Neil Walkinshaw Consistency in the Face of Complexity and Change
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Sad State of Web Development Random Thoughts on Web Development
The Sad State of Web Development Random thoughts on web development Going to shit 2015 is when web development went to shit. Web development used to be nice. You could fire up a text editor and start creating JS and CSS files. You can absolutely still do this. That has not changed. So yes, everything I’m about to say can be invalidated by saying that. The web (specifically the Javascript/Node community) has created some of the most complicated, convoluted, over engineered tools ever conceived. Node.js/NPM At times, I think where web development is at this point is some cruel joke played on us by Ryan Dahl. You see, to get into why web development is so terrible, you have to start at Node. By definition I was a magpie developer, so undoubtedly I used Node, just as everyone should. At universities they should make every developer write an app with Node.js, deploy it to production, then try to update the dependencies 3 months later. The only downside is we would have zero new developers coming out of computer science programs. You see the Node.js philosophy is to take the worst fucking language ever designed and put it on the server. Combine that with all the magpies that were using Ruby at the time, and you have the perfect fucking storm. Lets take everything that was great in Ruby and re write it in Javascript, I think was the official motto. Most of the smart magpies have moved on to Go at this point, but the people who have stayed in the Node community have undoubtedly created the most over engineered eco system that has ever appeared. -
16 Inspiring Women Engineers to Watch
Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com 16 Inspiring Women Engineers To Watch Women's engineering school Hackbright Academy is excited to share some updates from graduates of the software engineering fellowship. Check out what these 16 women are doing now at their companies - and what languages, frameworks, databases and other technologies these engineers use on the job! Software Engineer, Aclima Tiffany Williams is a software engineer at Aclima, where she builds software tools to ingest, process and manage city-scale environmental data sets enabled by Aclima’s sensor networks. Follow her on Twitter at @twilliamsphd. Technologies: Python, SQL, Cassandra, MariaDB, Docker, Kubernetes, Google Cloud Software Engineer, Eventbrite 1 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com Maggie Shine works on backend and frontend application development to make buying a ticket on Eventbrite a great experience. In 2014, she helped build a WiFi-enabled basal body temperature fertility tracking device at a hardware hackathon. Follow her on Twitter at @magksh. Technologies: Python, Django, Celery, MySQL, Redis, Backbone, Marionette, React, Sass User Experience Engineer, GoDaddy 2 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. -

CROP: Linking Code Reviews to Source Code Changes
CROP: Linking Code Reviews to Source Code Changes Matheus Paixao Jens Krinke University College London University College London London, United Kingdom London, United Kingdom [email protected] [email protected] Donggyun Han Mark Harman University College London Facebook and University College London London, United Kingdom London, United Kingdom [email protected] [email protected] ABSTRACT both industrial and open source software development communities. Code review has been widely adopted by both industrial and open For example, large organisations such as Google and Facebook use source software development communities. Research in code re- code review systems on a daily basis [5, 9]. view is highly dependant on real-world data, and although existing In addition to its increasing popularity among practitioners, researchers have attempted to provide code review datasets, there code review has also drawn the attention of software engineering is still no dataset that links code reviews with complete versions of researchers. There have been empirical studies on the effect of code the system’s code base mainly because reviewed versions are not review on many aspects of software engineering, including software kept in the system’s version control repository. Thus, we present quality [11, 12], review automation [2], and automated reviewer CROP, the Code Review Open Platform, the first curated code recommendation [20]. Recently, other research areas in software review repository that links review data with isolated complete engineering have leveraged the data generated during code review versions (snapshots) of the source code at the time of review. CROP to expand previously limited datasets and to perform empirical currently provides data for 8 software systems, 48,975 reviews and studies. -

Crawling Code Review Data from Phabricator
Friedrich-Alexander-Universit¨atErlangen-N¨urnberg Technische Fakult¨at,Department Informatik DUMITRU COTET MASTER THESIS CRAWLING CODE REVIEW DATA FROM PHABRICATOR Submitted on 4 June 2019 Supervisors: Michael Dorner, M. Sc. Prof. Dr. Dirk Riehle, M.B.A. Professur f¨urOpen-Source-Software Department Informatik, Technische Fakult¨at Friedrich-Alexander-Universit¨atErlangen-N¨urnberg Versicherung Ich versichere, dass ich die Arbeit ohne fremde Hilfe und ohne Benutzung anderer als der angegebenen Quellen angefertigt habe und dass die Arbeit in gleicher oder ¨ahnlicherForm noch keiner anderen Pr¨ufungsbeh¨ordevorgelegen hat und von dieser als Teil einer Pr¨ufungsleistung angenommen wurde. Alle Ausf¨uhrungen,die w¨ortlich oder sinngem¨aߨubernommenwurden, sind als solche gekennzeichnet. Nuremberg, 4 June 2019 License This work is licensed under the Creative Commons Attribution 4.0 International license (CC BY 4.0), see https://creativecommons.org/licenses/by/4.0/ Nuremberg, 4 June 2019 i Abstract Modern code review is typically supported by software tools. Researchers use data tracked by these tools to study code review practices. A popular tool in open-source and closed-source projects is Phabricator. However, there is no tool to crawl all the available code review data from Phabricator hosts. In this thesis, we develop a Python crawler named Phabry, for crawling code review data from Phabricator instances using its REST API. The tool produces minimal server and client load, reproducible crawling runs, and stores complete and genuine review data. The new tool is used to crawl the Phabricator instances of the open source projects FreeBSD, KDE and LLVM. The resulting data sets can be used by researchers. -

Letter, If Not the Spirit, of One Or the Other Definition
Producing Open Source Software How to Run a Successful Free Software Project Karl Fogel Producing Open Source Software: How to Run a Successful Free Software Project by Karl Fogel Copyright © 2005-2021 Karl Fogel, under the CreativeCommons Attribution-ShareAlike (4.0) license. Version: 2.3214 Home site: https://producingoss.com/ Dedication This book is dedicated to two dear friends without whom it would not have been possible: Karen Under- hill and Jim Blandy. i Table of Contents Preface ............................................................................................................................. vi Why Write This Book? ............................................................................................... vi Who Should Read This Book? ..................................................................................... vi Sources ................................................................................................................... vii Acknowledgements ................................................................................................... viii For the first edition (2005) ................................................................................ viii For the second edition (2021) .............................................................................. ix Disclaimer .............................................................................................................. xiii 1. Introduction ................................................................................................................... -

Jetbrains Upsource Comparison Upsource Is a Powerful Tool for Teams Wish- Key Benefits Ing to Improve Their Code, Projects and Pro- Cesses
JetBrains Upsource Comparison Upsource is a powerful tool for teams wish- Key benefits ing to improve their code, projects and pro- cesses. It serves as a polyglot code review How Upsource Compares to Other Code Review Tools tool, a source of data-driven project ana- lytics, an intelligent repository browser and Accuracy of Comparison a team collaboration center. Upsource boasts in-depth knowledge of Java, PHP, JavaScript, Integration with JetBrains Tools Python, and Kotlin to increase the efcien- cy of code reviews. It continuously analyzes Sales Contacts the repository activity providing a valuable insight into potential design problems and project risks. On top of that Upsource makes team collaboration easy and enjoyable. Key benefits IDE-level code insight to help developers Automated workflow, to minimize manual tasks. Powerful search engine. understand and review code changes more efectively. Smart suggestion of suitable reviewers, revi- IDE plugins that allow developers to partici- sions, etc. based on historical data and intel- pate in code reviews right from their IDEs. Data-driven project analytics highlighting ligent progress tracking. potential design flaws such as hotspots, abandoned files and more. Unified access to all your Git, Mercurial, Secure, and scalable. Perforce or Subversion projects. To learn more about Upsource, please visit our website at jetbrains.com/upsource. How Upsource Compares to Other Code Review Tools JetBrains has extensively researched various As all the products mentioned in the docu- tools to come up with a useful comparison ment are being actively developed and their table. We tried to make it as comprehensive functionality changes on a regular basis, this and neutral as we possibly could. -
Phabricator 538D8f2... Overview
Institute of Computational Science Phabricator 538d8f2... overview Dmitry Mikushin (for the Bugs Course) . October 17, 2013 Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 1 / 14 . What is Phabricator? The LAMP-based web-server + command-line client for: peer code review task management project communication And it’s open-source Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 2 / 14 . Test drive! Browse to http://devel.kernelgen.org, login and look around Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 3 / 14 . Key features Peer code review Integrated environment for request reviewing, tasks/bugs and versioning system - in web environment - in command line Ergonomic task interface Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 4 / 14 . Key features Peer code review Integrated environment for request reviewing, tasks/bugs and versioning system - in web environment - in command line Ergonomic task interface Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 5 / 14 . Peer code review: traditional 1 RFC: Developer publishes a patch with the source and tests 2 Other developers comment on the patch issues/improvements 3 After all issues are addressed, reviewers ACK patch for commit 4 Developer himself or someone with rw rights commits the patch Everything is over email Relationship with Bugs: fixes for PRs are also reviewed this way Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 6 / 14 . Peer code review: Phabricator approach 1 Developer check-ins the patch to the Phabricator over the command line (passing lint/unit tests, if any) $ arc diff . -
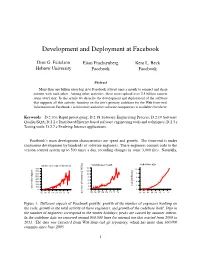
Development and Deployment at Facebook
Development and Deployment at Facebook Dror G. Feitelson Eitan Frachtenberg Kent L. Beck Hebrew University Facebook Facebook Abstract More than one billion users log in to Facebook at least once a month to connect and share content with each other. Among other activities, these users upload over 2.5 billion content items every day. In this article we describe the development and deployment of the software that supports all this activity, focusing on the site’s primary codebase for the Web front-end. Information on Facebook’s architecture and other software components is available elsewhere. Keywords D.2.10.i Rapid prototyping; D.2.18 Software Engineering Process; D.2.19 Software Quality/SQA; D.2.2.c Distributed/Internet based software engineering tools and techniques; D.2.5.r Testing tools; D.2.7.e Evolving Internet applications. Facebook’s main development characteristics are speed and growth. The front-end is under continuous development by hundreds of software engineers. These engineers commit code to the version control system up to 500 times a day, recording changes in some 3,000 files. Naturally, codebase size unique developers by week commits per month 14 800 10 700 12 600 10 8 500 8 6 400 6 300 4 4 200 LoC [millions] 2 100 2 active developers 0 0 0 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 number of commits [1000s] ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 Figure 1: Different aspects of Facebook growth: growth of the number of engineers working on the code, growth in the total activity of these engineers, and growth of the codebase itself. -

Zerorpc) by Jérôme Petazzoni from Dot- Cloud 73 10.1 Introduction
Marc’s PyCon 2012 Notes Documentation Release 1.0 Marc Abramowitz January 27, 2014 Contents 1 Stop Mocking, Start Testing by Augie Fackler and Nathaniel Manista from Google Code3 1.1 Modern Mocking.............................................4 1.2 Testing Today..............................................4 1.3 Injected dependencies..........................................5 1.4 Separate state from behavior.......................................5 1.5 Define interfaces between components.................................5 1.6 Decline to write a test when there’s no clear interface..........................5 1.7 Thank you................................................5 1.8 Questions.................................................6 2 Fast test, slow test by Gary Bernhardt from destroyallsoftware.com7 2.1 Goals of tests...............................................7 2.2 How To Fail...............................................9 2.3 Unit tests................................................. 10 2.4 The End................................................. 11 2.5 Questions................................................. 11 3 Speedily Practical Large-Scale Tests with Erik Rose from Votizen 13 3.1 Die, setUp(), die............................................. 13 3.2 Die, fixtures, die............................................. 13 4 Fake It Til You Make It: Unit Testing Patterns With Mocks And Fakes by Brian K. Jones 17 4.1 Your Speaker............................................... 17 4.2 What’s covered............................................. -

Sapfix: Automated End-To-End Repair at Scale
SapFix: Automated End-to-End Repair at Scale A. Marginean, J. Bader, S. Chandra, M. Harman, Y. Jia, K. Mao, A. Mols, A. Scott Facebook Inc. Abstract—We report our experience with SAPFIX: the first In order to deploy such a fully automated end-to-end detect- deployment of automated end-to-end fault fixing, from test case and-fix process we naturally needed to combine a number of design through to deployed repairs in production code1. We have different techniques. Nevertheless the SAPFIX core algorithm used SAPFIX at Facebook to repair 6 production systems, each consisting of tens of millions of lines of code, and which are is a simple one. Specifically, it combines straightforward collectively used by hundreds of millions of people worldwide. approaches to mutation testing [8], [9], search-based software testing [6], [10], [11], and fault localisation [12] as well as INTRODUCTION existing developer-designed test cases. We also needed to Automated program repair seeks to find small changes to deploy many practical engineering techniques and develop software systems that patch known bugs [1], [2]. One widely new engineering solutions in order to ensure scalability. studied approach uses software testing to guide the repair SAPFIX combines a mutation-based technique, augmented by process, as typified by the GenProg approach to search-based patterns inferred from previous human fixes, with a reversion-as- program repair [3]. last resort strategy for high-firing crashes (that would otherwise Recently, the automated test case design system, Sapienz block further testing, if not fixed or removed). This core fixing [4], has been deployed at scale [5], [6]. -

Holistic Configuration Management at Facebook
Holistic Configuration Management at Facebook Chunqiang Tang, Thawan Kooburat, Pradeep Venkatachalam, Akshay Chander, Zhe Wen, Aravind Narayanan, Patrick Dowell, and Robert Karl Facebook Inc. ftang, thawan, pradvenkat, akshay, wenzhe, aravindn, pdowell, [email protected] Abstract the many challenges. This paper presents Facebook’s holistic Facebook’s web site and mobile apps are very dynamic. configuration management solution. Facebook uses Chef [7] Every day, they undergo thousands of online configuration to manage OS settings and software deployment [11], which changes, and execute trillions of configuration checks to is not the focus of this paper. Instead, we focus on the home- personalize the product features experienced by hundreds grown tools for managing applications’ dynamic runtime of million of daily active users. For example, configuration configurations that may be updated live multiple times a changes help manage the rollouts of new product features, day, without application redeployment or restart. Examples perform A/B testing experiments on mobile devices to iden- include gating product rollouts, managing application-level tify the best echo-canceling parameters for VoIP, rebalance traffic, and running A/B testing experiments. the load across global regions, and deploy the latest machine Below, we outline the key challenges in configuration learning models to improve News Feed ranking. This paper management for an Internet service and our solutions. gives a comprehensive description of the use cases, design, Configuration sprawl. Facebook internally has a large implementation, and usage statistics of a suite of tools that number of systems, including frontend products, backend manage Facebook’s configuration end-to-end, including the services, mobile apps, data stores, etc. -

Khodayari and Giancarlo Pellegrino, CISPA Helmholtz Center for Information Security
JAW: Studying Client-side CSRF with Hybrid Property Graphs and Declarative Traversals Soheil Khodayari and Giancarlo Pellegrino, CISPA Helmholtz Center for Information Security https://www.usenix.org/conference/usenixsecurity21/presentation/khodayari This paper is included in the Proceedings of the 30th USENIX Security Symposium. August 11–13, 2021 978-1-939133-24-3 Open access to the Proceedings of the 30th USENIX Security Symposium is sponsored by USENIX. JAW: Studying Client-side CSRF with Hybrid Property Graphs and Declarative Traversals Soheil Khodayari Giancarlo Pellegrino CISPA Helmholtz Center CISPA Helmholtz Center for Information Security for Information Security Abstract ior and avoiding the inclusion of HTTP cookies in cross-site Client-side CSRF is a new type of CSRF vulnerability requests (see, e.g., [28, 29]). In the client-side CSRF, the vul- where the adversary can trick the client-side JavaScript pro- nerable component is the JavaScript program instead, which gram to send a forged HTTP request to a vulnerable target site allows an attacker to generate arbitrary requests by modifying by modifying the program’s input parameters. We have little- the input parameters of the JavaScript program. As opposed to-no knowledge of this new vulnerability, and exploratory to the traditional CSRF, existing anti-CSRF countermeasures security evaluations of JavaScript-based web applications are (see, e.g., [28, 29, 34]) are not sufficient to protect web appli- impeded by the scarcity of reliable and scalable testing tech- cations from client-side CSRF attacks. niques. This paper presents JAW, a framework that enables the Client-side CSRF is very new—with the first instance af- analysis of modern web applications against client-side CSRF fecting Facebook in 2018 [24]—and we have little-to-no leveraging declarative traversals on hybrid property graphs, a knowledge of the vulnerable behaviors, the severity of this canonical, hybrid model for JavaScript programs.