or so, then provide an instantiation of the model it has become widely recognized that the devel- in RDF/XML which makes clear the re- opment of new digital methods for encoding lan- lationship between our wordlist database guage data can, in principle, not only help descrip- and interlingua approaches aimed towards tive linguists to work more effectively but also al- machine translation, and which also al- low them, with relatively little extra effort, to pro- lows for straightforward interoperation duce resources which can be straightforwardly re- with data from full lexicons. purposed for, among other things, NLP (Simons et al., 2004; Farrar and Lewis, 2007). 1 Introduction Despite this, it has proven difficult to create When looking at the relationship between NLP significant electronic descriptive resources due to and linguistics, it is typical to focus on the dif- the complex and specific problems inevitably as- ferent approaches taken with respect to issues sociated with the conversion of legacy data. -

TEI and the Documentation of Mixtepec-Mixtec Jack Bowers
Language Documentation and Standards in Digital Humanities: TEI and the documentation of Mixtepec-Mixtec Jack Bowers To cite this version: Jack Bowers. Language Documentation and Standards in Digital Humanities: TEI and the documen- tation of Mixtepec-Mixtec. Computation and Language [cs.CL]. École Pratique des Hauts Études, 2020. English. tel-03131936 HAL Id: tel-03131936 https://tel.archives-ouvertes.fr/tel-03131936 Submitted on 4 Feb 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Préparée à l’École Pratique des Hautes Études Language Documentation and Standards in Digital Humanities: TEI and the documentation of Mixtepec-Mixtec Soutenue par Composition du jury : Jack BOWERS Guillaume, JACQUES le 8 octobre 2020 Directeur de Recherche, CNRS Président Alexis, MICHAUD Chargé de Recherche, CNRS Rapporteur École doctorale n° 472 Tomaž, ERJAVEC Senior Researcher, Jožef Stefan Institute Rapporteur École doctorale de l’École Pratique des Hautes Études Enrique, PALANCAR Directeur de Recherche, CNRS Examinateur Karlheinz, MOERTH Senior Researcher, Austrian Center for Digital Humanities Spécialité and Cultural Heritage Examinateur Linguistique Emmanuel, SCHANG Maître de Conférence, Université D’Orléans Examinateur Benoit, SAGOT Chargé de Recherche, Inria Examinateur Laurent, ROMARY Directeur de recherche, Inria Directeur de thèse 1. -

1 from Text to Thought How Analyzing Language Can Advance
1 From Text to Thought How Analyzing Language Can Advance Psychological Science Joshua Conrad Jackson1*, Joseph Watts2,3,4, Johann-Mattis List2, Ryan Drabble1, Kristen Lindquist1 1Department of Psychology and Neuroscience, University of North Carolina at Chapel Hill 2Department of Linguistic and Cultural Evolution, Max Planck Institute for the Science of Human History 3Center for Research on Evolution, Belief, and Behaviour, University of Otago 4Religion Programme, University of Otago *Corresponding author Main Text Word Count, Excluding References: 8,116 Reference Count: 123 Acknowledgements: JCJ is supported by the National Science Foundation, the Royster Society of Fellows, and the John Templeton Foundation. JW is supported by the John Templeton Foundation and the Marsden Foundation of New Zealand (19-VUW-188). JML is supported by the European Research Council. The views in this paper do not necessarily reflect the views of these funding agencies. Abstract: Humans have been using language for thousands of years, but psychologists seldom consider what natural language can tell us about the mind. Here we propose that language offers a unique window into human cognition. After briefly summarizing the legacy of language analyses in psychological science, we show how methodological advances have made these analyses more feasible and insightful than ever before. In particular, we describe how two forms of language analysis—comparative linguistics and natural language processing—are already contributing to how we understand emotion, creativity, and religion, and overcoming methodological obstacles related to statistical power and culturally diverse samples. We summarize resources for learning both of these methods, and highlight the best way to combine language analysis techniques with behavioral paradigms.