Glottal Opening and Strategies of Production of Fricatives Benjamin Elie, Yves Laprie
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Larynx Anatomy
LARYNX ANATOMY Elena Rizzo Riera R1 ORL HUSE INTRODUCTION v Odd and median organ v Infrahyoid region v Phonation, swallowing and breathing v Triangular pyramid v Postero- superior base àpharynx and hyoid bone v Bottom point àupper orifice of the trachea INTRODUCTION C4-C6 Tongue – trachea In women it is somewhat higher than in men. Male Female Length 44mm 36mm Transverse diameter 43mm 41mm Anteroposterior diameter 36mm 26mm SKELETAL STRUCTURE Framework: 11 cartilages linked by joints and fibroelastic structures 3 odd-and median cartilages: the thyroid, cricoid and epiglottis cartilages. 4 pair cartilages: corniculate cartilages of Santorini, the cuneiform cartilages of Wrisberg, the posterior sesamoid cartilages and arytenoid cartilages. Intrinsic and extrinsic muscles THYROID CARTILAGE Shield shaped cartilage Right and left vertical laminaà laryngeal prominence (Adam’s apple) M:90º F: 120º Children: intrathyroid cartilage THYROID CARTILAGE Outer surface à oblique line Inner surface Superior border à superior thyroid notch Inferior border à inferior thyroid notch Superior horns à lateral thyrohyoid ligaments Inferior horns à cricothyroid articulation THYROID CARTILAGE The oblique line gives attachement to the following muscles: ¡ Thyrohyoid muscle ¡ Sternothyroid muscle ¡ Inferior constrictor muscle Ligaments attached to the thyroid cartilage ¡ Thyroepiglottic lig ¡ Vestibular lig ¡ Vocal lig CRICOID CARTILAGE Complete signet ring Anterior arch and posterior lamina Ridge and depressions Cricothyroid articulation -
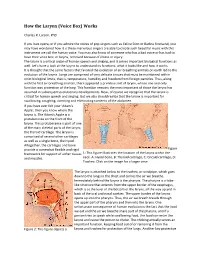
How the Larynx (Voice Box) Works
How the Larynx (Voice Box) Works Charles R. Larson, PhD If you love opera, or if you admire the voices of pop singers such as Celine Dion or Barbra Streisand, you may have wondered how it is these marvelous singers are able to create such beautiful music with this instrument we call the human voice. You may also know of someone who has a bad voice or has had to have their voice box, or larynx, removed because of illness or injury. The larynx is a critical organ of human speech and singing, and it serves important biological functions as well. Let's have a look at the larynx to understand its functions, what it looks like and how it works. It is thought that the same factors that favored the evolution of air‐breathing animals on earth led to the evolution of the larynx. Lungs are comprised of very delicate tissues that must be maintained within strict biological limits, that is, temperature, humidity and freedom from foreign particles. Thus, along with the first air‐breathing animals, there appeared a primitive sort of larynx, whose one and only function was protection of the lung. This function remains the most important of those the larynx has assumed in subsequent evolutionary developments. Now, of course we recognize that the larynx is critical for human speech and singing. But we also should realize that the larynx is important for swallowing, coughing, vomiting and eliminating contents of the abdomen. If you have ever felt your 'Adam's Apple', then you know where the larynx is. -

Larynx 2017‐2018 Naaccr Webinar Series
NAACCR 2017-2018 Webinar Series 11/2/2017 COLLECTING CANCER DATA: LARYNX 2017‐2018 NAACCR WEBINAR SERIES Q&A • Please submit all questions concerning webinar content through the Q&A panel. • Reminder: • If you have participants watching this webinar at your site, please collect their names and emails. • We will be distributing a Q&A document in about one week. This document will fully answer questions asked during the webinar and will contain any corrections that we may discover after the webinar. 2 Larynx 1 NAACCR 2017-2018 Webinar Series 11/2/2017 Fabulous Prizes 3 AGENDA • Anatomy • Epi Moment • Quiz 1 • Staging • Treatment • Quiz 2 • Case Scenarios 4 Larynx 2 NAACCR 2017-2018 Webinar Series 11/2/2017 ANATOMY LARYNX 5 LARYNX ANATOMY • Voice Box • Passageway of air • Extends from C3 to C6 vertebrae 6 Larynx 3 NAACCR 2017-2018 Webinar Series 11/2/2017 LARYNX ANATOMY • Divided into 3 Sections • Supraglottis • area above vocal cords, contains epiglottis • arytenoids, aryepiglottic folds and false cords • Glottis • containing true vocal cords, anterior and posterior commissures • Subglottis • below the vocal cords 7 LARYNX ANATOMY • Epiglottis • Aryepiglottic Folds • Anterior and Posterior • False vocal cords Commissure • True vocal cords • Arytenoids 8 Larynx 4 NAACCR 2017-2018 Webinar Series 11/2/2017 LARYNX ANATOMY • Thyroid cartilage • Arytenoid cartilage • Adam’s apple • Influence position and tension of the • Thyrohyoid membrane vocal cords • Cricoid cartilage • Corniculate cartilage • Inferior wall of larynx • Horn shaped pieces located -

Epiglottis Reconstruction with Auricular Free Flap For
ISSN: 2572-4193 Bottini et al. J Otolaryngol Rhinol 2017, 3:032 DOI: 10.23937/2572-4193.1510032 Volume 3 | Issue 2 Journal of Open Access Otolaryngology and Rhinology CASE REPORT Epiglottis Reconstruction with Auricular Free Flap for Re- habilitation of Dysphagia: A Case Study Battista Bottini G1*, Brandtner C1, Rasp G2 and Gaggl A1 1Department of Oral and Maxillofacial Surgery, University Hospital, Private Medical University Paracelsus, Austria 2Department of Ear, Nose and Throat, University Hospital, Private Medical University Paracelsus, Check for updates Austria *Corresponding author: Gian Battista Bottini, MD, DMD, Department of Oral and Maxillofacial Surgery, Uni- versity Hospital, Private Medical University Paracelsus, 48 Muellner Hauptstrasse, 5020 Salzburg, Austria, Tel: +43(0)57255-57230, Fax: +43(0)57255-26499, E-mail: [email protected] and requires a coordinated activity of nerves, muscles, Abstract the hyoid bone and the larynx [1]. The process can be Supraglottic laryngectomy for laryngeal cancer aims to remove divided in stages: oral pharyngeal and oesophageal [1]. cancer of the larynx whilst preserving its functions of airway protection, breathing and voice production. A well-known long- During the pharyngeal stage, the vocal cords adduct term complication of this procedure is aspiration. to seal the glottis and the arytenoid tilt forward to con- We present a case of a delayed epiglottis reconstruction tact the epiglottis base. with auricular free flap for surgical rehabilitation of dyspha- gia. Primarily the patient underwent supraglottic laryngecto- When the hyo-laryngeal complex is pulled in anterior my, bilateral neck dissection and radiotherapy. She had a and superior direction against the base of the tongue, permanent tracheostoma because of a complete paralysis the epiglottis, acting like a shield, tilts backwards and of the right vocal cord and a residual minimal mobility of the covers completely the glottis [1]. -

The Larynx Prof
The Larynx Prof. Dr.Mohammed Hisham Al-Muhtaseb The Larynx • Extends from the middle of C3 vertebra till the level of the lower border of C6 • Continue as Trachea • Above it opens into the laryngo-pharynx • Suspended from the hyoid bone above and attached to the trachea below by membranes and ligaments Functions • 1. acts as an open valve in respiration • 2. Acts as a closed valve in deglutition • 3. Acts as a partially closed valve in the production of voice • 4. During cough it is first closed and then open suddenly to release compressed air Parts • 1. Cartilage • 2. Mucosa • 3. Ligaments • 4. Muscles Cartilage • A. Single : Epiglottis Cricoid Thyroid B. Pairs: Arytenoid Cuneiform Corniculate Cricoid cartilage • The most inferior of the laryngeal cartilages • Completely encircles the airway • Shaped like a 'signet ring' • Broad lamina of cricoid cartilage posterior • Much narrower arch of cricoid cartilage circling anteriorly. Cricoid cartilage • Posterior surface of the lamina has two oval depressions separated by a ridge • The esophagus is attached to the ridge • Depressions are for attachment of the posterior crico-arytenoid muscles. • Has two articular facets on each side • One facet is on the sloping superolateral surface and articulates with the base of an arytenoid cartilage; • The other facet is on the lateral surface near its base and is for articulation with the inferior horn of the thyroid cartilage Thyroid cartilage • The largest of the laryngeal cartilages • It is formed by a right and a left lamina • Widely separated posteriorly, -
![English Is a Purely [Spread Glottis] Language](https://docslib.b-cdn.net/cover/0005/english-is-a-purely-spread-glottis-language-1200005.webp)
English Is a Purely [Spread Glottis] Language
English is a purely [spread glottis] language Dániel Huber (Sorbonne Nouvelle, Paris 3, France) & Katalin Balogné Bérces (PPKE University, Piliscsaba, Hungary) Aims: to show that: the received view, that English has a phonological opposition between voiceless and voiced obstruents, is mistaken (spelling?? other (truly voice) languages??) the correct characterization of the opposition: aspirated ([spread glottis] – [sg] for short) vs. unaspirated using a privative [sg] feature not only for plosives, but fricatives, too London, 14-17 July 2009 ICLCE3 2 Aims: to account for: the “lack” of aspiration in tautosyllabic s+C[obs] the devoicing of the sonorant in both C[sg]+C[son] and s+C[son] the "devoicing" of non-intersonorant lenis stops "bidirectional voice assimilation" the identical distribution of plosive aspiration and the segment /h/ London, 14-17 July 2009 ICLCE3 3 Laryngeal systems one-way contrast two-way contrast + three/four-way contrast... London, 14-17 July 2009 ICLCE3 4 Two-way laryngeal contrast in obstruents: [voice] vs. [spread glottis] languages* ("laryngeal realism" – Honeybone 2005): in what follows: arguments that voice and aspiration ([sg]) are two totally different mechanisms defining the two types of system and incompatible within two-way systems * cf. Iverson & Salmons 1995 (and subsequent publications), etc. London, 14-17 July 2009 ICLCE3 5 Two totally different mechanisms voice totally inactive in [sg] languages (English, German, etc.): no assimilation! instead: "bidirectional devoicing": => nothing happens! -

States of the Glottis for Voiceless Plosives
STATES OF THE GLOTTIS FOR VOICELESS PLOSIVES Jimmy G. Harris University of Victoria, Canada ABSTRACT stricture and the voicing onset of the following vowel has been While the state of glottis of voiceless aspirated stops has been called Voice Onset Time (VOT). The results of the VOT studies well documented, the state of the glottis of voiceless unaspirated have added another important acoustic dimension to the study of stops has not. We have therefore concentrated on the states of the overlapping stricture release phase of oral stops and the glottis of voiceless unaspirated stops including glottal stop. stricture closing (or onset) phase of following voiced vowels. Breath and nil phonation are traditionally regarded as the The results concerning voiceless oral stops point to a direct phonation types of voicelessness. Catford has described both as correlation between the degree of opening of the glottis and the having a wide open glottis, but differing in airflow turbulence. amount of positive VOT lag. The wider open they are, the longer By contrast, stops made with either the glottis closed or no air the VOT lag. passing through it he termed ÒunphonatedÓ. We consider existing Our purpose in this article is to provide a more detailed and definitions of nil phonation, breath, and unphonated to be systematic description of the states of the glottis during the inappropriate for describing the state of the glottis during the closure phase of the articulatory strictures of voiceless articulatory stricture phase of voiceless unaspirated oral stops. unaspirated oral stops and glottal stop. We have mainly limited We describe that state of the glottis and propose the term our discussion to our fiberoptic laryngoscopy study of the states prephonation be used to refer to it. -

Larynx Anatomy O Divided Into 3 Subsites: Glottis: True Vocal Folds
Larynx Anatomy o Divided into 3 subsites: Glottis: True vocal folds. Supraglottis: Structures above the true vocal folds Subglottis: Area between true vocal folds and trachea o Housed in a bony-cartilaginous framework Hyoid bone: superiorly suspends the thyroid cartilage Thyroid cartilage: Shield-like cartilage that creates framework; houses true vocal folds, false vocal folds Cricoid cartilage: Only complete ring in the upper airway; houses subglottic area Arytenoid cartilage: Paired cartilages responsible for vocal fold motion o True vocal folds Multi-layered structure . Body: Vocalis muscle, deep and intermediate lamina propria (ligament) . Cover: Superficial lamina propria, epithelial lining Intrinsic muscles act on the arytenoid cartilage to move vocal folds . Adductors = Muscles that move vocal folds medially to close the glottis [Thyroarytenoid (TA, bilateral); Lateral cricoarytenoid (LCA, bilateral); interarytenoid (IA)] . Abductor = Muscles that move vocal fold laterally to open the glottis. [Posterior cricoarytenoid (PCA, bilateral)} . Tension: Cricothryoid (CT), Bilateral, elongates and increases tension of the vocal folds o Nerve supply Recurrent laryngeal nerve: Branch of Vagus Nerve (Cranial Nerve X) . Supplies motor input to TA, LCA, PCA, IA muscles . Supplies sensation to the subglottis Superior laryngeal nerve: Branch of Vagus Nerve (Cranial Nerve X) . External branch supplies motor input to CT muscle . Internal branch supplies sensation to the glottis and supraglottis American Laryngological Association Comprehensive Laryngology Curriculum www.alahns.org Updated 04/15/2019 Lindsay Reder, MD Physiology and Function o The larynx is responsive for a complicated balance between breathing, lower airway protection/swallowing, and voice production o Lower airway protection: Most primitive function of larynx. Coordinated function during swallowing (closure of true and false vocal folds, aryepiglottic folds, and retroflexion of the epiglottis over the larynx) protects lower airways. -

Membranes of the Larynx
Membranes of the Larynx: Extrinsic membranes connect the laryngeal apparatus with adjacent structures for support. The thyrohyoid membrane is an unpaired fibro-elastic sheet which connects the inferior surface of the hyoid bone with the superior border of the thyroid cartilage. The thyrohyoid membrane has an opening in its lateral aspect to admit the internal laryngeal nerve and artery Figure 12-08 Thyrohyoid membrane. The Cricotracheal membrane connects the most superior tracheal cartilage with the inferior border of the cricoid cartilage Figure 07-09 Cricotracheal membrane/ligament. Intrinsic Membranes connect the laryngeal cartilages with each other to regulate movement. There are two intrinsic membranes: the conus elasticus and the quadrate membranes. The Conus Elasticus connects the cricoid cartilage with the thyroid and arytenoid cartilages. It is composed of dense fibroconnective tissue with abundant elastic fibers. It can be described as having two parts: The medial cricothyroid ligament is a thickened anterior part of the membrane that connects the anterior apart of the arch of the cricoid cartilage with the inferior border of the thyroid membrane. The lateral cricothyroid membranes originate on the superior surface of the cricoid arch and rise superiorly and medially to insert on the vocal process of the arytenoid cartilages posteriorly, and to the interior median part of the thyroid cartilage anteriorly. Its free borders form the VOCAL LIGAMENTS. Lateral aspect of larynx – right thyroid lamina removed. Figure 12-10 Conus elasticus. A. Right lateral aspect. B. superior aspect The paired Quadrangular Membranes connect the epiglottis with the arytenoid and thyroid cartilages. It arises from the lateral margins of the epiglottis and adjacent thyroid cartilage near the angle. -

LINGUISTICS 221 LECTURE #12 Features (Continued) 3. VOWEL
LINGUISTICS 221 LECTURE #12 Introduction to Phonetics and Phonology Features (continued) 3. VOWEL FEATURES: Basic vowel features: [front] [back] [high] [low] [tense] Study Table 4.3 (p.81) and Table 4.4 (p. 82) Other vowel features: [ATR] (Advanced Tongue Root), [long] [nasal] (for nasalized vowels), [stress] 4. PLACE FEATURES FOR CONSONANTS There are three place features distinguishing between consonants relating to places of articulation: [+labial] articulated with the lips [+coronal] articulated with the blade or tip of the tongue [+dorsal] articulated with the tongue body One articulator: + or – for the feature; two articulators (complex segments): both features have to be specified for example: [w] is [+labial, +dorsal] Glottal segment: no articulators are involved, thus they are [-labial, -coronal, -dorsal] Argument for recognizing places of articulation in the phonological patterning of languages: Classical Arabic example, p. 84. Explain! Features for classifying the coronals [anterior] [distributed] [strident] [lateral] 1 [anterior] articulated at the alveolar ridge or forward, e.g., [t] [s] [†] [+anterior] [ß] [c] [-anterior] [distributed] articulated with a constriction that extends for a relatively great distance along the vocal tract, e.g., [ß] [tíß] [+distributed] [t] [n] [-distributed] [strident] relevant to fricatives and affricates only; [+strident] segments cause a noisier kind of friction, e.g., [ß] [tíß] [+strident] [†] [∂] [-strident] [lateral] distinguishes between coronal liquids e.g., [l] [+lateral] [®] [-lateral] Features for classifying the dorsals Dorsal articulator: tongue body. It is also the primary articulator for vowels. e.g., [k] [g] [+dorsal] Study the list of segments classified with this feature: p. 87 Study Table 4.5 on p. 88 5. -

Function of the Posterior Cricoarytenoid Muscle in Phonation: in Vivo Laryngeal Model
Function of the posterior cricoarytenoid muscle in phonation: In vivo laryngeal model HONG-SHIK CHOI, MD, GERALD S. BERKE, MD, MING YE, MD, and JODY KREIMAN, PhD, Los Angeles, California The function of the posterior cricoarytenoid (PCA) muscle In phonation has not been well documented. To date, several electromyographlc studies have suggested that the PCA muscle Is not simply an abductor of the vocal folds, but also functions In phonation. This study used an In vivo canine laryngeal model to study the function of the PCA muscle. SUbglottic pressure and electroglottographlc, photoglottographlc, and acoustic waveforms were gathered from fiVe adult mongrel dogs under varying conditions of nerve stimulation. Subglottic pressure. fundamental frequency, sound Intensity, and vocal efficiency decreased with Increasing stimulation of the posterior branch of the recurrent laryngeal nerve. These results suggest that the PCA muscle not only acts to brace the larynx against the anterior pull of the adductor and cricothyroid muscles, but also functions Inhlbltorlly In phonation by controlling the phonatory glottal width. (OTOLARYNGOL HEAD NECK SURG 1993;109: 1043-51.) The important physiologicfunctions of the larynx during phonation in some clinical cases. Kotby and protection of the lower airway, phonation, and res Haugen? also observed increased activity in the 1 piration - are all mediated by the laryngeal mus PCA muscle during phonation and postulated that cles. Intrinsic laryngeal muscles are classified into the muscle is not simply an abductor of the vocal three groups: the tensors, which regulate the length cord. and tension of the vocal folds; the adductors, which Gay et al." observed increased activity in the PCA close the glottis; and the abductor, which opens the muscle during phonation in chest voice at high glottis. -
Continuum of Phonation Types
Phonation types: a cross-linguistic overview Matthew Gordon University of California, Santa Barbara Peter Ladefoged University of California, Los Angeles 1. Introduction Cross-linguistic phonetic studies have yielded several insights into the possible states of the glottis. People can control the glottis so that they produce speech sounds with not only regular voicing vibrations at a range of different pitches, but also harsh, soft, creaky, breathy and a variety of other phonation types. These are controllable variations in the actions of the glottis, not just personal idiosyncratic possibilities or involuntary pathological actions. What appears to be an uncontrollable pathological voice quality for one person might be a necessary part of the set of phonological contrasts for someone else. For example, some American English speakers may have a very breathy voice that is considered to be pathological, while Gujarati speakers need a similar voice quality to distinguish the word /baª|/ meaning ‘outside’ from the word /ba|/ meaning ‘twelve’ (Pandit 1957, Ladefoged 1971). Likewise, an American English speaker may have a very creaky voice quality similar to the one employed by speakers of Jalapa Mazatec to distinguish the word /ja0!/ meaning ‘he wears’ from the word /ja!/ meaning ‘tree’ (Kirk et al. 1993). As was noted some time ago, one person's voice disorder might be another person's phoneme (Ladefoged 1983). 2. The cross-linguistic distribution of phonation contrasts Ladefoged (1971) suggested that there might be a continuum of phonation types, defined in terms of the aperture between the arytenoid cartilages, ranging from voiceless (furthest apart), through breathy voiced, to regular, modal voicing, and then on through creaky voice to glottal closure (closest together).