Crawling Code Review Data from Phabricator
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Sad State of Web Development Random Thoughts on Web Development
The Sad State of Web Development Random thoughts on web development Going to shit 2015 is when web development went to shit. Web development used to be nice. You could fire up a text editor and start creating JS and CSS files. You can absolutely still do this. That has not changed. So yes, everything I’m about to say can be invalidated by saying that. The web (specifically the Javascript/Node community) has created some of the most complicated, convoluted, over engineered tools ever conceived. Node.js/NPM At times, I think where web development is at this point is some cruel joke played on us by Ryan Dahl. You see, to get into why web development is so terrible, you have to start at Node. By definition I was a magpie developer, so undoubtedly I used Node, just as everyone should. At universities they should make every developer write an app with Node.js, deploy it to production, then try to update the dependencies 3 months later. The only downside is we would have zero new developers coming out of computer science programs. You see the Node.js philosophy is to take the worst fucking language ever designed and put it on the server. Combine that with all the magpies that were using Ruby at the time, and you have the perfect fucking storm. Lets take everything that was great in Ruby and re write it in Javascript, I think was the official motto. Most of the smart magpies have moved on to Go at this point, but the people who have stayed in the Node community have undoubtedly created the most over engineered eco system that has ever appeared. -
16 Inspiring Women Engineers to Watch
Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com 16 Inspiring Women Engineers To Watch Women's engineering school Hackbright Academy is excited to share some updates from graduates of the software engineering fellowship. Check out what these 16 women are doing now at their companies - and what languages, frameworks, databases and other technologies these engineers use on the job! Software Engineer, Aclima Tiffany Williams is a software engineer at Aclima, where she builds software tools to ingest, process and manage city-scale environmental data sets enabled by Aclima’s sensor networks. Follow her on Twitter at @twilliamsphd. Technologies: Python, SQL, Cassandra, MariaDB, Docker, Kubernetes, Google Cloud Software Engineer, Eventbrite 1 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com Maggie Shine works on backend and frontend application development to make buying a ticket on Eventbrite a great experience. In 2014, she helped build a WiFi-enabled basal body temperature fertility tracking device at a hardware hackathon. Follow her on Twitter at @magksh. Technologies: Python, Django, Celery, MySQL, Redis, Backbone, Marionette, React, Sass User Experience Engineer, GoDaddy 2 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. -

Learning React Functional Web Development with React and Redux
Learning React Functional Web Development with React and Redux Alex Banks and Eve Porcello Beijing Boston Farnham Sebastopol Tokyo Learning React by Alex Banks and Eve Porcello Copyright © 2017 Alex Banks and Eve Porcello. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com/safari). For more information, contact our corporate/insti‐ tutional sales department: 800-998-9938 or [email protected]. Editor: Allyson MacDonald Indexer: WordCo Indexing Services Production Editor: Melanie Yarbrough Interior Designer: David Futato Copyeditor: Colleen Toporek Cover Designer: Karen Montgomery Proofreader: Rachel Head Illustrator: Rebecca Demarest May 2017: First Edition Revision History for the First Edition 2017-04-26: First Release See http://oreilly.com/catalog/errata.csp?isbn=9781491954621 for release details. The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Learning React, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights. -

CROP: Linking Code Reviews to Source Code Changes
CROP: Linking Code Reviews to Source Code Changes Matheus Paixao Jens Krinke University College London University College London London, United Kingdom London, United Kingdom [email protected] [email protected] Donggyun Han Mark Harman University College London Facebook and University College London London, United Kingdom London, United Kingdom [email protected] [email protected] ABSTRACT both industrial and open source software development communities. Code review has been widely adopted by both industrial and open For example, large organisations such as Google and Facebook use source software development communities. Research in code re- code review systems on a daily basis [5, 9]. view is highly dependant on real-world data, and although existing In addition to its increasing popularity among practitioners, researchers have attempted to provide code review datasets, there code review has also drawn the attention of software engineering is still no dataset that links code reviews with complete versions of researchers. There have been empirical studies on the effect of code the system’s code base mainly because reviewed versions are not review on many aspects of software engineering, including software kept in the system’s version control repository. Thus, we present quality [11, 12], review automation [2], and automated reviewer CROP, the Code Review Open Platform, the first curated code recommendation [20]. Recently, other research areas in software review repository that links review data with isolated complete engineering have leveraged the data generated during code review versions (snapshots) of the source code at the time of review. CROP to expand previously limited datasets and to perform empirical currently provides data for 8 software systems, 48,975 reviews and studies. -

UNIVERSITY of CALIFORNIA SAN DIEGO Simplifying Datacenter Fault
UNIVERSITY OF CALIFORNIA SAN DIEGO Simplifying datacenter fault detection and localization A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science by Arjun Roy Committee in charge: Alex C. Snoeren, Co-Chair Ken Yocum, Co-Chair George Papen George Porter Stefan Savage Geoff Voelker 2018 Copyright Arjun Roy, 2018 All rights reserved. The Dissertation of Arjun Roy is approved and is acceptable in quality and form for publication on microfilm and electronically: Co-Chair Co-Chair University of California San Diego 2018 iii DEDICATION Dedicated to my grandmother, Bela Sarkar. iv TABLE OF CONTENTS Signature Page . iii Dedication . iv Table of Contents . v List of Figures . viii List of Tables . x Acknowledgements . xi Vita........................................................................ xiii Abstract of the Dissertation . xiv Chapter 1 Introduction . 1 Chapter 2 Datacenters, applications, and failures . 6 2.1 Datacenter applications, networks and faults . 7 2.1.1 Datacenter application patterns . 7 2.1.2 Datacenter networks . 10 2.1.3 Datacenter partial faults . 14 2.2 Partial faults require passive impact monitoring . 17 2.2.1 Multipath hampers server-centric monitoring . 18 2.2.2 Partial faults confuse network-centric monitoring . 19 2.3 Unifying network and server centric monitoring . 21 2.3.1 Load-balanced links mean outliers correspond with partial faults . 22 2.3.2 Centralized network control enables collating viewpoints . 23 Chapter 3 Related work, challenges and a solution . 24 3.1 Fault localization effectiveness criteria . 24 3.2 Existing fault management techniques . 28 3.2.1 Server-centric fault detection . 28 3.2.2 Network-centric fault detection . -

Letter, If Not the Spirit, of One Or the Other Definition
Producing Open Source Software How to Run a Successful Free Software Project Karl Fogel Producing Open Source Software: How to Run a Successful Free Software Project by Karl Fogel Copyright © 2005-2021 Karl Fogel, under the CreativeCommons Attribution-ShareAlike (4.0) license. Version: 2.3214 Home site: https://producingoss.com/ Dedication This book is dedicated to two dear friends without whom it would not have been possible: Karen Under- hill and Jim Blandy. i Table of Contents Preface ............................................................................................................................. vi Why Write This Book? ............................................................................................... vi Who Should Read This Book? ..................................................................................... vi Sources ................................................................................................................... vii Acknowledgements ................................................................................................... viii For the first edition (2005) ................................................................................ viii For the second edition (2021) .............................................................................. ix Disclaimer .............................................................................................................. xiii 1. Introduction ................................................................................................................... -

Artificial Intelligence for Understanding Large and Complex
Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Abstract Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Copyright © 2020 by Pengfei Zheng All rights reserved except the rights granted by the Creative Commons Attribution-Noncommercial Licence Abstract As the democratization of global-scale web applications and cloud computing, under- standing the performance of a live production datacenter becomes a prerequisite for making strategic decisions related to datacenter design and optimization. Advances in monitoring, tracing, and profiling large, complex systems provide rich datasets and establish a rigorous foundation for performance understanding and reasoning. But the sheer volume and complexity of collected data challenges existing techniques, which rely heavily on human intervention, expert knowledge, and simple statistics. In this dissertation, we address this challenge using artificial intelligence and make the case for two important problems, datacenter performance diagnosis and datacenter workload characterization. The first thrust of this dissertation is the use of statistical causal inference and Bayesian probabilistic model for datacenter straggler diagnosis. -

Jetbrains Upsource Comparison Upsource Is a Powerful Tool for Teams Wish- Key Benefits Ing to Improve Their Code, Projects and Pro- Cesses
JetBrains Upsource Comparison Upsource is a powerful tool for teams wish- Key benefits ing to improve their code, projects and pro- cesses. It serves as a polyglot code review How Upsource Compares to Other Code Review Tools tool, a source of data-driven project ana- lytics, an intelligent repository browser and Accuracy of Comparison a team collaboration center. Upsource boasts in-depth knowledge of Java, PHP, JavaScript, Integration with JetBrains Tools Python, and Kotlin to increase the efcien- cy of code reviews. It continuously analyzes Sales Contacts the repository activity providing a valuable insight into potential design problems and project risks. On top of that Upsource makes team collaboration easy and enjoyable. Key benefits IDE-level code insight to help developers Automated workflow, to minimize manual tasks. Powerful search engine. understand and review code changes more efectively. Smart suggestion of suitable reviewers, revi- IDE plugins that allow developers to partici- sions, etc. based on historical data and intel- pate in code reviews right from their IDEs. Data-driven project analytics highlighting ligent progress tracking. potential design flaws such as hotspots, abandoned files and more. Unified access to all your Git, Mercurial, Secure, and scalable. Perforce or Subversion projects. To learn more about Upsource, please visit our website at jetbrains.com/upsource. How Upsource Compares to Other Code Review Tools JetBrains has extensively researched various As all the products mentioned in the docu- tools to come up with a useful comparison ment are being actively developed and their table. We tried to make it as comprehensive functionality changes on a regular basis, this and neutral as we possibly could. -
Phabricator 538D8f2... Overview
Institute of Computational Science Phabricator 538d8f2... overview Dmitry Mikushin (for the Bugs Course) . October 17, 2013 Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 1 / 14 . What is Phabricator? The LAMP-based web-server + command-line client for: peer code review task management project communication And it’s open-source Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 2 / 14 . Test drive! Browse to http://devel.kernelgen.org, login and look around Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 3 / 14 . Key features Peer code review Integrated environment for request reviewing, tasks/bugs and versioning system - in web environment - in command line Ergonomic task interface Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 4 / 14 . Key features Peer code review Integrated environment for request reviewing, tasks/bugs and versioning system - in web environment - in command line Ergonomic task interface Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 5 / 14 . Peer code review: traditional 1 RFC: Developer publishes a patch with the source and tests 2 Other developers comment on the patch issues/improvements 3 After all issues are addressed, reviewers ACK patch for commit 4 Developer himself or someone with rw rights commits the patch Everything is over email Relationship with Bugs: fixes for PRs are also reviewed this way Dmitry Mikushin Test-drive at http://devel.kernelgen.org October 17, 2013 6 / 14 . Peer code review: Phabricator approach 1 Developer check-ins the patch to the Phabricator over the command line (passing lint/unit tests, if any) $ arc diff . -

Unicorn: a System for Searching the Social Graph
Unicorn: A System for Searching the Social Graph Michael Curtiss, Iain Becker, Tudor Bosman, Sergey Doroshenko, Lucian Grijincu, Tom Jackson, Sandhya Kunnatur, Soren Lassen, Philip Pronin, Sriram Sankar, Guanghao Shen, Gintaras Woss, Chao Yang, Ning Zhang Facebook, Inc. ABSTRACT rative of the evolution of Unicorn's architecture, as well as Unicorn is an online, in-memory social graph-aware index- documentation for the major features and components of ing system designed to search trillions of edges between tens the system. of billions of users and entities on thousands of commodity To the best of our knowledge, no other online graph re- servers. Unicorn is based on standard concepts in informa- trieval system has ever been built with the scale of Unicorn tion retrieval, but it includes features to promote results in terms of both data volume and query volume. The sys- with good social proximity. It also supports queries that re- tem serves tens of billions of nodes and trillions of edges quire multiple round-trips to leaves in order to retrieve ob- at scale while accounting for per-edge privacy, and it must jects that are more than one edge away from source nodes. also support realtime updates for all edges and nodes while Unicorn is designed to answer billions of queries per day at serving billions of daily queries at low latencies. latencies in the hundreds of milliseconds, and it serves as an This paper includes three main contributions: infrastructural building block for Facebook's Graph Search • We describe how we applied common information re- product. In this paper, we describe the data model and trieval architectural concepts to the domain of the so- query language supported by Unicorn. -
Development and Deployment at Facebook
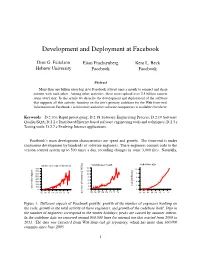
Development and Deployment at Facebook Dror G. Feitelson Eitan Frachtenberg Kent L. Beck Hebrew University Facebook Facebook Abstract More than one billion users log in to Facebook at least once a month to connect and share content with each other. Among other activities, these users upload over 2.5 billion content items every day. In this article we describe the development and deployment of the software that supports all this activity, focusing on the site’s primary codebase for the Web front-end. Information on Facebook’s architecture and other software components is available elsewhere. Keywords D.2.10.i Rapid prototyping; D.2.18 Software Engineering Process; D.2.19 Software Quality/SQA; D.2.2.c Distributed/Internet based software engineering tools and techniques; D.2.5.r Testing tools; D.2.7.e Evolving Internet applications. Facebook’s main development characteristics are speed and growth. The front-end is under continuous development by hundreds of software engineers. These engineers commit code to the version control system up to 500 times a day, recording changes in some 3,000 files. Naturally, codebase size unique developers by week commits per month 14 800 10 700 12 600 10 8 500 8 6 400 6 300 4 4 200 LoC [millions] 2 100 2 active developers 0 0 0 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 number of commits [1000s] ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 Figure 1: Different aspects of Facebook growth: growth of the number of engineers working on the code, growth in the total activity of these engineers, and growth of the codebase itself. -

2.3 Apache Chemistry
UNIVERSITY OF DUBLIN TRINITY COLLEGE DISSERTATION PRESENTED TO THE UNIVERSITY OF DUBLIN,TRINITY COLLEGE IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF MAGISTER IN ARTE INGENIARIA Content Interoperability and Open Source Content Management Systems An implementation of the CMIS standard as a PHP library Author: Supervisor: MATTHEW NICHOLSON DAVE LEWIS Submitted to the University of Dublin, Trinity College, May, 2015 Declaration I, Matthew Nicholson, declare that the following dissertation, except where otherwise stated, is entirely my own work; that it has not previously been submitted as an exercise for a degree, either in Trinity College Dublin, or in any other University; and that the library may lend or copy it or any part thereof on request. May 21, 2015 Matthew Nicholson i Summary This paper covers the design, implementation and evaluation of PHP li- brary to aid in use of the Content Management Interoperability Services (CMIS) standard. The standard attempts to provide a language indepen- dent and platform specific mechanisms to better allow content manage- ment systems (CM systems) work together. There is currently no PHP implementation of CMIS server framework available, at least not widely. The name given to the library is Elaphus CMIS. The implementation should remove a barrier for making PHP CM sys- tems CMIS compliant. Aswell testing how language independent the stan- dard is and look into the features of PHP programming language. The technologies that are the focus of this report are: CMIS A standard that attempts to structure the data within a wide range of CM systems and provide standardised API for interacting with this data.