Regular Expressions and Grammars
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nooj Computational Devices Max Silberztein
NooJ Computational Devices Max Silberztein To cite this version: Max Silberztein. NooJ Computational Devices. Formalising Natural Languages With NooJ, Jun 2012, Paris, France. hal-02435921 HAL Id: hal-02435921 https://hal.archives-ouvertes.fr/hal-02435921 Submitted on 11 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. NOOJ COMPUTATIONAL DEVICES MAX SILBERZTEIN Introduction NooJ’s linguistic development environment provides tools for linguists to construct linguistic resources that formalize 7 types of linguistic phenomena: typography, orthography, inflectional and derivational morphology, local and structural syntax, and semantics. NooJ also provides a set of parsers that can process any linguistic resource for these 7 types, and apply it to any corpus of texts in order to extract examples, annotate matching sequences, perform statistical analyses, etc.1 NooJ’s approach to Linguistics is peculiar in the world of Computational Linguistics: instead of constructing a large single grammar to describe a particular natural language (e.g. “a grammar of English”), NooJ users typically construct, edit, test and maintain a large number of local (small) grammars; for instance, there is a grammar that describes how to conjugate the verb to be, another grammar that describes how to state a date in English, another grammar that describes the heads of Noun Phrases, etc. -

Theory of Computer Science
Theory of Computer Science MODULE-1 Alphabet A finite set of symbols is denoted by ∑. Language A language is defined as a set of strings of symbols over an alphabet. Language of a Machine Set of all accepted strings of a machine is called language of a machine. Grammar Grammar is the set of rules that generates language. CHOMSKY HIERARCHY OF LANGUAGES Type 0-Language:-Unrestricted Language, Accepter:-Turing Machine, Generetor:-Unrestricted Grammar Type 1- Language:-Context Sensitive Language, Accepter:- Linear Bounded Automata, Generetor:-Context Sensitive Grammar Type 2- Language:-Context Free Language, Accepter:-Push Down Automata, Generetor:- Context Free Grammar Type 3- Language:-Regular Language, Accepter:- Finite Automata, Generetor:-Regular Grammar Finite Automata Finite Automata is generally of two types :(i)Deterministic Finite Automata (DFA)(ii)Non Deterministic Finite Automata(NFA) DFA DFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. Σ is a finite set of symbols, called the alphabet of the automaton. δ is the transition function, that is, δ: Q × Σ → Q. q0 is the start state, that is, the state of the automaton before any input has been processed, where q0 Q. F is a set of states of Q (i.e. F Q) called accept states or Final States 1. Construct a DFA that accepts set of all strings over ∑={0,1}, ending with 00 ? 1 0 A B S State/Input 0 1 1 A B A 0 B C A 1 * C C A C 0 2. Construct a DFA that accepts set of all strings over ∑={0,1}, not containing 101 as a substring ? 0 1 1 A B State/Input 0 1 S *A A B 0 *B C B 0 0,1 *C A R C R R R R 1 NFA NFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. -

Grammars (Cfls & Cfgs) Reading: Chapter 5
Context-Free Languages & Grammars (CFLs & CFGs) Reading: Chapter 5 1 Not all languages are regular So what happens to the languages which are not regular? Can we still come up with a language recognizer? i.e., something that will accept (or reject) strings that belong (or do not belong) to the language? 2 Context-Free Languages A language class larger than the class of regular languages Supports natural, recursive notation called “context- free grammar” Applications: Context- Parse trees, compilers Regular free XML (FA/RE) (PDA/CFG) 3 An Example A palindrome is a word that reads identical from both ends E.g., madam, redivider, malayalam, 010010010 Let L = { w | w is a binary palindrome} Is L regular? No. Proof: N N (assuming N to be the p/l constant) Let w=0 10 k By Pumping lemma, w can be rewritten as xyz, such that xy z is also L (for any k≥0) But |xy|≤N and y≠ + ==> y=0 k ==> xy z will NOT be in L for k=0 ==> Contradiction 4 But the language of palindromes… is a CFL, because it supports recursive substitution (in the form of a CFG) This is because we can construct a “grammar” like this: Same as: 1. A ==> A => 0A0 | 1A1 | 0 | 1 | Terminal 2. A ==> 0 3. A ==> 1 Variable or non-terminal Productions 4. A ==> 0A0 5. A ==> 1A1 How does this grammar work? 5 How does the CFG for palindromes work? An input string belongs to the language (i.e., accepted) iff it can be generated by the CFG G: Example: w=01110 A => 0A0 | 1A1 | 0 | 1 | G can generate w as follows: Generating a string from a grammar: 1. -

Cs 61A/Cs 98-52
CS 61A/CS 98-52 Mehrdad Niknami University of California, Berkeley Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 1 / 23 Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ -

Use Perl Regular Expressions in SAS® Shuguang Zhang, WRDS, Philadelphia, PA
NESUG 2007 Programming Beyond the Basics Use Perl Regular Expressions in SAS® Shuguang Zhang, WRDS, Philadelphia, PA ABSTRACT Regular Expression (Regexp) enhance search and replace operations on text. In SAS®, the INDEX, SCAN and SUBSTR functions along with concatenation (||) can be used for simple search and replace operations on static text. These functions lack flexibility and make searching dynamic text difficult, and involve more function calls. Regexp combines most, if not all, of these steps into one expression. This makes code less error prone, easier to maintain, clearer, and can improve performance. This paper will discuss three ways to use Perl Regular Expression in SAS: 1. Use SAS PRX functions; 2. Use Perl Regular Expression with filename statement through a PIPE such as ‘Filename fileref PIPE 'Perl programm'; 3. Use an X command such as ‘X Perl_program’; Three typical uses of regular expressions will also be discussed and example(s) will be presented for each: 1. Test for a pattern of characters within a string; 2. Replace text; 3. Extract a substring. INTRODUCTION Perl is short for “Practical Extraction and Report Language". Larry Wall Created Perl in mid-1980s when he was trying to produce some reports from a Usenet-Nes-like hierarchy of files. Perl tries to fill the gap between low-level programming and high-level programming and it is easy, nearly unlimited, and fast. A regular expression, often called a pattern in Perl, is a template that either matches or does not match a given string. That is, there are an infinite number of possible text strings. -

Lecture 18: Theory of Computation Regular Expressions and Dfas
Introduction to Theoretical CS Lecture 18: Theory of Computation Two fundamental questions. ! What can a computer do? ! What can a computer do with limited resources? General approach. Pentium IV running Linux kernel 2.4.22 ! Don't talk about specific machines or problems. ! Consider minimal abstract machines. ! Consider general classes of problems. COS126: General Computer Science • http://www.cs.Princeton.EDU/~cos126 2 Why Learn Theory In theory . Regular Expressions and DFAs ! Deeper understanding of what is a computer and computing. ! Foundation of all modern computers. ! Pure science. ! Philosophical implications. a* | (a*ba*ba*ba*)* In practice . ! Web search: theory of pattern matching. ! Sequential circuits: theory of finite state automata. a a a ! Compilers: theory of context free grammars. b b ! Cryptography: theory of computational complexity. 0 1 2 ! Data compression: theory of information. b "In theory there is no difference between theory and practice. In practice there is." -Yogi Berra 3 4 Pattern Matching Applications Regular Expressions: Basic Operations Test if a string matches some pattern. Regular expression. Notation to specify a set of strings. ! Process natural language. ! Scan for virus signatures. ! Search for information using Google. Operation Regular Expression Yes No ! Access information in digital libraries. ! Retrieve information from Lexis/Nexis. Concatenation aabaab aabaab every other string ! Search-and-replace in a word processors. cumulus succubus Wildcard .u.u.u. ! Filter text (spam, NetNanny, Carnivore, malware). jugulum tumultuous ! Validate data-entry fields (dates, email, URL, credit card). aa Union aa | baab baab every other string ! Search for markers in human genome using PROSITE patterns. aa ab Closure ab*a abbba ababa Parse text files. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Regular Languages and Finite Automata for Part IA of the Computer Science Tripos
N Lecture Notes on Regular Languages and Finite Automata for Part IA of the Computer Science Tripos Prof. Andrew M. Pitts Cambridge University Computer Laboratory c 2012 A. M. Pitts Contents Learning Guide ii 1 Regular Expressions 1 1.1 Alphabets,strings,andlanguages . .......... 1 1.2 Patternmatching................................. .... 4 1.3 Somequestionsaboutlanguages . ....... 6 1.4 Exercises....................................... .. 8 2 Finite State Machines 11 2.1 Finiteautomata .................................. ... 11 2.2 Determinism, non-determinism, and ε-transitions. .. .. .. .. .. .. .. .. .. 14 2.3 Asubsetconstruction . .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..... 17 2.4 Summary ........................................ 20 2.5 Exercises....................................... .. 20 3 Regular Languages, I 23 3.1 Finiteautomatafromregularexpressions . ............ 23 3.2 Decidabilityofmatching . ...... 28 3.3 Exercises....................................... .. 30 4 Regular Languages, II 31 4.1 Regularexpressionsfromfiniteautomata . ........... 31 4.2 Anexample ....................................... 32 4.3 Complementand intersectionof regularlanguages . .............. 34 4.4 Exercises....................................... .. 36 5 The Pumping Lemma 39 5.1 ProvingthePumpingLemma . .... 40 5.2 UsingthePumpingLemma . ... 41 5.3 Decidabilityoflanguageequivalence . ........... 44 5.4 Exercises....................................... .. 45 6 Grammars 47 6.1 Context-freegrammars . ..... 47 6.2 Backus-NaurForm ................................ -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
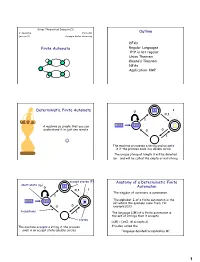
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Perl Regular Expressions Tip Sheet Functions and Call Routines
– Perl Regular Expressions Tip Sheet Functions and Call Routines Basic Syntax Advanced Syntax regex-id = prxparse(perl-regex) Character Behavior Character Behavior Compile Perl regular expression perl-regex and /…/ Starting and ending regex delimiters non-meta Match character return regex-id to be used by other PRX functions. | Alternation character () Grouping {}[]()^ Metacharacters, to match these pos = prxmatch(regex-id | perl-regex, source) $.|*+?\ characters, override (escape) with \ Search in source and return position of match or zero Wildcards/Character Class Shorthands \ Override (escape) next metacharacter if no match is found. Character Behavior \n Match capture buffer n Match any one character . (?:…) Non-capturing group new-string = prxchange(regex-id | perl-regex, times, \w Match a word character (alphanumeric old-string) plus "_") Lazy Repetition Factors Search and replace times number of times in old- \W Match a non-word character (match minimum number of times possible) string and return modified string in new-string. \s Match a whitespace character Character Behavior \S Match a non-whitespace character *? Match 0 or more times call prxchange(regex-id, times, old-string, new- \d Match a digit character +? Match 1 or more times string, res-length, trunc-value, num-of-changes) Match a non-digit character ?? Match 0 or 1 time Same as prior example and place length of result in \D {n}? Match exactly n times res-length, if result is too long to fit into new-string, Character Classes Match at least n times trunc-value is set to 1, and the number of changes is {n,}? Character Behavior Match at least n but not more than m placed in num-of-changes. -

Formal Language and Automata Theory (CS21004)
Context Free Grammar Normal Forms Derivations and Ambiguities Pumping lemma for CFLs PDA Parsing CFL Properties Formal Language and Automata Theory (CS21004) Soumyajit Dey CSE, IIT Kharagpur Context Free Formal Language and Automata Theory Grammar (CS21004) Normal Forms Derivations and Ambiguities Pumping lemma Soumyajit Dey for CFLs CSE, IIT Kharagpur PDA Parsing CFL Properties DPDA, DCFL Membership CSL Soumyajit Dey CSE, IIT Kharagpur Formal Language and Automata Theory (CS21004) Context Free Grammar Normal Forms Derivations and Ambiguities Pumping lemma for CFLs PDA Parsing CFL Properties Formal Language and Automata Announcements Theory (CS21004) Soumyajit Dey CSE, IIT Kharagpur Context Free Grammar Normal Forms Derivations and The slide is just a short summary Ambiguities Follow the discussion and the boardwork Pumping lemma for CFLs Solve problems (apart from those we dish out in class) PDA Parsing CFL Properties DPDA, DCFL Membership CSL Soumyajit Dey CSE, IIT Kharagpur Formal Language and Automata Theory (CS21004) Context Free Grammar Normal Forms Derivations and Ambiguities Pumping lemma for CFLs PDA Parsing CFL Properties Formal Language and Automata Table of Contents Theory (CS21004) Soumyajit Dey 1 Context Free Grammar CSE, IIT Kharagpur 2 Normal Forms Context Free Grammar 3 Derivations and Ambiguities Normal Forms 4 Derivations and Pumping lemma for CFLs Ambiguities 5 Pumping lemma PDA for CFLs 6 Parsing PDA Parsing 7 CFL Properties CFL Properties DPDA, DCFL 8 DPDA, DCFL Membership 9 Membership CSL 10 CSL Soumyajit Dey CSE,