Intel Integrated Performance Primitives in Intel® SGX Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2.5 Classification of Parallel Computers
52 // Architectures 2.5 Classification of Parallel Computers 2.5 Classification of Parallel Computers 2.5.1 Granularity In parallel computing, granularity means the amount of computation in relation to communication or synchronisation Periods of computation are typically separated from periods of communication by synchronization events. • fine level (same operations with different data) ◦ vector processors ◦ instruction level parallelism ◦ fine-grain parallelism: – Relatively small amounts of computational work are done between communication events – Low computation to communication ratio – Facilitates load balancing 53 // Architectures 2.5 Classification of Parallel Computers – Implies high communication overhead and less opportunity for per- formance enhancement – If granularity is too fine it is possible that the overhead required for communications and synchronization between tasks takes longer than the computation. • operation level (different operations simultaneously) • problem level (independent subtasks) ◦ coarse-grain parallelism: – Relatively large amounts of computational work are done between communication/synchronization events – High computation to communication ratio – Implies more opportunity for performance increase – Harder to load balance efficiently 54 // Architectures 2.5 Classification of Parallel Computers 2.5.2 Hardware: Pipelining (was used in supercomputers, e.g. Cray-1) In N elements in pipeline and for 8 element L clock cycles =) for calculation it would take L + N cycles; without pipeline L ∗ N cycles Example of good code for pipelineing: §doi =1 ,k ¤ z ( i ) =x ( i ) +y ( i ) end do ¦ 55 // Architectures 2.5 Classification of Parallel Computers Vector processors, fast vector operations (operations on arrays). Previous example good also for vector processor (vector addition) , but, e.g. recursion – hard to optimise for vector processors Example: IntelMMX – simple vector processor. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

An Introduction to Gpus, CUDA and Opencl
An Introduction to GPUs, CUDA and OpenCL Bryan Catanzaro, NVIDIA Research Overview ¡ Heterogeneous parallel computing ¡ The CUDA and OpenCL programming models ¡ Writing efficient CUDA code ¡ Thrust: making CUDA C++ productive 2/54 Heterogeneous Parallel Computing Latency-Optimized Throughput- CPU Optimized GPU Fast Serial Scalable Parallel Processing Processing 3/54 Why do we need heterogeneity? ¡ Why not just use latency optimized processors? § Once you decide to go parallel, why not go all the way § And reap more benefits ¡ For many applications, throughput optimized processors are more efficient: faster and use less power § Advantages can be fairly significant 4/54 Why Heterogeneity? ¡ Different goals produce different designs § Throughput optimized: assume work load is highly parallel § Latency optimized: assume work load is mostly sequential ¡ To minimize latency eXperienced by 1 thread: § lots of big on-chip caches § sophisticated control ¡ To maXimize throughput of all threads: § multithreading can hide latency … so skip the big caches § simpler control, cost amortized over ALUs via SIMD 5/54 Latency vs. Throughput Specificaons Westmere-EP Fermi (Tesla C2050) 6 cores, 2 issue, 14 SMs, 2 issue, 16 Processing Elements 4 way SIMD way SIMD @3.46 GHz @1.15 GHz 6 cores, 2 threads, 4 14 SMs, 48 SIMD Resident Strands/ way SIMD: vectors, 32 way Westmere-EP (32nm) Threads (max) SIMD: 48 strands 21504 threads SP GFLOP/s 166 1030 Memory Bandwidth 32 GB/s 144 GB/s Register File ~6 kB 1.75 MB Local Store/L1 Cache 192 kB 896 kB L2 Cache 1.5 MB 0.75 MB -

Cuda C Programming Guide
CUDA C PROGRAMMING GUIDE PG-02829-001_v10.0 | October 2018 Design Guide CHANGES FROM VERSION 9.0 ‣ Documented restriction that operator-overloads cannot be __global__ functions in Operator Function. ‣ Removed guidance to break 8-byte shuffles into two 4-byte instructions. 8-byte shuffle variants are provided since CUDA 9.0. See Warp Shuffle Functions. ‣ Passing __restrict__ references to __global__ functions is now supported. Updated comment in __global__ functions and function templates. ‣ Documented CUDA_ENABLE_CRC_CHECK in CUDA Environment Variables. ‣ Warp matrix functions now support matrix products with m=32, n=8, k=16 and m=8, n=32, k=16 in addition to m=n=k=16. www.nvidia.com CUDA C Programming Guide PG-02829-001_v10.0 | ii TABLE OF CONTENTS Chapter 1. Introduction.........................................................................................1 1.1. From Graphics Processing to General Purpose Parallel Computing............................... 1 1.2. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model.............3 1.3. A Scalable Programming Model.........................................................................4 1.4. Document Structure...................................................................................... 5 Chapter 2. Programming Model............................................................................... 7 2.1. Kernels......................................................................................................7 2.2. Thread Hierarchy........................................................................................ -

Threading SIMD and MIMD in the Multicore Context the Ultrasparc T2
Overview SIMD and MIMD in the Multicore Context Single Instruction Multiple Instruction ● (note: Tute 02 this Weds - handouts) ● Flynn’s Taxonomy Single Data SISD MISD ● multicore architecture concepts Multiple Data SIMD MIMD ● for SIMD, the control unit and processor state (registers) can be shared ■ hardware threading ■ SIMD vs MIMD in the multicore context ● however, SIMD is limited to data parallelism (through multiple ALUs) ■ ● T2: design features for multicore algorithms need a regular structure, e.g. dense linear algebra, graphics ■ SSE2, Altivec, Cell SPE (128-bit registers); e.g. 4×32-bit add ■ system on a chip Rx: x x x x ■ 3 2 1 0 execution: (in-order) pipeline, instruction latency + ■ thread scheduling Ry: y3 y2 y1 y0 ■ caches: associativity, coherence, prefetch = ■ memory system: crossbar, memory controller Rz: z3 z2 z1 z0 (zi = xi + yi) ■ intermission ■ design requires massive effort; requires support from a commodity environment ■ speculation; power savings ■ massive parallelism (e.g. nVidia GPGPU) but memory is still a bottleneck ■ OpenSPARC ● multicore (CMT) is MIMD; hardware threading can be regarded as MIMD ● T2 performance (why the T2 is designed as it is) ■ higher hardware costs also includes larger shared resources (caches, TLBs) ● the Rock processor (slides by Andrew Over; ref: Tremblay, IEEE Micro 2009 ) needed ⇒ less parallelism than for SIMD COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 1 COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 3 Hardware (Multi)threading The UltraSPARC T2: System on a Chip ● recall concurrent execution on a single CPU: switch between threads (or ● OpenSparc Slide Cast Ch 5: p79–81,89 processes) requires the saving (in memory) of thread state (register values) ● aggressively multicore: 8 cores, each with 8-way hardware threading (64 virtual ■ motivation: utilize CPU better when thread stalled for I/O (6300 Lect O1, p9–10) CPUs) ■ what are the costs? do the same for smaller stalls? (e.g. -

Thread-Level Parallelism I
Great Ideas in UC Berkeley UC Berkeley Teaching Professor Computer Architecture Professor Dan Garcia (a.k.a. Machine Structures) Bora Nikolić Thread-Level Parallelism I Garcia, Nikolić cs61c.org Improving Performance 1. Increase clock rate fs ú Reached practical maximum for today’s technology ú < 5GHz for general purpose computers 2. Lower CPI (cycles per instruction) ú SIMD, “instruction level parallelism” Today’s lecture 3. Perform multiple tasks simultaneously ú Multiple CPUs, each executing different program ú Tasks may be related E.g. each CPU performs part of a big matrix multiplication ú or unrelated E.g. distribute different web http requests over different computers E.g. run pptx (view lecture slides) and browser (youtube) simultaneously 4. Do all of the above: ú High fs , SIMD, multiple parallel tasks Garcia, Nikolić 3 Thread-Level Parallelism I (3) New-School Machine Structures Software Harness Hardware Parallelism & Parallel Requests Achieve High Assigned to computer Performance e.g., Search “Cats” Smart Phone Warehouse Scale Parallel Threads Computer Assigned to core e.g., Lookup, Ads Computer Core Core Parallel Instructions Memory (Cache) >1 instruction @ one time … e.g., 5 pipelined instructions Input/Output Parallel Data Exec. Unit(s) Functional Block(s) >1 data item @ one time A +B A +B e.g., Add of 4 pairs of words 0 0 1 1 Main Memory Hardware descriptions Logic Gates A B All gates work in parallel at same time Out = AB+CD C D Garcia, Nikolić Thread-Level Parallelism I (4) Parallel Computer Architectures Massive array -

AMD Ryzen 5 1600 Specifications
AMD Ryzen 5 1600 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD Ryzen 5 Model number 1600 CPU part numbers YD1600BBM6IAE is an OEM/tray microprocessor YD1600BBAEBOX is a boxed microprocessor with fan and heatsink Frequency 3200 MHz Turbo frequency 3600 MHz Package 1331-pin lidded micro-PGA package Socket Socket AM4 Introduction date March 15, 2017 (announcement) April 11, 2017 (launch) Price at introduction $219 Architecture / Microarchitecture Microarchitecture Zen Processor core Summit Ridge Core stepping B1 Manufacturing process 0.014 micron FinFET process 4.8 billion transistors Data width 64 bit The number of CPU cores 6 The number of threads 12 Floating Point Unit Integrated Level 1 cache size 6 x 64 KB 4-way set associative instruction caches 6 x 32 KB 8-way set associative data caches Level 2 cache size 6 x 512 KB inclusive 8-way set associative unified caches Level 3 cache size 2 x 8 MB exclusive 16-way set associative shared caches Multiprocessing Uniprocessor Features MMX instructions Extensions to MMX SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions AVX / Advanced Vector Extensions AVX2 / Advanced Vector Extensions 2.0 BMI / BMI1 + BMI2 / Bit Manipulation instructions SHA / Secure Hash Algorithm extensions F16C / 16-bit Floating-Point conversion instructions -

Chapter 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures Copyright © 2012, Elsevier Inc. All rights reserved. 1 Contents 1. SIMD architecture 2. Vector architectures optimizations: Multiple Lanes, Vector Length Registers, Vector Mask Registers, Memory Banks, Stride, Scatter-Gather, 3. Programming Vector Architectures 4. SIMD extensions for media apps 5. GPUs – Graphical Processing Units 6. Fermi architecture innovations 7. Examples of loop-level parallelism 8. Fallacies Copyright © 2012, Elsevier Inc. All rights reserved. 2 Classes of Computers Classes Flynn’s Taxonomy SISD - Single instruction stream, single data stream SIMD - Single instruction stream, multiple data streams New: SIMT – Single Instruction Multiple Threads (for GPUs) MISD - Multiple instruction streams, single data stream No commercial implementation MIMD - Multiple instruction streams, multiple data streams Tightly-coupled MIMD Loosely-coupled MIMD Copyright © 2012, Elsevier Inc. All rights reserved. 3 Introduction Advantages of SIMD architectures 1. Can exploit significant data-level parallelism for: 1. matrix-oriented scientific computing 2. media-oriented image and sound processors 2. More energy efficient than MIMD 1. Only needs to fetch one instruction per multiple data operations, rather than one instr. per data op. 2. Makes SIMD attractive for personal mobile devices 3. Allows programmers to continue thinking sequentially SIMD/MIMD comparison. Potential speedup for SIMD twice that from MIMID! x86 processors expect two additional cores per chip per year SIMD width to double every four years Copyright © 2012, Elsevier Inc. All rights reserved. 4 Introduction SIMD parallelism SIMD architectures A. Vector architectures B. SIMD extensions for mobile systems and multimedia applications C. -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -
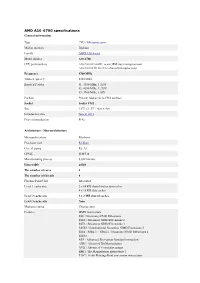
AMD A10-6700 Specifications General Information
AMD A10-6700 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD A10-Series Model number A10-6700 CPU part numbers AD6700OKA44HL is an OEM/tray microprocessor AD6700OKHLBOX is a boxed microprocessor Frequency 3700 MHz Turbo frequency 4300 MHz Boosted P states #1: 4300 MHz, 1.325V #2: 4200 MHz, 1.275V #3: 3900 MHz, 1.05V Package 904-pin lidded micro-PGA package Socket Socket FM2 Size 1.57" x 1.57" / 4cm x 4cm Introduction date June 4, 2013 Price at introduction $142 Architecture / Microarchitecture Microarchitecture Piledriver Processor core Richland Core stepping RL-A1 CPUID 610F31h Manufacturing process 0.032 micron Data width 64 bit The number of cores 4 The number of threads 4 Floating Point Unit Integrated Level 1 cache size 2 x 64 KB shared instruction caches 4 x 16 KB data caches Level 2 cache size 2 x 2 MB shared caches Level 3 cache size None Multiprocessing Uniprocessor Features MMX instructions SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions ABM / Advanced Bit Manipulation AVX / Advanced Vector Extensions BMI1 / Bit Manipulation instructions 1 F16C / 16-bit Floating-Point conversion instructions FMA3 / 3-operand Fused Multiply-Add instructions FMA4 / 4-operand Fused Multiply-Add instructions TBM / Trailing Bit Manipulation instructions XOP / eXtended Operations instructions AMD64 -

Lect. 11: Vector and SIMD Processors
Lect. 11: Vector and SIMD Processors . Many real-world problems, especially in science and engineering, map well to computation on arrays . RISC approach is inefficient: – Based on loops → require dynamic or static unrolling to overlap computations – Indexing arrays based on arithmetic updates of induction variables – Fetching of array elements from memory based on individual, and unrelated, loads and stores – Instruction dependences must be identified for each individual instruction . Idea: – Treat operands as whole vectors, not as individual integer of float-point numbers – Single machine instruction now operates on whole vectors (e.g., a vector add) – Loads and stores to memory also operate on whole vectors – Individual operations on vector elements are independent and only dependences between whole vector operations must be tracked CS4/MSc Parallel Architectures - 2012-2013 1 Execution Model for (i=0; i<64; i++) a[i] = b[i] + s; . Straightforward RISC code: – F2 contains the value of s – R1 contains the address of the first element of a – R2 contains the address of the first element of b – R3 contains the address of the last element of a + 8 loop: L.D F0,0(R2) ;F0=array element of b ADD.D F4,F0,F2 ;main computation S.D F4,0(R1) ;store result DADDUI R1,R1,8 ;increment index DADDUI R2,R2,8 ;increment index BNE R1,R3,loop ;next iteration CS4/MSc Parallel Architectures - 2012-2013 2 Execution Model for (i=0; i<64; i++) a[i] = b[i] + s; . Straightforward vector code: – F2 contains the value of s – R1 contains the address of the first element of a – R2 contains the address of the first element of b – Assume vector registers have 64 double precision elements LV V1,R2 ;V1=array b ADDVS.D V2,V1,F2 ;main computation SV V2,R1 ;store result – Notes: . -

SIMD the Good, the Bad and the Ugly
SIMD The Good, the Bad and the Ugly Viktor Leis Outline 1. Why does SIMD exist? 2. How to use SIMD? 3. When does SIMD help? 1 Why Does SIMD Exist? Hardware Trends • for decades, single-threaded performance doubled every 18-22 months • during the last decade, single-threaded performance has been stagnating • clock rates stopped growing due to heat/end of Dennard’s scaling • number of transistors is still growing, used for: • large caches • many cores (thread parallelism) • SIMD (data parallelism) 2 Number of Cores AMD Rome 64 48 AMD Naples 32 cores Skylake SP Broadwell EX Broadwell EP Haswell EP 16 Ivy Bridge EX Ivy Bridge EP Nehalem (Westmere EX) Nehalem (Beckton) Sandy Bridge EP Core (Kentsfield) Core (Lynnfield) NetBurst (Foster) NetBurst (Paxville) 1 2000 2004 2008 2012 2016 2020 year 3 Skylake CPU 4 Skylake Core 5 x86 SIMD History • 1997: MMX 64-bit (Pentium 1) • 1999: SSE 128-bit (Pentium 3) • 2011: AVX 256-bit float (Sandy Bridge) • 2013: AVX2 256-bit int (Haswell) • 2017: AVX-512 512 bit (Skylake Server) • instructions usually introduced by Intel • AMD typically followed quickly (except for AVX-512) 6 Single Instruction Multiple Data (SIMD) • data parallelism exposed by the CPU’s instruction set • CPU register holds multiple fixed-size values (e.g., 4×32-bit) • instructions (e.g., addition) are performed on two such registers (e.g., executing 4 additions in one instruction) 42 1 7 + 31 6 2 = 73 7 9 7 Registers • SSE: 16×128 bit (XMM0...XMM15) • AVX: 16×256 bit (YMM0...YMM15) • AVX-512: 32×512 bit (ZMM0...ZMM31) • XMM0 is lower half