Empirical Comparisons of Various Voting Methods in Bagging
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Critical Strategies Under Approval Voting: Who Gets Ruled in and Ruled Out
Critical Strategies Under Approval Voting: Who Gets Ruled In And Ruled Out Steven J. Brams Department of Politics New York University New York, NY 10003 USA [email protected] M. Remzi Sanver Department of Economics Istanbul Bilgi University 80310, Kustepe, Istanbul TURKEY [email protected] January 2005 2 Abstract We introduce the notion of a “critical strategy profile” under approval voting (AV), which facilitates the identification of all possible outcomes that can occur under AV. Included among AV outcomes are those given by scoring rules, single transferable vote, the majoritarian compromise, Condorcet systems, and others as well. Under each of these systems, a Condorcet winner may be upset through manipulation by individual voters or coalitions of voters, whereas AV ensures the election of a Condorcet winner as a strong Nash equilibrium wherein voters use sincere strategies. To be sure, AV may also elect Condorcet losers and other lesser candidates, sometimes in equilibrium. This multiplicity of (equilibrium) outcomes is the product of a social-choice framework that is more general than the standard preference-based one. From a normative perspective, we argue that voter judgments about candidate acceptability should take precedence over the usual social-choice criteria, such as electing a Condorcet or Borda winner. Keywords: approval voting; elections; Condorcet winner/loser; voting games; Nash equilibrium. Acknowledgments. We thank Eyal Baharad, Dan S. Felsenthal, Peter C. Fishburn, Shmuel Nitzan, Richard F. Potthoff, and Ismail Saglam for valuable suggestions. 3 1. Introduction Our thesis in this paper is that several outcomes of single-winner elections may be socially acceptable, depending on voters’ individual views on the acceptability of the candidates. -

A Generalization of the Minisum and Minimax Voting Methods
A Generalization of the Minisum and Minimax Voting Methods Shankar N. Sivarajan Undergraduate, Department of Physics Indian Institute of Science Bangalore 560 012, India [email protected] Faculty Advisor: Prof. Y. Narahari Deparment of Computer Science and Automation Revised Version: December 4, 2017 Abstract In this paper, we propose a family of approval voting-schemes for electing committees based on the preferences of voters. In our schemes, we calcu- late the vector of distances of the possible committees from each of the ballots and, for a given p-norm, choose the one that minimizes the magni- tude of the distance vector under that norm. The minisum and minimax methods suggested by previous authors and analyzed extensively in the literature naturally appear as special cases corresponding to p = 1 and p = 1; respectively. Supported by examples, we suggest that using a small value of p; such as 2 or 3, provides a good compromise between the minisum and minimax voting methods with regard to the weightage given to approvals and disapprovals. For large but finite p; our method reduces to finding the committee that covers the maximum number of voters, and this is far superior to the minimax method which is prone to ties. We also discuss extensions of our methods to ternary voting. 1 Introduction In this paper, we consider the problem of selecting a committee of k members out of n candidates based on preferences expressed by m voters. The most common way of conducting this election is to allow each voter to select his favorite candidate and vote for him/her, and we select the k candidates with the most number of votes. -

1 Introduction 2 Condorcet and Borda Tallies
1 Introduction General introduction goes here. 2 Condorcet and Borda Tallies 2.1 Definitions We are primarily interested in comparing the behaviors of two information aggregation methods, namely the Condorcet and Borda tallies. This interest is motivated by both historical and practical concerns: the relative merits of the two methods have been argued since the 18th century, and, although variations on the Borda tally are much more common in practice, there is a significant body of theoretical evidence that the Condorcet tally is in many cases superior. To begin, we provide formal definitions of both of these methods, and of a generalized information aggregation problem. An information aggregation problem, often referred to simply as a voting problem, is a problem which involves taking information from a number of disparate sources, and using this information to produce a single output. Problems of this type arise in numerous domains. In political science, they are common, occurring whenever voters cast votes which are used to decide 1 the outcome of some issue. Although less directly, they also occur in fields as diverse as control theory and cognitive science. Wherever there is a system which must coalesce information from its subsystems, there is potentially the need to balance conflicting information about a single topic. In any such circumstance, if there is not reason to trust any single source more than the others, the problem can be phrased as one of information aggregation. 2.1.1 Information Aggregation Problems To facilitate the formalization of these problems, we only consider cases in which a finite number of information sources (which shall henceforth be re- ferred to as voters) provide information regarding some contested issue. -

Are Condorcet and Minimax Voting Systems the Best?1
1 Are Condorcet and Minimax Voting Systems the Best?1 Richard B. Darlington Cornell University Abstract For decades, the minimax voting system was well known to experts on voting systems, but was not widely considered to be one of the best systems. But in recent years, two important experts, Nicolaus Tideman and Andrew Myers, have both recognized minimax as one of the best systems. I agree with that. This paper presents my own reasons for preferring minimax. The paper explicitly discusses about 20 systems. Comments invited. [email protected] Copyright Richard B. Darlington May be distributed free for non-commercial purposes Keywords Voting system Condorcet Minimax 1. Many thanks to Nicolaus Tideman, Andrew Myers, Sharon Weinberg, Eduardo Marchena, my wife Betsy Darlington, and my daughter Lois Darlington, all of whom contributed many valuable suggestions. 2 Table of Contents 1. Introduction and summary 3 2. The variety of voting systems 4 3. Some electoral criteria violated by minimax’s competitors 6 Monotonicity 7 Strategic voting 7 Completeness 7 Simplicity 8 Ease of voting 8 Resistance to vote-splitting and spoiling 8 Straddling 8 Condorcet consistency (CC) 8 4. Dismissing eight criteria violated by minimax 9 4.1 The absolute loser, Condorcet loser, and preference inversion criteria 9 4.2 Three anti-manipulation criteria 10 4.3 SCC/IIA 11 4.4 Multiple districts 12 5. Simulation studies on voting systems 13 5.1. Why our computer simulations use spatial models of voter behavior 13 5.2 Four computer simulations 15 5.2.1 Features and purposes of the studies 15 5.2.2 Further description of the studies 16 5.2.3 Results and discussion 18 6. -

MGF 1107 FINAL EXAM REVIEW CHAPTER 9 1. Amy (A), Betsy
MGF 1107 FINAL EXAM REVIEW CHAPTER 9 1. Amy (A), Betsy (B), Carla (C), Doris (D), and Emilia (E) are candidates for an open Student Government seat. There are 110 voters with the preference lists below. 36 24 20 18 8 4 A E D B C C B C E D E D C B C C B B D D B E D E E A A A A A Who wins the election if the method used is: a) plurality? b) plurality with runoff? c) sequential pairwise voting with agenda ABEDC? d) Hare system? e) Borda count? 2. What is the minimum number of votes needed for a majority if the number of votes cast is: a) 120? b) 141? 3. Consider the following preference lists: 1 1 1 A C B B A D D B C C D A If sequential pairwise voting and the agenda BACD is used, then D wins the election. Suppose the middle voter changes his mind and reverses his ranking of A and B. If the other two voters have unchanged preferences, B now wins using the same agenda BACD. This example shows that sequential pairwise voting fails to satisfy what desirable property of a voting system? 4. Consider the following preference lists held by 5 voters: 2 2 1 A B C C C B B A A First, note that if the plurality with runoff method is used, B wins. Next, note that C defeats both A and B in head-to-head matchups. This example shows that the plurality with runoff method fails to satisfy which desirable property of a voting system? 5. -

On the Distortion of Voting with Multiple Representative Candidates∗
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) On the Distortion of Voting with Multiple Representative Candidates∗ Yu Cheng Shaddin Dughmi David Kempe Duke University University of Southern California University of Southern California Abstract voters and the chosen candidate in a suitable metric space (Anshelevich 2016; Anshelevich, Bhardwaj, and Postl 2015; We study positional voting rules when candidates and voters Anshelevich and Postl 2016; Goel, Krishnaswamy, and Mu- are embedded in a common metric space, and cardinal pref- erences are naturally given by distances in the metric space. nagala 2017). The underlying assumption is that the closer In a positional voting rule, each candidate receives a score a candidate is to a voter, the more similar their positions on from each ballot based on the ballot’s rank order; the candi- key questions are. Because proximity implies that the voter date with the highest total score wins the election. The cost would benefit from the candidate’s election, voters will rank of a candidate is his sum of distances to all voters, and the candidates by increasing distance, a model known as single- distortion of an election is the ratio between the cost of the peaked preferences (Black 1948; Downs 1957; Black 1958; elected candidate and the cost of the optimum candidate. We Moulin 1980; Merrill and Grofman 1999; Barbera,` Gul, consider the case when candidates are representative of the and Stacchetti 1993; Richards, Richards, and McKay 1998; population, in the sense that they are drawn i.i.d. from the Barbera` 2001). population of the voters, and analyze the expected distortion Even in the absence of strategic voting, voting systems of positional voting rules. -

Stable Voting
Stable Voting Wesley H. Hollidayy and Eric Pacuitz y University of California, Berkeley ([email protected]) z University of Maryland ([email protected]) September 12, 2021 Abstract In this paper, we propose a new single-winner voting system using ranked ballots: Stable Voting. The motivating principle of Stable Voting is that if a candidate A would win without another candidate B in the election, and A beats B in a head-to-head majority comparison, then A should still win in the election with B included (unless there is another candidate A0 who has the same kind of claim to winning, in which case a tiebreaker may choose between A and A0). We call this principle Stability for Winners (with Tiebreaking). Stable Voting satisfies this principle while also having a remarkable ability to avoid tied outcomes in elections even with small numbers of voters. 1 Introduction Voting reform efforts in the United States have achieved significant recent successes in replacing Plurality Voting with Instant Runoff Voting (IRV) for major political elections, including the 2018 San Francisco Mayoral Election and the 2021 New York City Mayoral Election. It is striking, by contrast, that Condorcet voting methods are not currently used in any political elections.1 Condorcet methods use the same ranked ballots as IRV but replace the counting of first-place votes with head- to-head comparisons of candidates: do more voters prefer candidate A to candidate B or prefer B to A? If there is a candidate A who beats every other candidate in such a head-to-head majority comparison, this so-called Condorcet winner wins the election. -
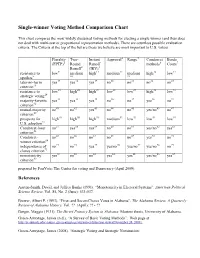
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Voting Procedures and Their Properties
Voting Theory AAAI-2010 Voting Procedures and their Properties Ulle Endriss 8 Voting Theory AAAI-2010 Voting Procedures We’ll discuss procedures for n voters (or individuals, agents, players) to collectively choose from a set of m alternatives (or candidates): • Each voter votes by submitting a ballot, e.g., the name of a single alternative, a ranking of all alternatives, or something else. • The procedure defines what are valid ballots, and how to aggregate the ballot information to obtain a winner. Remark 1: There could be ties. So our voting procedures will actually produce sets of winners. Tie-breaking is a separate issue. Remark 2: Formally, voting rules (or resolute voting procedures) return single winners; voting correspondences return sets of winners. Ulle Endriss 9 Voting Theory AAAI-2010 Plurality Rule Under the plurality rule each voter submits a ballot showing the name of one alternative. The alternative(s) receiving the most votes win(s). Remarks: • Also known as the simple majority rule (6= absolute majority rule). • This is the most widely used voting procedure in practice. • If there are only two alternatives, then it is a very good procedure. Ulle Endriss 10 Voting Theory AAAI-2010 Criticism of the Plurality Rule Problems with the plurality rule (for more than two alternatives): • The information on voter preferences other than who their favourite candidate is gets ignored. • Dispersion of votes across ideologically similar candidates. • Encourages voters not to vote for their true favourite, if that candidate is perceived to have little chance of winning. Ulle Endriss 11 Voting Theory AAAI-2010 Plurality with Run-Off Under the plurality rule with run-off , each voter initially votes for one alternative. -

Computational Perspectives on Democracy
Computational Perspectives on Democracy Anson Kahng CMU-CS-21-126 August 2021 Computer Science Department School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 Thesis Committee: Ariel Procaccia (Chair) Chinmay Kulkarni Nihar Shah Vincent Conitzer (Duke University) David Pennock (Rutgers University) Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Copyright c 2021 Anson Kahng This research was sponsored by the National Science Foundation under grant numbers IIS-1350598, CCF- 1525932, and IIS-1714140, the Department of Defense under grant number W911NF1320045, the Office of Naval Research under grant number N000141712428, and the JP Morgan Research grant. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied, of any sponsoring institution, the U.S. government or any other entity. Keywords: Computational Social Choice, Theoretical Computer Science, Artificial Intelligence For Grandpa and Harabeoji. iv Abstract Democracy is a natural approach to large-scale decision-making that allows people affected by a potential decision to provide input about the outcome. However, modern implementations of democracy are based on outdated infor- mation technology and must adapt to the changing technological landscape. This thesis explores the relationship between computer science and democracy, which is, crucially, a two-way street—just as principles from computer science can be used to analyze and design democratic paradigms, ideas from democracy can be used to solve hard problems in computer science. Question 1: What can computer science do for democracy? To explore this first question, we examine the theoretical foundations of three democratic paradigms: liquid democracy, participatory budgeting, and multiwinner elections. -

Chapter 9:Social Choice: the Impossible Dream
Chapter 9:Social Choice: The Impossible Dream September 18, 2013 Chapter 9:Social Choice: The Impossible Dream Last Time Last time we talked about Voting systems Majority Rule Condorcet's Method Plurality Borda Count Sequential Pairwise Voting Chapter 9:Social Choice: The Impossible Dream Condorcet's Method Definition A ballot consisting of such a rank ordering of candidates is called a preference list ballot because it is a statement of the preferences of the individual who is voting. Description of Condorcet's Method With the voting system known as Condorcet's method, a candidate is a winner precisely when he or she would, on the basis of the ballots cast, defeat every other candidate in a one-on-one contest using majority rule. Chapter 9:Social Choice: The Impossible Dream Example Consider the following set of preference lists: Number of Voters(9) Rank 3 1 1 1 1 1 1 First A A B B C C D Second D C C C B D B Third C B D A D B C Fourth B D A D A A A Winner: C Chapter 9:Social Choice: The Impossible Dream Pros and Cons of Condorcet's Method Pro: Takes all preferences into account. Con: Condorcet's Voting Paradox With three or more candidates, there are elections in which Condorcet's method yields no winners. In particular, the following ballots constitute an election in which Condorcet's method yields no winner. Chapter 9:Social Choice: The Impossible Dream Plurality Voting Plurality Voting Each voter pick their top choice. Chapter 9:Social Choice: The Impossible Dream Example Consider the following set of preference lists: Number of Voters(9) Rank 3 1 1 1 1 1 1 First A A B B C C D Second D B C C B D C Third B C D A D B B Fourth C D A D A A A Winner: A Chapter 9:Social Choice: The Impossible Dream Pros and Cons of Plurality Voting May's Theorem Among all two-candidate voting systems that never result in a tie, majority rule is the only one that treats all voters equally, treats both candidates equally, and is monotone. -

Complexity of Control of Borda Count Elections
Rochester Institute of Technology RIT Scholar Works Theses 2007 Complexity of control of Borda count elections Nathan Russell Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Russell, Nathan, "Complexity of control of Borda count elections" (2007). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Rochester Institute of Technology Department of Computer Science Complexity of Control of Borda Count Elections By Nathan F. Russell [email protected] July 9, 2007 A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science Edith Hemaspaandra, Chairperson Christopher Homan, Reader Piotr Faliszewski, Observer 1 Contents Chapter 1. Introduction and history of the Borda count 5 Chapter 2. Definitions 13 2.1. Elections in General 13 2.2. Means of control to be considered 17 Chapter 3. Prior work 23 3.1. Manipulation 23 3.2. Control 26 Chapter 4. Analysis of the Borda count 35 4.1. Addition and deletion of voters 35 4.2. Partition of voters 45 4.3. Addition and deletion of candidates 48 4.4. Summary of new results 50 Chapter 5. Conclusions 51 5.1. Further work 55 Bibliography 59 3 CHAPTER 1 Introduction and history of the Borda count In this thesis, we discuss some existing and new results relating to computational aspects of voting. In particular, we consider, apparently for the first time, the computational complexity of the application of certain types of control to the Borda count voting system.