SLF: Fuzzing Without Valid Seed Inputs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 8 Installing, Managing, and Removing User-Space Components
Red Hat Enterprise Linux 8 Installing, managing, and removing user-space components An introduction to AppStream and BaseOS in Red Hat Enterprise Linux 8 Last Updated: 2021-06-25 Red Hat Enterprise Linux 8 Installing, managing, and removing user-space components An introduction to AppStream and BaseOS in Red Hat Enterprise Linux 8 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. -
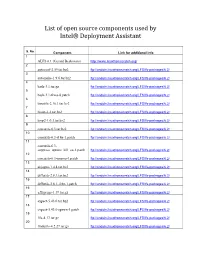
List of Open Source Components Used by Intel® Deployment Assistant
List of open source components used by Intel® Deployment Assistant S. No Component Link for additional info 1 ALFS 6.1 (Gerard Beekmans) http://www.linuxfromscratch.org/ 2 autoconf-2.59.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 3 automake-1.9.6.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 4 bash-3.1.tar.gz ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 5 bash-3.1-fixes-8.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 6 binutils-2.16.1.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 7 bison-2.2.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 8 bzip2-1.0.3.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 9 coreutils-6.3.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 10 coreutils-6.3-i18n-1.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 11 coreutils-6.3- suppress_uptime_kill_su-1.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 12 coreutils-6.3-uname-1.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 13 dejagnu-1.4.4.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 14 diffutils-2.8.1.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 15 diffutils-2.8.1-i18n-1.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 16 e2fsprogs-1.39.tar.gz ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 17 expect-5.43.0.tar.bz2 ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ 18 expect-5.43.0-spawn-1.patch ftp://anduin.linuxfromscratch.org/LFS/lfs-packages/6.2/ -

Troubleshooting Guide
Java Platform, Standard Edition Troubleshooting Guide Release 9 E61074-05 October 2017 Java Platform, Standard Edition Troubleshooting Guide, Release 9 E61074-05 Copyright © 1995, 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

Licensing Information User Manual Release 8.0 E65472-04
Oracle® Communications Calendar Server Licensing Information User Manual Release 8.0 E65472-04 March 2021 Copyright © 2000, 2021, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government. -

Zip Plugin 1.1 Read and Write Zip Archives with Hollywood
Zip Plugin 1.1 Read and write zip archives with Hollywood Andreas Falkenhahn i Table of Contents 1 General information::::::::::::::::::::::::::::: 1 1.1 Introduction :::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Terms and conditions ::::::::::::::::::::::::::::::::::::::::::: 1 1.3 Requirements::::::::::::::::::::::::::::::::::::::::::::::::::: 2 1.4 Installation ::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 2 About zip.hwp ::::::::::::::::::::::::::::::::::: 3 2.1 Credits ::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.2 Frequently asked questions:::::::::::::::::::::::::::::::::::::: 3 2.3 Known issues ::::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.4 Future:::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 2.5 History ::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 3 Usage ::::::::::::::::::::::::::::::::::::::::::::: 5 3.1 Activating the plugin ::::::::::::::::::::::::::::::::::::::::::: 5 3.2 Zip archives as directories::::::::::::::::::::::::::::::::::::::: 5 3.3 Extracting files ::::::::::::::::::::::::::::::::::::::::::::::::: 6 3.4 Zip archive basics::::::::::::::::::::::::::::::::::::::::::::::: 6 3.5 Creating zip archives ::::::::::::::::::::::::::::::::::::::::::: 7 3.6 Linking files :::::::::::::::::::::::::::::::::::::::::::::::::::: 7 4 Function reference::::::::::::::::::::::::::::::: 9 4.1 zip.AddDirectory ::::::::::::::::::::::::::::::::::::::::::::::: 9 4.2 zip.AddFile::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 4.3 zip.CloseArchive::::::::::::::::::::::::::::::::::::::::::::::: -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

Living Off the Land
Software Assurance Tips A product of the Software Assurance Tips Team[2] Jon Hood Monday 21st June, 2021 1 1 Living off the Land Updated Friday 6th August, 2021 Living off the Land (LotL) refers to using the tools, scripts, libraries, and binaries that arenative and pre-installed with an environment.[6, p. 299] Attackers use the existing tools of their exploited environment to decrease their footprint and avoid detection, often blending in by using legitimate tools and administrative functions in a malicious way.[1, p. 45] Nevertheless, developers can use LotL concepts to decrease the attackable footprint of their software as a mitigation strategy against attacks as well! 1.1 LotL: An Attacker’s Perspective When attacking an environment, penetration testing teams often attempt to take an inventory of what is available to see what can be utilized to establish persistence and pivot in the environment without detection. If the attacker has to install specialized tools and packages, intrusion detection and prevention systems can be configured to look for those packages as part of a defense-in-depth mitigation strategy. 1.2 LotL: A Defender’s Perspective Defensive (blue) teams should be familiar with the attacks and threats posed by penetration testing (red) teams. In 2013, the DoD used the following definition of Software Assurance: “the level of confidence that software functions as intended and is free of vulnerabilities, either intentionally or unintentionally designed or inserted as part of the software, throughout the life cycle.”[5, p. 255 §933.e.2] In 2017, the Office for the Secretary of Defense clarified the definition of “functions as intended” to mean “only functions as intended” by showing confidently that the software meets functionality and test coverage requirements and also “does not perform unrequired functions.”[4, p. -

Vorlage Für Dokumente Bei AI
OSS Disclosure Document Date: 27-Apr-2018 CM-AI/PJ-CC OSS Licenses used in Suzuki Project Page 1 Table of content 1 Overview ..................................................................................................................... 11 2 OSS Licenses used in the project ................................................................................... 11 3 Package details for OSS Licenses usage ........................................................................ 12 3.1 7 Zip - LZMA SDK ............................................................................................................. 12 3.2 ACL 2.2.51 ...................................................................................................................... 12 3.3 Alsa Libraries 1.0.27.2 ................................................................................................... 12 3.4 AES - Advanced Encryption Standard 1.0 ......................................................................... 12 3.5 Alsa Plugins 1.0.26 ........................................................................................................ 13 3.6 Alsa Utils 1.0.27.2 ......................................................................................................... 13 3.7 APMD 3.2.2 ................................................................................................................... 13 3.8 Atomic_ops .................................................................................................................... 13 3.9 Attr 2.4.46 ................................................................................................................... -

Page No. I Certification Test Plan T71379.01
Page No. i Certification Test Plan T71379.01 REPORT NO. Test Plan No. T71379.01 DATE February 13, 2014 PAGE OR PARAGRAPH REV DATE DESCRIPTION OF CHANGES AFFECTED --- 02-13-14 Entire Document Original Release WYLE LABORATORIES, INC. Huntsville Facility Page No. TOC-1 of 2 Certification Test Plan T71379.01 TABLE OF CONTENTS 1. INTRODUCTION ............................................................................................................................... 1 1.1 Established Baseline ................................................................................................................ 1 1.2 Scope of Modification .............................................................................................................. 2 1.3 Initial Assessment .................................................................................................................... 2 1.4 References ................................................................................................................................ 3 1.5 Terms and Abbreviations ......................................................................................................... 4 1.6 Testing Responsibilities. .......................................................................................................... 6 1.6.1 Project Schedule .......................................................................................................... 6 1.6.2 Test Case Development ............................................................................................. -

Ten Thousand Security Pitfalls: the ZIP File Format
Ten thousand security pitfalls: The ZIP file format. Gynvael Coldwind @ Technische Hochschule Ingolstadt, 2018 About your presenter (among other things) All opinions expressed during this presentation are mine and mine alone, and not those of my barber, my accountant or my employer. What's on the menu Also featuring: Steganograph 1. What's ZIP used for again? 2. What can be stored in a ZIP? y a. Also, file names 3. ZIP format 101 and format repair 4. Legacy ZIP encryption 5. ZIP format and multiple personalities 6. ZIP encryption and CRC32 7. Miscellaneous, i.e. all the things not mentioned so far. Or actually, hacking a "secure cloud disk" website. EDITORIAL NOTE Everything in this color is a quote from the official ZIP specification by PKWARE Inc. The specification is commonly known as APPNOTE.TXT https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT Cyber Secure CloudDisk Where is ZIP used? .zip files, obviously Default ZIP file icon from Microsoft Windows 10's Explorer And also... Open Packaging Conventions: .3mf, .dwfx, .cddx, .familyx, .fdix, .appv, .semblio, .vsix, .vsdx, .appx, .appxbundle, .cspkg, .xps, .nupkg, .oxps, .jtx, .slx, .smpk, .odt, .odp, .ods, ... .scdoc, (OpenDocument) and Offixe Open XML formats: .docx, .pptx, .xlsx https://en.wikipedia.org/wiki/Open_Packaging_Conventions And also... .war (Web application archive) .rar (not THAT .rar) .jar (resource adapter archive) (Java Archive) .ear (enterprise archive) .sar (service archive) .par (Plan Archive) .kar (Karaf ARchive) https://en.wikipedia.org/wiki/JAR_(file_format) -

1. Why POCS.Key
Symptoms of Complexity Prof. George Candea School of Computer & Communication Sciences Building Bridges A RTlClES A COMPUTER SCIENCE PERSPECTIVE OF BRIDGE DESIGN What kinds of lessonsdoes a classical engineering discipline like bridge design have for an emerging engineering discipline like computer systems Observation design?Case-study editors Alfred Spector and David Gifford consider the • insight and experienceof bridge designer Gerard Fox to find out how strong the parallels are. • bridges are normally on-time, on-budget, and don’t fall ALFRED SPECTORand DAVID GIFFORD • software projects rarely ship on-time, are often over- AS Gerry, let’s begin with an overview of THE DESIGN PROCESS bridges. AS What is the procedure for designing and con- GF In the United States, most highway bridges are budget, and rarely work exactly as specified structing a bridge? mandated by a government agency. The great major- GF It breaks down into three phases: the prelimi- ity are small bridges (with spans of less than 150 nay design phase, the main design phase, and the feet) and are part of the public highway system. construction phase. For larger bridges, several alter- There are fewer large bridges, having spans of 600 native designs are usually considered during the Blueprints for bridges must be approved... feet or more, that carry roads over bodies of water, preliminary design phase, whereas simple calcula- • gorges, or other large obstacles. There are also a tions or experience usually suffices in determining small number of superlarge bridges with spans ap- the appropriate design for small bridges. There are a proaching a mile, like the Verrazzano Narrows lot more factors to take into account with a large Bridge in New Yor:k. -

Sanrazor: Reducing Redundant Sanitizer Checks in C/C++ Programs
SANRAZOR: Reducing Redundant Sanitizer Checks in C/C++ Programs Jiang Zhang, University of Southern California; Shuai Wang, HKUST; Manuel Rigger, Pinjia He, and Zhendong Su, ETH Zurich https://www.usenix.org/conference/osdi21/presentation/zhang This paper is included in the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation. July 14–16, 2021 978-1-939133-22-9 Open access to the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX. SANRAZOR: Reducing Redundant Sanitizer Checks in C/C++ Programs Jiang Zhang1 Shuai Wang2∗ Manuel Rigger3 Pingjia He3 Zhendong Su3 University of Southern California1 HKUST2 ETH Zurich3 Abstract Sanitizers are commonly used by developers to find bugs Sanitizers detect unsafe actions such as invalid memory ac- before software deployment. In principle, they could also be cesses by inserting checks that are validated during a pro- used in deployed software, where they terminate program gram’s execution. Despite their extensive use for debugging executions to prevent vulnerabilities from being exploited. and vulnerability discovery, sanitizer checks often induce a In practice, however, the high runtime overhead of sanitizers high runtime cost. One important reason for the high cost is, inhibits their adoption in this application scenario [33, 40]. as we observe in this paper, that many sanitizer checks are For example, our study on SPEC CPU2006 benchmarks [34] redundant — the same safety property is repeatedly checked shows that the geometric mean overheads induced by Ad- — leading to unnecessarily wasted computing resources. dressSanitizer (ASan) [32] and UndefinedBehaviorSanitizer (UBSan) [8] are, respectively, 73.8% and 160.1% (cf.