A Review of Metadata Fields Associated with Podcast RSS Feeds
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Find the Best Hashtags for Your Business Hashtags Are a Simple Way to Boost Your Traffic and Target Specific Online Communities
CHECKLIST How to find the best hashtags for your business Hashtags are a simple way to boost your traffic and target specific online communities. This checklist will show you everything you need to know— from the best research tools to tactics for each social media network. What is a hashtag? A hashtag is keyword or phrase (without spaces) that contains the # symbol. Marketers tend to use hashtags to either join a conversation around a particular topic (such as #veganhealthchat) or create a branded community (such as Herschel’s #WellTravelled). HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 1 WAYS TO USE 3 HASHTAGS 1. Find a specific audience Need to reach lawyers interested in tech? Or music lovers chatting about their favorite stereo gear? Hashtags are a simple way to find and reach niche audiences. 2. Ride a trend From discovering soon-to-be viral videos to inspiring social movements, hashtags can quickly connect your brand to new customers. Use hashtags to discover trending cultural moments. 3. Track results It’s easy to monitor hashtags across multiple social channels. From live events to new brand campaigns, hashtags both boost engagement and simplify your reporting. HOW TO FIND THE BEST HASHTAGS FOR YOUR BUSINESS 2 HOW HASHTAGS WORK ON EACH SOCIAL NETWORK Twitter Hashtags are an essential way to categorize content on Twitter. Users will often follow and discover new brands via hashtags. Try to limit to two or three. Instagram Hashtags are used to build communities and help users find topics they care about. For example, the popular NYC designer Jessica Walsh hosts a weekly Q&A session tagged #jessicasamamondays. -
Samsung Podcasts RSS Spec 060921
Samsung Podcasts RSS Spec June 2021 SAMSUNG C&S SAMSUNG CONFIDENTIAL Introduction The purpose of this document is to provide technical guidelines to podcasters for optimal exposure of their RSS feeds on Samsung Podcasts. Notes • Submitting feeds to Samsung Podcasts will not prevent submission to other platforms. • Samsung Podcasts will not re-cache or re-host audio content. • These guidelines are meant to reflect requirements used by other standard podcast platforms. • Some requirements are meant to support future V2 features, marked in red. Samsung Proprietary and Confidential 2 RSS Feed Requirements Samsung Proprietary and Confidential 3 Feed Requirements: Podcast “Podcast” is defined as an ordered collection of episodes. A podcast must: • Be described by a valid RSS feed that conforms to RSS 2.0 specifications • Be freely reachable, not requiring login, token, or similar information • Be uniquely defined by its <link> field (Samsung Podcasts will handle a podcast as a new podcast if this field changes) Samsung Podcasts will use podcast metadata accessed via the <link> field. Podcasters will need to ensure that artwork files are valid, reachable, and accurate. Samsung Podcasts may choose to cache artwork and metadata to optimize performance, but will not cache or re-host audio data. Unreachable or uninterpretable RSS feeds will be disabled by Samsung Podcasts. Please ensure that explicit words in Podcast titles and descriptions are censored in your metadata before submitting. Failure to censor explicit words could result in suspension of content from the platform. 4 Feed Requirements: Episode “Episode” is defined as an audio segment expressed through an audio file. Podcast episodes must: • Be uniquely defined by its <guid> field (Samsung Podcasts will handle an episode as new if the GUID is new or changed) • Be freely reachable, not requiring login, token, or similar information • Provide a supported audio file format (mp3, m4a, aac, wav, ogg) Samsung Podcasts will use episode metadata accessed via the <link> field and episode <guid> field. -

Studying Social Tagging and Folksonomy: a Review and Framework
Studying Social Tagging and Folksonomy: A Review and Framework Item Type Journal Article (On-line/Unpaginated) Authors Trant, Jennifer Citation Studying Social Tagging and Folksonomy: A Review and Framework 2009-01, 10(1) Journal of Digital Information Journal Journal of Digital Information Download date 02/10/2021 03:25:18 Link to Item http://hdl.handle.net/10150/105375 Trant, Jennifer (2009) Studying Social Tagging and Folksonomy: A Review and Framework. Journal of Digital Information 10(1). Studying Social Tagging and Folksonomy: A Review and Framework J. Trant, University of Toronto / Archives & Museum Informatics 158 Lee Ave, Toronto, ON Canada M4E 2P3 jtrant [at] archimuse.com Abstract This paper reviews research into social tagging and folksonomy (as reflected in about 180 sources published through December 2007). Methods of researching the contribution of social tagging and folksonomy are described, and outstanding research questions are presented. This is a new area of research, where theoretical perspectives and relevant research methods are only now being defined. This paper provides a framework for the study of folksonomy, tagging and social tagging systems. Three broad approaches are identified, focusing first, on the folksonomy itself (and the role of tags in indexing and retrieval); secondly, on tagging (and the behaviour of users); and thirdly, on the nature of social tagging systems (as socio-technical frameworks). Keywords: Social tagging, folksonomy, tagging, literature review, research review 1. Introduction User-generated keywords – tags – have been suggested as a lightweight way of enhancing descriptions of on-line information resources, and improving their access through broader indexing. “Social Tagging” refers to the practice of publicly labeling or categorizing resources in a shared, on-line environment. -

Reuters Institute Digital News Report 2020
Reuters Institute Digital News Report 2020 Reuters Institute Digital News Report 2020 Nic Newman with Richard Fletcher, Anne Schulz, Simge Andı, and Rasmus Kleis Nielsen Supported by Surveyed by © Reuters Institute for the Study of Journalism Reuters Institute for the Study of Journalism / Digital News Report 2020 4 Contents Foreword by Rasmus Kleis Nielsen 5 3.15 Netherlands 76 Methodology 6 3.16 Norway 77 Authorship and Research Acknowledgements 7 3.17 Poland 78 3.18 Portugal 79 SECTION 1 3.19 Romania 80 Executive Summary and Key Findings by Nic Newman 9 3.20 Slovakia 81 3.21 Spain 82 SECTION 2 3.22 Sweden 83 Further Analysis and International Comparison 33 3.23 Switzerland 84 2.1 How and Why People are Paying for Online News 34 3.24 Turkey 85 2.2 The Resurgence and Importance of Email Newsletters 38 AMERICAS 2.3 How Do People Want the Media to Cover Politics? 42 3.25 United States 88 2.4 Global Turmoil in the Neighbourhood: 3.26 Argentina 89 Problems Mount for Regional and Local News 47 3.27 Brazil 90 2.5 How People Access News about Climate Change 52 3.28 Canada 91 3.29 Chile 92 SECTION 3 3.30 Mexico 93 Country and Market Data 59 ASIA PACIFIC EUROPE 3.31 Australia 96 3.01 United Kingdom 62 3.32 Hong Kong 97 3.02 Austria 63 3.33 Japan 98 3.03 Belgium 64 3.34 Malaysia 99 3.04 Bulgaria 65 3.35 Philippines 100 3.05 Croatia 66 3.36 Singapore 101 3.06 Czech Republic 67 3.37 South Korea 102 3.07 Denmark 68 3.38 Taiwan 103 3.08 Finland 69 AFRICA 3.09 France 70 3.39 Kenya 106 3.10 Germany 71 3.40 South Africa 107 3.11 Greece 72 3.12 Hungary 73 SECTION 4 3.13 Ireland 74 References and Selected Publications 109 3.14 Italy 75 4 / 5 Foreword Professor Rasmus Kleis Nielsen Director, Reuters Institute for the Study of Journalism (RISJ) The coronavirus crisis is having a profound impact not just on Our main survey this year covered respondents in 40 markets, our health and our communities, but also on the news media. -

ISCRAM2005 Conference Proceedings Format
Yee et al. The Tablecast Data Publishing Protocol The Tablecast Data Publishing Protocol Ka-Ping Yee Dieterich Lawson Google Medic Mobile [email protected] [email protected] Dominic König Dale Zak Sahana Foundation Medic Mobile [email protected] [email protected] ABSTRACT We describe an interoperability challenge that arose in Haiti, identify the parameters of a general problem in crisis data management, and present a protocol called Tablecast that is designed to address the problem. Tablecast enables crisis organizations to publish, share, and update tables of data in real time. It allows rows and columns of data to be merged from multiple sources, and its incremental update mechanism is designed to support offline editing and data collection. Tablecast uses a publish/subscribe model; the format is based on Atom and employs PubSubHubbub to distribute updates to subscribers. Keywords Interoperability, publish/subscribe, streaming, synchronization, relational table, format, protocol INTRODUCTION After the January 2010 earthquake in Haiti, there was an immediate need for information on available health facilities. Which hospitals had been destroyed, and which were still operating? Where were the newly established field clinics, and how many patients could they accept? Which facilities had surgeons, or dialysis machines, or obstetricians? Aid workers had to make fast decisions about where to send the sick and injured— decisions that depended on up-to-date answers to all these questions. But the answers were not readily at hand. The U. S. Joint Task Force began a broad survey to assess the situation in terms of basic needs, including the state of health facilities. The UN Office for the Coordination of Humanitarian Affairs (OCHA) was tasked with monitoring and coordinating the actions of the many aid organizations that arrived to help. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

Acceptable Use of Instant Messaging Issued by the CTO
State of West Virginia Office of Technology Policy: Acceptable Use of Instant Messaging Issued by the CTO Policy No: WVOT-PO1010 Issued: 11/24/2009 Revised: 12/22/2020 Page 1 of 4 1.0 PURPOSE This policy details the use of State-approved instant messaging (IM) systems and is intended to: • Describe the limitations of the use of this technology; • Discuss protection of State information; • Describe privacy considerations when using the IM system; and • Outline the applicable rules applied when using the State-provided system. This document is not all-inclusive and the WVOT has the authority and discretion to appropriately address any unacceptable behavior and/or practice not specifically mentioned herein. 2.0 SCOPE This policy applies to all employees within the Executive Branch using the State-approved IM systems, unless classified as “exempt” in West Virginia Code Section 5A-6-8, “Exemptions.” The State’s users are expected to be familiar with and to comply with this policy, and are also required to use their common sense and exercise their good judgment while using Instant Messaging services. 3.0 POLICY 3.1 State-provided IM is appropriate for informal business use only. Examples of this include, but may not be limited to the following: 3.1.1 When “real time” questions, interactions, and clarification are needed; 3.1.2 For immediate response; 3.1.3 For brainstorming sessions among groups; 3.1.4 To reduce chances of misunderstanding; 3.1.5 To reduce the need for telephone and “email tag.” 3.2 Employees must only use State-approved instant messaging. -
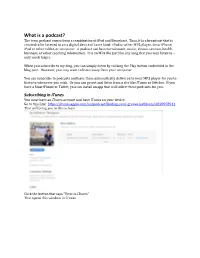
What Is a Podcast? the Term Podcast Comes from a Combination of Ipod and Broadcast
What is a podcast? The term podcast comes from a combination of iPod and Broadcast. Thus, it is a broadcast that is created to be listened to on a digital device of some kind: iPod or other MP3 player, SmartPhone, iPad or other tablet, or computer. A podcast can be entertainment, music, drama, sermon, health, business, or other coaching information. It is an MP3 file just like any song that you may listen to – only much larger. When you subscribe to my blog, you can simply listen by clicking the Play button embedded in the blog post. However, you may want to listen away from your computer. You can subscribe to podcasts and have them automatically delivered to your MP3 player for you to listen to whenever you wish. Or you can go out and listen from a site like iTunes or Stitcher. If you have a SmartPhone or Tablet, you can install an app that will collect these podcasts for you. Subscribing in iTunes You must have an iTunes account and have iTunes on your device. Go to this link: https://itunes.apple.com/us/podcast/finding-your-groove-kathleen/id829978911 That will bring you to this screen Click the button that says “View in iTunes” That opens this window in iTunes Click the Subscribe button just underneath the photo. To share this podcast with someone else, click the drop-down arrow just to the right of the Subscribe button. That will give you these share options: Tell a Friend, Share on Twitter, Share on Facebook, Copy Link (allows you to manually e-mail someone). -

Geotagging Photos to Share Field Trips with the World During the Past Few
Geotagging photos to share field trips with the world During the past few years, numerous new online tools for collaboration and community building have emerged, providing web-users with a tremendous capability to connect with and share a variety of resources. Coupled with this new technology is the ability to ‘geo-tag’ photos, i.e. give a digital photo a unique spatial location anywhere on the surface of the earth. More precisely geo-tagging is the process of adding geo-spatial identification or ‘metadata’ to various media such as websites, RSS feeds, or images. This data usually consists of latitude and longitude coordinates, though it can also include altitude and place names as well. Therefore adding geo-tags to photographs means adding details as to where as well as when they were taken. Geo-tagging didn’t really used to be an easy thing to do, but now even adding GPS data to Google Earth is fairly straightforward. The basics Creating geo-tagged images is quite straightforward and there are various types of software or websites that will help you ‘tag’ the photos (this is discussed later in the article). In essence, all you need to do is select a photo or group of photos, choose the "Place on map" command (or similar). Most programs will then prompt for an address or postcode. Alternatively a GPS device can be used to store ‘way points’ which represent coordinates of where images were taken. Some of the newest phones (Nokia N96 and i- Phone for instance) have automatic geo-tagging capabilities. These devices automatically add latitude and longitude metadata to the existing EXIF file which is already holds information about the picture such as camera, date, aperture settings etc. -

A Nova Mídia Podcast: Um Estudo De Caso Do Programa Matando Robôs Gigantes
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO CENTRO DE FILOSOFIA E CIÊNCIAS HUMANAS JORNALISMO A NOVA MÍDIA PODCAST: UM ESTUDO DE CASO DO PROGRAMA MATANDO ROBÔS GIGANTES TÁBATA CRISTINA PIRES FLORES RIO DE JANEIRO 2014 UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO CENTRO DE FILOSOFIA E CIÊNCIAS HUMANAS JORNALISMO A NOVA MÍDIA PODCAST: UM ESTUDO DE CASO DO PROGRAMA MATANDO ROBÔS GIGANTES Monografia submetida à Banca de Graduação como requisito para obtenção do diploma de Comunicação Social/ Jornalismo. TÁBATA CRISTINA PIRES FLORES Orientador: Octávio Aragão RIO DE JANEIRO 2014 UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO TERMO DE APROVAÇÃO A Comissão Examinadora, abaixo assinada, avalia a Monografia A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes, escrita por Tábata Flores. Monografia examinada: Rio de Janeiro, ___ de _______________ de 2014. Comissão Examinadora: Orientador: Prof. Octávio Aragão Doutor em Artes Visuais pela Escola de Belas Artes - UFRJ Departamento de Comunicação - UFRJ Prof. Fernando Mansur Doutor em Comunicação pela Escola de Comunicação - UFRJ Departamento de Comunicação - UFRJ Lúcio Luiz Corrêa da Silva Doutorando em Educação pela Universidade Estácio de Sá Programa de Pós-Graduação em Educação (Tecnologias de Informação e Comunicação nos Processos Educacionais) – Universidade Estácio de Sá RIO DE JANEIRO 2014 FICHA CATALOGRÁFICA FLORES, Tábata. A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes. Rio de Janeiro, 2014. Monografia (Graduação em Comunicação Social/Jornalismo) – Universidade Federal do Rio de Janeiro – UFRJ, Escola de Comunicação – ECO. Orientador: Octávio Aragão Orientadora: Raquel Paiva de Araújo Soares FLORES, Tábata. A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes. -

RSS (Really Simple Syndication) Is Offered by Some Websites to Allow Web Users to Be Alerted When Information Is Updated
What is RSS? RSS (Really Simple Syndication) is offered by some websites to allow web users to be alerted when information is updated. Users must subscribe to the website’s RSS feed in order to receive alerts on their desktop or mobile device. Feeds can also be used to deliver media content which you can view on your computer or mobile device. This is referred to as podcasting. How do I need if an RSS feed is available? If feeds are available on a website, the Feeds button will be displayed. How does a feed differ from a website? A feed can have the same content as a webpage, but it's often formatted differently. Why is the Shire using a RSS feed? The Shire has created an RSS feed for when it declares a Harvest and Vehicle Movement Ban. When the ban is declared, information is announced on ABC radio and displayed on the Shire’s main webpage. The RSS feed is another method for people wanting an instant alert. How do I subscribe to an RSS feed? To receive RSS feeds you may need to install an RSS feed reader. In more recent web browsers, feed readers are included as standard features. If you are using Microsoft Outlook or an up to date web browser, refer to the section on Browser Installation Guides below. If you do not already have a feed reader installed in your browser, you may need to install a separate RSS feed reader application. The Shire does not endorse or offer technical support for any third party products, though some commonly used RSS readers are listed below: Windows Microsoft Outlook 2007 or above Internet Explorer 7 and above Firefox Google Chrome FeedReader RSS Reader MAC Safari NewsFire RSS NetNews Wire Mobile (iOS, Android or Windows Mobile) RSS Reader Readers for those with visual impairments Podder . -

Tag Recommendations in Social Bookmarking Systems
1 Tag Recommendations in Social Bookmarking Systems Robert Jaschke¨ a,c Leandro Marinho b,d 1. Introduction Andreas Hotho a Lars Schmidt-Thieme b Gerd Stumme a,c Folksonomies are web-based systems that allow users to upload their resources, and to label them with a Knowledge & Data Engineering Group (KDE), arbitrary words, so-called tags. The systems can be dis- University of Kassel, tinguished according to what kind of resources are sup- 1 Wilhelmshoher¨ Allee 73, 34121 Kassel, Germany ported. Flickr , for instance, allows the sharing of pho- tos, del.icio.us2 the sharing of bookmarks, CiteULike3 http://www.kde.cs.uni-kassel.de 4 b and Connotea the sharing of bibliographic references, Information Systems and Machine Learning Lab and last.fm5 the sharing of music listening habits. Bib- (ISMLL), University of Hildesheim, 6 Sonomy allows to share bookmarks and BIBTEX based Samelsonplatz 1, 31141 Hildesheim, Germany publication entries simultaneously. http://www.ismll.uni-hildesheim.de In their core, these systems are all very similar. Once c Research Center L3S, a user is logged in, he can add a resource to the sys- Appelstr. 9a, 30167 Hannover, Germany tem, and assign arbitrary tags to it. The collection of all his assignments is his personomy, the collection of http://www.l3s.de folksonomy d all personomies constitutes the . The user Brazilian National Council Scientific and can explore his personomy, as well as the whole folk- Technological Research (CNPq) scholarship holder. sonomy, in all dimensions: for a given user one can see all resources he has uploaded, together with the tags he Abstract.