Domain Landscape Review and Data Value Chain Definition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Is a SPARQL Endpoint a Good Way to Manage Nursing Documentation
Is a SPARQL Endpoint a Good way to Manage Nursing Documentation Is a SPARQL Endpoint a good way to Manage Nursing Documentation by Muhammad Aslam Supervisor: Associate Professor Jan Pettersen Nytun Project report for Master Thesis in Information & Communication Technology IKT 590 in Spring 2014 University of Agder Faculty of Engineering and Science Grimstad, 2 June 2014 Status: Final Keywords: Semantic Web, Ontology, Jena, SPARQL, Triple Store, Relational Database Page 1 of 86 Is a SPARQL Endpoint a Good way to Manage Nursing Documentation Abstract. In Semantic Web there are different technologies available, among these technologies ontologies are considered a basic technology to promote semantic management and activities. An ontology is capable to exhibits a common, shareable and reusable view of a specific application domain, and they give meaning to information structures that are exchanged by information systems [63]. In this project our main goal is to develop an application that helps to store and manage the patient related clinical data. For this reason first we made an ontology, in ontology we add some patient related records. After that we made a Java application in which we read this ontology by the help of Jena. Then we checked this application with some other database solutions such as Triple Store (Jena TDB) and Relational database (Jena SDB). After that we performed SPARQL Queries to get results that reads from databases we have used, on the basis of results that we received after performing SPARQL Queries, we made an analysis on the performance and efficiency of databases. In these results we found that Triple Stores (Jena TDB) have capabilities to response very fast among other databases. -

Domain Landscape Review and Data Value Chain Definition
Ref. Ares(2018)2305100 - 30/04/2018 H2020 - INDUSTRIAL LEADERSHIP - Information and Communication Technologies (ICT) ICT-14-2016-2017: Big Data PPP: cross-sectorial and cross-lingual data integration and experimentation ICARUS: “Aviation-driven Data Value Chain for Diversified Global and Local Operations” D1.1 – Domain Landscape Review and Data Value Chain Definition Workpackage: WP1 – ICARUS Data Value Chain Elaboration Authors: University of Cyprus (UCY), Suite5, UBITECH, CINECA, AIA, PACE, ISI, CELLOCK, TXT, OAG Status: Final Classification: Public Date: 30/04/2018 Version: 1.00 Disclaimer: The ICARUS project is co-funded by the Horizon 2020 Programme of the European Union. The information and views set out in this publication are those of the author(s) and do not necessarily reflect the official opinion of the European Communities. Neither the European Union institutions and bodies nor any person acting on their behalf may be held responsible for the use which may be made of the information contained therein. © Copyright in this document remains vested with the ICARUS Partners. D1.1 - Domain Landscape Review and Data Value Chain Definition ICARUS Project Profile Grant Agreement No.: 780792 Acronym: ICARUS Aviation-driven Data Value Chain for Diversified Global and Local Title: Operations URL: http://www.icarus2020.aero Start Date: 01/01/2018 Duration: 36 months Partners UBITECH (UBITECH) Greece ENGINEERING - INGEGNERIA INFORMATICA SPA (ENG) Italy PACE Aerospace Engineering and Information Technology GmbH (PACE) Germany SUITE5 DATA -

Qualifikationsprofil #10309
QUALIFIKATIONSPROFIL #10309 ALLGEMEINE DATEN Geburtsjahr: 1972 Ausbildung: Abitur Diplom, Informatik, (TU, Kaiserslautern) Fremdsprachen: Englisch, Französisch Spezialgebiete: Kubernetes KENNTNISSE Tools Active Directory Apache Application Case CATIA CVS Eclipse Exchange Framework GUI Innovator ITIL J2EE JMS LDAP Lotus Notes make MS Exchange MS Outlook MS-Exchange MS-Office MS-Visual Studio NetBeans OSGI RACF SAS sendmail Together Turbine UML VMWare .NET ADS ANT ASP ASP.NET Flash GEnie IDES Image Intellij IDEA IPC Jackson JBOSS Lex MS-Visio ODBC Oracle Application Server OWL PGP SPSS SQS TesserAct Tivoli Toolbook Total Transform Visio Weblogic WebSphere YACC Tätigkeiten Administration Analyse Beratung Design Dokumentation KI Konzeption Optimierung Support Vertrieb Sprachen Ajax Basic C C# C++ Cobol Delphi ETL Fortran Java JavaScript Natural Perl PHP PL/I PL-SQL Python SAL Smalltalk SQL ABAP Atlas Clips Delta FOCUS HTML Nomad Pascal SPL Spring TAL XML Detaillierte Komponenten AM BI FS-BA MDM PDM PM BW CO FI LO PP Datenbanken Approach IBM Microsoft Object Store Oracle Progress Sybase DMS ISAM JDBC mySQL DC/Netzwerke ATM DDS Gateway HBCI Hub Internet Intranet OpenSSL SSL VPN Asynchronous CISCO Router DNS DSL Firewall Gateways HTTP RFC Router Samba Sockets Switches Finance Business Intelligence Excel Konsolidierung Management Projektleiter Reporting Testing Wertpapiere Einkauf CAD Systeme CATIA V5 sonstige Hardware Digital HP PC Scanner Siemens Spark Teradata Bus FileNet NeXT SUN Switching Tools, Methoden Docker Go Kubernetes Rational RUP -

Assessment of Multiple Ingest Strategies for Accumulo Key-Value Store
Assessment of Multiple Ingest Strategies for Accumulo Key-Value Store by Hai Pham A thesis submitted to the Graduate Faculty of Auburn University in partial fulfillment of the requirements for the Degree of Master of Science Auburn, Alabama May 7, 2016 Keywords: Accumulo, noSQL, ingest Copyright 2016 by Hai Pham Approved by Weikuan Yu, Co-Chair, Associate Professor of Computer Science, Florida State University Saad Biaz, Co-Chair, Professor of Computer Science and Software Engineering, Auburn University Sanjeev Baskiyar, Associate Professor of Computer Science and Software Engineering, Auburn University Abstract In recent years, the emergence of heterogeneous data, especially of the unstructured type, has been extremely rapid. The data growth happens concurrently in 3 dimensions: volume (size), velocity (growth rate) and variety (many types). This emerging trend has opened a new broad area of research, widely accepted as Big Data, which focuses on how to acquire, organize and manage huge amount of data effectively and efficiently. When coping with such Big Data, the traditional approach using RDBMS has been inefficient; because of this problem, a more efficient system named noSQL had to be created. This thesis will give an overview knowledge on the aforementioned noSQL systems and will then delve into a more specific instance of them which is Accumulo key-value store. Furthermore, since Accumulo is not designed with an ingest interface for users, this thesis focuses on investigating various methods for ingesting data, improving the performance and dealing with numerous parameters affecting this process. ii Acknowledgments First and foremost, I would like to express my profound gratitude to Professor Yu who with great kindness and patience has guided me through not only every aspect of computer science research but also many great directions towards my personal issues. -
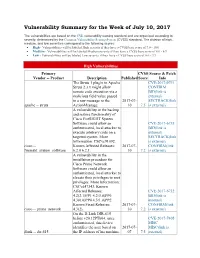
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

A Survey of Geospatial Semantic Web for Cultural Heritage
heritage Review A Survey of Geospatial Semantic Web for Cultural Heritage Ikrom Nishanbaev 1,* , Erik Champion 1 and David A. McMeekin 2 1 School of Media, Creative Arts, and Social Inquiry, Curtin University, Perth, WA 6845, Australia; [email protected] 2 School of Earth and Planetary Sciences, Curtin University, Perth, WA 6845, Australia; [email protected] * Correspondence: [email protected] Received: 23 April 2019; Accepted: 16 May 2019; Published: 20 May 2019 Abstract: The amount of digital cultural heritage data produced by cultural heritage institutions is growing rapidly. Digital cultural heritage repositories have therefore become an efficient and effective way to disseminate and exploit digital cultural heritage data. However, many digital cultural heritage repositories worldwide share technical challenges such as data integration and interoperability among national and regional digital cultural heritage repositories. The result is dispersed and poorly-linked cultured heritage data, backed by non-standardized search interfaces, which thwart users’ attempts to contextualize information from distributed repositories. A recently introduced geospatial semantic web is being adopted by a great many new and existing digital cultural heritage repositories to overcome these challenges. However, no one has yet conducted a conceptual survey of the geospatial semantic web concepts for a cultural heritage audience. A conceptual survey of these concepts pertinent to the cultural heritage field is, therefore, needed. Such a survey equips cultural heritage professionals and practitioners with an overview of all the necessary tools, and free and open source semantic web and geospatial semantic web platforms that can be used to implement geospatial semantic web-based cultural heritage repositories. -

Diplomová Práce Přenos Dat Z Registru SITS Ve Formátu DASTA
Západočeská univerzita v Plzni Fakulta aplikovaných věd Katedra informatiky a výpočetní techniky Diplomová práce Přenos dat z registru SITS (Safe Impementation of Treatments in Stroke) ve formátu DASTA Plzeň, 2012 Bc. Pavel Karlík 1 Originální zadání práce 2 Prohlášení: Prohlašuji, že jsem diplomovou práci vypracoval samostatně a výhradně s použitím citovaných pramenů, pokud není explicitně uvedeno jinak. V Plzni dne …………… Bc. Pavel Karlík ………………… 3 Abstract Data Transfer from the SITS Registry (Safe Implementation of Treatments in Stroke) in the Format of DASTA The goal of this master´s thesis is to analyze the data standards in the field of medical applications with focus on the format DASTA, work with them and developing a suitable web-based tool for doctors in the FN Plzeň hospital to simplify the forms filling in the SITS registry. Application will be user-friendly with the focus on one-click access, multi-lingual, adaptive to changes, and fill in the forms with the data from hospital database stored in the DASTA. In the background will send same data also to the Department of Computer Science and Engineering in the University of West Bohemia for future research. 4 Poděkování Tímto bych chtěl poděkovat paní Doc. Dr. Ing. Janě Klečkové za neutuchající optimismus a podporu, který mně byl motivací během celé doby mé práce. Dále si cením věnovaného času a pomoci, která mi byla velkou podporou při tvorbě. Poděkování patří také mé rodině a blízkým za jejich ohleduplnost a motivaci. 5 Obsah 1 ÚVOD ............................................................................................................ 9 2 DATOVÉ STANDARDY .................................................................................. 10 2.1 STANDARDY OBECNĚ ......................................................................................... 10 2.1 DASTA .......................................................................................................... 12 2.1.1 Historie ................................................................................................ -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Integration of Web Apis and Linked Data Using SPARQL Micro-Services
Integration of Web APIs and Linked Data Using SPARQL Micro-Services - Application to Biodiversity Use Cases Franck Michel, Catherine Faron Zucker, Olivier Gargominy, Fabien Gandon To cite this version: Franck Michel, Catherine Faron Zucker, Olivier Gargominy, Fabien Gandon. Integration of Web APIs and Linked Data Using SPARQL Micro-Services - Application to Biodiversity Use Cases. Information, MDPI, 2018, Special Issue ”Semantics for Big Data Integration”, 9 (12), 10.3390/info9120310. hal- 01947589 HAL Id: hal-01947589 https://hal.archives-ouvertes.fr/hal-01947589 Submitted on 7 Dec 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License information Article Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases † Franck Michel 1,*, Catherine Faron Zucker 1, Olivier Gargominy 2 and Fabien Gandon 1 1 I3S laboratory, University Côte d’Azur, CNRS, Inria, 930 route des Colles, 06903 Sophia Antipolis, France; [email protected] (C.F.Z.); [email protected] (F.G.) 2 Muséum National d’Histoire Naturelle, 36 rue Geoffroy Saint-Hilaire, 75005 Paris, France; [email protected] (O.G.) * Correspondence: [email protected] (F.M.) † This paper is an extended version of our paper published in Michel F., Faron Zucker C. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments.