Mathematical Equation Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bloomberg Professional Services MENU
Software Compatibility Matrix English 16 July 2020 Version: 24.0 This document should be used in conjunction with the Bloomberg® Workstation Requirements and Bloomberg® Transport and Security document. Please see our website or BBPC<GO> on the Terminal for more information. The information provided in this document outlines the Microsoft® platforms that are compatible with the Bloomberg Terminal® and its associated software. These requirements should be taken into consideration when determining the overall suitability of the users’ workstation to successfully utilize all available functionality. Please keep the latest Bloomberg specifications in mind when planning workstation upgrades. Extended support end date* Minimum Product Comments Microsoft Bloomberg Requirements Operating Systems Windows 7 Home Premium *Only 64-Bit versions are supported. Ultimate *Windows 7 Starter Edition is not supported. Professional Service Pack 1 *Customers installing Bloomberg Terminal® software 14-Jan-20 31-Jan-22 Enterprise newly must install Microsoft .NET Framework 4.0 or higher. 64-Bit only Windows 8/8.1 *Only 64-Bit versions are supported. Pro *Customers must install Microsoft Silverlight in order to 10-Jan-23 *TBA* Enterprise run multimedia functions and the BMAP function. *Only 64-Bit versions are supported. Windows 10 *Windows 10 Mobile / Mobile Enterprise are not Home supported. *TBA* *TBA* Pro *Windows 10 in S mode is not supported. Education *Customers must install Microsoft Silverlight in order to Enterprise run multimedia functions and the BMAP function. Microsoft Office Versions Office 2010 Service Pack 2 *Office Starter 2010 is not supported. 13-Oct-20 30-Apr-21 Version 14.0.x Office Professional Service Pack 1 11-Apr-23 *TBA* 2013 Version 15.0.x Office 365 *Office 365 ProPlus must be installed on the local Service Pack 1 computer. -

RIA Development with Silverlight &
RIA Development with Silverlight & WPF James Chittenden UX Evangelist Public Sector Why RIA? WPF Silverlight “A line-of-business application is one of the set of critical computer applications that are vital to running an enterprise ” – Wikipedia http://en.wikipedia.org/wiki/Line_of_business Deployable & Maintainable We don’t have a designer Employees don’t care what it looks like If it ain’t broke… Return on investment Don’t have the budget “ Design matters. But design is not about decoration or about ornamentation. Design is about making communication as easy and clear for the viewer as possible.” – Garr Reynolds http://www.presentationzen.com 1 Simplicity 2 Visibility 3 Metaphor 4 Natural Mappings 5 Constraints 6 Error Prevention 7 Consistency WPF Silverlight Microsoft .NET Application Platform Deliver applications across the UX Continuum Consistent Tools & Application Model Develop Deploy Design Browser User Experience Continuum Client • Unify UI, media, graphics and documents • Take full advantage of the graphical power of the PC • Easy, low-impact deployment options • Integration with Office and Windows • Compatibility with Silverlight for web and devices Key WPF Platform Concepts Element Lookless XAML Composition Controls Composited Data Binding Visuals XAML: Declarative Programming for Windows • Markup – Build applications in simple declarative statements • Code and content are separate – Streamline collaboration between designers and developers • Easy for tools to consume and generate <Button Width="100">OK Button b1 = new Button(); -
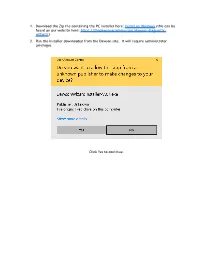
Dawson Install for Windows Users-V01
1. Download the Zip file containing the PC installer here: Install on Windows (this can be found on our website here: https://thedawsonacademy.com/dawson-diagnostic- wizard/) 2. Run the installer downloaded from the Dawson site. It will require administrator privileges. Click Yes to continue. 3. You will see the installer unpacking files and then see a message box letting you know that the installation will proceed. 4. Next, Microsoft Silverlight will be installed. Silverlight is the engine that runs the Dawson Wizard App. Click OK Uncheck the Bing and MSN boxes unless you want this, and click “Install now”. Note that any box that’s left check, will have that feature enabled for ALL your installed Browsers on your computer. Silverlight will proceed with the Install and you will see this window. Click “Close” to Continue. If Silverlight requires any additional configuration, you will see this window which will automatically close and take you to the next step when completed. 5. The next message window lets you know that the Dawson Wizard App installation step is about to proceed. After clicking OK, a Browser window will open where you will log into your account and the Dawson Wizard App will be downloaded and installed on your computer. Enter Credentials Wait for Download to finish Click “Install Application” and you will get another Install Window. Click “Install”: 6. Once the Install finishes, you’ll see the Dawson Wizard App running and a message box saying that the Install was successful. Click OK on the message box and log into the Dawson Wizard App with your credentials. -

Internet Explorer Users Are Required to Add the Portal URL to Trusted Sites
CLA Client Portal Browser and Silverlight FAQs 1. Question: I am receiving an “Error 500” when clicking the link to access the CLA Document Portal. Resolution: Verify with your IT department that the portal is not blocked by any internal monitoring or protection applications. 2. Question: How do I know if my computer has Microsoft Silverlight Installed? Resolution: The first time you try and login to the portal you will be prompted to install Silverlight from Microsoft’s website if you don’t have it already installed. The installation typically takes less than one minute and is completely safe. http://www.microsoft.com/getsilverlight/Get-Started/Install/Default.aspx If you cannot, or prefer not to, install Silverlight on your machine, a simplified version of the document portal that does not require Silverlight is available. Click on the Take me to the non- Silverlight login on the CLA Document Portal page (www.claconnect.com/docportal). 3. Question: I cannot access the CLA Document Portal. (Server error/Page not found) Resolution: Check that you are using a Microsoft Silverlight 4 compatible browser on all PC’s or MAC. A complete list of browsers and operating systems that support Silverlight 4 can be found at http://www.microsoft.com/getsilverlight/locale/en-us/html/installation-win-SL4.html Please note: Internet Explorer users are required to add the portal URL to Trusted Sites. Adding to Trusted Sites Internet Explorer settings 1. Open Internet Explorer and browse to https://portal.cchaxcess.com/Portal/. 2. In Internet Explorer, select Tools / Internet Options; then select the Security tab and click Trusted Sites and then Sites. -

Xactimate 28 Network Installation Guide
Network Installation Guide © 2011-2013 by Xactware . All rights reserved. Xactware, Xactimate, Xactimate Online, XactNet, and/or other Xactware products referenced herein are either trademarks or registered trademarks of Xactware Solutions, Inc. Other product and company names mentioned herein may be the trademarks of their respective owners. (031213) www.xactware.com Xactimate version 28 Network Installation Guide INTRODUCTION Like all networked software applications, Xactimate must be installed on a workstation connected to a network that has been properly set up and mapped to a shared drive (this document uses the X drive as an example). Xactware recommends that a certified network technician set up and administer the network. It is recommended for a network installation of Xactimate to use the physical disc. For instructions about how to set up a network installation of Xactimate via the downloadable version, visit the eService Center at https:/ / eservice.xactware.com/apps/esc/ Xactimate v28.0 Network Installation Guide Page 1 Introduction SYSTEM REQUIREMENTS - XACTIMATE V28.0 NETWORK INSTALLATION Specifications Minimum Requirements Recommended Requirements Processor Single Core Processor 1.5GHz Dual Core Processors Operating System Windows 8 (32 bit, 64 bit) Windows 7 (32 bit, 64 bit) Windows Vista (32 bit, 64 bit Business, 64 bit Ultimate) Windows XP Service Pack 3 *Windows RT is not Supported Video Card Open GL 2.0 Compatible with 128 Open GL 2.0 Compatible with MB of VRAM and Latest Drivers 512 MB of VRAM and Latest Drivers -

1 in the UNITED STATES DISTRICT COURT for the DISTRICT of DELAWARE VIATECH TECHNOLOGIES, INC., ) ) Plaintiff, ) Case No. 1:17Cv5
Case 1:17-cv-00570-RGA Document 11 Filed 10/01/17 Page 1 of 37 PageID #: 145 IN THE UNITED STATES DISTRICT COURT FOR THE DISTRICT OF DELAWARE VIATECH TECHNOLOGIES, INC., ) ) Plaintiff, ) Case No. 1:17cv570 v. ) ) MICROSOFT CORPORATION, ) DEMAND FOR JURY TRIAL ) Defendant. ) AMENDED COMPLAINT FOR PATENT INFRINGEMENT Plaintiff ViaTech Technologies, Inc. (“plaintiff” or “ViaTech”), through its attorneys, for its complaint against defendant Microsoft Corporation (“defendant” or “Microsoft”), alleges as follows: THE PARTIES 1. Plaintiff is a corporation organized and existing under the laws of the State of Delaware having a place of business at 1136 Ashbourne Circle, Trinity, FL 34655-7103. 2. Defendant Microsoft is a corporation organized and existing under the laws of the State of Washington having its principal place of business at One Microsoft Way, Redmond, WA 98052. JURISDICTION AND VENUE 3. This action arises under the patent laws of the United States, Title 35 of the United States Code. Subject matter jurisdiction is proper in this Court pursuant to 28 U.S.C. §§ 1331 and 1338(a). 4. Defendant Microsoft is subject to this Court’s specific and general personal jurisdiction consistent with due process and the Delaware Long Arm Statute, 10 Del. C. § 3104. 1 Case 1:17-cv-00570-RGA Document 11 Filed 10/01/17 Page 2 of 37 PageID #: 146 5. Venue in this Judicial District is proper under 28 U.S.C. § 1400(b). 6. Microsoft is registered to do business in Delaware, and has appointed Corporation Service Company, 2711 Centerville Rd., Suite 400, Wilmington, DE 19808, as its registered agent, and either directly, or indirectly through its distribution network, has transacted and/or continues to transact business in Delaware, and has regularly solicited and continues to regularly solicit business in Delaware. -

Microsoft Silverlight Photography Framework: Comparing Component Based Designs in Adobe Flex and Microsoft Silverlight
Grand Valley State University ScholarWorks@GVSU Masters Projects Graduate Research and Creative Practice 8-3-2009 Microsoft Silverlight Photography Framework: Comparing Component Based Designs in Adobe Flex and Microsoft Silverlight David Roossien Grand Valley State University, [email protected] Follow this and additional works at: https://scholarworks.gvsu.edu/gradprojects Part of the Computer and Systems Architecture Commons ScholarWorks Citation Roossien, David, "Microsoft Silverlight Photography Framework: Comparing Component Based Designs in Adobe Flex and Microsoft Silverlight" (2009). Masters Projects. 1. https://scholarworks.gvsu.edu/gradprojects/1 This Dissertation is brought to you for free and open access by the Graduate Research and Creative Practice at ScholarWorks@GVSU. It has been accepted for inclusion in Masters Projects by an authorized administrator of ScholarWorks@GVSU. For more information, please contact [email protected]. Microsoft Silverlight Photography Framework Comparing Component Based Designs in Adobe Flex and Microsoft Silverlight David Roossien August 3, 2009 Grand Valley State University CS693 Masters Project For Professor Robert Adams Table of Contents Introduction .......................................................................................................................... 3 Rich Internet Applications ............................................................................................... 3 Goals of Adobe Flex ....................................................................................................... -

Audio Oriented UI Components for the Web Platform Victor Saiz, Benjamin Matuszewski, Samuel Goldszmidt
Audio oriented UI components for the web platform Victor Saiz, Benjamin Matuszewski, Samuel Goldszmidt To cite this version: Victor Saiz, Benjamin Matuszewski, Samuel Goldszmidt. Audio oriented UI components for the web platform. WAC, Jan 2015, Paris, France. hal-01256945 HAL Id: hal-01256945 https://hal.archives-ouvertes.fr/hal-01256945 Submitted on 15 Jan 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Audio oriented UI components for the web platform Victor Saiz, Benjamin Matuszewski, Samuel Goldszmidt IRCAM – Centre Pompidou, STMS lab IRCAM-CNRS-UPMC 1, Place Igor Stravinsky 75004 Paris {firstname.lastname}@ircam.fr ABSTRACT media APIs yet, from knobs to waveform visualisers, spec- trograms, breakpoint functions, timelines etc. These new This paper presents a set of web-native tools for visualis- media elements presents new interaction and editing chal- ing and interacting with time-based objects. These visu- lenges specially for media streams like audio buffers. alisations are rendered as part of the document using web standard technologies, allowing for an easy integration and After widespread adoption (2008 to 2013 [14]), these new interaction with the elements on the same document with- APIs are made available in millions of browsers. -

Predix Design System Contents
Predix Design System Contents Predix Design System Overview 1 Create Modern Web Applications 1 About the Predix Design System 6 Application Development with the Predix Design System 7 Supported Browsers for Web Applications 9 Predix Design System Glossary 10 Use the Predix Design System 12 Using the Predix Design System 12 Setting Up the Predix Design System Developer Environment 13 Migrate to Predix Design System Cirrus 15 Migrating to Predix Design System Cirrus 15 New Predix UI Components for Predix Design System Cirrus 17 Deprecated Predix UI Components for Predix Design System Cirrus 18 Predix Design System Cirrus Design Changes 18 Predix Design System Cirrus API Changes 19 Get Started with Predix UI Components 26 About Predix UI Components 26 Getting Started with Predix UI Components 27 Using a Predix UI Component in a Web Application 27 Predix UI Basics 29 Predix UI Templates 30 Predix UI Components 31 Predix UI Datetime Components 33 Predix UI Mobile Components 33 Predix UI Data Visualization Components 34 Predix UI Vis Framework 35 Localize Predix UI Components 39 Localizing Predix UI Components 39 Localizing Text Strings 40 Localizing with the Moments.js Library 41 Localizing with the D3.js Library 44 Custom Locale Support 46 ii Predix Design System Theme Web Applications 51 Theming Web Applications 51 Styling a Predix UI Component 51 Applying a Theme to a Web Application 53 CSS Custom Properties Overview 54 CSS Custom Properties Reference 55 Get Started with Predix UI CSS Modules 56 About Predix UI CSS Modules 56 Getting Started with Predix UI CSS Modules 56 Predix UI CSS Visual Library 59 Predix UI CSS Layout Library 60 Predix UI CSS Utilities Library 61 Predix UI CSS Module Overview 62 Predix Design System Release Notes 66 Predix Design System Release Notes 66 iii Predix Design System Overview Create Modern Web Applications Web applications have evolved to implement many coordinated user functions and tasks traditionally associated with desktop software (for example, Google Docs and Microsoft Office). -

Silverlight Overview
Silverlight 4 Overview Technical Feature Overview Contents Credits ........................................................................................................................................................... 6 Introduction .................................................................................................................................................. 7 Enabling Business Application Development ................................................................................................ 8 Printing .................................................................................................................................................. 8 Localization with Bi-Directional and Script-Based Text and Right-to-Left Support .............................. 8 Extended Language Support ................................................................................................................. 9 RichTextBox Control .............................................................................................................................. 9 Text Input ............................................................................................................................................ 11 Viewbox Control .................................................................................................................................. 11 Auto-Sizing Columns and Copy from DataGrid ................................................................................... 12 Navigation Page Loading Extensibility -

Silverlight for Windows Embedded Developer's Guide 4
Silverlight for Windows Embedded Developer’s Guide Published: January 2012 Applies to: Windows Embedded Compact 7 Abstract This paper is a comprehensive introduction to developing Silverlight for Windows Embedded applications. It describes the programming model and design workflow in Silverlight for Windows Embedded. It covers the following concepts: How to provide safe implicit-type conversion of generic objects How to work with visual hosts and visual trees How to handle events in Silverlight for Windows Embedded This paper includes tutorials that show you how to create applications, create custom user controls, and implement hardware acceleration for graphics. These tutorials require Visual Studio 2008, Windows Embedded Compact 7, an OS image and a development device or virtual CEPC. To create XAML source files for your UI design, you also need Microsoft Expression Blend 3 or another XAML editor. © 2012 Microsoft. All rights reserved. Contents Introduction .......................................................................................................................................... 4 Overview .............................................................................................................................................. 4 Features and Benefits of Silverlight for Windows Embedded Development Framework ...................... 5 Supported Silverlight UI Features ...................................................................................................... 6 Programming Model in Silverlight for Windows Embedded -

Introducing Microsoft Web Technologies
Software + Services : Extending Rich User Experience to the Web Linda Chong Architect Evangelist Developer & Platform Evangelism Microsoft Singapore Agenda • Software + Services • The Next Web Evolution • Microsoft Next Web Technologies • User Experience – Silverlight • Windows Live Platform Services • Real life examples/showcases What's Next? SaaS? SOA? Web 2.0? ??? Web Client- Server Mainframe The Common Denominator SaaS Service delivery SOA Service composition Web 2.0 Service experience & economics Services are software + Take an expansive view + Need integration + Want platform = Software + Services The Next Wave Software + Services Web Client- Server Mainframe Software + Services iTunes Service – Updates, Music + iPod – device software iTunes – Software, Rip / Rich User Interface Software + Services XBOX LIVE – networked game-play, updates, profile, arcade + Xbox – device and state- of-art gaming experience Xbox.com – personalized portal Partners Roles within the organization Customers Silverlight Streaming Messenger Photos Contacts Expo Live Search Live ID Microsoft® Office SharePoint Gadgets Custom Virtual Server 2007 Domains Earth Software Services A Continuum of Experience Web “Supplemented Platform ” Web Optimized Rich Internet Applications The Next Web The Web will continue to Evolve… Geospatial Web – “hyper-local” context Richer User Experience Transform web into a Database Rise of Semantic Web Ubiquitous Connectivity Federated Identity Mashup Web application that combines data and services from more than one source into a