Mining the Web for Sympathy: the Pussy Riot Case
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Pussy Riot Affair: Gender and National Identity in Putin's Russia 1 Peter Rutland 2 the Pussy Riot Affair Was a Massive In
The Pussy Riot affair: gender and national identity in Putin’s Russia 1 Peter Rutland 2 The Pussy Riot affair was a massive international cause célèbre that ignited a widespread movement of support for the jailed activists around the world. The case tells us a lot about Russian society, the Russian state, and Western perceptions of Russia. It also raises interest in gender as a frame of analysis, something that has been largely overlooked in 20 years of work by mainstream political scientists analyzing Russia’s transition to democracy.3 There is general agreement that the trial of the punk rock group signaled a shift in the evolution of the authoritarian regime of President Vladimir Putin. However, there are many aspects of the affair still open to debate. Will the persecution of Pussy Riot go down in history as one of the classic trials that have punctuated Russian history, such as the arrest of dissidents Andrei Sinyavsky and Yuli Daniel in 1966, or the trial of revolutionary Vera Zasulich in 1878? Or is it just a flash in the pan, an artifact of media fascination with attractive young women behaving badly? The case also poses a challenge for feminists. While some observers, including Janet Elise Johnson (below), see Pussy Riot as part of the struggle for women’s rights, others, including Valerie Sperling and Marina Yusupova, raise questions about the extent to Pussy Riot can be seen as advancing the feminist cause. Origins Pussy Riot was formed in 2011, emerging from the underground art group Voina which had been active since 2007. -

The Problematic Westernization of Pussy Riot
Macalester College DigitalCommons@Macalester College Gateway Prize for Excellent Writing Academic Programs and Advising 2020 The Riot Continues: The Problematic Westernization of Pussy Riot Adam Clark Macalester College Follow this and additional works at: https://digitalcommons.macalester.edu/studentawards Part of the Music Commons Recommended Citation Clark, Adam, "The Riot Continues: The Problematic Westernization of Pussy Riot" (2020). Gateway Prize for Excellent Writing. 16. https://digitalcommons.macalester.edu/studentawards/16 This Gateway Prize for Excellent Writing is brought to you for free and open access by the Academic Programs and Advising at DigitalCommons@Macalester College. It has been accepted for inclusion in Gateway Prize for Excellent Writing by an authorized administrator of DigitalCommons@Macalester College. For more information, please contact [email protected]. Adam Clark Victoria Malawey, Gender & Music The Riot Continues: The Problematic Westernization of Pussy Riot “We’re gonna take over the punk scene for feminists” -Kathleen Hanna Although they share feminist ideals, the Russian art collective Pussy Riot distinguishes themselves from the U.S.-based Riot Grrrl Movement, as exemplified by the band Bikini Kill, because of their location-specific protest work in Moscow. Understanding how Pussy Riot is both similar to and different from Riot Grrrl is important for contextualizing the way we think about diverse, transnational feminisms so that we may develop more inclusive and nuanced ways in conceptualizing these feminisms in the future. While Pussy Riot shares similar ideals championed by Bikini Kill in the Riot Grrrl movement, they have temporal and location-specific activisms and each group has their own ways of protesting injustices against women and achieving their unique goals. -
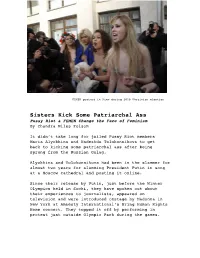
Pussy Riot & Femen
FEMEN protest in Kiev during 2010 Ukrainian election Sisters Kick Some Patriarchal Ass Pussy Riot & FEMEN Change the Face of Feminism By Chandra Niles Folsom It didn’t take long for jailed Pussy Riot members Maria Alyokhina and Nadezhda Tolokonnikova to get back to kicking some patriarchal ass after being sprung from the Russian Gulag. Alyokhina and Tolokonnikova had been in the slammer for almost two years for slamming President Putin in song at a Moscow cathedral and posting it online. Since their release by Putin, just before the Winter Olympics held in Sochi, they have spoken out about their experiences to journalists, appeared on television and were introduced onstage by Madonna in New York at Amnesty International’s Bring Human Rights Home concert. They topped it off by performing in protest just outside Olympic Park during the games. The band was in town to protest what they said was lack of freedom of speech and to record a new music video called "Putin Will Teach You To Love Your Country." And as they have become well accustomed, Pussy Riot members were attacked by security officials and beaten. www.youtube.com/watch?v=ivT-I-yxtdY Donning their traditional colorful ski masks, Pussy Riot was performing when they were pepper-sprayed by a Russian Cossack before other Cossacks jumped in, publicly flogging and unmasking them. One of the band's posse said that the Cossacks shouted at them, “You sold yourselves to the Americans!" A day earlier, band members had been detained and held for several hours at a police station nearby. -

2.2. What Does the Balaclava Stand For? Pussy Riot: Just Some Stupid Girls Or Punk with Substance?
2.2. What does the Balaclava stand for? Pussy Riot: just some stupid girls or punk with substance? Alexandre M. da Fonseca 1 Abstract 5 punk singers walk into the Cathedral of Christ the Savior in Moscow, address the Mother of God herself, ask her to free Russia from Putin and “become a feminist”. They are stopped by the security and three members are later arrested. The rest is history… Nevertheless, Pussy Riot have proven to be more complex. This article aims to go beyond the dichotomies and the narratives played out in Western and Russian media. Given the complexity of the affair, this article aims to dissect the political thought, the ideas (or ideology), the philosophy behind their punk direct actions. Focusing on their statements, lyrics and letters and the brechtian way they see “art as a transformative tool”, our aim is to ask what does the balaclava stand for? Are they really just some stupid punk girls or is there some substance to their punk? Who are (politically) the Pussy Riot? Keywords: Pussy Riot; Punk and Direct Action; Political Thought; Critical Discourse Analysis; 3rd wave feminism Who are the Pussy Riot? Are they those who have been judged in court and sentenced to prison? Or those anonymous member who have shunned the two persecuted girl? Or maybe it’s everyone who puts a balaclava and identifies with the rebellious attitude of the Russian group? Then, are Pussy Riot an “Idea” or are they impossible to separate from the faces of Nadia and Masha? This is the first difficulty of discussing Pussy Riot – defining who their subject is. -

Pussy Riot and the Translatability of Cultures
transcultural studies 13 (2017) 264-286 brill.com/ts Pussy Riot and the Translatability of Cultures Irina Dzero and Tatyana Bystrova Kent State University [email protected]; [email protected] Abstract The punk feminist collective Pussy Riot translate new ideas by embedding them in the visual symbols of the target culture. With their short bright-colored dresses and tights they tap into the stylistics of the Russian female performance as non-threatening am- biance to take the stage and protest against misogyny and authoritarianism. In 2012 they performed at Moscow’s Christ the Savior Cathedral and asked the Virgin Mary to put an end to Vladimir Putin’s rule. They were captured and sentenced to two years in prison for instigating religious hatred. Welcomed in the West, they made a music video “I Can’t Breathe” (2015) using the case of Eric Garner to explain the tolerance for au- thority in Russia. We look at the eclectic mix of thinkers and artists Pussy Riot named as their inspirers, and use the collective’s work to examine the changing attitude to the translatability of cultures. Keywords Pussy Riot – tolerance for authority – authoritarianism – intercultural translation – performance art Pussy Riot, a Russian punk feminist collective, rose to fame after their “punk prayer” – dancing at the altar at the Moscow Christ the Savior Cathedral and asking the Virgin Mary to “chase away” Vladimir Putin, Russia’s ruler since 2000. This article examines the collective’s work as intercultural translation: they seek to make intelligible bodies of knowledge poorly known or understood in the target culture. -

Pussy Riot and Its Aftershocks: Politics and Performance in Putin’S Russia
Pussy Riot and Its Aftershocks: Politics and Performance in Putin’s Russia Victoria Kouznetsov Senior Thesis May 6, 2013 When the all-female anarcho-punk group Pussy Riot staged a protest performance at the Cathedral of Christ the Savior—the spiritual heart of Moscow—in February of 2012, which led to the arrests of three members, they provoked a flood of public responses that quickly spilled over the borders of the Russian Federation. The significance of their “performance” can be gauged by the strength and diversity of these responses, of support and condemnation alike, that were voiced so vocally in the months leading up to and following the trial of Yekaterina Samutsevich, Nadezhda Tolokonnikova, and Maria Alyokhina (ages 30, 23, and 24, respectively). The discourse surrounding the group’s performance, amplified by the passions surrounding the imminent reelection of Vladimir Putin to a third term as president on May 7, 2012, reveals many emerging rifts in Russia’s social and political fabric. At a time when Russia faces increasingly challenging questions about its national identity, leadership, and role in the post-Soviet world, the action, arrest and subsequent trial of Pussy Riot serves as an epicenter for a diverse array of national and international quakes. The degree to which politicians, leaders of civil society, followers of the Russian Orthodox faith, and influential figures of the art scene in Russia rallied around the Pussy Riot trial speaks to the particularly fraught timing of the performance and its implications in gauging Russia’s emerging social and political trends. The disproportionately high degree of media attention given to the case by the West, however, has added both temporal and spatial dimensions to the case, evoking Cold War rhetoric both in Russia and abroad. -

'Frostpolitik'? Merkel, Putin and German Foreign Policy Towards Russia
From Ostpolitik to ‘frostpolitik’? Merkel, Putin and German foreign policy towards Russia TUOMAS FORSBERG* Germany’s relationship with Russia is widely considered to be of fundamental importance to European security and the whole constitution of the West since the Second World War. Whereas some tend to judge Germany’s reliability as a partner to the United States—and its so-called Westbindung in general—against its dealings with Russia, others focus on Germany’s leadership of European foreign policy, while still others see the Russo-German relationship as an overall barometer of conflict and cooperation in Europe.1 How Germany chooses to approach Russia and how it deals with the crisis in Ukraine, in particular, are questions that lie at the crux of several possible visions for the future European order. Ostpolitik is a term that was coined to describe West Germany’s cooperative approach to the Soviet Union and other Warsaw Pact countries, initiated by Chan- cellor Willy Brandt in 1969. As formulated by Brandt’s political secretary, Egon Bahr, the key idea of the ‘new eastern policy’ was to achieve positive ‘change through rapprochement’ (Wandel durch Annäherung). In the Cold War context, the primary example of Ostpolitik was West Germany’s willingness to engage with the Soviet Union through energy cooperation including gas supply, but also pipeline and nuclear projects.2 Yet at the same time West Germany participated in the western sanctions regime concerning technology transfer to the Soviet Union and its allies, and accepted the deployment of American nuclear missiles on its soil as a response * This work was partly supported by the Academy of Finland Centre of Excellence for Choices of Russian Modernisation (grant number 250691). -

Feminist Protest and Anti-Feminist Resurgence in Russia
Feminist Encounters: A Journal of Critical Studies in Culture and Politics, 2(1), 05 ISSN: 2542-4920 Pussy Provocations: Feminist Protest and Anti-Feminist Resurgence in Russia Jessica Mason 1* Published: March 19, 2018 ABSTRACT The Russian feminist punk-art group Pussy Riot sparked a remarkable series of responses with their provocative “punk prayer” in a Moscow cathedral in 2012. This article analyzes the social, political, and cultural dynamics of provocation (provokatsiya) by examining everyday conversations, speeches, articles and other linguistic acts through which Russian Orthodox, feminist, and left-leaning and liberal participants in the anti-Putin opposition made sense of Pussy Riot. A provocation violates norms in ways that compel observers to name and defend those norms. This process simultaneously invigorates norms and helps people shore up their own senses of self amid uncertainty. Yet what observers identify as the provocation — what norms are perceived to be violated — shapes what values they reinforce. Responding to Pussy Riot, Russian Orthodox activists asserted themselves as defenders of tradition against the forces of Western cultural imperialism, including feminism and LGBT rights. Yet most responses from the anti-Putin opposition focused on norms related to speech and protest rights, while Russian feminists were often reluctant even to claim Pussy Riot as feminist at all. Due to this asymmetry, Pussy Riot’s feminist protest revitalized anti- feminism in Russia without a concomitant strengthening of feminist values among supporters. Keywords: Russia, feminist politics, right-wing politic INTRODUCTION We consider the “punk prayer” an extremist crime, degrading millions of women of faith, and demand an appropriate legal assessment be given by society and those in power to this action. -

Detecting Malign Or Subversive Information Efforts Over Social Media
C O R P O R A T I O N WILLIAM MARCELLINO, KRYSTYNA MARCINEK, STEPHANIE PEZARD, MIRIAM MATTHEWS Detecting Malign or Subversive Information Efforts over Social Media Scalable Analytics for Early Warning For more information on this publication, visit www.rand.org/t/RR4192 Library of Congress Cataloging-in-Publication Data is available for this publication. ISBN: 978-1-9774-0379-7 Published by the RAND Corporation, Santa Monica, Calif. © Copyright 2020 RAND Corporation R® is a registered trademark. Limited Print and Electronic Distribution Rights This document and trademark(s) contained herein are protected by law. This representation of RAND intellectual property is provided for noncommercial use only. Unauthorized posting of this publication online is prohibited. Permission is given to duplicate this document for personal use only, as long as it is unaltered and complete. Permission is required from RAND to reproduce, or reuse in another form, any of its research documents for commercial use. For information on reprint and linking permissions, please visit www.rand.org/pubs/permissions. The RAND Corporation is a research organization that develops solutions to public policy challenges to help make communities throughout the world safer and more secure, healthier and more prosperous. RAND is nonprofit, nonpartisan, and committed to the public interest. RAND’s publications do not necessarily reflect the opinions of its research clients and sponsors. Support RAND Make a tax-deductible charitable contribution at www.rand.org/giving/contribute www.rand.org Preface This publication outlines the need for scalable analytic means to detect malign or subversive information efforts, lays out the methods and workflows used in detection of these efforts, and details a case study addressing such efforts during the 2018 World Cup. -

Nation, Ethnicity and Race on Russian Television
Nation, Ethnicity and Race on Russian Television Russia, one of the most ethno-culturally diverse countries in the world, provides a rich case study on how globalization and associated international trends are disrupting and causing the radical rethinking of approaches to inter-ethnic cohe- sion. The book highlights the importance of television broadcasting in shaping national discourse and the place of ethno-cultural diversity within it. It argues that television’s role here has been reinforced, rather than diminished, by the rise of new media technologies. Through an analysis of a wide range of news and other television programmes, the book shows how the covert meanings of discourse on a particular issue can diverge from the overt significance attributed to it, just as the impact of that dis- course may not conform with the original aims of the broadcasters. The book discusses the tension between the imperative to maintain security through cen- tralized government and overall national cohesion that Russia shares with other European states, and the need to remain sensitive to, and to accommodate, the needs and perspectives of ethnic minorities and labour migrants. It compares the increasingly isolationist popular ethno-nationalism in Russia, which harks back to ‘old-fashioned’ values, with the similar rise of the Tea Party in the United States and the UK Independence Party in Britain. Throughout, this extremely rich, well-argued book complicates and challenges received wisdom on Russia’s recent descent into authoritarianism. It points to a regime struggling to negotiate the dilemmas it faces, given its Soviet legacy of ethnic particularism, weak civil society, large native Muslim population and over- bearing, yet far from entirely effective, state control of the media. -

Should Russia's RT Register As a Foreign Agent?
AtlanticAtlantic Council Council DINU PATRICIU EURASIA CENTER DINU PATRICIU EURASIA CENTER Should Russia’s RT Register as a Foreign Agent? AGENT OF INFLUENCE Should Russia’s RT Register as a Foreign Agent? By ElenaBy Elena Postnikova Postnikova Foreword by Alina Polyakova AGENT OF INFLUENCE By Elena Postnikova The author would like to thank Judge James Baker, a visiting professor of National Security at Georgetown University Law Center and former Chief Judge of the US Court of Appeals for the Armed Forces, and Thomas Firestone of Baker McKenzie for their thoughtful comments and guidance in preparing this project. ISBN: 978-1-61977-408-7 This report is written and published in accordance with the Atlantic Council Policy on Intellectual Independence. The author is solely responsible for its analysis and recommendations. The Atlantic Council and its donors do not determine, nor do they necessarily endorse or advocate for, any of this report’s conclusions. August 2017 Table of Contents Table of Contents .............................................................................................................................1 Foreword ............................................................................................................................................2 Introduction .......................................................................................................................................3 Foreign Agents Registration Act of 1938 ............................................................................. -

Infiltrating the Space, Hijacking the Platform: Pussy Riot, Sochi Protests, and Media Events
. Volume 12, Issue 1 May 2015 Infiltrating the space, hijacking the platform: Pussy Riot, Sochi protests, and media events Kenzie Burchell, University of Toronto, Canada Abstract: The contemporary reformulation of the media events framework often focuses on the transformative role of mobile, video and social networking technologies in a global context, eclipsing another fundamental dimension: the geographically-bounded space of the media event. This article examines the surveillance and control of the physical space by organizers of the media event in an effort to control the wider global narrative extending beyond it, in this case the narrative of the controversial 2014 Winter Olympic Games in Sochi, Russia. For activists and other actors excluded from contributing to this narrative, infiltration of the physical space represents a potential vehicle for mobilizing media attention and engaging audiences with an alternative interpretation of the spectacle. Key words: Media Events, Protest, Geography, Olympics, Russia, Pussy Riot, LGBT, Twitter Introduction The contemporary reformulation of the media events framework often focuses, justifiably, on the transformative role of mobile, video and social networking technologies. When concentrating on these new media practices and the related changes to audience engagement and broadcasting formats, however, a particular element of Dayan and Katz’ (1992) original media events framework is overlooked, if it is not eclipsed altogether: namely, the geographically-bounded space of the media event. This article examines the centrality of the physical space of the media event in controlling the wider performance of the mediated narrative, using as a case study the Sochi 2014 Winter Olympic Games. For the event organizers, the physical space is of increasing importance, as control and surveillance of the space provides an extended and militarized media infrastructure for constructing and protecting the global narrative extending beyond the event and the success of the event itself.