Standalone Containers with ATLAS Offline Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tradition and Innovation in Olympiodorus' "Orphic" Creation of Mankind Radcliffe .G Edmonds III Bryn Mawr College, [email protected]
Bryn Mawr College Scholarship, Research, and Creative Work at Bryn Mawr College Greek, Latin, and Classical Studies Faculty Research Greek, Latin, and Classical Studies and Scholarship 2009 A Curious Concoction: Tradition and Innovation in Olympiodorus' "Orphic" Creation of Mankind Radcliffe .G Edmonds III Bryn Mawr College, [email protected] Let us know how access to this document benefits ouy . Follow this and additional works at: http://repository.brynmawr.edu/classics_pubs Part of the Classics Commons Custom Citation Edmonds, Radcliffe .,G III. "A Curious Concoction: Tradition and Innovation in Olympiodorus' 'Orphic' Creation of Mankind." American Journal of Philology 130, no. 4 (2009): 511-532. This paper is posted at Scholarship, Research, and Creative Work at Bryn Mawr College. http://repository.brynmawr.edu/classics_pubs/79 For more information, please contact [email protected]. Radcliffe G. Edmonds III “A Curious Concoction: Tradition and Innovation in Olympiodorus' ‘Orphic’ Creation of Mankind” American Journal of Philology 130 (2009), pp. 511–532. A Curious Concoction: Tradition and Innovation in Olympiodorus' Creation of Mankind Olympiodorus' recounting (In Plat. Phaed. I.3-6) of the Titan's dismemberment of Dionysus and the subsequent creation of humankind has served for over a century as the linchpin of the reconstructions of the supposed Orphic doctrine of original sin. From Comparetti's first statement of the idea in his 1879 discussion of the gold tablets from Thurii, Olympiodorus' brief testimony has been the -

Report from the Fourth Artemis Project
FOR A PREVENTIVE BREAST CANCER VACCINE Fourth Annual Meeting March 7-10, 2014 I. INTRODUCTION A. BACKGROUND The National Breast Cancer Coalition (NBCC) is dedicated to ending breast cancer through the power of grassroots action and advocacy. In 2010, NBCC launched Breast Cancer Deadline 2020® to focus resources and efforts to the areas that will lead to the knowledge needed to end breast cancer. The research component of Breast Cancer Deadline 2020® includes the Artemis Project®, an advocate led mission driven approach of strategic summits, catalytic workshops, research action plans and collaborative efforts among various stakeholders. The Artemis Project ® focuses on two areas: Primary Prevention: How do we stop people from getting breast cancer? Prevention of Metastasis: How do we stop people from dying of breast cancer? Artemis Project®: Preventive Vaccine The 2011 report from the first annual meeting provides an overview of the project and a description of the focus areas. After the first annual meeting in March, 2011, NBCC contracted with Science Application International Corporation (SAIC) to help prepare a detailed strategic plan for the Artemis Project®, based on the outcomes of the annual meeting and follow-up interviews with attendees. This Project Plan was completed in December, 2011. Subsequently, NBCC issued a call for proposals to address initial steps in antigen identification. The report from the second annual meeting outlines the refined strategies developed for the early stages of the project, particularly around antigen identification and evaluation. Discussion during the third annual meeting focused on the specific tasks required within the next two years to remain on track for a vaccine product ready for clinical trials. -

Athena ΑΘΗΝΑ Zeus ΖΕΥΣ Poseidon ΠΟΣΕΙΔΩΝ Hades ΑΙΔΗΣ
gods ΑΠΟΛΛΩΝ ΑΡΤΕΜΙΣ ΑΘΗΝΑ ΔΙΟΝΥΣΟΣ Athena Greek name Apollo Artemis Minerva Roman name Dionysus Diana Bacchus The god of music, poetry, The goddess of nature The goddess of wisdom, The god of wine and art, and of the sun and the hunt the crafts, and military strategy and of the theater Olympian Son of Zeus by Semele ΕΡΜΗΣ gods Twin children ΗΦΑΙΣΤΟΣ Hermes of Zeus by Zeus swallowed his first Mercury Leto, born wife, Metis, and as a on Delos result Athena was born ΑΡΗΣ Hephaestos The messenger of the gods, full-grown from Vulcan and the god of boundaries Son of Zeus the head of Zeus. Ares by Maia, a Mars The god of the forge who must spend daughter The god and of artisans part of each year in of Atlas of war Persephone the underworld as the consort of Hades ΑΙΔΗΣ ΖΕΥΣ ΕΣΤΙΑ ΔΗΜΗΤΗΡ Zeus ΗΡΑ ΠΟΣΕΙΔΩΝ Hades Jupiter Hera Poseidon Hestia Pluto Demeter The king of the gods, Juno Vesta Ceres Neptune The goddess of The god of the the god of the sky The goddess The god of the sea, the hearth, underworld The goddess of and of thunder of women “The Earth-shaker” household, the harvest and marriage and state ΑΦΡΟΔΙΤΗ Hekate The goddess Aphrodite First-generation Second- generation of magic Venus ΡΕΑ Titans ΚΡΟΝΟΣ Titans The goddess of MagnaRhea Mater Astraeus love and beauty Mnemosyne Kronos Saturn Deucalion Pallas & Perses Pyrrha Kronos cut off the genitals Crius of his father Uranus and threw them into the sea, and Asteria Aphrodite arose from them. -
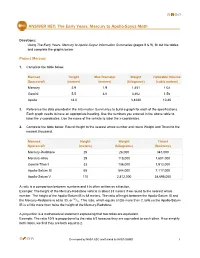
ANSWER KEY: the Early Years: Mercury to Apollo-Soyuz Math
ANSWER KEY: The Early Years: Mercury to Apollo-Soyuz Math Directions: Using The Early Years: Mercury to Apollo-Soyuz Information Summaries (pages 8 & 9), fill out the tables and complete the graphs below. Project Mercury 1. Complete the table below. Manned Height Max Diameter Weight Habitable Volume Spacecraft (meters) (meters) (kilograms) (cubic meters) Mercury 2.9 1.9 1,451 1.02 Gemini 5.5 3.0 3,402 1.56 Apollo 18.0 3,4280 10.45 2. Reference the data provided in the Information Summaries to build a graph for each of the specifications. Each graph needs to have an appropriate heading. Use the numbers you entered in the above table to label the y-coordinates. Use the name of the vehicle to label the x-coordinates. 3. Complete the table below. Round Height to the nearest whole number and round Weight and Thrust to the nearest thousand. Manned Height Weight Thrust Spacecraft (meters) (kilograms) (Newtons) Mercury-Redstone 25 28,000 347,000 Mercury-Atlas 29 118,000 1,601,000 Gemini-Titan II 33 136,000 1,913,000 Apollo-Saturn IB 68 544,000 7,117,000 Apollo-Saturn V 110 2,812,000 38,698,000 A ratio is a comparison between numbers and it is often written as a fraction. Example: The height of the Mercury-Redstone vehicle is about 33 meters if we round to the nearest whole number. The height of the Apollo-Saturn IB is 68 meters. The ratio of height between the Apollo-Saturn IB and 68 the Mercury-Redstone is 68 to 33, or /33. -

Symbolism of the Apple in Greek Mythology Highgate Private School Nicosia, CYPRUS
Symbolism of the Apple in Greek Mythology Highgate Private School Nicosia, CYPRUS Apples appear throughout numerous world religions and mythologies as a common symbol and motif. It is important to note though that in Middle English as late as the 17th century, the word ‘apple’ was used as a generic term to describe all fruit other than berries, so the appearance of apples in ancient writings may not actually be the apples known today. The etymology of 'apple' is an interesting one. That aside, Greek mythology presents several notable apples: the Golden Apples in the Garden of Hesperides, different golden apples associated with Atalanta, and of course the golden Apple of Discord. Each appearance of apples presents unique examples of symbolism. The Golden Apples in the Garden of Hesperides were a wedding gift to Hera from Gaia and were protected by a great serpent called Ladon. The Apples as well as the rest of the life in the Garden were tended by the Hesperides, minor earth goddesses or nymphs and daughters of the Titan, Atlas. The Garden itself rested in an inaccessible spot near the edge of the world under the power of the Olympians. For his Eleventh Labor, Hercules was sent to the Garden to retrieve three Golden Apples for King Eurystheus. The exact location of the Garden and the Apples was unknown and Hercules had to pry the information from Nereus, the Old Man of the Sea. Along the way, he also encountered and freed Prometheus who told not to try pick the Golden Apples himself, but to ask Atlas. -

Leonardoimpett Francomoretti Totentanz. Operationalizing Aby
Totentanz. AB Operationalizing Aby Warburg’s Pathosformeln Leonardo Impett Franco Moretti Literary Lab Pamphlet 16 NovemberN 2017 Pamphlets of the Stanford Literary Lab ISSN 2164-1757 (online version) Leonardo Impett Franco Moretti Totentanz. Operationalizing Aby Warburg’s Pathosformeln 1. Mnemosyne The object of this study is one of the most ambitious projects of twentieth-century in his intellectual biography of Warburg, he compared Mnemosyne to “certain types art history: Aby Warburg’s Atlas Mnemosyne, conceived in the summer of 1926 – of twentieth-century poetry – he must have been thinking of Pound’s Cantos, or El- when the first mention of aBilderatlas , or “atlas of images”, occurs in his journal iot’s Waste Land – where hosts of historical or literary allusions hide and reveal layers – and truncated three years later, unfinished, by his sudden death in October 1929. upon layers of private meanings”.3 An enigmatic work, in other words; often com- Mnemosyne consisted in a series of large black panels, about 170x140 cm., on pared to Benjamin’s Passagenwerk, but in truth much more elusive than that. One which were attached black-and-white photographs of paintings, sculptures, book thread through the labyrinth is however offered by Warburg’s greatest conceptual pages, stamps, newspaper clippings, tarot cards, coins, and other types of images creation: the Pathosformel, or formula for (the expression of) Pathos. Passion, emo- (Figure 1.1). Warburg kept changing the order of the panels and the position of the tion, suffering, agitation –Pathos is a term with many (and perhaps too many) se- images until the very end, and three main versions of the Atlas have been recorded: mantic shades,4 though they all share the “superlative” degree (Warburg’s word) of one from 1928 (the “1-43 version”, with 682 images); one from the early months of the feeling involved. -

Thomas Merton's Myth for Modern Times
10 THOMAS MERTON'S MYTH FOR MODERN TIMES: A Tale of the City by Gloria Kitto lewis There is nothing in the world of buildings that is nor fabricated, and if a tree gets in among the apartment houses by mistake it is taught to grow chemically. It is given a precise reason for existing. They put up a sign on it saying it is health, beauty, perspective; thar it is for peace, for prosperity .. .. All this is mystification. The city itself lives on its own myth. Instead of waking up and silently existing, the city people prefer a stubborn and fabricated dream; they do not care to be a part of the night, or to be merely of the world. They have constructed a world outside the world, against the world, a world of mechanical fictions which condemn nature and seek only to use it up, thus preventing it from renewing itself and man.' It can be posited that a central problem in the technological twentieth century is that human persons have far too often lost touch with reality. Partaking of the city myth, they live as if "only the city is real," deluding themselves into believing that their world is the world of buildings ("Rain," p.12). Holding fast to that "fabricated" dream, they stubbornly look for peace, prosperity, health, and beauty in that synthetic world, that mechanized environment which is actually" a world outside the world" and very importantly "against the world." Unfortunately, human persons have lost communion and identification with the natural world, a real world that exists underneath and beyond the humanmade, an idyllic world within the technological illu sionary world to which they belong by their very nature, and from which they draw their identity 0 Glori~ Kitto Lewis received her doctorate in English from the University of Michigan. -

Memory, Metaphor, and Aby Warburg's Atlas of Images
Memory, Metaphor, and Aby Warburg’s Atlas of Images Series editor: Peter Uwe Hohendahl, Cornell University Signale: Modern German Letters, Cultures, and Thought publishes new English- language books in literary studies, criticism, cultural studies, and intellectual history pertaining to the German-speaking world, as well as translations of im- portant German-language works. Signale construes “modern” in the broadest terms: the series covers topics ranging from the early modern period to the present. Signale books are published under a joint imprint of Cornell University Press and Cornell University Library in electronic and print formats. Please see http://signale.cornell.edu/. Memory, Metaphor, and Aby Warburg’s Atlas of Images Christopher D. Johnson A Signale Book Cornell University Press and Cornell University Library Ithaca, New York Cornell University Press and Cornell University Library gratefully acknowledge the support of The Andrew W. Mellon Foundation for the publication of this volume. Copyright © 2012 by Cornell University All rights reserved. Except for brief quotations in a review, this book, or parts thereof, must not be reproduced in any form without permission in writing from the publisher. For information, address Cornell University Press, Sage House, 512 East State Street, Ithaca, New York 14850. First published 2012 by Cornell University Press and Cornell University Library Printed in the United States of America Library of Congress Cataloging-in-Publication Data Johnson, Christopher D., 1964– Memory, metaphor, and Aby Warburg’s Atlas of images / Christopher D. Johnson. p. cm. — (Signale : modern German letters, cultures, and thought) Includes bibliographical references and index. ISBN 978-0-8014-7742-3 (pbk. -

Constellation Legends
Constellation Legends by Norm McCarter Naturalist and Astronomy Intern SCICON Andromeda – The Chained Lady Cassiopeia, Andromeda’s mother, boasted that she was the most beautiful woman in the world, even more beautiful than the gods. Poseidon, the brother of Zeus and the god of the seas, took great offense at this statement, for he had created the most beautiful beings ever in the form of his sea nymphs. In his anger, he created a great sea monster, Cetus (pictured as a whale) to ravage the seas and sea coast. Since Cassiopeia would not recant her claim of beauty, it was decreed that she must sacrifice her only daughter, the beautiful Andromeda, to this sea monster. So Andromeda was chained to a large rock projecting out into the sea and was left there to await the arrival of the great sea monster Cetus. As Cetus approached Andromeda, Perseus arrived (some say on the winged sandals given to him by Hermes). He had just killed the gorgon Medusa and was carrying her severed head in a special bag. When Perseus saw the beautiful maiden in distress, like a true champion he went to her aid. Facing the terrible sea monster, he drew the head of Medusa from the bag and held it so that the sea monster would see it. Immediately, the sea monster turned to stone. Perseus then freed the beautiful Andromeda and, claiming her as his bride, took her home with him as his queen to rule. Aquarius – The Water Bearer The name most often associated with the constellation Aquarius is that of Ganymede, son of Tros, King of Troy. -

Atlas (Mythology) from Wikipedia, the Free Encyclopedia
AAttllaas ((mmyytthhoollooggyy) - WWiikkiippeeddiiaa, tthhe ffrreee eennccyyccllooppeeddiiaa hhttttpp::////eenn..wwiikkiippeeddiiaa..oorrgg//wwiikkii//AAttllaass__((mmyytthhoollooggyy)) Atlas (mythology) From Wikipedia, the free encyclopedia InIn Greek mythologygy,, Atlas (/ˈætləs/; Ancient Greek: Ἄτλας) was the primordial Titan who held up thehe celestialal Atlas spheres. He is also the titan of astronomy and navigation. Although associated with various places, he became commonly identified with the Atlas Mountains in northwest Africa (Modern-day Morocco, Algeria and Tunisia).[1][1] Atlas was the son of the Titanan Iapetus and the Oceanidd Asiaa[2][2] or or ClClymene..[3][3] In contexts where a Titan and a Titaness are assigned each of the seven planetary powers, Atlas is paired with Phoebe and governs the moon..[4][4] Hyginus emphasises the primordial nature of Atlas by making him the son of Aether andd Gaia.a.[5][5] The first part of the term Atlantic Ocean refers to "Sea of Atlas", the term Atlantis refers to "island of Atlas". Titan of Astronomy Abode WWestern edge ofof Gaia (thethe Earth)) Contents Symbol Globe 11 EtEtymolologygy Parents Iapetus and Asia or Clymenee 22 Puninishmenentt Children Hesperides,s, Hyades,s, Hyas, Pleiades, Calypso,so, Dione and 2.1 VVariations Maera 33 Encounter with Heracleses Roman equivalent Atlas 44 Etruscan Arill 55 Chilildrdrenen 66 Cultural influencece 77 SeSee alalsoso 88 NNototeses 99 References 1010 External linkss Etymology The etymology of the name Atlas is uncertain. Virgil took pleasure in translating etymologies of Greek names by combining them with adjectives that explained them: for Atlas his adjective is durus, "hard, enduring",[6][6] which suggested to George Doig[7][7] that Virgil was aware of the Greek τλῆναι "to endure"; Doig offers the further possibility that Virgil was aware of Strabo’s remark that the native North African name for this mountain was Douris. -

In Greek Mythology, Atlas Was a Titan Who Had to Hold up the Heavens
Cutaway view of the ATLAS detector for CERN's LHC proton-proton collider. The outer ATLAS toroidal magnet will extend over 26 metres, with an outer diameter of almost 20 metres. The total weight of the detector is 7,000 tonnes. n Greek mythology, Atlas was a I Titan who had to hold up the heavens with his hands as a punish ment for having taken part in a revolt against the Olympians. For LHC, the ATLAS detector will also have an onerous physics burden to bear, but this is seen as a golden opportunity rather than a punishment. The major physics goal of CERN's LHC proton-proton collider is the quest for the long-awaited £higgs' mechanism which drives the sponta neous symmetry breaking of the electroweak Standard Model picture. The large ATLAS collaboration proposes a large general-purpose detector to exploit the full discovery potential of LHC's proton collisions. LHC will provide proton-proton collision luminosities at the awe- inspiring level of 1034 cnr2 s~1, with initial running in at 1033. The ATLAS philosophy is to handle as many signatures as possible at all luminos ity levels, with the initial running providing more complex possibilities. The ATLAS concept was first presented as a Letter of Intent to the toroids outside the calorimetry. This efficient tracking at high luminosity LHC Committee in November 1992. solution avoids constraining the for lepton momentum measurements, Following initial presentations at the calorimetry while providing a high for heavy quark tagging, and for good Evian meeting (Towards the LHC resolution, large acceptance and electron and photon identification, as Experimental Programme') in March robust detector. -

ADJOURNMENT SINE DIE—HOUSE of July 29,1994 REPRESENTATIVES and SENATE [H
CONCURRENT RESOLUTIONS—JULY 29, 1994 108 STAT. 5107 Whereas the successful execution of the program to reach and explore the Moon was one of the greatest achievements in the history of mankind; Whereas the hsirdware and astronauts involved in the Lunar pro gram subsequently flew 3 Skylab missions, and 1 international ApoUo-Sojoiz mission; Whereas the astronauts who put their lives on the line by flying in space in the execution of that program are true national heroes; and Whereas these astronauts should receive popular recognition from a grateful Nation for their tremendous achievement: Now, there fore, be it Resolved by the House of Representatives (the Senate concur ring), That henceforth Buzz Aldrin (Gemini 12, Apollo 11), William Alison Anders (Apollo 8), Neil Alden Armstrong (Gemini 8, Apollo 11), Charles Arthur Bassett II (died in T-38 crash), Alan LaVem Bean (Apollo 12, Skylab 3), Frank Borman (Gemini 7, Apollo 8), Vance DeVoe Brand (Apollo-So3aiz), Malcolm Scott Carpenter (Mer cury-Atlas 7), Gerald Paul Carr (Skylab 4), Eugene Andrew Ceman (Gemini 9, Apollo 10, Apollo 17), Roger Bruce Chaffee (Apollo 204), Michael Collins (Gremini 10, Apollo 11), Charles Conrad, Jr. (Gemini 5, Gemini 11, Apollo 12, Skylab 2), Leroy Gordon Cooper, Jr. (Mer cury-Atlas 9, G«mini 5), Ronnie Walter Cunningham (Apollo 7), Charles Moss Duke, Jr. (Apollo 16), Donn Fulton Eisele (Apollo 7), Ronald EUwin Evans (Apollo 17), Theodore Cordy Freeman (died in T-38 crash), Owen Kay Garriott (Skylab 3), Edward George Gibson (Skylab 4), John Herschel Glenn, Jr. (Mercury-Atlas 6), Richard Francis (Gordon, Jr.