Molecular Sciences High-Resolution Chromosome Ideogram Representation of Currently Recognized Genes for Autism Spectrum Disorder
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nuclear and Mitochondrial Genome Defects in Autisms
UC Irvine UC Irvine Previously Published Works Title Nuclear and mitochondrial genome defects in autisms. Permalink https://escholarship.org/uc/item/8vq3278q Journal Annals of the New York Academy of Sciences, 1151(1) ISSN 0077-8923 Authors Smith, Moyra Spence, M Anne Flodman, Pamela Publication Date 2009 DOI 10.1111/j.1749-6632.2008.03571.x License https://creativecommons.org/licenses/by/4.0/ 4.0 Peer reviewed eScholarship.org Powered by the California Digital Library University of California THE YEAR IN HUMAN AND MEDICAL GENETICS 2009 Nuclear and Mitochondrial Genome Defects in Autisms Moyra Smith, M. Anne Spence, and Pamela Flodman Department of Pediatrics, University of California, Irvine, California In this review we will evaluate evidence that altered gene dosage and structure im- pacts neurodevelopment and neural connectivity through deleterious effects on synap- tic structure and function, and evidence that the latter are key contributors to the risk for autism. We will review information on alterations of structure of mitochondrial DNA and abnormal mitochondrial function in autism and indications that interactions of the nuclear and mitochondrial genomes may play a role in autism pathogenesis. In a final section we will present data derived using Affymetrixtm SNP 6.0 microar- ray analysis of DNA of a number of subjects and parents recruited to our autism spectrum disorders project. We include data on two sets of monozygotic twins. Col- lectively these data provide additional evidence of nuclear and mitochondrial genome imbalance in autism and evidence of specific candidate genes in autism. We present data on dosage changes in genes that map on the X chromosomes and the Y chro- mosome. -

Mouse Germ Line Mutations Due to Retrotransposon Insertions Liane Gagnier1, Victoria P
Gagnier et al. Mobile DNA (2019) 10:15 https://doi.org/10.1186/s13100-019-0157-4 REVIEW Open Access Mouse germ line mutations due to retrotransposon insertions Liane Gagnier1, Victoria P. Belancio2 and Dixie L. Mager1* Abstract Transposable element (TE) insertions are responsible for a significant fraction of spontaneous germ line mutations reported in inbred mouse strains. This major contribution of TEs to the mutational landscape in mouse contrasts with the situation in human, where their relative contribution as germ line insertional mutagens is much lower. In this focussed review, we provide comprehensive lists of TE-induced mouse mutations, discuss the different TE types involved in these insertional mutations and elaborate on particularly interesting cases. We also discuss differences and similarities between the mutational role of TEs in mice and humans. Keywords: Endogenous retroviruses, Long terminal repeats, Long interspersed elements, Short interspersed elements, Germ line mutation, Inbred mice, Insertional mutagenesis, Transcriptional interference Background promoter and polyadenylation motifs and often a splice The mouse and human genomes harbor similar types of donor site [10, 11]. Sequences of full-length ERVs can TEs that have been discussed in many reviews, to which encode gag, pol and sometimes env, although groups of we refer the reader for more in depth and general infor- LTR retrotransposons with little or no retroviral hom- mation [1–9]. In general, both human and mouse con- ology also exist [6–9]. While not the subject of this re- tain ancient families of DNA transposons, none view, ERV LTRs can often act as cellular enhancers or currently active, which comprise 1–3% of these genomes promoters, creating chimeric transcripts with genes, and as well as many families or groups of retrotransposons, have been implicated in other regulatory functions [11– which have caused all the TE insertional mutations in 13]. -

AGAP1 (NM 014914) Human Recombinant Protein Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TP314836 AGAP1 (NM_014914) Human Recombinant Protein Product data: Product Type: Recombinant Proteins Description: Recombinant protein of human ArfGAP with GTPase domain, ankyrin repeat and PH domain 1 (AGAP1), transcript variant 2 Species: Human Expression Host: HEK293T Tag: C-Myc/DDK Predicted MW: 88.9 kDa Concentration: >50 ug/mL as determined by microplate BCA method Purity: > 80% as determined by SDS-PAGE and Coomassie blue staining Buffer: 25 mM Tris.HCl, pH 7.3, 100 mM glycine, 10% glycerol Preparation: Recombinant protein was captured through anti-DDK affinity column followed by conventional chromatography steps. Storage: Store at -80°C. Stability: Stable for 12 months from the date of receipt of the product under proper storage and handling conditions. Avoid repeated freeze-thaw cycles. RefSeq: NP_055729 Locus ID: 116987 UniProt ID: Q9UPQ3 RefSeq Size: 4078 Cytogenetics: 2q37.2 RefSeq ORF: 2412 Synonyms: AGAP-1; CENTG2; cnt-g2; GGAP1 Summary: This gene encodes a member of an ADP-ribosylation factor GTPase-activating protein family involved in membrane trafficking and cytoskeleton dynamics. This gene functions as a direct regulator of the adaptor-related protein complex 3 on endosomes. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Oct 2011] This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 AGAP1 (NM_014914) Human Recombinant Protein – TP314836 Protein Pathways: Endocytosis Product images: Coomassie blue staining of purified AGAP1 protein (Cat# TP314836). -

Supplemental Table S1
Entrez Gene Symbol Gene Name Affymetrix EST Glomchip SAGE Stanford Literature HPA confirmed Gene ID Profiling profiling Profiling Profiling array profiling confirmed 1 2 A2M alpha-2-macroglobulin 0 0 0 1 0 2 10347 ABCA7 ATP-binding cassette, sub-family A (ABC1), member 7 1 0 0 0 0 3 10350 ABCA9 ATP-binding cassette, sub-family A (ABC1), member 9 1 0 0 0 0 4 10057 ABCC5 ATP-binding cassette, sub-family C (CFTR/MRP), member 5 1 0 0 0 0 5 10060 ABCC9 ATP-binding cassette, sub-family C (CFTR/MRP), member 9 1 0 0 0 0 6 79575 ABHD8 abhydrolase domain containing 8 1 0 0 0 0 7 51225 ABI3 ABI gene family, member 3 1 0 1 0 0 8 29 ABR active BCR-related gene 1 0 0 0 0 9 25841 ABTB2 ankyrin repeat and BTB (POZ) domain containing 2 1 0 1 0 0 10 30 ACAA1 acetyl-Coenzyme A acyltransferase 1 (peroxisomal 3-oxoacyl-Coenzyme A thiol 0 1 0 0 0 11 43 ACHE acetylcholinesterase (Yt blood group) 1 0 0 0 0 12 58 ACTA1 actin, alpha 1, skeletal muscle 0 1 0 0 0 13 60 ACTB actin, beta 01000 1 14 71 ACTG1 actin, gamma 1 0 1 0 0 0 15 81 ACTN4 actinin, alpha 4 0 0 1 1 1 10700177 16 10096 ACTR3 ARP3 actin-related protein 3 homolog (yeast) 0 1 0 0 0 17 94 ACVRL1 activin A receptor type II-like 1 1 0 1 0 0 18 8038 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 1 0 0 0 0 19 8751 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 1 0 0 0 0 20 8728 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 1 0 0 0 0 21 81792 ADAMTS12 ADAM metallopeptidase with thrombospondin type 1 motif, 12 1 0 0 0 0 22 9507 ADAMTS4 ADAM metallopeptidase with thrombospondin type 1 -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

ANKRD11 Gene Ankyrin Repeat Domain 11
ANKRD11 gene ankyrin repeat domain 11 Normal Function The ANKRD11 gene provides instructions for making a protein called ankyrin repeat domain 11 (ANKRD11). As its name suggests, this protein contains multiple regions called ankyrin domains; proteins with these domains help other proteins interact with each other. The ANKRD11 protein interacts with certain proteins called histone deacetylases, which are important for controlling gene activity. Through these interactions, ANKRD11 affects when genes are turned on and off. For example, ANKRD11 brings together histone deacetylases and other proteins called p160 coactivators. This association regulates the ability of p160 coactivators to turn on gene activity. ANKRD11 may also enhance the activity of a protein called p53, which controls the growth and division (proliferation) and the self-destruction (apoptosis) of cells. The ANKRD11 protein is found in nerve cells (neurons) in the brain. During embryonic development, ANKRD11 helps regulate the proliferation of these cells and development of the brain. Researchers speculate that the protein may also be involved in the ability of neurons to change and adapt over time (plasticity), which is important for learning and memory. ANKRD11 may function in other cells in the body and appears to be involved in normal bone development. Health Conditions Related to Genetic Changes KBG syndrome Several ANKRD11 gene mutations have been found to cause KBG syndrome, a condition characterized by large upper front teeth and other unusual facial features, skeletal abnormalities, and intellectual disability. Most of these mutations lead to an abnormally short ANKRD11 protein, which likely has little or no function. Reduction of this protein's function is thought to underlie the signs and symptoms of the condition. -

Investigating the Genetic Basis of Cisplatin-Induced Ototoxicity in Adult South African Patients
--------------------------------------------------------------------------- Investigating the genetic basis of cisplatin-induced ototoxicity in adult South African patients --------------------------------------------------------------------------- by Timothy Francis Spracklen SPRTIM002 SUBMITTED TO THE UNIVERSITY OF CAPE TOWN In fulfilment of the requirements for the degree MSc(Med) Faculty of Health Sciences UNIVERSITY OF CAPE TOWN University18 December of Cape 2015 Town Supervisor: Prof. Rajkumar S Ramesar Co-supervisor: Ms A Alvera Vorster Division of Human Genetics, Department of Pathology, University of Cape Town 1 The copyright of this thesis vests in the author. No quotation from it or information derived from it is to be published without full acknowledgement of the source. The thesis is to be used for private study or non- commercial research purposes only. Published by the University of Cape Town (UCT) in terms of the non-exclusive license granted to UCT by the author. University of Cape Town Declaration I, Timothy Spracklen, hereby declare that the work on which this dissertation/thesis is based is my original work (except where acknowledgements indicate otherwise) and that neither the whole work nor any part of it has been, is being, or is to be submitted for another degree in this or any other university. I empower the university to reproduce for the purpose of research either the whole or any portion of the contents in any manner whatsoever. Signature: Date: 18 December 2015 ' 2 Contents Abbreviations ………………………………………………………………………………….. 1 List of figures …………………………………………………………………………………... 6 List of tables ………………………………………………………………………………….... 7 Abstract ………………………………………………………………………………………… 10 1. Introduction …………………………………………………………………………………. 11 1.1 Cancer …………………………………………………………………………….. 11 1.2 Adverse drug reactions ………………………………………………………….. 12 1.3 Cisplatin …………………………………………………………………………… 12 1.3.1 Cisplatin’s mechanism of action ……………………………………………… 13 1.3.2 Adverse reactions to cisplatin therapy ………………………………………. -

Open Dogan Phdthesis Final.Pdf
The Pennsylvania State University The Graduate School Eberly College of Science ELUCIDATING BIOLOGICAL FUNCTION OF GENOMIC DNA WITH ROBUST SIGNALS OF BIOCHEMICAL ACTIVITY: INTEGRATIVE GENOME-WIDE STUDIES OF ENHANCERS A Dissertation in Biochemistry, Microbiology and Molecular Biology by Nergiz Dogan © 2014 Nergiz Dogan Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy August 2014 ii The dissertation of Nergiz Dogan was reviewed and approved* by the following: Ross C. Hardison T. Ming Chu Professor of Biochemistry and Molecular Biology Dissertation Advisor Chair of Committee David S. Gilmour Professor of Molecular and Cell Biology Anton Nekrutenko Professor of Biochemistry and Molecular Biology Robert F. Paulson Professor of Veterinary and Biomedical Sciences Philip Reno Assistant Professor of Antropology Scott B. Selleck Professor and Head of the Department of Biochemistry and Molecular Biology *Signatures are on file in the Graduate School iii ABSTRACT Genome-wide measurements of epigenetic features such as histone modifications, occupancy by transcription factors and coactivators provide the opportunity to understand more globally how genes are regulated. While much effort is being put into integrating the marks from various combinations of features, the contribution of each feature to accuracy of enhancer prediction is not known. We began with predictions of 4,915 candidate erythroid enhancers based on genomic occupancy by TAL1, a key hematopoietic transcription factor that is strongly associated with gene induction in erythroid cells. Seventy of these DNA segments occupied by TAL1 (TAL1 OSs) were tested by transient transfections of cultured hematopoietic cells, and 56% of these were active as enhancers. Sixty-six TAL1 OSs were evaluated in transgenic mouse embryos, and 65% of these were active enhancers in various tissues. -

AVILA-DISSERTATION.Pdf
LOGOS EX MACHINA: A REASONED APPROACH TOWARD CANCER by Andrew Avila, B. S., M. S. A Dissertation In Biological Sciences Submitted to the Graduate Faculty of Texas Tech University in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Approved Lauren Gollahon Chairperson of the Committee Rich Strauss Sean Rice Boyd Butler Richard Watson Peggy Gordon Miller Dean of the Graduate School May, 2012 c 2012, Andrew Avila Texas Tech University, Andrew Avila, May 2012 ACKNOWLEDGEMENTS I wish to acknowledge the incredible support given to me by my major adviser, Dr. Lauren Gollahon. Without your guidance surely I would not have made it as far as I have. Furthermore, the intellectual exchange I have shared with my advisory committee these long years have propelled me to new heights of inquiry I had not dreamed of even in the most lucid of my imaginings. That their continual intellectual challenges have provoked and evoked a subtle sense of natural wisdom is an ode to their efficacy in guiding the aspirant to the well of knowledge. For this initiation into the mysteries of nature I cannot thank my advisory committee enough. I also wish to thank the Vice President of Research for the fellowship which sustained the initial couple years of my residency at Texas Tech. Furthermore, my appreciation of the support provided to me by the Biology Department, financial and otherwise, cannot be understated. Finally, I also wish to acknowledge the individuals working at the High Performance Computing Center, without your tireless support in maintaining the cluster I would have not have completed the sheer amount of research that I have. -

ARTICLE Doi:10.1038/Nature10523
ARTICLE doi:10.1038/nature10523 Spatio-temporal transcriptome of the human brain Hyo Jung Kang1*, Yuka Imamura Kawasawa1*, Feng Cheng1*, Ying Zhu1*, Xuming Xu1*, Mingfeng Li1*, Andre´ M. M. Sousa1,2, Mihovil Pletikos1,3, Kyle A. Meyer1, Goran Sedmak1,3, Tobias Guennel4, Yurae Shin1, Matthew B. Johnson1,Zˇeljka Krsnik1, Simone Mayer1,5, Sofia Fertuzinhos1, Sheila Umlauf6, Steven N. Lisgo7, Alexander Vortmeyer8, Daniel R. Weinberger9, Shrikant Mane6, Thomas M. Hyde9,10, Anita Huttner8, Mark Reimers4, Joel E. Kleinman9 & Nenad Sˇestan1 Brain development and function depend on the precise regulation of gene expression. However, our understanding of the complexity and dynamics of the transcriptome of the human brain is incomplete. Here we report the generation and analysis of exon-level transcriptome and associated genotyping data, representing males and females of different ethnicities, from multiple brain regions and neocortical areas of developing and adult post-mortem human brains. We found that 86 per cent of the genes analysed were expressed, and that 90 per cent of these were differentially regulated at the whole-transcript or exon level across brain regions and/or time. The majority of these spatio-temporal differences were detected before birth, with subsequent increases in the similarity among regional transcriptomes. The transcriptome is organized into distinct co-expression networks, and shows sex-biased gene expression and exon usage. We also profiled trajectories of genes associated with neurobiological categories and diseases, and identified associations between single nucleotide polymorphisms and gene expression. This study provides a comprehensive data set on the human brain transcriptome and insights into the transcriptional foundations of human neurodevelopment. -
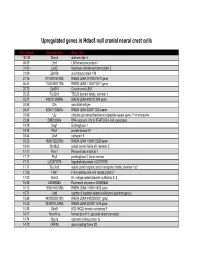
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

A Private 16Q24.2Q24.3 Microduplication in a Boy with Intellectual Disability, Speech Delay and Mild Dysmorphic Features
G C A T T A C G G C A T genes Article A Private 16q24.2q24.3 Microduplication in a Boy with Intellectual Disability, Speech Delay and Mild Dysmorphic Features Orazio Palumbo * , Pietro Palumbo , Ester Di Muro, Luigia Cinque, Antonio Petracca, Massimo Carella and Marco Castori Division of Medical Genetics, Fondazione IRCCS-Casa Sollievo della Sofferenza, San Giovanni Rotondo, 71013 Foggia, Italy; [email protected] (P.P.); [email protected] (E.D.M.); [email protected] (L.C.); [email protected] (A.P.); [email protected] (M.C.); [email protected] (M.C.) * Correspondence: [email protected]; Tel.: +39-088-241-6350 Received: 5 June 2020; Accepted: 24 June 2020; Published: 26 June 2020 Abstract: No data on interstitial microduplications of the 16q24.2q24.3 chromosome region are available in the medical literature and remain extraordinarily rare in public databases. Here, we describe a boy with a de novo 16q24.2q24.3 microduplication at the Single Nucleotide Polymorphism (SNP)-array analysis spanning ~2.2 Mb and encompassing 38 genes. The patient showed mild-to-moderate intellectual disability, speech delay and mild dysmorphic features. In DECIPHER, we found six individuals carrying a “pure” overlapping microduplication. Although available data are very limited, genomic and phenotype comparison of our and previously annotated patients suggested a potential clinical relevance for 16q24.2q24.3 microduplication with a variable and not (yet) recognizable phenotype predominantly affecting cognition. Comparing the cytogenomic data of available individuals allowed us to delineate the smallest region of overlap involving 14 genes. Accordingly, we propose ANKRD11, CDH15, and CTU2 as candidate genes for explaining the related neurodevelopmental manifestations shared by these patients.