Some Elementary Formulas in 'Matrix Calculus' and Their Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mathematics for Dynamicists - Lecture Notes Thomas Michelitsch
Mathematics for Dynamicists - Lecture Notes Thomas Michelitsch To cite this version: Thomas Michelitsch. Mathematics for Dynamicists - Lecture Notes. Doctoral. Mathematics for Dynamicists, France. 2006. cel-01128826 HAL Id: cel-01128826 https://hal.archives-ouvertes.fr/cel-01128826 Submitted on 10 Mar 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Mathematics for Dynamicists Lecture Notes c 2004-2006 Thomas Michael Michelitsch1 Department of Civil and Structural Engineering The University of Sheffield Sheffield, UK 1Present address : http://www.dalembert.upmc.fr/home/michelitsch/ . Dedicated to the memory of my parents Michael and Hildegard Michelitsch Handout Manuscript with Fractal Cover Picture by Michael Michelitsch https://www.flickr.com/photos/michelitsch/sets/72157601230117490 1 Contents Preface 1 Part I 1.1 Binomial Theorem 1.2 Derivatives, Integrals and Taylor Series 1.3 Elementary Functions 1.4 Complex Numbers: Cartesian and Polar Representation 1.5 Sequences, Series, Integrals and Power-Series 1.6 Polynomials and Partial Fractions -

A Brief but Important Note on the Product Rule
A brief but important note on the product rule Peter Merrotsy The University of Western Australia [email protected] The product rule in the Australian Curriculum he product rule refers to the derivative of the product of two functions Texpressed in terms of the functions and their derivatives. This result first naturally appears in the subject Mathematical Methods in the senior secondary Australian Curriculum (Australian Curriculum, Assessment and Reporting Authority [ACARA], n.d.b). In the curriculum content, it is mentioned by name only (Unit 3, Topic 1, ACMMM104). Elsewhere (Glossary, p. 6), detail is given in the form: If h(x) = f(x) g(x), then h'(x) = f(x) g'(x) + f '(x) g(x) (1) or, in Leibniz notation, d dv du ()u v = u + v (2) dx dx dx presupposing, of course, that both u and v are functions of x. In the Australian Capital Territory (ACT Board of Senior Secondary Studies, 2014, pp. 28, 43), Tasmania (Tasmanian Qualifications Authority, 2014, p. 21) and Western Australia (School Curriculum and Standards Authority, 2014, WACE, Mathematical Methods Year 12, pp. 9, 22), these statements of the Australian Senior Mathematics Journal vol. 30 no. 2 product rule have been adopted without further commentary. Elsewhere, there are varying attempts at elaboration. The SACE Board of South Australia (2015, p. 29) refers simply to “differentiating functions of the form , using the product rule.” In Queensland (Queensland Studies Authority, 2008, p. 14), a slight shift in notation is suggested by referring to rules for differentiation, including: d []f (t)g(t) (product rule) (3) dt At first, the Victorian Curriculum and Assessment Authority (2015, p. -

A Quotient Rule Integration by Parts Formula Jennifer Switkes ([email protected]), California State Polytechnic Univer- Sity, Pomona, CA 91768
A Quotient Rule Integration by Parts Formula Jennifer Switkes ([email protected]), California State Polytechnic Univer- sity, Pomona, CA 91768 In a recent calculus course, I introduced the technique of Integration by Parts as an integration rule corresponding to the Product Rule for differentiation. I showed my students the standard derivation of the Integration by Parts formula as presented in [1]: By the Product Rule, if f (x) and g(x) are differentiable functions, then d f (x)g(x) = f (x)g(x) + g(x) f (x). dx Integrating on both sides of this equation, f (x)g(x) + g(x) f (x) dx = f (x)g(x), which may be rearranged to obtain f (x)g(x) dx = f (x)g(x) − g(x) f (x) dx. Letting U = f (x) and V = g(x) and observing that dU = f (x) dx and dV = g(x) dx, we obtain the familiar Integration by Parts formula UdV= UV − VdU. (1) My student Victor asked if we could do a similar thing with the Quotient Rule. While the other students thought this was a crazy idea, I was intrigued. Below, I derive a Quotient Rule Integration by Parts formula, apply the resulting integration formula to an example, and discuss reasons why this formula does not appear in calculus texts. By the Quotient Rule, if f (x) and g(x) are differentiable functions, then ( ) ( ) ( ) − ( ) ( ) d f x = g x f x f x g x . dx g(x) [g(x)]2 Integrating both sides of this equation, we get f (x) g(x) f (x) − f (x)g(x) = dx. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

Matrix Calculus
Appendix D Matrix Calculus From too much study, and from extreme passion, cometh madnesse. Isaac Newton [205, §5] − D.1 Gradient, Directional derivative, Taylor series D.1.1 Gradients Gradient of a differentiable real function f(x) : RK R with respect to its vector argument is defined uniquely in terms of partial derivatives→ ∂f(x) ∂x1 ∂f(x) , ∂x2 RK f(x) . (2053) ∇ . ∈ . ∂f(x) ∂xK while the second-order gradient of the twice differentiable real function with respect to its vector argument is traditionally called the Hessian; 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂x1 ∂x1∂x2 ··· ∂x1∂xK 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 2 K f(x) , ∂x2∂x1 ∂x2 ··· ∂x2∂xK S (2054) ∇ . ∈ . .. 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂xK ∂x1 ∂xK ∂x2 ∂x ··· K interpreted ∂f(x) ∂f(x) 2 ∂ ∂ 2 ∂ f(x) ∂x1 ∂x2 ∂ f(x) = = = (2055) ∂x1∂x2 ³∂x2 ´ ³∂x1 ´ ∂x2∂x1 Dattorro, Convex Optimization Euclidean Distance Geometry, Mεβoo, 2005, v2020.02.29. 599 600 APPENDIX D. MATRIX CALCULUS The gradient of vector-valued function v(x) : R RN on real domain is a row vector → v(x) , ∂v1(x) ∂v2(x) ∂vN (x) RN (2056) ∇ ∂x ∂x ··· ∂x ∈ h i while the second-order gradient is 2 2 2 2 , ∂ v1(x) ∂ v2(x) ∂ vN (x) RN v(x) 2 2 2 (2057) ∇ ∂x ∂x ··· ∂x ∈ h i Gradient of vector-valued function h(x) : RK RN on vector domain is → ∂h1(x) ∂h2(x) ∂hN (x) ∂x1 ∂x1 ··· ∂x1 ∂h1(x) ∂h2(x) ∂hN (x) h(x) , ∂x2 ∂x2 ··· ∂x2 ∇ . -

Matrix Calculus
D Matrix Calculus D–1 Appendix D: MATRIX CALCULUS D–2 In this Appendix we collect some useful formulas of matrix calculus that often appear in finite element derivations. §D.1 THE DERIVATIVES OF VECTOR FUNCTIONS Let x and y be vectors of orders n and m respectively: x1 y1 x2 y2 x = . , y = . ,(D.1) . xn ym where each component yi may be a function of all the xj , a fact represented by saying that y is a function of x,or y = y(x). (D.2) If n = 1, x reduces to a scalar, which we call x.Ifm = 1, y reduces to a scalar, which we call y. Various applications are studied in the following subsections. §D.1.1 Derivative of Vector with Respect to Vector The derivative of the vector y with respect to vector x is the n × m matrix ∂y1 ∂y2 ∂ym ∂ ∂ ··· ∂ x1 x1 x1 ∂ ∂ ∂ ∂ y1 y2 ··· ym y def ∂x ∂x ∂x = 2 2 2 (D.3) ∂x . . .. ∂ ∂ ∂ y1 y2 ··· ym ∂xn ∂xn ∂xn §D.1.2 Derivative of a Scalar with Respect to Vector If y is a scalar, ∂y ∂x1 ∂ ∂ y y def ∂ = x2 .(D.4) ∂x . . ∂y ∂xn §D.1.3 Derivative of Vector with Respect to Scalar If x is a scalar, ∂y def ∂ ∂ ∂ = y1 y2 ... ym (D.5) ∂x ∂x ∂x ∂x D–2 D–3 §D.1 THE DERIVATIVES OF VECTOR FUNCTIONS REMARK D.1 Many authors, notably in statistics and economics, define the derivatives as the transposes of those given above.1 This has the advantage of better agreement of matrix products with composition schemes such as the chain rule. -

CHAPTER 1 VECTOR ANALYSIS ̂ ̂ Distribution Rule Vector Components
8/29/2016 CHAPTER 1 1. VECTOR ALGEBRA VECTOR ANALYSIS Addition of two vectors 8/24/16 Communicative Chap. 1 Vector Analysis 1 Vector Chap. Associative Definition Multiplication by a scalar Distribution Dot product of two vectors Lee Chow · , & Department of Physics · ·· University of Central Florida ·· 2 Orlando, FL 32816 • Cross-product of two vectors Cross-product follows distributive rule but not the commutative rule. 8/24/16 8/24/16 where , Chap. 1 Vector Analysis 1 Vector Chap. Analysis 1 Vector Chap. In a strict sense, if and are vectors, the cross product of two vectors is a pseudo-vector. Distribution rule A vector is defined as a mathematical quantity But which transform like a position vector: so ̂ ̂ 3 4 Vector components Even though vector operations is independent of the choice of coordinate system, it is often easier 8/24/16 8/24/16 · to set up Cartesian coordinates and work with Analysis 1 Vector Chap. Analysis 1 Vector Chap. the components of a vector. where , , and are unit vectors which are perpendicular to each other. , , and are components of in the x-, y- and z- direction. 5 6 1 8/29/2016 Vector triple products · · · · · 8/24/16 8/24/16 · ( · Chap. 1 Vector Analysis 1 Vector Chap. Analysis 1 Vector Chap. · · · All these vector products can be verified using the vector component method. It is usually a tedious process, but not a difficult process. = - 7 8 Position, displacement, and separation vectors Infinitesimal displacement vector is given by The location of a point (x, y, z) in Cartesian coordinate ℓ as shown below can be defined as a vector from (0,0,0) 8/24/16 In general, when a charge is not at the origin, say at 8/24/16 to (x, y, z) is given by (x’, y’, z’), to find the field produced by this Chap. -
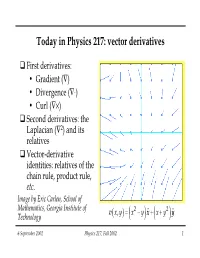
Today in Physics 217: Vector Derivatives
Today in Physics 217: vector derivatives First derivatives: • Gradient (—) • Divergence (—◊) •Curl (—¥) Second derivatives: the Laplacian (—2) and its relatives Vector-derivative identities: relatives of the chain rule, product rule, etc. Image by Eric Carlen, School of Mathematics, Georgia Institute of 22 vxyxy, =−++ x yˆˆ x y Technology ()()() 6 September 2002 Physics 217, Fall 2002 1 Differential vector calculus df/dx provides us with information on how quickly a function of one variable, f(x), changes. For instance, when the argument changes by an infinitesimal amount, from x to x+dx, f changes by df, given by df df= dx dx In three dimensions, the function f will in general be a function of x, y, and z: f(x, y, z). The change in f is equal to ∂∂∂fff df=++ dx dy dz ∂∂∂xyz ∂∂∂fff =++⋅++ˆˆˆˆˆˆ xyzxyz ()()dx() dy() dz ∂∂∂xyz ≡⋅∇fdl 6 September 2002 Physics 217, Fall 2002 2 Differential vector calculus (continued) The vector derivative operator — (“del”) ∂∂∂ ∇ =++xyzˆˆˆ ∂∂∂xyz produces a vector when it operates on scalar function f(x,y,z). — is a vector, as we can see from its behavior under coordinate rotations: I ′ ()∇∇ff=⋅R but its magnitude is not a number: it is an operator. 6 September 2002 Physics 217, Fall 2002 3 Differential vector calculus (continued) There are three kinds of vector derivatives, corresponding to the three kinds of multiplication possible with vectors: Gradient, the analogue of multiplication by a scalar. ∇f Divergence, like the scalar (dot) product. ∇⋅v Curl, which corresponds to the vector (cross) product. ∇×v 6 September 2002 Physics 217, Fall 2002 4 Gradient The result of applying the vector derivative operator on a scalar function f is called the gradient of f: ∂∂∂fff ∇f =++xyzˆˆˆ ∂∂∂xyz The direction of the gradient points in the direction of maximum increase of f (i.e. -

The Calculus of Newton and Leibniz CURRENT READING: Katz §16 (Pp
Worksheet 13 TITLE The Calculus of Newton and Leibniz CURRENT READING: Katz §16 (pp. 543-575) Boyer & Merzbach (pp 358-372, 382-389) SUMMARY We will consider the life and work of the co-inventors of the Calculus: Isaac Newton and Gottfried Leibniz. NEXT: Who Invented Calculus? Newton v. Leibniz: Math’s Most Famous Prioritätsstreit Isaac Newton (1642-1727) was born on Christmas Day, 1642 some 100 miles north of London in the town of Woolsthorpe. In 1661 he started to attend Trinity College, Cambridge and assisted Isaac Barrow in the editing of the latter’s Geometrical Lectures. For parts of 1665 and 1666, the college was closed due to The Plague and Newton went home and studied by himself, leading to what some observers have called “the most productive period of mathematical discover ever reported” (Boyer, A History of Mathematics, 430). During this period Newton made four monumental discoveries 1. the binomial theorem 2. the calculus 3. the law of gravitation 4. the nature of colors Newton is widely regarded as the most influential scientist of all-time even ahead of Albert Einstein, who demonstrated the flaws in Newtonian mechanics two centuries later. Newton’s epic work Philosophiæ Naturalis Principia Mathematica (Mathematical Principles of Natural Philosophy) more often known as the Principia was first published in 1687 and revolutionalized science itself. Infinite Series One of the key tools Newton used for many of his mathematical discoveries were power series. He was able to show that he could expand the expression (a bx) n for any n He was able to check his intuition that this result must be true by showing that the power series for (1+x)-1 could be used to compute a power series for log(1+x) which he then used to calculate the logarithms of several numbers close to 1 to over 50 decimal paces. -

1. Antiderivatives for Exponential Functions Recall That for F(X) = Ec⋅X, F ′(X) = C ⋅ Ec⋅X (For Any Constant C)
1. Antiderivatives for exponential functions Recall that for f(x) = ec⋅x, f ′(x) = c ⋅ ec⋅x (for any constant c). That is, ex is its own derivative. So it makes sense that it is its own antiderivative as well! Theorem 1.1 (Antiderivatives of exponential functions). Let f(x) = ec⋅x for some 1 constant c. Then F x ec⋅c D, for any constant D, is an antiderivative of ( ) = c + f(x). 1 c⋅x ′ 1 c⋅x c⋅x Proof. Consider F (x) = c e +D. Then by the chain rule, F (x) = c⋅ c e +0 = e . So F (x) is an antiderivative of f(x). Of course, the theorem does not work for c = 0, but then we would have that f(x) = e0 = 1, which is constant. By the power rule, an antiderivative would be F (x) = x + C for some constant C. 1 2. Antiderivative for f(x) = x We have the power rule for antiderivatives, but it does not work for f(x) = x−1. 1 However, we know that the derivative of ln(x) is x . So it makes sense that the 1 antiderivative of x should be ln(x). Unfortunately, it is not. But it is close. 1 1 Theorem 2.1 (Antiderivative of f(x) = x ). Let f(x) = x . Then the antiderivatives of f(x) are of the form F (x) = ln(SxS) + C. Proof. Notice that ln(x) for x > 0 F (x) = ln(SxS) = . ln(−x) for x < 0 ′ 1 For x > 0, we have [ln(x)] = x . -

9.3 Undoing the Product Rule
< Previous Section Home Next Section > 9.3 Undoing the Product Rule In 9.2, we investigated how to find closed form antiderivatives of functions that fit the pattern of a Chain Rule derivative. In this section we explore a technique for finding antiderivatives based on the Product Rule for finding derivatives. The Importance of Undoing the Chain Rule Before developing this new idea, we should highlight the importance of Undoing the Chain rule from 9.2 because of how commonly it applies. You will likely have need for this technique more than any other in finding closed form antiderivatives. Furthermore, applying Undoing the Chain rule is often necessary in combination with or as part of the other techniques we will develop in this chapter. The bottom line is this: when it comes to antiderivatives, Undoing the Chain rule is everywhere. Whenever posed with finding closed form accumulation functions, you should be continually on the look-out for rate functions that require this technique. When it comes to Undoing the Chain rule being involved with other antiderivative techniques, Undoing the Product Rule is no exception. We’ll see this in the second half of this section. The Idea of Undoing the Product Rule Recall that the Product Rule determines the derivative of a function that is the product of other functions, i.e. a function that can be expressed as f (x)g(x) . The Product Rule can be expressed compactly as: ( f g)′ = f g′ + g f ′ In other words, the derivative of a product of two functions is the first function times the derivative of the second plus the second function times the derivative of the first. -

Higher Order Derivatives 1 Chapter 3 Higher Order Derivatives
Higher order derivatives 1 Chapter 3 Higher order derivatives You certainly realize from single-variable calculus how very important it is to use derivatives of orders greater than one. The same is of course true for multivariable calculus. In particular, we shall de¯nitely want a \second derivative test" for critical points. A. Partial derivatives First we need to clarify just what sort of domains we wish to consider for our functions. So we give a couple of de¯nitions. n DEFINITION. Suppose x0 2 A ½ R . We say that x0 is an interior point of A if there exists r > 0 such that B(x0; r) ½ A. A DEFINITION. A set A ½ Rn is said to be open if every point of A is an interior point of A. EXAMPLE. An open ball is an open set. (So we are fortunate in our terminology!) To see this suppose A = B(x; r). Then if y 2 A, kx ¡ yk < r and we can let ² = r ¡ kx ¡ yk: Then B(y; ²) ½ A. For if z 2 B(y; ²), then the triangle inequality implies kz ¡ xk · kz ¡ yk + ky ¡ xk < ² + ky ¡ xk = r; so that z 2 A. Thus B(y; ²) ½ B(x; r) (cf. Problem 1{34). This proves that y is an interior point of A. As y is an arbitrary point of A, we conclude that A is open. PROBLEM 3{1. Explain why the empty set is an open set and why this is actually a problem about the logic of language rather than a problem about mathematics.