Formal Languages and Grammars
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Theory of Computer Science
Theory of Computer Science MODULE-1 Alphabet A finite set of symbols is denoted by ∑. Language A language is defined as a set of strings of symbols over an alphabet. Language of a Machine Set of all accepted strings of a machine is called language of a machine. Grammar Grammar is the set of rules that generates language. CHOMSKY HIERARCHY OF LANGUAGES Type 0-Language:-Unrestricted Language, Accepter:-Turing Machine, Generetor:-Unrestricted Grammar Type 1- Language:-Context Sensitive Language, Accepter:- Linear Bounded Automata, Generetor:-Context Sensitive Grammar Type 2- Language:-Context Free Language, Accepter:-Push Down Automata, Generetor:- Context Free Grammar Type 3- Language:-Regular Language, Accepter:- Finite Automata, Generetor:-Regular Grammar Finite Automata Finite Automata is generally of two types :(i)Deterministic Finite Automata (DFA)(ii)Non Deterministic Finite Automata(NFA) DFA DFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. Σ is a finite set of symbols, called the alphabet of the automaton. δ is the transition function, that is, δ: Q × Σ → Q. q0 is the start state, that is, the state of the automaton before any input has been processed, where q0 Q. F is a set of states of Q (i.e. F Q) called accept states or Final States 1. Construct a DFA that accepts set of all strings over ∑={0,1}, ending with 00 ? 1 0 A B S State/Input 0 1 1 A B A 0 B C A 1 * C C A C 0 2. Construct a DFA that accepts set of all strings over ∑={0,1}, not containing 101 as a substring ? 0 1 1 A B State/Input 0 1 S *A A B 0 *B C B 0 0,1 *C A R C R R R R 1 NFA NFA is represented formally by a 5-tuple (Q,Σ,δ,q0,F), where: Q is a finite set of states. -

Cs 61A/Cs 98-52
CS 61A/CS 98-52 Mehrdad Niknami University of California, Berkeley Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 1 / 23 Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 What if you were looking for a pattern? Like an email address? Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ j] is_match= False break if is_match: return i Mehrdad Niknami (UC Berkeley) CS 61A/CS 98-52 2 / 23 Motivation How would you find a substring inside a string? Something like this? (Is this good?) def find(string, pattern): n= len(string) m= len(pattern) for i in range(n-m+ 1): is_match= True for j in range(m): if pattern[j] != string[i+ -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Regular Languages and Finite Automata for Part IA of the Computer Science Tripos
N Lecture Notes on Regular Languages and Finite Automata for Part IA of the Computer Science Tripos Prof. Andrew M. Pitts Cambridge University Computer Laboratory c 2012 A. M. Pitts Contents Learning Guide ii 1 Regular Expressions 1 1.1 Alphabets,strings,andlanguages . .......... 1 1.2 Patternmatching................................. .... 4 1.3 Somequestionsaboutlanguages . ....... 6 1.4 Exercises....................................... .. 8 2 Finite State Machines 11 2.1 Finiteautomata .................................. ... 11 2.2 Determinism, non-determinism, and ε-transitions. .. .. .. .. .. .. .. .. .. 14 2.3 Asubsetconstruction . .. .. .. .. .. .. .. .. .. .. .. .. .. .. ..... 17 2.4 Summary ........................................ 20 2.5 Exercises....................................... .. 20 3 Regular Languages, I 23 3.1 Finiteautomatafromregularexpressions . ............ 23 3.2 Decidabilityofmatching . ...... 28 3.3 Exercises....................................... .. 30 4 Regular Languages, II 31 4.1 Regularexpressionsfromfiniteautomata . ........... 31 4.2 Anexample ....................................... 32 4.3 Complementand intersectionof regularlanguages . .............. 34 4.4 Exercises....................................... .. 36 5 The Pumping Lemma 39 5.1 ProvingthePumpingLemma . .... 40 5.2 UsingthePumpingLemma . ... 41 5.3 Decidabilityoflanguageequivalence . ........... 44 5.4 Exercises....................................... .. 45 6 Grammars 47 6.1 Context-freegrammars . ..... 47 6.2 Backus-NaurForm ................................ -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
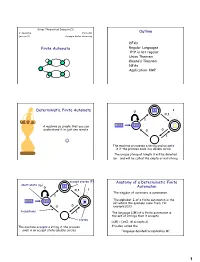
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Ambiguity Detection Methods for Context-Free Grammars
Ambiguity Detection Methods for Context-Free Grammars H.J.S. Basten Master’s thesis August 17, 2007 One Year Master Software Engineering Universiteit van Amsterdam Thesis and Internship Supervisor: Prof. Dr. P. Klint Institute: Centrum voor Wiskunde en Informatica Availability: public domain Contents Abstract 5 Preface 7 1 Introduction 9 1.1 Motivation . 9 1.2 Scope . 10 1.3 Criteria for practical usability . 11 1.4 Existing ambiguity detection methods . 12 1.5 Research questions . 13 1.6 Thesis overview . 14 2 Background and context 15 2.1 Grammars and languages . 15 2.2 Ambiguity in context-free grammars . 16 2.3 Ambiguity detection for context-free grammars . 18 3 Current ambiguity detection methods 19 3.1 Gorn . 19 3.2 Cheung and Uzgalis . 20 3.3 AMBER . 20 3.4 Jampana . 21 3.5 LR(k)test...................................... 22 3.6 Brabrand, Giegerich and Møller . 23 3.7 Schmitz . 24 3.8 Summary . 26 4 Research method 29 4.1 Measurements . 29 4.1.1 Accuracy . 29 4.1.2 Performance . 31 4.1.3 Termination . 31 4.1.4 Usefulness of the output . 31 4.2 Analysis . 33 4.2.1 Scalability . 33 4.2.2 Practical usability . 33 4.3 Investigated ADM implementations . 34 5 Analysis of AMBER 35 5.1 Accuracy . 35 5.2 Performance . 36 3 5.3 Termination . 37 5.4 Usefulness of the output . 38 5.5 Analysis . 38 6 Analysis of MSTA 41 6.1 Accuracy . 41 6.2 Performance . 41 6.3 Termination . 42 6.4 Usefulness of the output . 42 6.5 Analysis . -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language. -

Neural Edit Operations for Biological Sequences
Neural Edit Operations for Biological Sequences Satoshi Koide Keisuke Kawano Toyota Central R&D Labs. Toyota Central R&D Labs. [email protected] [email protected] Takuro Kutsuna Toyota Central R&D Labs. [email protected] Abstract The evolution of biological sequences, such as proteins or DNAs, is driven by the three basic edit operations: substitution, insertion, and deletion. Motivated by the recent progress of neural network models for biological tasks, we implement two neural network architectures that can treat such edit operations. The first proposal is the edit invariant neural networks, based on differentiable Needleman-Wunsch algorithms. The second is the use of deep CNNs with concatenations. Our analysis shows that CNNs can recognize regular expressions without Kleene star, and that deeper CNNs can recognize more complex regular expressions including the insertion/deletion of characters. The experimental results for the protein secondary structure prediction task suggest the importance of insertion/deletion. The test accuracy on the widely-used CB513 dataset is 71.5%, which is 1.2-points better than the current best result on non-ensemble models. 1 Introduction Neural networks are now used in many applications, not limited to classical fields such as image processing, speech recognition, and natural language processing. Bioinformatics is becoming an important application field of neural networks. These biological applications are often implemented as a supervised learning model that takes a biological string (such as DNA or protein) as an input, and outputs the corresponding label(s), such as a protein secondary structure [13, 14, 15, 18, 19, 23, 24, 26], protein contact maps [4, 8], and genome accessibility [12]. -

Context-Free Grammars
Chapter 3 Context-Free Grammars By Dr Zalmiyah Zakaria •Context-Free Grammars and Languages •Regular Grammars Formal Definition of Context-Free Grammars (CFG) A CFG can be formally defined by a quadruple of (V, , P, S) where: – V is a finite set of variables (non-terminal) – (the alphabet) is a finite set of terminal symbols , where V = – P is a finite set of rules (production rules) written as: A for A V, (v )*. – S is the start symbol, S V 2 Formal Definition of CFG • We can give a formal description to a particular CFG by specifying each of its four components, for example, G = ({S, A}, {0, 1}, P, S) where P consists of three rules: S → 0S1 S → A A → Sept2011 Theory of Computer Science 3 Context-Free Grammars • Terminal symbols – elements of the alphabet • Variables or non-terminals – additional symbols used in production rules • Variable S (start symbol) initiates the process of generating acceptable strings. 4 Terminal or Variable ? • S → (S) | S + S | S × S | A • A → 1 | 2 | 3 • The terminal symbols are { (, ), +, ×, 1, 2, 3} • The variable symbols are S and A Sept2011 Theory of Computer Science 5 Context-Free Grammars • A rule is an element of the set V (V )*. • An A rule: [A, w] or A w • A null rule or lambda rule: A 6 Context-Free Grammars • Grammars are used to generate strings of a language. • An A rule can be applied to the variable A whenever and wherever it occurs. • No limitation on applicability of a rule – it is context free 8 Context-Free Grammars • CFG have no restrictions on the right-hand side of production rules. -

Theory of Computation
Theory of Computation Alexandre Duret-Lutz [email protected] September 10, 2010 ADL Theory of Computation 1 / 121 References Introduction to the Theory of Computation (Michael Sipser, 2005). Lecture notes from Pierre Wolper's course at http://www.montefiore.ulg.ac.be/~pw/cours/calc.html (The page is in French, but the lecture notes labelled chapitre 1 to chapitre 8 are in English). Elements of Automata Theory (Jacques Sakarovitch, 2009). Compilers: Principles, Techniques, and Tools (A. Aho, R. Sethi, J. Ullman, 2006). ADL Theory of Computation 2 / 121 Introduction What would be your reaction if someone came at you to explain he has invented a perpetual motion machine (i.e. a device that can sustain continuous motion without losing energy or matter)? You would probably laugh. Without looking at the machine, you know outright that such the device cannot sustain perpetual motion. Indeed the laws of thermodynamics demonstrate that perpetual motion devices cannot be created. We know beforehand, from scientic knowledge, that building such a machine is impossible. The ultimate goal of this course is to develop similar knowledge for computer programs. ADL Theory of Computation 3 / 121 Theory of Computation Theory of computation studies whether and how eciently problems can be solved using a program on a model of computation (abstractions of a computer). Computability theory deals with the whether, i.e., is a problem solvable for a given model. For instance a strong result we will learn is that the halting problem is not solvable by a Turing machine. Complexity theory deals with the how eciently. -

(A) for Any Regular Expression R, the Set L(R) of Strings
Kleene’s Theorem Definition. Alanguageisregular iff it is equal to L(M), the set of strings accepted by some deterministic finite automaton M. Theorem. (a) For any regular expression r,thesetL(r) of strings matching r is a regular language. (b) Conversely, every regular language is the form L(r) for some regular expression r. L6 79 Example of a regular language Recall the example DFA we used earlier: b a a a a M ! q0 q1 q2 q3 b b b In this case it’s not hard to see that L(M)=L(r) for r =(a|b)∗ aaa(a|b)∗ L6 80 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ L6 81 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ since baabaa ∈ L(M) WRONG! but baabaa ̸∈ L(a∗|a∗b(ab)∗ aaa∗ ) We need an algorithm for constructing a suitable r for each M (plus a proof that it is correct). L6 81 Lemma. Given an NFA M =(Q, Σ, δ, s, F),foreach subset S ⊆ Q and each pair of states q, q′ ∈ Q,thereisa S regular expression rq,q′ satisfying S Σ∗ u ∗ ′ L(rq,q′ )={u ∈ | q −→ q in M with all inter- mediate states of the sequence of transitions in S}. Hence if the subset F of accepting states has k distinct elements, q1,...,qk say, then L(M)=L(r) with r ! r1|···|rk where Q ri = rs,qi (i = 1, .