Towards Visual Semantics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Distribution Agreement in Presenting This Thesis Or Dissertation As A
Distribution Agreement In presenting this thesis or dissertation as a partial fulfillment of the requirements for an advanced degree from Emory University, I hereby grant to Emory University and its agents the non-exclusive license to archive, make accessible, and display my thesis or dissertation in whole or in part in all forms of media, now or hereafter known, including display on the world wide web. I understand that I may select some access restrictions as part of the online submission of this thesis or dissertation. I retain all ownership rights to the copyright of the thesis or dissertation. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation. Signature: _____________________________ ____3/31/16__________ Shelley Burian Date Flowers of Re: The floral origins and solar significance of rosettes in Egyptian art By Shelley Burian Master of Arts Art History _________________________________________ Rebecca Bailey, Ph.D., Advisor _________________________________________ Gay Robin, Ph.D., Committee Member _________________________________________ Walter Melion, Ph.D., Committee Member Accepted: _________________________________________ Lisa A. Tedesco, Ph.D. Dean of the James T. Laney School of Graduate Studies ___________________ Date Flowers of Re: The floral origins and solar significance of rosettes in Egyptian art By Shelley Burian B.A., First Honors, McGill University, 2011 An abstract of A thesis submitted to the Faculty of the James T. Laney School of Graduate Studies of Emory University in partial fulfillment of the requirements for the degree of Master of Arts In Art History 2016 Abstract Flowers of Re: The floral origins and solar significance of rosettes in Egyptian art By Shelley Burian Throughout the Pharaonic period in Egypt an image resembling a flower, called a rosette, was depicted on every type of art form from architecture to jewelry. -

Microsculpture of Cypsela Surface of Bellis L. (Asteraceae) in Libya Ghalia T
Research Article ISSN: 0976-7126 CODEN (USA): IJPLCP Rabiai & Elbadry , 12(2):1-5, 2021 [[ Microsculpture of cypsela surface of Bellis L. (Asteraceae) in Libya Ghalia T. El Rabiai* and Seham H. Elbadry Department of Botany, Faculty of Science, Benghazi University, Libya Abstract Article info In this study, the cypsela surfaces of three taxa belonging to the genus Bellis L. were investigated in details by means of electron microscopy. Received: 12/01/2021 The main aim of this study was to characterize the microsculpture of cypsela surface of the Libyan taxa of Bellis. (Asteraceae). Detailed Revised: 28/01/2021 descriptions of cypsela surface were given for each taxon. The results indicated that the examined taxa had very high variations regarding their Accepted: 27/02/2021 cypselae surfaces and these variations have great importance in determining the taxonomic relationships of the discussed taxa. Based on © IJPLS the results, pericarp texture and color could be used for taxonomical diagnosis. The fruit coat was usually roguish and its ornamentation was www.ijplsjournal.com fairly variable; therefore, this taxonomical microcharacter might also be useful in distinguishing closely related taxa. The hairiness of the surface of the pericarp was characteristic in the studied taxa. Key words: Bellis , Asteraceae, fruit surface, micromorphology, Libya [ Introduction The Asteraceae is a large family belonging to were observed among the taxa. Cypselae Asterales (Sennikov et al ., 2016) and is about were dry, indehiscent, unilocular, with a 10% of all angiosperms, comprises 1700 single seed that is usually not adnate to the genera and about 27000 accepted species pericarp (linked only by the funicle) and (Moreira et al . -

Flora Mediterranea 26
FLORA MEDITERRANEA 26 Published under the auspices of OPTIMA by the Herbarium Mediterraneum Panormitanum Palermo – 2016 FLORA MEDITERRANEA Edited on behalf of the International Foundation pro Herbario Mediterraneo by Francesco M. Raimondo, Werner Greuter & Gianniantonio Domina Editorial board G. Domina (Palermo), F. Garbari (Pisa), W. Greuter (Berlin), S. L. Jury (Reading), G. Kamari (Patras), P. Mazzola (Palermo), S. Pignatti (Roma), F. M. Raimondo (Palermo), C. Salmeri (Palermo), B. Valdés (Sevilla), G. Venturella (Palermo). Advisory Committee P. V. Arrigoni (Firenze) P. Küpfer (Neuchatel) H. M. Burdet (Genève) J. Mathez (Montpellier) A. Carapezza (Palermo) G. Moggi (Firenze) C. D. K. Cook (Zurich) E. Nardi (Firenze) R. Courtecuisse (Lille) P. L. Nimis (Trieste) V. Demoulin (Liège) D. Phitos (Patras) F. Ehrendorfer (Wien) L. Poldini (Trieste) M. Erben (Munchen) R. M. Ros Espín (Murcia) G. Giaccone (Catania) A. Strid (Copenhagen) V. H. Heywood (Reading) B. Zimmer (Berlin) Editorial Office Editorial assistance: A. M. Mannino Editorial secretariat: V. Spadaro & P. Campisi Layout & Tecnical editing: E. Di Gristina & F. La Sorte Design: V. Magro & L. C. Raimondo Redazione di "Flora Mediterranea" Herbarium Mediterraneum Panormitanum, Università di Palermo Via Lincoln, 2 I-90133 Palermo, Italy [email protected] Printed by Luxograph s.r.l., Piazza Bartolomeo da Messina, 2/E - Palermo Registration at Tribunale di Palermo, no. 27 of 12 July 1991 ISSN: 1120-4052 printed, 2240-4538 online DOI: 10.7320/FlMedit26.001 Copyright © by International Foundation pro Herbario Mediterraneo, Palermo Contents V. Hugonnot & L. Chavoutier: A modern record of one of the rarest European mosses, Ptychomitrium incurvum (Ptychomitriaceae), in Eastern Pyrenees, France . 5 P. Chène, M. -

Morphology, Anatomy, Palynology and Achene Micromorphology of Bellis L. (Asteraceae) Species from Turkey
Acta Bot. Croat. 79 (1), 59–67, 2020 CODEN: ABCRA 25 DOI: 10.37427/botcro-2020-006 ISSN 0365-0588 eISSN 1847-8476 Morphology, anatomy, palynology and achene micromorphology of Bellis L. (Asteraceae) species from Turkey Faruk Karahan* Department of Biology, Faculty of Science and Arts, Hatay Mustafa Kemal University, 31040 Hatay, Turkey Abstract – In the present study, the morphological characters, root, stem and leaf anatomy, pollen and achene micromorphology of Bellis L. species (Bellis annua L., B. perennis L. and B. sylvestris Cirillo) distributed in Turkey have been investigated on light and scanning electron microscope. Palynological analysis showed that pollen characters were found as small to medium size, isopolar, radially symmetrical, oblate-spheroidal and prolate- spheroidal, tricolporate and echinate-perforate ornamentation in the three species. Achene characters were found dark brown to yellow in colour, often cylindrical, compressed, with thickened margin, obovate orobovoid shaped, pappus absent and the coat ornamentations are rectangular with short hairs on the surface. As a result of this study, leaf morphology and some pollen characteristics such as pollen size, shape, perforation and distance be- tween spines were demonstrated to be different among the Bellis species. Keywords: Bellis, common daisy, Compositae, taxonomy, SEM Introduction The genus Bellis L. (Asteraceae) has been included in the Fiz et al. (2002) studied the phylogenetic relationships subtribe Bellidinae Willk. (tribe Astereae Cass.) along with between Bellis and the closely related genera (Bellidastrum 117 other genera representing more than 3000 annual or Scop, Bellium L. and Rhynchospermum Lindl.) and evolu- perennial taxa (Bremer 1994). It is native to western, cen- tion of their morphological characters. -

) 2 10( ;3 201 Life Science Journal 659
Science Journal 210(;3201Life ) http://www.lifesciencesite.com Habitats and plant diversity of Al Mansora and Jarjr-oma regions in Al- Jabal Al- Akhdar- Libya Abusaief, H. M. A. Agron. Depar. Fac. Agric., Omar Al-Mukhtar Univ. [email protected] Abstract: Study conducted in two areas of Al Mansora and Jarjr-oma regions in Al- Jabal Al- Akhdar on the coast. The Rocky habitat Al Mansora 6.5 km of the Mediterranean Sea with altitude at 309.4 m, distance Jarjr-oma 300 m of the sea with altitude 1 m and distance. Vegetation study was undertaken during the autumn 2010 and winter, spring and summer 2011. The applied classification technique was the TWINSPAN, Divided ecologically into six main habitats to the vegetation in Rocky habitat of Al Mansora and five habitats in Jarjr oma into groups depending on the average number of species in habitats and community: In Rocky habitat Al Mansora community vegetation type Cistus parviflorus, Erica multiflora, Teucrium apollinis, Thymus capitatus, Micromeria Juliana, Colchium palaestinum and Arisarum vulgare. In Jarjr oma existed five habitat Salt march habitat Community dominant species by Suaeda vera, Saline habitat species Onopordum cyrenaicum, Rocky coastal habitat species Rumex bucephalophorus, Sandy beach habitat species Tamarix tetragyna and Sand formation habitat dominant by Retama raetem. The number of species in the Rocky habitat Al Mansora 175 species while in Jarjr oma reached 19 species of Salt march habitat and Saline habitat 111 species and 153 of the Rocky coastal habitat and reached to 33 species in Sandy beach and 8 species of Sand formations habitat. -
Flora and Vegetation Outline of Mt. Pozzoni-St. Rufo Valley (Cittareale, Rieti)
PhytoKeys 178: 111–146 (2021) A peer-reviewed open-access journal doi: 10.3897/phytokeys.178.62947 CHECKLIST https://phytokeys.pensoft.net Launched to accelerate biodiversity research An unknown hotspot of plant diversity in the heart of the Central Apennine: flora and vegetation outline of Mt. Pozzoni-St. Rufo valley (Cittareale, Rieti) Edda Lattanzi1, Eva Del Vico2, Roberto Tranquilli3, Emmanuele Farris4, Michela Marignani5, Leonardo Rosati6 1 Via V. Cerulli 59, 00143 Roma, Italy 2 Dipartimento di Biologia Ambientale, Sapienza Università di Roma, P.le A. Moro 5, 00185 Roma, Italy 3 Via Achille Mauri 11, 00135 Roma, Italy 4 Department of Chemistry and Pharmacy, University of Sassari, Via Piandanna 4, 07100 Sassari, Italy 5 Department of Life and Environmental Sciences – Botany Division, University of Cagliari, Via Sant’Ignazio da Laconi 13, 09123 Cagliari, Italy 6 School of Agriculture, Forestry, Food and Environment, Via dell’Ateneo Lucano 10, University of Basilicata, 85100 Potenza, Italy Corresponding author: Eva Del Vico ([email protected]) Academic editor: Manuel Luján | Received 9 January 2021 | Accepted 9 March 2021 | Published 31 May 2021 Citation: Lattanzi E, Del Vico E, Tranquilli R, Farris E, Marignani M, Rosati L (2021) An unknown hotspot of plant diversity in the heart of the Central Apennine: flora and vegetation outline of Mt. Pozzoni-St. Rufo valley (Cittareale, Rieti). PhytoKeys 178: 111–146. https://doi.org/10.3897/phytokeys.178.62947 Abstract Surprisingly enough, Italy still has some botanically unexplored areas; among these there are some territo- ries between Lazio, Umbria and Abruzzo not included in any protected area. The study area, ranging for 340 ha, includes the mountainous area of Mt. -
Supporting Information. C. M. Herrera. 2020. Flower Traits, Habitat, and Phylogeny As Predictors of Pollinator Service: a Plant Community Perspective
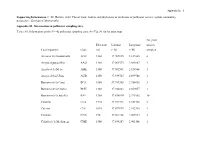
Appendix S1 – 1 Supporting Information. C. M. Herrera. 2020. Flower traits, habitat, and phylogeny as predictors of pollinator service: a plant community perspective. Ecological Monographs. Appendix S1. Information on pollinator sampling sites. TABLE S1. Information on the N = 42 pollinator sampling sites. See Fig. S1 for location map. No. plant Elevation Latitude Longitude species Local toponym Code (m) (º N) (º W) sampled Arenales del Guadalentín AGU 1360 37.909835 2.837405 4 Arroyo Aguaderillos AAG 1180 37.961573 2.883887 1 Arroyo de la Mesa AME 1100 37.902591 2.928966 1 Arroyo de los Ubios AUB 1250 37.939725 2.899766 1 Barranco de la Canal BCA 1580 37.789385 2.956438 3 Barranco de la Charca BCH 1360 37.942843 2.859057 1 Barranco de la Juanfría BJU 1380 37.836814 2.975302 10 Calarilla CLA 1710 37.944316 2.851708 2 Calerón CLE 1075 37.897973 2.942710 1 Cantalar CAN 770 37.964158 2.907974 3 Cañada de la Medianega CME 1580 37.894287 2.903146 1 Appendix S1 – 2 Cañada Pajarera CPA 1640 37.927456 2.805615 1 Collado del Calvario CCA 1420 37.950202 2.885484 1 Collado Zamora CZA 1420 37.839329 2.999615 2 Coto del Valle CVA 850 37.930542 2.928517 7 Cuesta del Bazar CBA 1330 37.906523 2.907470 1 Cuevas Bermejas CBE 1160 37.966959 2.851117 5 Fuente Bermejo FBE 1550 37.932268 2.840672 14 Fuente la Reina FRE 1460 37.941698 2.833632 2 Guadalentín GUA 1310 37.900404 2.836944 8 Hoyos de Muñoz HMU 1110 37.984831 2.876597 3 La Cabrilla LCA 1600 37.932364 2.780637 5 La Fresnedilla LFR 1080 37.980387 2.855875 2 La Mesa LME 1610 37.889823 2.913788 2 Las -

Flowers of Italy's Gargano Peninsula
Flowers of Italy's Gargano Peninsula Naturetrek Tour Report 15 - 22 April 2019 Ophrys scolopax ssp cornuta Orchis pauciflora Ophrys tenthredinifera Alpine Swift at Peschici Glanville Fritillary Report and images by Andrew Cleave Naturetrek Mingledown Barn Wolf's Lane Chawton Alton Hampshire GU34 3HJ UK T: +44 (0)1962 733051 E: [email protected] W: www.naturetrek.co.uk Tour Report Flowers of Italy's Gargano Peninsula Tour participants: Andrew Cleave & Andrew Bray (leaders) with nine Naturetrek clients. Summary We managed to fit plenty of sites and lots of plants into our week in the “Orchid Capital of Europe”, visiting a good variety of plant-rich habitats ranging from breezy coastal salt marshes and limestone sea cliffs to typical Mediterranean stony hillsides, olive groves and shady woodlands. The orchids did not fail to delight, and we found a superb selection of species during the week. The non-orchid flora was equally attractive with showy displays of Narcissi, Wild Tulips, Anemones and Irises, and plenty of the usual Mediterranean species in all the areas we visited. We were fortunate in that most of the locations we looked at were almost deserted and we were able to explore beautiful woodlands and open glades with only bird-song and cow-bells to be heard. Butterflies were spotted at most of the sites we visited, and there were plenty of other interesting insects to be found as well. Although we spent most of our time looking down at the plants, we did manage to produce a very good bird list with some exciting coastal species seen, as well as the more usual Mediterranean birds of stony hillsides and dark forests. -

Vascular Flora of Eight Water Reservoir Areas in Southern Italy
11 2 1593 the journal of biodiversity data February 2015 Check List LISTS OF SPECIES Check List 11(2): 1593, February 2015 doi: http://dx.doi.org/10.15560/11.2.1593 ISSN 1809-127X © 2015 Check List and Authors Vascular flora of eight water reservoir areas in southern Italy Antonio Croce Second University of Naples, Department of Environmental Biological and Pharmaceutical Sciences and Technologies, Via Vivaldi, 43, 8100 Caserta, Italy E-mail: [email protected] Abstract: Artificial lakes play an important role in Although many authors have reported the negative maintaining the valuable biodiversity linked to water impact of dams on rivers and their ecosystems (e.g., bodies and related habitats. The vascular plant diversity McAllister et al. 2001; Nilsson et al. 2005), dams are of eight reservoirs and surrounding areas in southern very important for wildlife, such as birds (Mancuso Italy was inventoried and further analysed in terms of 2010). Artificial lakes fulfill an important role as water biodiversity. A total of 730 specific and subspecific taxa reservoirs for agricultural irrigation; however, their were recorded, with 179 taxa in the poorest area and 303 other functions, such as recreation, fishing, and bio- in the richest one. The results indicate a good richness diversity conservation, should not be overlooked. The of the habitats surrounding the water basins, with some Italian National Institute for Economic Agriculture species of nature conservation interest and only a few (INEA) launched the project “Azione 7” (Romano and alien species. Costantini 2010) to assess the suitability of reservoirs in southern Italy for nature conservation purposes. -

A Sanctuary of Orchids a Protected Area on Holcim Land, Lebanon a Biodiversity Assessment 2014
A Sanctuary of Orchids A protected area on Holcim Land, Lebanon A biodiversity assessment 2014 INTERNATIONAL UNION FOR CONSERVATION OF NATURE Sweifiyeh, Hasan Baker Al Azzazi Street, #20 Amman, Jordan Tel: +962 (6) 5546912/3/4 Fax: +962 (6) 5546915 E-mail: [email protected] www.iucn.org/westasia The International Union for Conservation of Nature - Regional Office for West Asia Credits Acknowledgments The designation of geographical entities in this book, and the presentation of the material, do not imply The International Union for Conservation of the expression of any opinion whatsoever on the part of IUCN Regional Office of West Asia or other Nature – Regional Office for West Asia (IUCN partnering organizations concerning the legal status of any country, territory, or area, or of its authori- ROWA) would like to thank everyone who has ties, or concerning the delimitation of its frontiers or boundaries. supported the making of this book. The views expressed in this publication do not necessarily reflect those of IUCN Regional Office for We also thank the team for their support and West Asia or other partnering organizations. valuable contribution, for without them this could not have been accomplished. This publication has been made possible by funding from the Holcim (Liban) s.a.l. Author: Dr. Myrna Semaan Project team: Dr. Hany El Shaer, Dr. Myrna Cover & book photos : Dr. Myrna Semaan Semaan, Mr. Ziad Samaha and Ms. Lara Nassar Layout by: Magic Line – Jordan Special thanks go to the Holcim Team : Mr. Bene- Printed by: Magic Line – Jordan dikt Vonnegut, Mr. Jamil Bou-Haroun and Ms. -
Vernacular Names of Plants Between Diversity and Potential Risks Of
© 2021 Journal of Pharmacy & Pharmacognosy Research, 9 (2), 222-250, 2021 ISSN 0719-4250 http://jppres.com/jppres Original Article Vernacular names of plants between diversity and potential risks of confusion: Case of toxic plants used in medication in the central Middle Atlas, Morocco [Nombres vernáculos de las plantas entre la diversidad y los posibles riesgos de confusión: caso de las plantas tóxicas utilizadas en la medicación en el Atlas Medio central, Marruecos] Mariame Najem*, Laila Nassiri, Jamal Ibijbijen Environment and Valorisation of Microbial and Plant Resources Unit, Faculty of Sciences, Moulay Ismail University of Meknes, B.P: 11201 Meknes, Morocco. *E-mail: [email protected], [email protected] Abstract Resumen Context: Knowledge of medicinal plants is the first step in preserving Contexto: El conocimiento de las plantas medicinales es el primer paso traditional use and preventing intoxication. para preservar el uso tradicional y prevenir la intoxicación. Aims: To highlight the risks of intoxication related to the similarities of Objetivos: Destacar los riesgos de intoxicación relacionados con las vernacular names between medicinal plants and to confusion during similitudes de los nombres vernáculos de las plantas medicinales y con harvesting. la confusión durante la cosecha. Methods: Indigenous knowledge on the traditional use of toxic plants for Métodos: Los conocimientos indígenas sobre el uso tradicional de las medicinal purposes was gathered through direct interviews with plantas tóxicas con fines medicinales se reunieron mediante entrevistas practitioners of herbal medicine and field surveys in the Central Middle directas con profesionales de la medicina herbaria y estudios de campo Atlas. The vernacular names were collected from the respondents and en el Atlas Medio central. -
Study of Essential Oils and Phenolic Compounds; Their Changes and Anticancer Activity in Some Species Belonging to Asteraceae and Lamiaceae Families
People’s Democratic Republic of Algeria Ministry of Higher Education and Scientific Research Larbi Ben M’hidi University - Oum El Bouaghi Faculty of Exact Sciences and Life Sciences and Nature Departement of Life Sciences and Nature Thesis Presented by: Maarfia Sara SUBMITTED FOR THE DEGREE OF: DOCTORAT OF SCIENCES In Biological Sciences Option: Applied Biochemistry Study of essential oils and phenolic compounds; their changes and anticancer activity in some species belonging to Asteraceae and Lamiaceae families. Discussed on: Members of jury: Chairman: Noureddine GHERRAF Prof. Larbi Ben M’hidi University Oum El Bouaghi Supervisor: Amar ZELLAGUI Prof. Larbi Ben M’hidi University Oum El Bouaghi Examiner: Lekhmissi ARRAR Prof. Ferhat Abbas University Setif Examiner: Noureddine CHAREF Prof. Ferhat Abbas University Setif Examiner: Youcef NECIB Prof. Mentouri Brothers University Constantine 1 2018/2019 I dedicate this research work To My Beloved Father and Loving Mother For Their Love And Support Most Precious For Me In This World, My Sisters My Family All My Teachers All My Friends And Colleagues i Acknowledgements In the name of ALLAH who gave me strength and courage to accomplish this task. I bow my head to Almighty ALLAH with the core of my heart who provided me the opportunity of exploring the texture of this natural beauty on the Applied Biochemistry level. At first, I would like to express my gratitude to my supervisor, Professor Amar Zellagui, for his constant support, patience and efficient supervision and for providing an amiable working environment. It was great to have the privilege to work with him and to learn from his expertise in the past years.