Enter Your Title Here in All Capital Letters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hank-Aaron.Pdf
The Swing that Rewrote HISTORY 40 years later, Hank Aaron’s feat stands the test of time By Adam DeCock he Braves April 8th home opener marked more than just the the Boston Red Sox, then spent the majority of his well-documented start of the baseball season this year. It also marked the career with the New York Yankees. ‘The Curse of the Bambino’ might 40th anniversary of Hank Aaron breaking Babe Ruth’s long be the most well-known curse in baseball, having haunted the Sox standing home run record and #715. for over 80 seasons following the trade that put Ruth in pinstripes. When Aaron stepped into the batter’s box in the fourth inning in a Almost 40 years after Ruth’s 714th home run, an unassuming game against the Los Angeles Dodgers on April 8, 1974, ‘Hammerin’ young ballplayer from Mobile, AL entered the picture. Little did Hank’ did more than break a record that had stood for nearly 40 Aaron know his feat would capture his and future generations of years. The feat itself remains a marvel in baseball history, but is baseball fans, and change the landscape of America’s pastime just one aspect of what makes Aaron’s path as a player, as well as forever. his post-playing days, a memorable journey. And it wasn’t all luck. Aaron ended the 1973 season with 713 home runs, one shy of the “I’m proud of all of my accomplishments that I’ve had in baseball,” record set by Babe Ruth in 1935, a record that most considered Aaron said. -

NCAA Division I Baseball Records
Division I Baseball Records Individual Records .................................................................. 2 Individual Leaders .................................................................. 4 Annual Individual Champions .......................................... 14 Team Records ........................................................................... 22 Team Leaders ............................................................................ 24 Annual Team Champions .................................................... 32 All-Time Winningest Teams ................................................ 38 Collegiate Baseball Division I Final Polls ....................... 42 Baseball America Division I Final Polls ........................... 45 USA Today Baseball Weekly/ESPN/ American Baseball Coaches Association Division I Final Polls ............................................................ 46 National Collegiate Baseball Writers Association Division I Final Polls ............................................................ 48 Statistical Trends ...................................................................... 49 No-Hitters and Perfect Games by Year .......................... 50 2 NCAA BASEBALL DIVISION I RECORDS THROUGH 2011 Official NCAA Division I baseball records began Season Career with the 1957 season and are based on informa- 39—Jason Krizan, Dallas Baptist, 2011 (62 games) 346—Jeff Ledbetter, Florida St., 1979-82 (262 games) tion submitted to the NCAA statistics service by Career RUNS BATTED IN PER GAME institutions -

415 Vs. TB.Pdf
WORLD SERIES CHAMPIONS (8): 1903, 1912, 1915, 1916, 1918, 2004, 2007, 2013 AMERICAN LEAGUE CHAMPIONS (13): 1903, 1904, 1912, 1915, 1916, 1918, 1946, 1967, 1975, 1986, 2004, 2007, 2013 AMERICAN LEAGUE EAST DIVISION CHAMPIONS (8): 1975, 1986, 1988, 1990, 1995, 2007, 2013, 2016 AMERICAN LEAGUE WILD CARD (7): 1998, 1999, 2003, 2004, 2005, 2008, 2009 @BOSTONREDSOXPR • HTTP://PRESSROOM.REDSOX.COM • @SOXNOTES BOSTON RED SOX (5-5) vs. TAMPA BAY RAYS (6-5) Saturday, April 15, 2017 • 4:05 p.m. ET • Fenway Park • Boston, MA LHP Chris Sale (0-1, 1.23) vs. RHP Jake Odorizzi (1-1, 4.50) Game #11 • Home Game #7 • TV: NESN • Radio: WEEI 93.7 FM, WCEC 1490 AM/103.7 FM (Spanish) ONE BOSTON DAY: A special pre-game ceremony in- RISE & SHINE, BOSTON: The Red Sox have won 18 of cluding a moment of reflection will take place today to their last 21 day games at Fenway Park (beginning 5/14/16)... REGULAR SEASON BREAKDOWN recognize the 4-year anniversary of the Boston Marathon In those games, they are batting .321 with a .924 OPS (237- AL East Standing .......................4th, 2.5 GB Home/Road ..................................... 4-2/1-3 bombings...The Red Sox will also honor those affected by for-738, 60 2B, 5 3B, 30 HR). Day/Night ........................................ 3-3/2-2 the tragic events with a moment of silence at 2:49 p.m. April .......................................................5-5 HAVE WE BENINTRODUCED?: Andrew Benintendi has vs. AL East ..............................................1-2 JACKIE ROBINSON DAY: Today is MLB’s 14th annual Jackie reached base in each of the Sox’ 10 games this season...He vs. -

Washington State Cougar History Cougar Baseball History
WASHINGTON STATE Cougar History COUGAR BASEBALL HISTORY Cougar baseball is almost as old as Washington State University. BRAYTON’S MILESTONES Classes met for the first time Jan. 3-22-62: 1st win (and game), 9-4 vs. Gonzaga at Lewiston; 13, 1892, and in March of that 5-21-65: 100th win, 2-1 vs. Washington at Seattle; year the students organized a 3-27-69: 200th win, 8-0 vs. W. Washington at Lewiston; baseball team. It is only natural 4-15-72: 300th win, 5-0 vs. Washington at Seattle; that baseball should have been the 3-24-75: 400th win, 18-2 vs. Cornell at Riverside, Calif.; first organized sport at WSU, since 5-1-77: 500th win, 6-2 vs. Washington at Seattle; at the time the University was 3-16-80: 600th win, 9-7 vs. LCSC at Lewiston; 4-9-83: 700th win, 11-6 vs. CWU at Pullman; founded the game was immensely 4-30-83: 1,000th WSU game, 6-2 vs. Gonzaga at Pullman; popular all over the country. 5-1-85: 800th win, 10-4 vs. Whitworth at Pullman; The 1995 season marked a 3-16-88: 900th win, 6-5 vs. Clemson at Fresno, Calif.; special celebration in Cougar 4-11-90: 1,000th win, 14-6 vs. E. Washington at Pullman; baseball history. It was the 100th 3-7-93: 1,100th win, 9-6 vs. Gonzaga at Lewiston; year WSU had fielded a baseball 5-20-94: Last game, 11-9 vs. Portland at Pullman. team. Following the first season, 1892, play was discontinued When Bailey retired in 1961, one of and did not resume until 1896. -

Oakland A's, Manny Ramirez Agree on Minor League Contract A's
A’s News Clips, Tuesday, February 21, 2012 Oakland A's, Manny Ramirez agree on minor league contract By Joe Stiglich, Oakland Tribune PHOENIX -- The A's agreed to terms with free-agent designated hitter Manny Ramirez on a minor league contract Monday, tying themselves to one of baseball's most productive -- and controversial -- sluggers of all time. The deal is pending a physical, but Ramirez is expected to report to spring training by the end of this week. He must serve a 50-game suspension for violating Major League Baseball's drug policy for a second time, meaning he would become eligible for a May 30 game at Minnesota, on his 40th birthday. A's general manager Billy Beane, who had been looking for a veteran D.H. for several weeks, is expected to address the signing with the media Tuesday. If Oakland adds Ramirez to the major league roster after his suspension, his salary is expected to be around $500,000. "A guy like that can only help out," second baseman Jemile Weeks said. "Being loose, him having his goofy side -- if he still has it, that helps the camaraderie of the team.— Ramirez ranks 14th on the majors' all-time list with 555 home runs and carries a .312 career batting average. But considering his age, it's fair to ask how much impact he can make, especially since he'll miss almost a third of the season. Ramirez hasn't played since last April, when he abruptly retired after playing five games for the Tampa Bay Rays. -

Postseaason Sta Rec Ats & Caps & Re S, Li Ecord Ne S Ds
Postseason Recaps, Line Scores, Stats & Records World Champions 1955 World Champions For the Brooklyn Dodgers, the 1955 World Series was not just a chance to win a championship, but an opportunity to avenge five previous World Series failures at the hands of their chief rivals, the New York Yankees. Even with their ace Don Newcombe on the mound, the Dodgers seemed to be doomed from the start, as three Yankee home runs set back Newcombe and the rest of the team in their opening 6-5 loss. Game 2 had the same result, as New York's southpaw Tommy Byrne held Brooklyn to five hits in a 4-2 victory. With the Series heading back to Brooklyn, Johnny Podres was given the start for Game 3. The Dodger lefty stymied the Yankees' offense over the first seven innings by allowing one run on four hits en route to an 8-3 victory. Podres gave the Dodger faithful a hint as to what lay ahead in the series with his complete-game, six-strikeout performance. Game 4 at Ebbets Field turned out to be an all-out slugfest. After falling behind early, 3-1, the Dodgers used the long ball to knot up the series. Future Hall of Famers Roy Campanella and Duke Snider each homered and Gil Hodges collected three of the club’s 14 hits, including a home run in the 8-5 triumph. Snider's third and fourth home runs of the Series provided the support needed for rookie Roger Craig and the Dodgers took Game 5 by a score of 5-3. -

Moneyball' Bit Player Korach Likes Film
A’s News Clips, Tuesday, October 11, 2011 'Moneyball' bit player Korach likes film ... and Howe Ron Kantowski, Las Vegas Review Ken Korach's voice can be heard for about 22 seconds in the hit baseball movie "Moneyball," now showing at a theater near you. That's probably not enough to warrant an Oscar nomination, given Anthony Quinn holds the record for shortest amount of time spent on screen as a Best Supporting Actor of eight minutes, as painter Paul Gaugin in 1956's "Lust for Life." But whereas Brad Pitt only stars in "Moneyball," longtime Las Vegas resident Korach lived the 2002 season as play-by- play broadcaster for the Oakland Athletics, who set an American League record by winning 20 consecutive games. And though Korach's 45-minute interview about that season wound up on the cutting-room floor -- apparently along with photographs of the real Art Howe, the former A's manager who was nowhere near as rotund (or cantankerous) as Philip Seymour Hoffman made him out to be in the movie -- Korach said director Bennett Miller and the Hollywood people got it right. Except, perhaps, for the part about Art Howe. "I wish they had done a more flattering portrayal of Art ... but it's Hollywood," Korach said of "Moneyball," based on author Michael Lewis' 2003 book of the same name. "They wanted to show conflict between Billy and Art." Billy is Billy Beane, who was general manager of the Athletics then and still is today. Beane is credited with adapting the so-called "Moneyball" approach -- finding value in players based on sabermetric statistical data and analysis, rather than traditional scouting values such as hitting home runs and stealing bases -- to building a ballclub. -

Final 1991 Division I Baseball
-----------------------------------------------------------------------------------------------------------------)------ ----- -- -- ------ -------- ----- -------------------------------------------- ---- ---- ------ --- FINAL 1991 DIVISION I BASEBALL. BATTING BATTING (2. 5 ab/game and 75 at bats) AB HTS AVG. (2. 5 ab/game and 75 at bats) AB HTS AVG. 1. Ron Dziezgowski, Duquesne SR 33 88 500 36. Matt Raleigh, Western Caro. ------- JR 62 223 92 . 413 2. Gene Schall, Villanova ------------ JR 40 155 75 484 37. Brent Gates , Minnesota ------------ JR 64 221 91 . 412 Mike Neill, Villanova ------------- JR 52 216 101 468 37. chris Sexton, Miami (Ohio) -------- SO 49 153 63 . 412 C. Hendrix, Campbell ------------ JR 52 192 89 464 39. Jason Geis , Portland -------------- JR 42 146 60 . 411 Tom Vantiger , Iowa St. ------------ SR 58 177 82 463 40. Glen Taylor, Iona ----------------- SR 36 105 43 410 Al Watson, New York Tech ---------- JR 52 188 87 463 41. John Callihan, Mercer ------------- JR 45 169 69 . 408 Mike Carlsen , FDU-Teaneck --------- JR 40 145 67 462 42. Jason Giambi, Long Beach St. ------ SO 60 199 81 . 407 Mike Edwards , Utah ---------------- SO 53 184 84 457 42. Greg Elliott, Md. -BaIt. County ---- SO 49 199 81 . 407 9. Scott Stahoviak, Creighton JR 72 267 120 449 44. Mike Welch, Geo. Washington ------- JR 56 209 85 . 407 10. Jon Sbrocco, Wright St. ----------- SO 51 179 80 447 45. Bob Higginson, Temple ------------- SO 46 156 63 . 404 11. John Burns, Md. -BaIt. County ------ SO 46 188 84 447 46. Ricky Bush, Jackson St. SR 34 114 46 . 404 12. Larry Sutton, Illinois ------------ JR 47 155 69 445 47. Ken Cavazzoni, Columbia ----------- SR 35 124 50 . 403 13. James Ruocchio, LIU-C. W. Post ----- SR 43 165 72 436 48. -
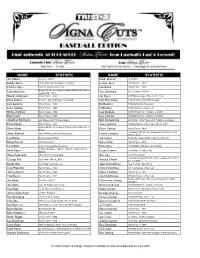
Printer-Friendly Version (PDF)
NAME STATISTIC NAME STATISTIC Jim Abbott No-Hitter 9/4/93 Ralph Branca 3x All-Star Bobby Abreu 2005 HR Derby Champion; 2x All-Star George Brett Hall of Fame - 1999 Tommie Agee 1966 AL Rookie of the Year Lou Brock Hall of Fame - 1985 Boston #1 Overall Prospect-Named 2008 Boston Minor Lars Anderson Tom Browning Perfect Game 9/16/88 League Off. P.O.Y. Sparky Anderson Hall of Fame - 2000 Jay Bruce 2007 Minor League Player of the Year Elvis Andrus Texas #1 Overall Prospect -shortstop Tom Brunansky 1985 All-Star; 1987 WS Champion Luis Aparicio Hall of Fame - 1984 Bill Buckner 1980 NL Batting Champion Luke Appling Hall of Fame - 1964 Al Bumbry 1973 AL Rookie of the Year Richie Ashburn Hall of Fame - 1995 Lew Burdette 1957 WS MVP; b. 11/22/26 d. 2/6/07 Earl Averill Hall of Fame - 1975 Ken Caminiti 1996 NL MVP; b. 4/21/63 d. 10/10/04 Jonathan Bachanov Los Angeles AL Pitching prospect Bert Campaneris 6x All-Star; 1st to Player all 9 Positions in a Game Ernie Banks Hall of Fame - 1977 Jose Canseco 1986 AL Rookie of the Year; 1988 AL MVP Boston #4 Overall Prospect-Named 2008 Boston MiLB Daniel Bard Steve Carlton Hall of Fame - 1994 P.O.Y. Philadelphia #1 Overall Prospect-Winning Pitcher '08 Jesse Barfield 1986 All-Star and Home Run Leader Carlos Carrasco Futures Game Len Barker Perfect Game 5/15/81 Joe Carter 5x All-Star; Walk-off HR to win the 1993 WS Marty Barrett 1986 ALCS MVP Gary Carter Hall of Fame - 2003 Tim Battle New York AL Outfield prospect Rico Carty 1970 Batting Champion and All-Star 8x WS Champion; 2 Bronze Stars & 2 Purple Hearts Hank -

The Science Behind an Unfair Game
The Science Behind an Unfair Game Moneyball by Michael Lewis W.W. Norton & Company Inc. ©2004 Nonfiction 301 Pages By Justin Moross “It’s unbelievable how much you don’t know about the game you’ve been playing all your life,” Mickey Mantle once said. As an avid baseball fan, and a high school baseball player, I thought I knew tons about baseball until I read Michal Lewis’ Moneyball. Michael Lewis’ striking best seller, no pun intended, examines the story of the poor market baseball team, the Oakland Athletics (also known as the A’s). Billy Beane, the General Manager of the A’s, adopts a theory created by Bill James, a baseball statistician and author, whose method is a tricky way for a general manager to build a baseball roster at an inexpensive price. This method happened to be called Moneyball, which gives the title its special meaning. In 2001, the A’s lost to the New York Yankees in the first round of the playoffs after a wonderful 102-win season. During the offseason, Oakland lost three of their most important players on their roster: Johnny Damon, Jason Giambi, and Jason Isringhausen. These players all signed for different teams who were much richer than the Athletics. Many fans and scouts couldn’t answer the Oakland A’s simple question: What is the problem? Is it the fact that they lost three of their key baseball players? Nope. Did they need to replace 39 home runs and 120 RBI’s? Nope. The problem is that there are rich teams and poor teams. -

True Harvest
Aaron Payne Fine Art October 3, 2020 TRUE HARVEST AARON PAYNE FINE ART • SANTA FE, NEW MEXICO Throughout the month of October, we will present a small offering of artworks. Each Saturday we will highlight a favorite charity. For each of these appeals, I tried to pick some artworks which related in theme or medium to the cause. I want the purchase of the work to be both an act of love and also something that will remind you of the charity when you enjoy it. I also wanted the purchase to be part of a collaboration between the art, the gallery, and the charity…. so, I lowered all the prices for the duration of this appeal. My hope is that selling them at this level benefits the charity as much as possible and also leaves the buyer feeling like they got something they love at a fair price. Our first charity is Nat King Cole Generation Hope. 1 Aaron Payne Fine Art October 3, 2020 ART, JAZZ, BASEBALL & THE KING Nat King Cole became the first African American entertainer to host a television variety show, in 1956. As such, he was the first Black man many White families “invited” into their living rooms. He was, in many ways, the Jackie Robinson of television and music. A virtuoso jazz pianist, he is now best remembered for his soft baritone voice, which he used to great effect in both big band and jazz genres. His popularity as a musical artist has never waned in the nearly sixty years since his death in 1964. -
Union Closing Already of Concern
TUESDAY, MAY 28, 2019 ‘The new emergency room at Salem Hospital cannot handle what both facilities handle right now. I think it’s going to impact the citizens in a negative way.’ — Fire Capt. Joseph Zukas Union closing already of concern By Gayla Cawley ready overcrowded and he doesn’t believe proved a $180 million expansion of North ITEM STAFF the new ER being built on the Salem cam- Shore Medical Center (NSMC) in 2016 pus will have the capacity for patients it that will close Union and move the beds LYNN — The impending closure of will see when Union Hospital closes. to a new Salem campus. The medical fa- Union Hospital is already having a neg- ative impact on the availability of ambu- Union Hospital is scheduled to close in cilities in Lynn and Salem are part of lance service for medical call response in May 2020, which will coincide with the Partners Healthcare. the city, according to the Lynn Fire De- opening of a new medical village on the “I don’t think people are fully prepared partment. site. The new facility will have urgent for it,” said Zukas, the city’s emergen- Lori Ehrlich Lynn Fire Capt. Joseph Zukas said with care services, but the city will no longer cy medical services (EMS) director. “The an increasing amount of the city’s ambu- have an emergency room after the hospi- new emergency room at Salem Hospital lance transports being diverted to Salem tal’s closure. Women lead Hospital, the emergency room there is al- The Department of Public Health ap- UNION, A3 the way in A salute to Memorial Day Swampscott By Bella diGrazia ITEM STAFF SWAMPSCOTT — Inspired by the town’s rst majority female Board of Selectmen, Swampscott will host its initial Women’s Leadership Forum.