Devop(Tion)S for Enterprises” White Paper By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Magic Quadrant for Application Release Automation
Magic Quadrant for Application Release Automation Published: 27 September 2017 ID: G00315074 Analyst(s): Colin Fletcher, Laurie F. Wurster The ARA market is rapidly evolving in response to growing enterprise requirements to both scale DevOps initiatives and improve release management agility across multiple cultures, processes and generations of technology. This research helps I&O leaders make better-informed decisions. Strategic Planning Assumption By 2020, 50% of global enterprises will have implemented at least one application release automation solution, up from less than 15% today. Market Definition/Description Application release automation (ARA) tools provide a combination of automation, environment modeling and release coordination capabilities to simultaneously improve the quality and the velocity of application releases. ARA tools enable best practices in moving application-related artifacts, applications, configurations and even data together across the application life cycle process. These tools are a key part of enabling the DevOps goal of achieving continuous delivery with large numbers of rapid, small releases. Approximately seven years old, the ARA solution market reached an estimated $228.2 million in 2016, up 31.4% from $173.6 million in 2015. The market is continues to be expected to grow at an estimated 20% compound annual growth rate (CAGR) through 2020. Magic Quadrant Figure 1. Magic Quadrant for Application Release Automation Source: Gartner (September 2017) Vendor Strengths and Cautions Arcad Software Founded in 1992, Arcad Software is a privately held company headquartered in Chavanod, France. The company was started by its founder to deliver automation-oriented solutions supporting the Page 2 of 28 Gartner, Inc. | G00315074 IBM i (introduced as AS/400, then later renamed eServer iSeries) platform. -

Ebook Devops Toolchain.Pdf
DevOps Toolchain 1 Introduction accordingly based on the problem at hand. DevOps may need little introduction these days, Similarly, most systems administrators possess but many are still at a loss to explain precisely competent programming abilities for traversing what the movement entails. Some emphasize the the stack—on top of the requisite skills for portmanteau of the two terms, stating that the managing IT operations. The industry has heart of DevOps is the collaboration between been quick in attaching new labels to these developers and operations staff. Others choose emerging hybrid roles: DevOps Engineer and to focus on the tools and the problems they solve, DevOps Specialist being the most common. singing the praises of DevOps for fixing their Notwithstanding, the key takeaway is that no respective infrastructure woes. Tools—though single IT skill is more important or valuable than crucial enablers of the movement—only form part another; subsequently, many different tools are of the equation. DevOps encompasses cultural required to do the job effectively. So as DevOps innovation, a breaking down of walls and silos is comprised of a group of concepts clustered between software development, operations, around the premise of continuous software and QA/ testing—in addition to the tools and delivery, these concepts in turn encompass a methodologies enabling this transformation. range of associated tools for fulfilling particular Ultimately, the definition of DevOps varies per functions. organization. Since its meaning depends heavily on the audience and context in question, general All in all, these complementary tools fill out the discussions around the true definition of DevOps DevOps toolchain, unifying the best elements are for the most part inconsequential. -

Continuous Delivery for Every Team
Continuous Delivery for Every Team Six ways CA Continuous Delivery Director can help you become a modern software factory Keeping up with customer demand—and getting ahead of the competition—means you must continuously deliver high-quality apps and experiences. In the modern software factory, you’ll find: Application releases are occurring at increased volumes, with greater frequency and speed.1 33% Release daily or “Cloud First” is Microservice more frequently 66% becoming a global architectures and 33% priority. container-based apps In 15 months, 80 percent are the new norm. Release weekly of all IT budgets will be 83 percent of organizations committed to cloud apps are actively using containers 2 and solutions. today.3 1 CA Technologies DevOps Research, prepared by Spiceworks, February 2017 2 Forbes, “2017 State of Cloud Adoption and Security,” April 2017 3 Ibid 02 But how do you become a modern software factory when you’re still facing challenges like: • Manual Processes: Manual, ad hoc release and testing processes do not scale in a multi-app, multi-release pipeline. And increased deployment frequency and speed through automation exacerbate the issue. • Testing Bottlenecks: Testing is critical, but a siloed, time- consuming and manual part of the release cycle. In fact, 66 percent still use Microsoft Excel®, Microsoft Word® and email to track testing.4 • Evolving Tech: DevOps toolchains and technologies are constantly evolving, putting pressure on teams to balance new capabilities with existing investments. • Limited Visibility: The proliferation of moving parts requires that you establish a big picture view of the pipeline to continuously improve the speed and quality of releases. -

Software Engineering Using Devops - a Silver Bullet?
UPTEC IT 19 002 Examensarbete 30 hp Januari 2019 Software Engineering using DevOps - a Silver Bullet? Mikaela Eriksson Institutionen för informationsteknologi Department of Information Technology Abstract Software Engineering using DevOps - a Silver Bullet? Mikaela Eriksson Teknisk- naturvetenskaplig fakultet UTH-enheten Today we have technology that help us scan millions of medical databases in a glimpse of an eye and self-driving cars that are outperforming humans at driving. Besöksadress: Technology is developing so fast that new updates in the technology world are Ångströmlaboratoriet Lägerhyddsvägen 1 commonplace to us and we are more often frustrated in case something is not up Hus 4, Plan 0 to speed. Technology is moving so quickly and in order for humans to keep up with the development needed in the tech business, different methodologies for how to Postadress: optimise the development process have been applied, some that work better than Box 536 751 21 Uppsala others. But just as fast as the technology changes, the methodologies used change with them. Recently a new term has entered the methodologies field. This Telefon: term is said to bring faster deployment, decreased failures and improved the 018 – 471 30 03 loyalties within the teams. The term in question, is called DevOps. Telefax: 018 – 471 30 00 This study is about uncovering the world of DevOps. This thesis is exploring the term in real teams in order to find out whether or not DevOps is the silver bullet it Hemsida: makes out to be. The study is based on ten interviews with people at different http://www.teknat.uu.se/student organisations, using DevOps, and will find out how these interviewees use and feel about DevOps. -

Gartner Magic Quadrant for Enterprise Agile Planning Tools, April 2019
13/09/2019 Gartner Reprint Licensed for Distribution Magic Quadrant for Enterprise Agile Planning Tools Published 18 April 2019 - ID G00361074 - 40 min read By Analysts Keith Mann, Mike West, Thomas Murphy, Nathan Wilson As organizations mature their enterprise-scale agile capabilities, established vendors refine their offerings and new providers emerge. This Magic Quadrant evaluates 17 vendors of enterprise agile planning tools to help you make the right choice for your organization. Market Definition/Description This document was revised on 26 April 2019. The document you are viewing is the corrected version. For more information, see the Corrections (http://www.gartner.com/technology/about/policies/current_corrections.jsp) page on gartner.com. Enterprise agile planning (EAP) tools help organizations make use of agile practices at scale to achieve enterprise-class agile development. This is achieved by supporting practices that are business-outcome-driven, customer-centric, collaborative and cooperative, in conjunction with continual stakeholder feedback. These tools represent an evolution from project-centric agile tools and traditional application development life cycle management (ADLM) tools. The majority of products in the EAP tool market play into the overall ADLM product set, acting as hubs for the definition and management of work item tracking. There is a relationship between EAP tools, project portfolio management (PPM) tools and product roadmapping tools. Traditional PPM tools provide the high-level planning and resource management enterprises demand, but may lack enterprise-class agile development support. EAP tools, for their part, may not support project management outside agile frameworks. (Gartner has a separate Magic Quadrant for PPM, the latest being “Magic Quadrant for Project Portfolio Management, Worldwide”). -

The Practical Blueprint to Continuous Delivery Executive Summary
The Practical Blueprint to Continuous Delivery Executive Summary CA Technologies, A Broadcom Company, proposes a four-stage blueprint to continuous delivery to assist enterprises at any stage of their DevOps journey. This plan can take a company of any maturity level all the way up to enterprise-scale continuous delivery using a combination of Automic® Continuous Delivery Automation, 40-plus years of business automation experience, and the proven tools and practices the company is already leveraging. As the only vendor that automates within the toolchain (steps one and two) and across the toolchain (steps three and four), CA Technologies is in a unique position to help enterprises at every stage of their progression. Our tool-agnostic, cross-platform and multi- stack technology means developers can continue using the tools they are most comfortable with, while DevOps teams can collaboratively build automated, production-ready deployment processes that make operations comfortable. CA Technologies offers a DevOps Maturity Assessment that shows on which of the four steps an organization sits, and compares its current state with that of its competitors, its industry and its competition globally. Using the assessment findings will give companies a blueprint to guide them up to the next level on the road to enterprise agility as quickly and safely as possible. 2 Step 1: Manual and Scripting Participation in our DevOps Maturity Assessment will deliver a continuous delivery roadmap that contains a blueprint for DevOps throughout the enterprise. Customers will be able to compare their current state with their competitors, their industry and globally. Manual steps will be identified and documented, then replaced with automated tasks and workflows. -
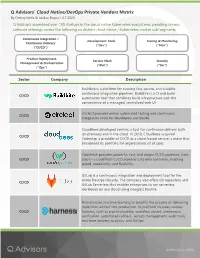
Q Advisors' Cloud Native/Devops Private Vendors Matrix
Q Advisors' Cloud Native/DevOps Private Vendors Matrix By Dmitry Netis & Jordan Rupar / 4.7.2020 Q Advisors assembled over 100 startups in the cloud native Kubernetes ecosystems, peddling various software offerings across the following six distinct cloud native / Kubernetes market sub-segments: Continuous Integration / Development Tools Testing & Monitoring Continuous Delivery (“Dev”) (“Mon”) (“CI/CD”) Product Deployment, Service Mesh Security Management & Orchestration (“Run”) (“Sec”) (“Ops”) Sector Company Description Buildkite is a platform for running fast, secure, and scalable continuous integration pipelines. Buildkite is a CI and build CI/CD automation tool that combines build infrastructure with the convenience of a managed, centralized web UI. CircleCI provides online automated testing and continuous CI/CD integration tools for developers worldwide. CloudBees developed Jenkins, a tool for continuous delivery both on-premises and in the cloud. In 2018, CloudBees acquired CI/CD Codeship, a provider of CI/CD as a cloud-based service, a move that broadened its portfolio for organizations of all sizes. Codefresh provides powerful, fast, and simple CI/CD pipelines. Each CI/CD step in a Codefresh CI/CD pipeline is its own container, enabling speed, modularity, and flexibility. GitLab is a continuous integration and deployment tool for the entire DevOps lifecycle. The company also offers Git repository and CI/CD GitLab Serverless that enables enterprises to run serverless workloads on any cloud using Google’s Knative. Harness uses machine learning to simplify the process of delivering code from artifact into production. Its platform includes various CI/CD features, such as pipeline builder, workflow wizard, continuous verification, automated rollback, secrets management, audit trails, real-time delivery analytics, and GitOps. -

Devops for Salesforce: Choosing Between a Build and Buy Approach
® White Paper DevOps for Salesforce: Choosing Between a Build and Buy Approach Even in the ecosystem surrounding Salesforce (which was We are living in the not a focus of DevOps activity early on), organizations Age of DevOps. are now looking for ways to leverage DevOps and CI/CD. This can be challenging, because a CI/CD solution for Salesforce needs to address unique challenges that do not exist in the context of generic DevOps. Those challenges include issues such as how to integrate Salesforce (a decades-old platform that was first released well before anyone was talking about DevOps) into a CI/CD pipeline from a technical perspective. They also include questions related to managing Salesforce metadata, parent-child relationships, and auditing, which standard DevOps tools are not typically able to address. With these challenges in mind, this white paper walks through best practices for implementing a Salesforce- friendly DevOps solution. In particular, it focuses on how to make the right decision regarding whether to build a CI/CD pipeline for Salesforce by implementing your own toolchain or adopting a ready-made solution. In other words, we address the build-vs.-buy question of Salesforce DevOps. To learn more about AutoRABIT and find out how you can set up an AutoRABIT Playground to test the product for free, visit autorabit.com. Build vs. Buy Considerations Resources • Do you have the headcount to create what you need? • Can you outsource if necessary? • Maintenance? Timeline • How soon do you want/need functionality? • Can you afford to wait? Uniqueness • How “out-of-the-box” are your needs? • Do your research Competition • Consider the business landscape your company operates in • The prize is smaller for second & third place 2 ©2019 AutoRABIT Inc. -

From Devops to Devdataops: Data Management in Devops Processes
From DevOps to DevDataOps: Data Management in DevOps processes Antonio Capizzi1, Salvatore Distefano1,Manuel Mazzara2 1 University of Messina, Italy 2 Innopolis University, Innopolis, Respublika Tatarstan, Russian Federation. Abstract. DevOps is a quite effective approach for managing software development and operation, as confirmed by plenty of success stories in real applications and case studies. DevOps is now becoming the main- stream solution adopted by the software industry in development, able to reduce the time to market and costs while improving quality and ensuring evolvability and adaptability of the resulting software archi- tecture. Among the aspects to take into account in a DevOps process, data is assuming strategic importance, since it allows to gain insights from the operation directly into the development, the main objective of a DevOps approach. Data can be therefore considered as the fuel of the DevOps process, requiring proper solutions for its management. Based on the amount of data generated, its variety, velocity, variability, value and other relevant features, DevOps data management can be mainly framed into the BigData category. This allows exploiting BigData so- lutions for the management of DevOps data generated throughout the process, including artefacts, code, documentation, logs and so on. This paper aims at investigating data management in DevOps processes, iden- tifying related issues, challenges and potential solutions taken from the BigData world as well as from new trends adopting and adapting DevOps approaches in data management, i.e. DataOps. 1 Introduction DevOps [1, 2] is an approach for software development and (IT) sys- tem operation combining best practices from both such domains to im- prove the overall quality of the software-system while reducing costs and shortening time-to-market. -

Vendor Selection Matrix™ Application Release Orchestration (Aro) Saas and Software
VENDOR SELECTION MATRIX™ APPLICATION RELEASE ORCHESTRATION (ARO) SAAS AND SOFTWARE THE TOP GLOBAL VENDORS 2020 Research In Action February 2020 © 2020, Research In Action GmbH Reproduction Prohibited 1 FOREWORD The Vendor Selection Matrix™ is a primarily survey-based methodology for comparative vendor evaluation where 60% of the evaluation is based on a survey of enterprise IT or business decision makers. This is balanced by analyst subject matter expert input fed by a combination of intensive interviews with software or Research In Action GmbH services vendors and their clients, plus the informed, independent points-of-view - all of which combine to Alte Schule make Research in Action Vendor Selection Matrix™ reports so unique. For this report, we interviewed 1,500 56244 Hartenfels IT mangers with budget responsibility in enterprises globally. We selected those vendors which achieved the Germany best evaluation scores from the buyers, having disregarded those with too few evaluations. Eveline Oehrlich Enterprises of all types are demanding quality software delivery into production. This capability is critical for Research Director a successful digital business. However, as the development team proceeds with agile software delivery, the +49 151 40158054 challenge is that some IT operations teams are unable to cope with this speed. The adoption of Application [email protected] Release Orchestration can automate and improve the release cadence, improve quality and efficiency to accelerate innovation, support transformations and allow for efficient work between the responsible teams. IT enterprise teams today are either starting to adopt these automation tools or are looking to replace their existing tools. Key investment trends such as integration with testing tools, migration to SaaS platforms and the support of compliance regulations are driving the offerings of the existing vendors. -

Devops Requires “Continuous Quality” Is Published by Parasoft
1 Issue 1 1 Why Agile Development Teams Must Reinvent the DevOps Requires Software Testing Process 3 What’s Needed for “Continuous Quality” Continuous Testing? 10 Research from Gartner: Market Trends: DevOps — Not a Market, but a Tool-Centric Philosophy That Supports a Continuous Delivery Value Chain Why Agile Development Teams Must Reinvent the 19 About Parasoft Software Testing Process In today’s economy, businesses create a competitive edge through software and every company is essentially a software company. Now that rapid delivery of differentiable software has become a business imperative, software development teams are scrambling to keep up. In response to increased demand, they are seeking new ways to accelerate their release cycles—driving the adoption of agile or lean development practices such as DevOps. Yet, based on the number of software failures now making headlines on a daily basis, it’s evident that speeding up the SDLC opens the door to severe repercussions. Organizations are remiss to assume that yesterday’s practices can meet today’s process In order for more advanced automation to occur, we demands. There needs to be a cultural shift from need to move beyond the test pass/fail percentage testing an application to understanding the risks into a much more granular understanding of the associated with a release candidate. Such a shift impact of failure: a nuance that gets lost in the requires moving beyond the traditional “bottom- traditional regression test suite. Continuous up” approach to testing, which focuses on Testing is key for bridging this gap. Continuous adding incremental tests for new functionality. -
Automated Testing and the Devops Pipeline
Automation Testing and the DevOps Pipeline presented by Randy Spiess (Jan ‘18) Learning Objectives What is a DevOps Pipeline DevOps Foundational Elements Tools Used in the DevOps Pipeline About Randy DevOps Instructor Agile Coach Process & Quality Manager Manager of Software Development Manager of SCM and Test What is DevOps What Does DevOps Achieve Highest Quality Shortest Lead Time Lowest Cost Sustainability State of DevOps 2017 High-performing organizations decisively outperform their lower-performing peers. ◦ They deploy 46 times more frequently. ◦ 440 times faster lead times ◦ recover 96 times faster ◦ have 5 times lower change failure rates. High performers have better employee loyalty, as measured by employee Net Promoter Score (eNPS). High-performing organizations ◦ spend 22 percent less time on unplanned work. ◦ are able to spend 29 percent more time on new work, such as new features or code. DevOps is not... A certification A role A set of tools A prescriptive process ◦ Jez Humble What is DevOps “a cross-disciplinary community of practice dedicated to the study of building, evolving and operating rapidly-changing resilient systems at scale.” - Jez Humble “A set of practices that emphasize the collaboration and communication of both software developers and information technology (IT) professionals while automating the process of software delivery and infrastructure changes. It aims at establishing a culture and environment where building, testing, and releasing software can happen rapidly, frequently, and more reliably.” - Wikipedia DevOps wants to achieve Operations and development are skills, not roles. Delivery teams are composed of people with all the necessary skills. Delivery teams run software products - not projects - that run from inception to retirement How did DevOps get here 1948-75 Toyota Production System 1984 The Goal published 2001 Agile Manifesto 2007 Continuous Integration 2010 Continuous Delivery.