A Comprehensive Social Matrix Factorization with Social Regularization for Recommendation Based on Implicit Similarity by Fusing Trust Relationships and Social Tags
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Universities Receiving the Grant by Region Japan Hokkaido
List of Universities receiving the Grant by Region Japan Hokkaido University Hokkaido Kokushikan University Tokyo Tohoku Fukushi University Miyagi Musashino University Tokyo Tohoku University Miyagi Soka University Tokyo Akita International University Akita Showa Womens University Tokyo Yamagata University Yamagata J. F. Oberlin University Tokyo Fukushima University Fukushima Toho Gakuen College of Drama and Music Tokyo University of Tsukuba Ibaraki National Defense Academy of Japan Kanagawa Heisei International University Saitama Ferris University Kanagawa Meikai University Chiba Bunkyo University Kanagawa Tokyo University of Science Chiba Kanto Gakuin University Kanagawa Ryutsu Keizai University Chiba Keio University Kanagawa Nihon University College of Art Tokyo University of Niigata Prefecture Niigata Kaetsu University Tokyo University of Toyama Toyama University of Tokyo College of Arts and Science Tokyo Takaoka University of Law Toyama University of Tokyo Graduate School of Interdisciplinary Studies Tokyo Hokuriku University Ishikawa Waseda Unviersity Graduate School Tokyo Yamanashi Gakuin University Yamanashi Tokyo Gakugei University Tokyo Nihon University College of International Relations Shizuoka Hitotsubashi University Tokyo Aichi University Aichi Tokyo University of Foreign Studies Tokyo Aichi Prefectural University Aichi Meiji University Tokyo Ritsumeikan University Kyoto Teikyo University Tokyo Ryukoku University Kyoto Aoyama Gakuin University Tokyo Heian Jogakuin University Kyoto Nihon University College of Humanities and -

A Complete Collection of Chinese Institutes and Universities For
Study in China——All China Universities All China Universities 2019.12 Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities Anhui 安徽 【www.studyinanhui.com】 1. Anhui University 安徽大学 http://ahu.admissions.cn 2. University of Science and Technology of China 中国科学技术大学 http://ustc.admissions.cn 3. Hefei University of Technology 合肥工业大学 http://hfut.admissions.cn 4. Anhui University of Technology 安徽工业大学 http://ahut.admissions.cn 5. Anhui University of Science and Technology 安徽理工大学 http://aust.admissions.cn 6. Anhui Engineering University 安徽工程大学 http://ahpu.admissions.cn 7. Anhui Agricultural University 安徽农业大学 http://ahau.admissions.cn 8. Anhui Medical University 安徽医科大学 http://ahmu.admissions.cn 9. Bengbu Medical College 蚌埠医学院 http://bbmc.admissions.cn 10. Wannan Medical College 皖南医学院 http://wnmc.admissions.cn 11. Anhui University of Chinese Medicine 安徽中医药大学 http://ahtcm.admissions.cn 12. Anhui Normal University 安徽师范大学 http://ahnu.admissions.cn 13. Fuyang Normal University 阜阳师范大学 http://fynu.admissions.cn 14. Anqing Teachers College 安庆师范大学 http://aqtc.admissions.cn 15. Huaibei Normal University 淮北师范大学 http://chnu.admissions.cn Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities 16. Huangshan University 黄山学院 http://hsu.admissions.cn 17. Western Anhui University 皖西学院 http://wxc.admissions.cn 18. Chuzhou University 滁州学院 http://chzu.admissions.cn 19. Anhui University of Finance & Economics 安徽财经大学 http://aufe.admissions.cn 20. Suzhou University 宿州学院 http://ahszu.admissions.cn 21. -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -
1 Please Read These Instructions Carefully
PLEASE READ THESE INSTRUCTIONS CAREFULLY. MISTAKES IN YOUR CSC APPLICATION COULD LEAD TO YOUR APPLICATION BEING REJECTED. Visit http://studyinchina.csc.edu.cn/#/login to CREATE AN ACCOUNT. • The online application works best with Firefox or Internet Explorer (11.0). Menu selection functions may not work with other browsers. • The online application is only available in Chinese and English. 1 • Please read this page carefully before clicking on the “Application online” tab to start your application. 2 • The Program Category is Type B. • The Agency No. matches the university you will be attending. See Appendix A for a list of the Chinese university agency numbers. • Use the + by each section to expand on that section of the form. 3 • Fill out your personal information accurately. o Make sure to have a valid passport at the time of your application. o Use the name and date of birth that are on your passport. Use the name on your passport for all correspondences with the CLIC office or Chinese institutions. o List Canadian as your Nationality, even if you have dual citizenship. Only Canadian citizens are eligible for CLIC support. o Enter the mailing address for where you want your admission documents to be sent under Permanent Address. Leave Current Address blank. Contact your home or host university coordinator to find out when you will receive your admission documents. Contact information for you home university CLIC liaison can be found here: http://clicstudyinchina.com/contact-us/ 4 • Fill out your Education and Employment History accurately. o For Highest Education enter your current degree studies. -

Of the Students, by the Students, and for the Students
Of the Students, By the Students, and For the Students Of the Students, By the Students, and For the Students: Time for Another Revolution Edited by Martin Wolff Of the Students, By the Students, and For the Students: Time for Another Revolution, Edited by Martin Wolff This book first published 2010 Cambridge Scholars Publishing 12 Back Chapman Street, Newcastle upon Tyne, NE6 2XX, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2010 by Martin Wolff and contributors All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-4438-2565-4, ISBN (13): 978-1-4438-2565-8 English has become the gatekeeper to higher education and employment in China. This book is dedicated to all of those who are unable to unlock the gate and pass through. CET 4 and CET 6 National English examinations have become the symbol of English proficiency in reading and writing. Employers have required them as prerequisite to employment consideration. All comments of students quoted in this book were written by post-graduate students who have passed CET 4 and some have passed CET 6; and the comments were created on computers equipped with Microsoft WORD. The students’ comments are unedited to reflect their true lack of English competency and to debunk the claim that CET 4 and CET 6 reflect any appreciable English writing proficiency, particularly with the availability of the “spell function” of WORD. -

The Fourth International Conference on Law, Language and Discourse (LLD)
The Fourth International Conference On Law, Language and Discourse (LLD) October 18 -19, 2014, Xi'an, China The American Scholars Press Editors: Le Cheng, Qinglin Ma, Jinbang Du, Lisa Hale, et al. Cover Designer: Jian Li Published by The American Scholars Press, Inc. The Fourth International Conference on Law, Language and Discourse is published by the American Scholars Press, Inc., Marietta, Georgia, USA. No part of this book may be reproduced in any form or by any electronic or mechanical means including information storage and retrieval systems, without permission in writing from the publisher. Copyright © 2014 by the American Scholars Press All rights reserved. ISBN: 978-0-9861817-0-2 Printed in the United States of America 2 Preface Internationally, there is a growing interest from the academia and the legal professionals in the study of the interface between language and law. Locally, Language and Law is one of the core postgraduate programs, which can be traced back to the early 1990s at City University of Hong Kong. In recent years, exchanges and collaborations in language and law among universities such as City University of Hong Kong, Aston University, China University of Political Science and Law, Columbia Law School, Georgetown University and Peking University, have been frequent and productive. With Hong Kong, as an international city, playing an important role of the meeting point for different cultures and with China being the convergence of various jurisdictions, a new association – the Multicultural Association of Law and Language (hereafter as MALL) was founded in 2009 with the Secretariat located in Hong Kong. -

List of Universities Receiving the Grant by Region Japan Hokkaido
List of Universities receiving the Grant by Region Japan Hokkaido University Hokkaido Kokushikan University Tokyo Tohoku Fukushi University Miyagi Musashino University Tokyo Tohoku University Miyagi Soka University Tokyo Akita International University Akita Showa Womens University Tokyo Yamagata University Yamagata J. F. Oberlin University Tokyo Fukushima University Fukushima Toho Gakuen College of Drama and Music Tokyo University of Tsukuba Ibaraki National Defense Academy of Japan Kanagawa Heisei International University Saitama Ferris University Kanagawa Meikai University Chiba Bunkyo University Kanagawa Tokyo University of Science Chiba Kanto Gakuin University Kanagawa Ryutsu Keizai University Chiba Keio University Kanagawa Nihon University College of Art Tokyo University of Niigata Prefecture Niigata Kaetsu University Tokyo Niigata Sangyo University Niigata University of Tokyo College of Arts and Science Tokyo University of Toyama Toyama University of Tokyo Graduate School of Interdisciplinary Studies Tokyo Takaoka University of Law Toyama Waseda Unviersity Graduate School Tokyo Hokuriku University Ishikawa Tokyo Gakugei University Tokyo Yamanashi Gakuin University Yamanashi Hitotsubashi University Tokyo Nihon University College of International Relations Shizuoka Tokyo University of Foreign Studies Tokyo Aichi University Aichi Meiji University Tokyo Aichi Prefectural University Aichi Teikyo University Tokyo Ritsumeikan University Kyoto Aoyama Gakuin University Tokyo Ryukoku University Kyoto Nihon University College of Humanities -
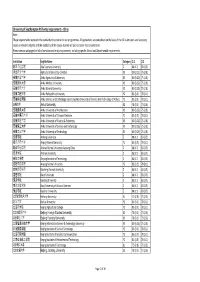
University of Southampton PGT Entry Requirements ‐ China Note: These Requirements Represent the Standard Entry Criteria for Our Programmes
University of Southampton PGT entry requirements ‐ China Note: These requirements represent the standard entry criteria for our programmes. All applications are considered on the basis of the full submission, and so strong scores in relevant subjects and the suitability of the course studied will also be taken into consideration. Please see our webpages for full information and entry requirements, including specific School and Departmental requirements. Institution English Name Category 2:1 2:2 阿坝师范学院 Aba Teachers University Z 88 (3.7) 83 (3.5) 河北农业大学 Agricultural University of Hebei X3 80 (3.25) 75 (2.8) 安徽农业大学 Anhui Agricultural University X3 80 (3.25) 75 (2.8) 安徽医科大学 Anhui Medical University X3 80 (3.25) 75 (2.8) 安徽师范大学 Anhui Normal University X3 80 (3.25) 75 (2.8) 安徽工程大学 Anhui Polytechnic University Y2 83 (3.5) 78 (3.1) 安徽科技学院 Anhui Science and Technology University (AKA University of Science And Technology of Anhui) Y2 83 (3.5) 78 (3.1) 安徽大学 Anhui University X2 78 (3.1) 73 (2.6) 安徽建筑大学 Anhui University of Architecture X3 80 (3.25) 75 (2.8) 安徽中医药大学 Anhui University of Chinese Medicine Y2 83 (3.5) 78 (3.1) 安徽财经大学 Anhui University of Finance & Economics X3 80 (3.25) 75 (2.8) 安徽理工大学 Anhui University of Science and Technology X3 80 (3.25) 75 (2.8) 安徽工业大学 Anhui University of Technology X3 80 (3.25) 75 (2.8) 安康学院 Ankang University Z 88 (3.7) 83 (3.5) 安庆师范大学 Anqing Normal University Y2 83 (3.5) 78 (3.1) 鞍山师范学院 Anshan Normal University Liaoning China Z 88 (3.7) 83 (3.5) 安顺学院 Anshun University Z 88 (3.7) 83 (3.5) 安阳工学院 Anyang Institute of Technology -

List of Regular Institutions of Higher Education In
Table 1 List of Regular Institutions of Higher Education in China (As of May 23th, 2011) (Total number:820) Serial Level of Name of Institution Affiliation Location Remarks No. -

Jews and Judaism in Modern China
Jews and Judaism in Modern China Jews and Judaism in Modern China explores and compares the dynamics at work in two of the oldest – and starkly contrasting – intact civilizations on earth: Jewish and Chinese. The book studies how they interact in modernity and how each views the other, and analyzes areas of cooperation between scholars, activists and politicians. Through evaluation of the respective talents, qualities and social assets that are fused and borrowed in the socio- economic, intellectual and cultural exchanges, we gain an insight into the social processes underpinning two dissimilar and long-surviving civilizations. Identifying and analyzing some of the emerging current issues, this book suggests that Jewish–Chinese relations may become a growing discipline of importance to the study of religion and comparative identity, and looks at how the significant contrasts in Jewish and Chinese national constructs may serve them well in the quest for a meaningful discourse. Chapters explore identity, integrity of the family unit, minority status, religious freedom, ethics and morality, tradition versus modernity, the environment, and other areas which are undergoing profound transformation. Identifying the intellectual and practical nexus and bifurcation between the two cultures, worldviews and identities, this work is indispensable for students of Chinese Studies, sociology, religion and the Jewish Diaspora, and provides useful reading for Western tourists to China. M. Avrum Ehrlich is a theologian, social philosopher and scholar of Jewish texts. He is a full professor of Judaic Studies at the Center for Judaic and Inter-Religious Studies at Shandong University, a government-funded national center for inter-religious research in Jinan, Shandong Province, the People’s Republic of China, and is also the Founding President of the Israel Asia Center, based in Jerusalem.