Chinese Calligraphy: Character Style Recognition Based on Full-Page Document
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

INSCRIPTIONS on CHINESE PAINTINGS and SCHOLAR OBJECTS EXHIBITION DATES: SEPTEMBER 10 - 17, 2010 GALLERY HOURS: MONDAY – FRIDAY, 11 – 5 Or by APPOINTMENT
CHINA 2 0 0 0 F I N E A R T LITERATI MUSING: INSCRIPTIONS ON CHINESE PAINTINGS AND SCHOLAR OBJECTS EXHIBITION DATES: SEPTEMBER 10 - 17, 2010 GALLERY HOURS: MONDAY – FRIDAY, 11 – 5 or BY APPOINTMENT China 2000 Fine Art takes great pleasure in presenting “Literati Musing: Inscriptions on Chinese Paintings and Scholar Objects” which will be shown in the gallery at 434A East 75th Street in Manhattan and in an online exhibition on our website at China2000FineArt.com. Like the contemporary twitter, ancient inscriptions on Chinese art were the momentary (and now art historically monumental) thoughts about society, relationships, politics, and aesthetics of the literati. For our exhibition, we have gathered together objects for the scholar’s desk and Chinese paintings that bear inscriptions by eminent scholars and calligraphers of Chinese history. Their words literally etched in stone or wood or written with indelible ink on paper provide clues to where they were at particular times in their lives and offer their knowledge about the object or the painting upon which they inscribe their thoughts. Just to illustrate a few of the exhibits, Deng Shiru, a very important calligrapher and seal carver from the 18th century, has carved a Ming dynasty poem on a soapstone seal-paste box, Ding Jing, another important 18th century calligrapher, has carved a Tang dynasty poem on an Anhui inkstone, Chang Dai-chien, the great 20th century painter, has inscribed a painting by a wonderful artist whose works are not generally known but who was with him in Dunhuang in 1941, Lu Yanshao, another famous name in 20th century Chinese art, has inscribed his thoughts on a western style painting of his contemporary, Wu Hufan has given authentication to a painting by Xiao Junxian, and Pu Ru, a great artist and member of the Manchu imperial family, has inscribed a poem on a masterpiece painting by his student, An Ho. -

Real-Time Image-Based Chinese Ink Painting Rendering Lixing Dong
Real-time image-based chinese ink painting rendering Lixing Dong, Shufang Lu & Xiaogang Jin Multimedia Tools and Applications An International Journal ISSN 1380-7501 Multimed Tools Appl DOI 10.1007/s11042-012-1126-9 1 23 Your article is protected by copyright and all rights are held exclusively by Springer Science+Business Media, LLC. This e-offprint is for personal use only and shall not be self- archived in electronic repositories. If you wish to self-archive your work, please use the accepted author’s version for posting to your own website or your institution’s repository. You may further deposit the accepted author’s version on a funder’s repository at a funder’s request, provided it is not made publicly available until 12 months after publication. 1 23 Author's personal copy Multimed Tools Appl DOI 10.1007/s11042-012-1126-9 Real-time image-based chinese ink painting rendering Lixing Dong · Shufang Lu · Xiaogang Jin © Springer Science+Business Media, LLC 2012 Abstract Chinese ink painting, also known as ink and wash painting, is a technically demanding art form. Creating Chinese ink paintings usually requires great skill, concentration, and years of training. This paper presents a novel real-time, automatic framework to convert images into Chinese ink painting style. Given an input image, we first construct its saliency map which captures the visual contents in perceptually salient regions. Next, the image is abstracted and its salient edges are calculated with the help of the saliency map. Then, the abstracted image is diffused by a non-physical ink diffusion process. -

Downloaded 4.0 License
86 Chapter 3 Chapter 3 Eloquent Stones Of the critical discourses that this book has examined, one feature is that works of art are readily compared to natural forms of beauty: bird song, a gush- ing river or reflections in water are such examples. Underlying such rhetorical devices is an ideal of art as non-art, namely that the work of art should appear so artless that it seems to have been made by nature in its spontaneous process of creation. Nature serves as the archetype (das Vorbild) of art. At the same time, the Song Dynasty also saw refined objects – such as flowers, tea or rocks – increasingly aestheticised, collected, classified, described, ranked and com- moditised. Works of connoisseurship on art or natural objects prospered alike. The hundred-some pu 譜 or lu 錄 works listed in the literature catalogue in the History of the Song (“Yiwenzhi” in Songshi 宋史 · 藝文志) are evenly divided between those on manmade and those on natural objects.1 Through such dis- cursive transformation, ‘natural beauty’ as a cultural construct curiously be- came the afterimage (das Nachbild) of art.2 In other words, when nature appears as the ideal of art, at the same time it discovers itself to be reshaped according to the image of art. As a case study of Song nature aesthetics, this chapter explores the multiple dimensions of meaning invested in Su Shi’s connoisseur discourse on rocks. Su Shi professed to be a rock lover. Throughout his life, he collected inkstones, garden rocks and simple pebbles. We are told, for instance, that a pair of rocks, called Qiuchi 仇池, accompanied him through his exiles to remote Huizhou and Hainan, even though most of his family members were left behind. -

Identification of the Proto-Inkstone by Organic Residue Analysis: a Case Study from the Changle Cemetery in China
Ren et al. Herit Sci (2018) 6:19 https://doi.org/10.1186/s40494-018-0184-3 RESEARCH ARTICLE Open Access Identifcation of the proto‑inkstone by organic residue analysis: a case study from the Changle Cemetery in China Meng Ren1,2, Renfang Wang3 and Yimin Yang2* Abstract The inkstone is a specifc writing implement in China that was popularized since the Han Dynasty (202 BC–AD 220). A rectangular/round grinding plate accompanied with a grinding stone is considered as a kind of proto-inkstone. How- ever, little scientifc investigation has been performed to support this hypothesis. In this paper, a micro-destructive approach, including Fourier transform infrared spectroscopy (FTIR), Raman spectroscopy and gas chromatography coupled with mass spectrometry (GC–MS), were employed to analyse the black residues on a grinding plate and a grinding stone excavated from the Changle Cemetery (202 BC–AD 8) in northwestern China. The FTIR and Raman analyses indicated that the residues were ancient ink. GC–MS analysis further identifed that the residues were pine- soot ink, based on the relative abundances of the main polycyclic aromatic hydrocarbons, as well as the detection of conifer biomarkers. The trace of animal glue was not detected in the residues; thus, the ink was possibly formed as small pellets and the small grinding stone was necessary to assist during the ink-grinding process. This study confrms that this set of stone implements is indeed an early type of inkstone, and ofers some insight into the co-evolution relationship between ink production and inkstone shapes. Keywords: Chinese inkstone, Shape, Pine-soot ink, Dehydroabietic acid Introduction and culture. -

Download Article (PDF)
International Conference on Contemporary Education, Social Sciences and Humanities (ICCESSH 2016) Discussion on Development of Lu Zhe Chengni Inkstone Yongmei Wu Shandong College of Arts Jinan, China 250001 Abstract—As one of the four famous inkstones of China, hometown of Confucius and it has excellent cultural tradition. Chengni inkstone’s popularity is nowhere near Duan inkstone, Pottery making in Zhegou area has a history of at least 5000 She inkstone and Tao inkstone. Besides, Chengni inkstone years. Generations of pottery makers are cultivated here and suffers many mishaps, from making a noise to declining, they have wide consensus and internal enthusiasm towards stopping firing, lose of technology and archaeology and after- development and research of Chengni inkstone. In late 1980s burning. During the intermittent process, Chengni inkstone fails and early 1990s, under the support of local government in to develop well. Until today, under the support of national Shandong, Mr. Shi Ke, a famous inkstone specialist and intangible cultural heritage, new research on and propulsion of sealing cutting specialist, and Mr. Yang Yuzhen organize development of Chengni inkstone appear in various places. Lu burning experiments in Zhegou town, Sishui county and Zhe Chengni inkstone is uniquely owned by Zhegou town, Sishui achieve success in 1991. It attracts general attention from county, Shandong province. It has strong local features and it is worth deeply researching. scholars and inkstone lovers both at home and abroad. When traveling in Japan, Gu Mu, vice president of national Chinese Keywords—Lu Zhe Chengni inkstone; development; People’s Political Consultative Conference at that time, gives innovation Lu Zhe Chengni inkstone to Japanese as a national gift. -
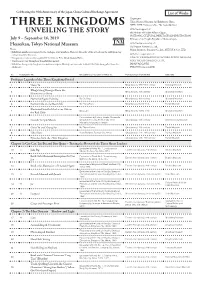
Three Kingdoms Unveiling the Story: List of Works
Celebrating the 40th Anniversary of the Japan-China Cultural Exchange Agreement List of Works Organizers: Tokyo National Museum, Art Exhibitions China, NHK, NHK Promotions Inc., The Asahi Shimbun With the Support of: the Ministry of Foreign Affairs of Japan, NATIONAL CULTURAL HERITAGE ADMINISTRATION, July 9 – September 16, 2019 Embassy of the People’s Republic of China in Japan With the Sponsorship of: Heiseikan, Tokyo National Museum Dai Nippon Printing Co., Ltd., Notes Mitsui Sumitomo Insurance Co.,Ltd., MITSUI & CO., LTD. ・Exhibition numbers correspond to the catalogue entry numbers. However, the order of the artworks in the exhibition may not necessarily be the same. With the cooperation of: ・Designation is indicated by a symbol ☆ for Chinese First Grade Cultural Relic. IIDA CITY KAWAMOTO KIHACHIRO PUPPET MUSEUM, ・Works are on view throughout the exhibition period. KOEI TECMO GAMES CO., LTD., ・ Exhibition lineup may change as circumstances require. Missing numbers refer to works that have been pulled from the JAPAN AIRLINES, exhibition. HIKARI Production LTD. No. Designation Title Excavation year / Location or Artist, etc. Period and date of production Ownership Prologue: Legends of the Three Kingdoms Period 1 Guan Yu Ming dynasty, 15th–16th century Xinxiang Museum Zhuge Liang Emerges From the 2 Ming dynasty, 15th century Shanghai Museum Mountains to Serve 3 Narrative Figure Painting By Qiu Ying Ming dynasty, 16th century Shanghai Museum 4 Former Ode on the Red Cliffs By Zhang Ruitu Ming dynasty, dated 1626 Tianjin Museum Illustrated -

Private Life and Social Commentary in the Honglou Meng
University of Pennsylvania ScholarlyCommons Honors Program in History (Senior Honors Theses) Department of History March 2007 Authorial Disputes: Private Life and Social Commentary in the Honglou meng Carina Wells [email protected] Follow this and additional works at: https://repository.upenn.edu/hist_honors Wells, Carina, "Authorial Disputes: Private Life and Social Commentary in the Honglou meng" (2007). Honors Program in History (Senior Honors Theses). 6. https://repository.upenn.edu/hist_honors/6 A Senior Thesis Submitted in Partial Fulfillment of the Requirements for Honors in History. Faculty Advisor: Siyen Fei This paper is posted at ScholarlyCommons. https://repository.upenn.edu/hist_honors/6 For more information, please contact [email protected]. Authorial Disputes: Private Life and Social Commentary in the Honglou meng Comments A Senior Thesis Submitted in Partial Fulfillment of the Requirements for Honors in History. Faculty Advisor: Siyen Fei This thesis or dissertation is available at ScholarlyCommons: https://repository.upenn.edu/hist_honors/6 University of Pennsylvania Authorial Disputes: Private Life and Social Commentary in the Honglou meng A senior thesis submitted in partial fulfillment of the requirements for Honors in History by Carina L. Wells Philadelphia, PA March 23, 2003 Faculty Advisor: Siyen Fei Honors Director: Julia Rudolph Contents Acknowledgements………………………………………………………………………...i Explanatory Note…………………………………………………………………………iv Dynasties and Periods……………………………………………………………………..v Selected Reign -

An Analysis of the Ways of Inheritance and Development of Duanyan Inkstone Culture
Volume 3, Issue 3, 2020 ISSN: 2617-9938 DOI: https://doi.org/10.31058/j.ad.2020.33006 An Analysis of the Ways of Inheritance and Development of Duanyan Inkstone Culture Xibin Wang1* 1 Academy of Fine Arts, Zhaoqing College, Zhaoqing, China Email Address [email protected] (Xibin Wang) *Correspondence: [email protected] Received: 6 June 2020; Accepted: 16 July 2020; Published: 9 August 2020 Abstract: In order to better inherit the Duanyan inkstone Culture, this article comparatively analyzes the characteristics, functions and limitations of the three main ways of the traditional mentorship inheritance, social public inheritance and school education inheritance. In the context of the new era, we should take the school education inheritance approach as the core, integrate all resources, and promote the inheritance and development of Duanyan inkstone Culture. Keywords: Duanyan Inkstone Culture, Inheritance and Development, Approach, Integration 1. Introduction Duanyan inkstone is an important part of Chinese traditional culture. It’s in the first batch of national-level non-material cultural heritage names with the approval of the State Council. It was rated as the “Top Ten Cultural Cards of Lingnan” by the People's Government of Guangdong Province. The historical mission of culture. But like many excellent traditional cultures, Duanyan inkstone Culture is also facing the urgent problem of how to survive and develop in the context of the new era. The State Council’s policy on the protection of intangible cultural heritage is “protection first, rescue first, rational use, and inheritance and development.” Among them, “inheritance and development” is a targeted protection policy for intangible cultural heritage, and its importance is self-evident. -

Chinese Writing and Calligraphy
CHINESE LANGUAGE LI Suitable for college and high school students and those learning on their own, this fully illustrated coursebook provides comprehensive instruction in the history and practical techniques of Chinese calligraphy. No previous knowledge of the language is required to follow the text or complete the lessons. The work covers three major areas:1) descriptions of Chinese characters and their components, including stroke types, layout patterns, and indications of sound and meaning; 2) basic brush techniques; and 3) the social, cultural, historical, and philosophical underpinnings of Chinese calligraphy—all of which are crucial to understanding and appreciating this art form. Students practice brush writing as they progress from tracing to copying to free-hand writing. Model characters are marked to indicate meaning and stroke order, and well-known model phrases are shown in various script types, allowing students to practice different calligraphic styles. Beginners will fi nd the author’s advice on how to avoid common pitfalls in writing brush strokes invaluable. CHINESE WRITING AND CALLIGRAPHY will be welcomed by both students and instructors in need of an accessible text on learning the fundamentals of the art of writing Chinese characters. WENDAN LI is associate professor of Chinese language and linguistics at the University of North Carolina at Chapel Hill. Cover illustration: Small Seal Script by Wu Rangzhi, Qing dynasty, and author’s Chinese writing brushes and brush stand. Cover design: Wilson Angel UNIVERSITY of HAWAI‘I PRESS Honolulu, Hawai‘i 96822-1888 LI-ChnsWriting_cvrMech.indd 1 4/19/10 4:11:27 PM Chinese Writing and Calligraphy Wendan Li Chinese Writing and Calligraphy A Latitude 20 Book University of Hawai‘i Press Honolulu © 2009 UNIVERSITY OF HAWai‘i Press All rights reserved 14â13â12â11â10â09ââââ6 â5â4â3â2â1 Library of Congress Cataloging-in-Publication Data Li, Wendan. -

Gagosian Gallery
artnet June 20, 2018 GAGOSIAN Meet Hao Liang, the Young Chinese Artist Whose Reboot of Ancient Ink Painting Has Become a Bona Fide Market Sensation The up-and-coming artist's dense, referential paintings have already sold out at Gagosian. Taylor Dafoe Hao Liang. ©�Hao Liang. Courtesy Gagosian. The powerhouse gallery Gagosian is not exactly the first place you would think to look to discover new talent. But walk into its Upper East Side location today and you’ll encounter the work of an artist you have likely never heard of—though you probably will soon. The 35-year- old Beijing-based artist Hao Liang is working to do nothing less than reinvent traditional Chinese ink wash painting. Though he is well known in China, his inaugural exhibition with Gagosian, “Portraits and Wonders,” on view until June 23, marks his first solo show in the United States. And it sold out before it even opened. Hao is bringing the ancient technique of ink wash painting, which is thousands of years old, into the 21st century with a heady mélange of art historical allusions and formal techniques that bridge Eastern and Western cultural symbols. The artist made a splash last year when his landscapes of the Hunan province painted on silk were included in the Venice Biennale’s central exhibition. He was one of the youngest artists in the show. As Hao continues to get international exposure, he could achieve in the market what he has already realized in his paintings—a link between the East and the West. “Understandably, Hao is better known in Asia than he is in the West, but we’re introducing his extraordinary practice to a wider and more global audience,” Nick Simunovic, the director of Gagosian Hong Kong, tells artnet News. -

PDF Download the Social Life of Inkstones Artisans and Scholars In
THE SOCIAL LIFE OF INKSTONES ARTISANS AND SCHOLARS IN EARLY QING CHINA 1ST EDITION PDF, EPUB, EBOOK Dorothy Ko | 9780295999180 | | | | | The Social Life of Inkstones Artisans and Scholars in Early Qing China 1st edition PDF Book More Details Wuyuan inkstones a. Ko explains the significance of this highly specialized art form. When the Manchu from the northeast conquered China in , they felt the urgent need to develop an influence on, and an amicable control over, the material and intellectual world of the Chinese literati. A master of her trade, Ko draws on artifacts and texts to unfurl Qing material, intellectual, and social life. Break This Down: Racialized Capitalism. Dorothy Ko is professor of history at Barnard College. Add to Basket New Condition: Neu. Lin Hang. Can you tell us about the research on which this new archive is based? Published by Univ of Washington Pr Sort order. Trivia About The Social Life o Very good in very good dust jacket. If you want to know more, the book is in the library: Ko, Dorothy. Download Free PDF. For those interested in material culture histories, Chinese art history or Chinese culture more broadly, this is a must-read. Can we detect traces of embroidery stitching techniques in the treatment of the right wing of the lower swallow? There are no discussion topics on this book yet. Published by University of Washington Press Jingdezhen was the capital of Chinese porcelain since the Ming dynasty but other sites of porcelain production included Dehua , known for their production of porcelain dolls in the both the Ming and Qing era. -

Stx********************************************************************* Reproductions Supplied by EDPS Are the Best Thatcan Bu Made from the Original Document
ED 332 925 SO 021 361 TITLE Yani: The Brush of Innocence. Teacher's Activity Packet, Grades One through rive. INSTITUTION Smithsonian Institution, Washington, DC. Arthur X. Sackler Gallery. PUB DATE 89 NOTE 81p. AVAILABLE FROMEducation Department, Arthur M. Sackler Gallery, Smithsonian Institution, Washington, DC 20560 (includes slide set). PUB TYPE Guides - Classroom Use - Instructional Materials (For Learner) (051)-- Guides - Classroom Use - Teaching Guides (For Teacher) (052) EDRS PRICE MF01/PC04 Plus Postage. DESCRIPTORS Aesthetic Education; *Art Appreciation; *Art Education; Artists; *Childrens Art; Chinese Culture; Creative Activities; *Cultural Activities; Early Childhood Education; Elementary Education; Enrichment Activities; Manuscript Writing (Handlettering); Painting (Visual Arts); *Poetry IDENTIFIERS *Wang (Yani) ABSTRACT This document presents a teaching package designed to introduce students in grades one through five to Chinese painting methods and equipment. Prepared in conjunction withan exhibition of paintings by child prodigy Wang Yani titled "The Brush of Innocence," the package consists of a teacher's activity plan unit, a slideset of art works by Wang Yani, an activity book for children, anda teacher evaluation form. The package is organized into five sections: (1) an introduction to the artist Wang Yani; (2)slides and discussion material about Wang Yani's paintings and the four treasures of the Chinese artist's studio (the inkstand, the inkstone, brush, and paper); (3) activities of students; (4) background information about Chinese painting for teachers; and (5) a list of places that sell Chinese painting materials. All but one of the slides presents works by Wang Yani who painted them between theages of five and eleven years old. Classroom activitiesare organized into two sections: the four treasures of the scholar's studio;and painting and poetry.