Abstract Syntax Trees and Symbol Tables
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Using the Unibasic Debugger
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\DEBUGGER\BASBTITL.fm March 8, 2010 10:30 am Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Using the UniBasic Debugger UDT-720-UDEB-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\DEBUGGER\BASBTITL.fm March 8, 2010 10:30 am Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July 2008 Book number: UDT-720-UDEB-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2008. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii Using the UniBasic Debugger The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Kednos PL/I for Openvms Systems User Manual
) Kednos PL/I for OpenVMS Systems User Manual Order Number: AA-H951E-TM November 2003 This manual provides an overview of the PL/I programming language. It explains programming with Kednos PL/I on OpenVMS VAX Systems and OpenVMS Alpha Systems. It also describes the operation of the Kednos PL/I compilers and the features of the operating systems that are important to the PL/I programmer. Revision/Update Information: This revised manual supersedes the PL/I User’s Manual for VAX VMS, Order Number AA-H951D-TL. Operating System and Version: For Kednos PL/I for OpenVMS VAX: OpenVMS VAX Version 5.5 or higher For Kednos PL/I for OpenVMS Alpha: OpenVMS Alpha Version 6.2 or higher Software Version: Kednos PL/I Version 3.8 for OpenVMS VAX Kednos PL/I Version 4.4 for OpenVMS Alpha Published by: Kednos Corporation, Pebble Beach, CA, www.Kednos.com First Printing, August 1980 Revised, November 1983 Updated, April 1985 Revised, April 1987 Revised, January 1992 Revised, May 1992 Revised, November 1993 Revised, April 1995 Revised, October 1995 Revised, November 2003 Kednos Corporation makes no representations that the use of its products in the manner described in this publication will not infringe on existing or future patent rights, nor do the descriptions contained in this publication imply the granting of licenses to make, use, or sell equipment or software in accordance with the description. Possession, use, or copying of the software described in this publication is authorized only pursuant to a valid written license from Kednos Corporation or an anthorized sublicensor. -

Data General Extended Algol 60 Compiler
DATA GENERAL EXTENDED ALGOL 60 COMPILER, Data General's Extended ALGOL is a powerful language tial I/O with optional formatting. These extensions comple which allows systems programmers to develop programs ment the basic structure of ALGOL and significantly in on mini computers that would otherwise require the use of crease the convenience of ALGOL programming without much larger, more expensive computers. No other mini making the language unwieldy. computer offers a language with the programming features and general applicability of Data General's Extended FEATURES OF DATA GENERAL'S EXTENDED ALGOL Character strings are implemented as an extended data ALGOL. type to allow easy manipulation of character data. The ALGOL 60 is the most widely used language for describ program may, for example, read in character strings, search ing programming algorithms. It has a flexible, generalized, for substrings, replace characters, and maintain character arithmetic organization and a modular, "building block" string tables efficiently. structure that provides clear, easily readable documentation. Multi-precision arithmetic allows up to 60 decimal digits The language is powerful and concise, allowing the systems of precision in integer or floating point calculations. programmer to state algorithms without resorting to "tricks" Device-independent I/O provides for reading and writ to bypass the language. ing in line mode, sequential mode, or random mode.' Free These characteristics of ALGOL are especially important form reading and writing is permitted for all data types, or in the development of working prototype systems. The output can be formatted according to a "picture" of the clear documentation makes it easy for the programmer to output line or lines. -

Supplementary Materials
Contents 2 Programming Language Syntax C 1 2.3.5 Syntax Errors C 1 2.4 Theoretical Foundations C 13 2.4.1 Finite Automata C 13 2.4.2 Push-Down Automata C 18 2.4.3 Grammar and Language Classes C 19 2.6 Exercises C 24 2.7 Explorations C 25 3 Names, Scopes, and Bindings C 26 3.4 Implementing Scope C 26 3.4.1 Symbol Tables C 26 3.4.2 Association Lists and Central Reference Tables C 31 3.8 Separate Compilation C 36 3.8.1 Separate Compilation in C C 37 3.8.2 Packages and Automatic Header Inference C 40 3.8.3 Module Hierarchies C 41 3.10 Exercises C 42 3.11 Explorations C 44 4SemanticAnalysis C 45 4.5 Space Management for Attributes C 45 4.5.1 Bottom-Up Evaluation C 45 4.5.2 Top-Down Evaluation C 50 C ii Contents 4.8 Exercises C 57 4.9 Explorations C 59 5 Target Machine Architecture C 60 5.1 The Memory Hierarchy C 61 5.2 Data Representation C 63 5.2.1 Integer Arithmetic C 65 5.2.2 Floating-Point Arithmetic C 67 5.3 Instruction Set Architecture (ISA) C 70 5.3.1 Addressing Modes C 71 5.3.2 Conditions and Branches C 72 5.4 Architecture and Implementation C 75 5.4.1 Microprogramming C 76 5.4.2 Microprocessors C 77 5.4.3 RISC C 77 5.4.4 Multithreading and Multicore C 78 5.4.5 Two Example Architectures: The x86 and ARM C 80 5.5 Compiling for Modern Processors C 88 5.5.1 Keeping the Pipeline Full C 89 5.5.2 Register Allocation C 93 5.6 Summary and Concluding Remarks C 98 5.7 Exercises C 100 5.8 Explorations C 104 5.9 Bibliographic Notes C 105 6 Control Flow C 107 6.5.4 Generators in Icon C 107 6.7 Nondeterminacy C 110 6.9 Exercises C 116 6.10 Explorations -

AST Indexing: a Near-Constant Time Solution to the Get-Descendants-By-Type Problem Samuel Livingston Kelly Dickinson College
Dickinson College Dickinson Scholar Student Honors Theses By Year Student Honors Theses 5-18-2014 AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem Samuel Livingston Kelly Dickinson College Follow this and additional works at: http://scholar.dickinson.edu/student_honors Part of the Software Engineering Commons Recommended Citation Kelly, Samuel Livingston, "AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem" (2014). Dickinson College Honors Theses. Paper 147. This Honors Thesis is brought to you for free and open access by Dickinson Scholar. It has been accepted for inclusion by an authorized administrator. For more information, please contact [email protected]. AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem by Sam Kelly Submitted in partial fulfillment of Honors Requirements for the Computer Science Major Dickinson College, 2014 Associate Professor Tim Wahls, Supervisor Associate Professor John MacCormick, Reader Part-Time Instructor Rebecca Wells, Reader April 22, 2014 The Department of Mathematics and Computer Science at Dickinson College hereby accepts this senior honors thesis by Sam Kelly, and awards departmental honors in Computer Science. Tim Wahls (Advisor) Date John MacCormick (Committee Member) Date Rebecca Wells (Committee Member) Date Richard Forrester (Department Chair) Date Department of Mathematics and Computer Science Dickinson College April 2014 ii Abstract AST Indexing: A Near-Constant Time Solution to the Get- Descendants-by-Type Problem by Sam Kelly In this paper we present two novel abstract syntax tree (AST) indexing algorithms that solve the get-descendants-by-type problem in near constant time. -
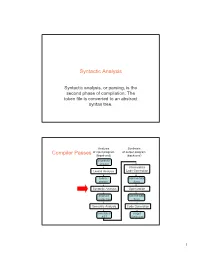
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -

CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 12
CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 12: Symbol Tables February 15, 2008 CS 412/413 Spring 2008 Introduction to Compilers 1 Where We Are Source code if (b == 0) a = b; (character stream) Lexical Analysis Token if ( b == 0 ) a = b ; stream Syntax Analysis if (Parsing) == = Abstract syntax tree (AST) b0ab if Semantic Analysis boolean int Decorated == = AST int b int 0 int a int b Errors lvalue (incorrect program) CS 412/413 Spring 2008 Introduction to Compilers 2 Non-Context-Free Syntax • Programs that are correct with respect to the language’s lexical and context-free syntactic rules may still contain other syntactic errors • Lexical analysis and context-free syntax analysis are not powerful enough to ensure the correct usage of variables, objects, functions, statements, etc. • Non-context-free syntactic analysis is known as semantic analysis CS 412/413 Spring 2008 Introduction to Compilers 3 Incorrect Programs •Example 1: lexical analysis does not distinguish between different variable or function identifiers (it returns the same token for all identifiers) int a; int a; a = 1; b = 1; •Example 2: syntax analysis does not correlate the declarations with the uses of variables in the program: int a; a = 1; a = 1; •Example3: syntax analysis does not correlate the types from the declarations with the uses of variables: int a; int a; a = 1; a = 1.0; CS 412/413 Spring 2008 Introduction to Compilers 4 Goals of Semantic Analysis • Semantic analysis ensures that the program satisfies a set of additional rules regarding the -

Understanding Source Code Evolution Using Abstract Syntax Tree Matching
Understanding Source Code Evolution Using Abstract Syntax Tree Matching Iulian Neamtiu Jeffrey S. Foster Michael Hicks [email protected] [email protected] [email protected] Department of Computer Science University of Maryland at College Park ABSTRACT so understanding how the type structure of real programs Mining software repositories at the source code level can pro- changes over time can be invaluable for weighing the merits vide a greater understanding of how software evolves. We of DSU implementation choices. Second, we are interested in present a tool for quickly comparing the source code of dif- a kind of “release digest” for explaining changes in a software ferent versions of a C program. The approach is based on release: what functions or variables have changed, where the partial abstract syntax tree matching, and can track sim- hot spots are, whether or not the changes affect certain com- ple changes to global variables, types and functions. These ponents, etc. Typical release notes can be too high level for changes can characterize aspects of software evolution use- developers, and output from diff can be too low level. ful for answering higher level questions. In particular, we To answer these and other software evolution questions, consider how they could be used to inform the design of a we have developed a tool that can quickly tabulate and sum- dynamic software updating system. We report results based marize simple changes to successive versions of C programs on measurements of various versions of popular open source by partially matching their abstract syntax trees. The tool programs, including BIND, OpenSSH, Apache, Vsftpd and identifies the changes, additions, and deletions of global vari- the Linux kernel. -

Parsing with Earley Virtual Machines
Communication papers of the Federated Conference on DOI: 10.15439/2017F162 Computer Science and Information Systems, pp. 165–173 ISSN 2300-5963 ACSIS, Vol. 13 Parsing with Earley Virtual Machines Audrius Saikˇ unas¯ Institute of Mathematics and Informatics Akademijos 4, LT-08663 Vilnius, Lithuania Email: [email protected] Abstract—Earley parser is a well-known parsing method used EVM is capable of parsing context-free languages with data- to analyse context-free grammars. While being less efficient in dependant constraints. The core idea behind of EVM is to practical contexts than other generalized context-free parsing have two different grammar representations: one is user- algorithms, such as GLR, it is also more general. As such it can be used as a foundation to build more complex parsing algorithms. friendly and used to define grammars, while the other is used We present a new, virtual machine based approach to parsing, internally during parsing. Therefore, we end up with grammars heavily based on the original Earley parser. We present several that specify the languages in a user-friendly way, which are variations of the Earley Virtual Machine, each with increasing then compiled into grammar programs that are executed or feature set. The final version of the Earley Virtual Machine is interpreted by the EVM to match various input sequences. capable of parsing context-free grammars with data-dependant constraints and support grammars with regular right hand sides We present several iterations of EVM: and regular lookahead. • EVM0 that is equivalent to the original Earley parser in We show how to translate grammars into virtual machine it’s capabilities.