Conversion Rate Prediction in Search Engine Marketing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Six-Steps for Search Engine Marketing Learning
SIX-STEPS FOR SEARCH ENGINE MARKETING LEARNING Kai-Yu Wang, Brock University AXCESSCAPON TEACHING INNOVATION COMPETIION TEACHING NOTES Google AdWords is considered to be the most important digital marketing channel, causing firms to consistently increase their budget in this area (Hanapin Marketing, 2016). Paid search advertising expenditures in the US are predicted to reach $45.81 billion by 2018, making up 42.7% of the total expected digital advertising expenditures in the country (eMarketer, 2018). One of the key challenges in teaching digital marketing is determining how to help students learn digital marketing strategies with actionable tactics that they can directly apply to the real digital business world. Thus, a six-step process was proposed and used in my internet and social media class to address this pedagogical problem. Students learned search engine marketing (SEM) through in-class assignments and a SEM campaign for a local organization. 1. Local Businesses (i.e., community partners): Before the semester began, a call for service-learning project participation was sent to a pool of local community partners. Among the 24 interested community partners, nine from various industries (e.g., wine, construction, auto repairs) were selected to work with my internet and social media marketing class. In week two of the semester, nine teams (five students per team) were formed and randomly assigned one local business to work with on the project. Each team was required to schedule a meeting with its community partner in the following week. The purpose of this meeting was to understand the partner’s products/services, current marketing strategies, and digital marketing problems. -

Search Engine Marketing
■ Search Engine Marketing - SEM ■ Search Engine Optimization - SEO ■ Social Media Optimization - SMO ■ Pay per Click Campaign Management ■ Affiliate Marketing Solutions www.seosolutions.us Monday, July 20, 2009 ProfileProfile Of ofThe the CompanyCompany • Doug Dvorak, President and CEO • Doug Dvorak is the President and CEO of SEO Solutions Inc., a worldwide organization that assists clients with strategic internet marketing and search engine optimization (SEO), as well as other aspects of sales and marketing management. Mr. Dvorak's clients are characterized as Fortune 1000 companies, small to medium businesses, civic organizations and service businesses. Mr. Dvorak has earned an international reputation for his powerful internet marketing and search engine optimization methods, techniques and strategies. • Doug Dvorak, an internet entrepreneur, has been developing and growing successful online businesses for more than 12 years. He has extensive knowledge and experience in all online marketing matters, including search engine optimization, pay per click marketing, social media optimization, and affiliate marketing. He holds a Bachelor of Arts degree in Business Administration and a Master of Business Administration in Marketing Management. Doug is responsible for the development of partnerships and clients, as well as overseeing all search engine optimization projects. Together with his staff, located in Chicago, Illinois, it is Doug's responsibility to create cost-effective strategies that get web sites to the top of major search engines. www.seosolutions.us Monday, July 20, 2009 ClientClient Feedback Feedback "SEO Solutions has allowed us to get to the next level in terms of customer sales and client reach. We have experienced tremendous results with search engine optimization. -

No. 19-1061, Viewed 07/29/2020
MicrosoftUSCA4 Advertising Appeal:| Search Engine Marketing19-1061 (SEM) & more Doc: 51 Filed: 08/13/2020 Pg: 1 of 5 Benefits Advertising Cost Testimonials FAQ Sign up now Sign In Millions are searching. Already use Microsoft Advertising? Make sure they find you. Enter your user name or email address to Reach customers looking for your business. Use the Microsoft Search Network to sign in: connect with an audience that searches 5.9 billion times a month.1 Sign up now Have a question? Please call us at 877-635-3561. 1. comScore qSearch, Explicit Core Search (custom), September 2019. Microsoft Search Network includes Microsoft Forgot your user name? sites, Yahoo sites (searches powered by Bing) and AOL sites in the United States. Data represents desktop traffic only. Powerful network. Powerful07/29/2020 benefits. viewed 19-1061, No. © 2020 Microsoft Legal Privacy & Cookies Advertise Developers Support Blog Feedback REACH ACROSS DEVICES GO GLOBAL OR LOCAL EASY TO IMPORT Connect with customers who are Reach millions of unique searchers on If you're already using another product looking for your products and services the Microsoft Search Network — by like Google Ads, it's easy to pull that at home, at work or on the go. country, city or within a specific campaign into Microsoft Advertising. distance. Keep costs in check https://ads.microsoft.com/[7/29/2020 4:09:35 PM] MicrosoftUSCA4 Advertising Appeal:| Search Engine Marketing19-1061 (SEM) & more Doc: 51 Filed: 08/13/2020 Pg: 2 of 5 Use our tools to help manage your campaigns and meet your advertising goals. -

Search Engine Marketing Combining Social Media, SEO and SEM
Search Engine Marketing Combining Social Media, SEO and SEM Search engine marketing (SEM) has evolved to become the most reliable strategy for reaching your target audience and driving conversions on the internet. It compels your market to visit your website; it boosts your company's exposure within your space; it positions your product as the solution to their problems. As a result, your sales go up. Your revenue and profit swell. Your ROI rises. And your business enjoys stronger branding and customer loyalty in the process. Search engine marketing (SEM) has evolved to become the most reliable strategy for reaching your target audience and driving conversions on the internet. It compels your market to visit your website; it boosts your company's exposure within your space; it positions your product as the solution to their problems. As a result, your sales go up. Your revenue and profit swell. Your ROI rises. And your business enjoys stronger branding and customer loyalty in the process. Why Search Engine Marketing Is Critical Search engine marketing blends SEO, pay-per-click advertising, and social media strategies to give your company a higher level of visibility within the search engines' listings. However, visibility without sales defeats the purpose. And therein lies the true value of SEM. Your marketing efforts must generate conversions in order to justify the investment. Conversions might include a prospect buying your product, signing up for your newsletter, or becoming your affiliate. It might include subscribing to a continuity program that generates monthly revenue. Search engine marketing not only allows your company to approach your audience, but it engages the conversation that is already occurring in their mind. -

Affiliate Marketing 19
Guide to buying Online Marketing services How to choose the right Online Marketing supplier for your business CONTENTS About Computer Weekly 4 About Approved Index 5 Introduction 6 Marketing through new media 7 Advertising 7 Viral marketing 7 Affiliate programmes 8 E-mail marketing 8 Leads generation services 8 Interdisciplinary overlap 9 PPC Advertising 10 Keyword PPC 10 Product PPC 11 Service PPC 11 Potential pitfalls 11 Too broad 12 Too specific 12 Overbidding 12 The target site 12 Invalid clicks 12 Benefits of PPC 13 Banner Advertising 14 Banner clicks/click-throughs 15 Banner page views 15 Click-Through Rate (CTR) 15 Cost per sale 16 Search Engine Marketing 18 Affiliate Marketing 19 2 Text links 20 Banners 20 Search box 21 E-mail Marketing 23 Newsletters 23 Advertisements 24 Customised e-mails 24 Spam 25 E-mail tracking 26 HTML and plain text 26 Viral Marketing 27 Pass-along 28 Incentivised viral 28 Undercover marketing 29 ‘Edgy’ gossip/buzz marketing 29 User-managed databases 29 Word of web 29 Word of e-mail 30 Word of IM 30 Reward for referrals 30 Mobile phones 30 Successful viral marketing 31 Choosing a marketing company 33 Your goals and budget 33 Range of services 34 Past performance and references 34 Techniques 35 Costs 36 Making the decision 36 Price guide 37 3 ABOUT COMPUTER WEEKLY ComputerWeekly.com is the number one online destination for senior IT decision-making professionals. It is dedicated to providing IT professionals with the best information, the best knowledge and the best range of solutions that will enable them to succeed in the industry. -
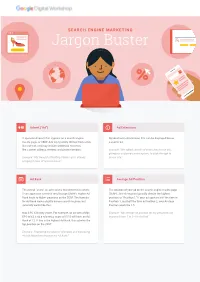
Jargon Buster
SEARCH ENGINE MARKETING Jargon Buster Advert (“Ad”) Ad Extensions A sponsored result that appears on a search engine Optional extra information that can be displayed below results page, or SERP. Ads are typically formed from a few a search ad. lines of text, and may include additional elements like a street address, reviews and phone numbers. Example: “We added sitelink ad extensions to our ads, giving our customers extra options to click-through to Example: “My ‘Beautiful Wedding Photos’ ad is already on our site.” bringing in tons of new business.” Ad Rank Average Ad Position The overall “score” an ad receives that determines where The position of your ad on the search engine results page it can appear on a search results page (SERP). Higher Ad (SERP). Search engines typically denote the highest Rank leads to higher positions on the SERP. The formula position as “Position 1.” If your ad appears half the time in for Ad Rank varies slightly across search engines, but Position 1, and half the time in Position 2, your Average generally works like this: Position would be 1.5. Max CPC X Quality Score. For example, an ad with a Max Example: “My average ad position for my pet photos ad CPC of £2 a nd a relevance score of 6/10 will have an Ad improved from 7 to 3—I’m thrilled!” Rank of 12. If this is the highest Ad Rank, this ad wins the top position on the SERP. Example: “Improving my adverts’ relevance and increasing my bid helped me improve my Ad Rank.” Actual Cost-per-Click (CPC) The true amount that a business pays to the search engine when their ad is clicked. -

Online and Mobile Advertising: Current Scenario, Emerging Trends, and Future Directions
Marketing Science Institute Special Report 07-206 Online and Mobile Advertising: Current Scenario, Emerging Trends, and Future Directions Venkatesh Shankar and Marie Hollinger © 2007 Venkatesh Shankar and Marie Hollinger MSI special reports are in draft form and are distributed online only for the benefit of MSI corporate and academic members. Reports are not to be reproduced or published, in any form or by any means, electronic or mechanical, without written permission. Online and Mobile Advertising: Current Scenario, Emerging Trends, and Future Directions Venkatesh Shankar Marie Hollinger* September 2007 * Venkatesh Shankar is Professor and Coleman Chair in Marketing and Director of the Marketing PhD. Program at the Mays Business School, Texas A&M University, College Station, TX 77843. Marie Hollinger is with USAA, San Antonio. The authors thank David Hobbs for assistance with data collection and article preparation. They also thank the MSI review team and Thomas Dotzel for helpful comments. Please address all correspondence to [email protected]. Online and Mobile Advertising: Current Scenario, Emerging Trends and Future Directions, Copyright © 2007 Venkatesh Shankar and Marie Hollinger. All rights reserved. Online and Mobile Advertising: Current Scenario, Emerging Trends, and Future Directions Abstract Online advertising expenditures are growing rapidly and are expected to reach $37 billion in the U.S. by 2011. Mobile advertising or advertising delivered through mobile devices or media is also growing substantially. Advertisers need to better understand the different forms, formats, and media associated with online and mobile advertising, how such advertising influences consumer behavior, the different pricing models for such advertising, and how to formulate a strategy for effectively allocating their marketing dollars to different online advertising forms, formats and media. -

SEM Marketing and Drawbacks
A Marketer’s Guide to A Marketer’s Guide To SEMSearch EngineMarketing Marketing www.topfloortech.com Index 03 Introduction 04 SEM- Why its Important 07 The Players: SEO and PPC 14 Benefits and Drawbacks 19 Working Together 24 Bringing It All Together 27 Glossary of Terminology 2725 S Moorland Rd, New Berlin, WI 53151 | 262-364-0010 | topfloortech.com Introduction from the President The world of advertising has evolved over the years on how to promote company brands, products, and services. As advertising on TV or in print magazines has become somewhat obsolete for capturing people's attention that leads to positive action. We live in a digital world and companies are moving towards digital marketing & advertising to draw people to their second home: the internet. With the progression of the internet and mobile technology, it's changed marketing strategy entirely. Today people rely heavily on search engines such as Google, Bing, and Yahoo to research and find products before making a purchase online or in-store. This eBook intends to provide insight into the paid and unpaid strategies of Search Engine Marketing (SEM). And what falls under its umbrella including Search Engine Optimization (SEO) and Pay- Per-Click (PPC). If you're new to SEM or unsure of the best approach, consider this guide as a strong starting point. But before we go deeper into SEM, it's best to start with what SEM is and why it's essential for companies to be utilizing it. 2725 S Moorland Rd, New Berlin, WI 53151 | 262-364-0010 | topfloortech.com Chapter 1: A Marketer’s Guide to Search Engine Marketing SEMWhy Marketingits Important www.topfloortech.com What is Search Engine Marketing? Search Engine Marketing (SEM) is the process of increasing traffic and visibility of your website, products, and services through a search engine. -

Evaluating Quality Score of New Ads
Evaluating Quality Score of New Ads Sohil Jain, Dr. Deepak Garg Computer Science and Engineering Department Thapar University Patiala, India 147001 Email: [email protected], [email protected] Abstract—Online or web advertisement(ad) is the prime has 50% probability to get clicked and it get decreased to 40%, source of income for search engines. Revenue generated through 30%, 20%, and 20% at the 2nd 3rd 4th position respectively web advertisement depends on the number of times user clicks on [4]. There is stiff competition between advertisers to get top ads. To increase revenue search engine selects best ad from pool slots. of ads. So, ads of good quality score has more chances of getting selected by search engine. It is very difficult to calculate quality The remainder of the paper is organized as follows: related of new ads as they have no historic information related of their work is explained in section II. Overall proposed method is performance. Hence, evaluation of quality score is crucial. In this discussed in subsequent section III. In section IV we describe paper, we have proposed straightforward yet efficient method in the implementation part of proposed method. In next section V terms of computation and space requirement to evaluate quality we evaluate our approach, present experimental results. Finally score of new ad. And also values of dominant parameters are we conclude our paper with a conclusion and future work. computed empirically, that quality web page should possess. Keywords GSP, online ad, new advertisements, web advertise- — II. RELATED WORK ment, quality score. A new advertisement auction mechanism based on GSP is proposed in [4] which consider the value of advertisement. -

Google/ Doubleclick REGULATION (EC) No 139/2004 MERGER PROCEDURE Article 8(1)
EN This text is made available for information purposes only. A summary of this decision is published in all Community languages in the Official Journal of the European Union. Case No COMP/M.4731 – Google/ DoubleClick Only the English text is authentic. REGULATION (EC) No 139/2004 MERGER PROCEDURE Article 8(1) Date: 11-03-2008 COMMISSION OF THE EUROPEAN COMMUNITIES Brussels, 11/03/2008 C(2008) 927 final PUBLIC VERSION COMMISSION DECISION of 11/03/2008 declaring a concentration to be compatible with the common market and the functioning of the EEA Agreement (Case No COMP/M.4731 – Google/ DoubleClick) (Only the English text is authentic) Table of contents 1 INTRODUCTION .....................................................................................................4 2 THE PARTIES...........................................................................................................5 3 THE CONCENTRATION.........................................................................................6 4 COMMUNITY DIMENSION ...................................................................................6 5 MARKET DESCRIPTION......................................................................................6 6 RELEVANT MARKETS.........................................................................................17 6.1. Relevant product markets ............................................................................17 6.1.1. Provision of online advertising space.............................................17 6.1.2. Intermediation in -

An Empirical Analysis of Search Engine Advertising: Sponsored Search in Electronic Markets
University of Pennsylvania ScholarlyCommons Operations, Information and Decisions Papers Wharton Faculty Research 10-2009 An Empirical Analysis of Search Engine Advertising: Sponsored Search in Electronic Markets Anindya Ghose University of Pennsylvania Sha Yang Follow this and additional works at: https://repository.upenn.edu/oid_papers Part of the E-Commerce Commons, and the Management Sciences and Quantitative Methods Commons Recommended Citation Ghose, A., & Yang, S. (2009). An Empirical Analysis of Search Engine Advertising: Sponsored Search in Electronic Markets. Management Science, 55 (10), 1605-1622. http://dx.doi.org/10.1287/ mnsc.1090.1054 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/oid_papers/159 For more information, please contact [email protected]. An Empirical Analysis of Search Engine Advertising: Sponsored Search in Electronic Markets Abstract The phenomenon of sponsored search advertising—where advertisers pay a fee to Internet search engines to be displayed alongside organic (nonsponsored) Web search results—is gaining ground as the largest source of revenues for search engines. Using a unique six-month panel data set of several hundred keywords collected from a large nationwide retailer that advertises on Google, we empirically model the relationship between different sponsored search metrics such as click-through rates, conversion rates, cost per click, and ranking of advertisements. Our paper proposes a novel framework to better understand the factors that drive differences in these metrics. We use a hierarchical Bayesian modeling framework and estimate the model using Markov Chain Monte Carlo methods. Using a simultaneous equations model, we quantify the relationship between various keyword characteristics, position of the advertisement, and the landing page quality score on consumer search and purchase behavior as well as on advertiser's cost per click and the search engine's ranking decision. -

Complaint and Request ) for Inquiry and Injunctive Relief ) Concerning Unfair ) and Deceptive ) Online Marketing Practices ) ______)
1 November 2006 ______________________________ ) Complaint and Request ) for Inquiry and Injunctive Relief ) Concerning Unfair ) and Deceptive ) Online Marketing Practices ) ______________________________) Deborah Platt Majoras, Chairman Room 440 Federal Trade Commission 600 Pennsylvania Avenue, N.W. Washington, D.C. 20580 Commissioner Pamela Jones Harbour Federal Trade Commission Room 326 600 Pennsylvania Ave, NW Washington, DC 20580 Commissioner Jon D. Leibowitz Federal Trade Commission Room 340 600 Pennsylvania Ave, NW Washington, DC 20580 Commissioner William E. Kovacic Room 540 600 Pennsylvania Ave, NW Washington, DC 20580 Commissioner J. Thomas Rosch Room 528 600 Pennsylvania Ave, NW Washington, DC 20580 Dear Chairman Majoras: The online marketplace, which now accounts for over $100 billion in U.S. e-commerce 1 sales annually, has evolved rapidly over the past decade.1 The policies governing consumer privacy on the Internet have failed to keep pace with the developments that continue to re-shape the online world, however. Privacy policies designed for a largely static, text-based World Wide Web offer little protection in the dynamic Web of the present, in which both rich-media content, and the array of sophisticated marketing technologies designed to support that content, are assembled and re-assembled on the fly, customized and targeted for the user. Many of these data collection techniques, automated and operating in real time, are based on sophisticated algorithms that analyze user behavior online—down to the level of "micro-actions"—and shape content and advertising accordingly. For example, as Touch Clarity (a developer of consumer profiling software tools) explains, its Behavioral Targeting technology "is essentially … an automated process of intelligent listening and responding, working with each individual visitor, based upon everything they have expressed through their click-stream interactions … to-date.