Conference Program
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
![[Myanmar] Research Society Brief History of the Burma](https://docslib.b-cdn.net/cover/2607/myanmar-research-society-brief-history-of-the-burma-2607.webp)
[Myanmar] Research Society Brief History of the Burma
Analytical Study on the Publications edited and published by the Burma [Myanmar] Research Society Ni Win Zaw Abstract The Burma Research Society (BRS) was founded on 29th. March 1910 and had a programmee to Publish, in printed book-form, important texts from Myanmar palm-leaf and parabike paper manuscripts. The BRS did most valuable work in carefully editing and publishing many old manuscripts texts. The famous Myanmar scholar Dr. Pe Maung Tin served as the BRS General Editor for its Text Program from the early 1920s to about 1940 when the Society had to cease its activities due to the Second World War. After Second World War U Wun (Min Thu Wun) and U Tin E made energetic efforts for the BRS. U Wun served asa the General Editor for the New Series. This Paper describes authors, editors, editions, printing presses, publishing dates, cover style, arrangements, physical descriptions, series numbers, appendixes, indexes, footnotes, and subjects of these books.And also it identifies the performance of editors who were prominent Myanmar and Pali scholars like Saya Lin, Saya Pwa, U Po Sein, BaganWundauk U Tin, U Lu Pe Win, U Chan Mya, U Wun, U Thein Han, and others. Moreover,abilities of ancient Myanmar authors and role of old Myanmar literature are investigated and expressed in this paper. Brief History of the Burma (Myanmar ) Research Society The Burma Research Society was founded on 29th. March 1910 at Bernard Free Library in Rangoon (Yangon) by J.S.Furnivall who was a member of the India Civil Service stationed in Myanmar together with some learned Myanmar officials like U May Oung.1After Opening the Rangoon (Yangon) University, the headquarter of the Society was located at the Rangoon University (Universities' Central Library), from about 1930-1980. -

Small-Package Delivery Services in Asean
FOSTERING COMPETITION IN ASEAN OECD COMPETITIVE NEUTRALITY REVIEWS: SMALL-PACKAGE DELIVERY SERVICES IN ASEAN SERVICES DELIVERY OECD COMPETITIVE NEUTRALITY REVIEWS: SMALL-PACKAGE OECD Competitive Neutrality Reviews ASEAN SMALL-PACKAGE DELIVERY SERVICES OECD Competitive Neutrality Reviews: Small-Package Delivery Services in ASEAN PUBE 2 Please cite this publication as: OECD (2021), OECD Competitive Neutrality Reviews: Small-Package Delivery Services in ASEAN https://www.oecd.org/competition/fostering-competition-in-asean.htm This work is published under the responsibility of the Secretary-General of the OECD. The opinions expressed and arguments employed herein do not necessarily reflect the official views of the OECD or of the governments of its member countries or those of the European Union. This document and any map included herein are without prejudice to the status or sovereignty over any territory, to the delimitation of international frontiers and boundaries and to the name of any territory, city, or area. The OECD has two official languages: English and French. The English version of this report is the only official one. © OECD 2021 OECD COMPETITIVE NEUTRALITY REVIEWS: SMALL-PACKAGE DELIVERY SERVICES IN ASEAN © OECD 2021 3 Foreword As one of the fastest growing regions in the world, Southeast Asia has benefited from broadly embracing economic growth models based on international trade, foreign investment and integration into regional and global value chains. Maintaining this momentum, however, will require certain reforms to strengthen the region’s economic and social sustainability. This will include reducing regulatory barriers to competition and market entry to help foster innovation, efficiency and productivity. The logistics sector plays a significant role in fostering economic development. -

Śāntiniketan and Modern Southeast Asian
Artl@s Bulletin Volume 5 Article 2 Issue 2 South - South Axes of Global Art 2016 Śāntiniketan and Modern Southeast Asian Art: From Rabindranath Tagore to Bagyi Aung Soe and Beyond YIN KER School of Art, Design & Media, Nanyang Technological University, [email protected] Follow this and additional works at: https://docs.lib.purdue.edu/artlas Part of the Art Education Commons, Art Practice Commons, Asian Art and Architecture Commons, Modern Art and Architecture Commons, Other History of Art, Architecture, and Archaeology Commons, Other International and Area Studies Commons, and the South and Southeast Asian Languages and Societies Commons Recommended Citation KER, YIN. "Śāntiniketan and Modern Southeast Asian Art: From Rabindranath Tagore to Bagyi Aung Soe and Beyond." Artl@s Bulletin 5, no. 2 (2016): Article 2. This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. This is an Open Access journal. This means that it uses a funding model that does not charge readers or their institutions for access. Readers may freely read, download, copy, distribute, print, search, or link to the full texts of articles. This journal is covered under the CC BY-NC-ND license. South-South Śāntiniketan and Modern Southeast Asian Art: From Rabindranath Tagore to Bagyi Aung Soe and Beyond Yin Ker * Nanyang Technological University Abstract Through the example of Bagyi Aung Soe, Myanmar’s leader of modern art in the twentieth century, this essay examines the potential of Śāntiniketan’s pentatonic pedagogical program embodying Rabindranath Tagore’s universalist and humanist vision of an autonomous modernity in revitalizing the prevailing unilateral and nation- centric narrative of modern Southeast Asian art. -

Study on Selected Male Writers' Handwritings Collected in The
Study on Selected Male Writers’ Handwritings Collected in The University of Yangon Library A Research Paper Submitted to the Myanmar Academy of Arts and Science By Min Min Htun MRes Assistant Lecturer Department of Library and Information Studies University of Yangon October, 2016 Study on Selected Male Writers’ Handwritings Collected in The University of Yangon Library by Daw Min Min Htun ABSTRACT The objective of this research is to maintain the selected handwritings of ten male writers who were born in the period between (1901 - 1939) collected in the University of Yangon Library. The paper has studied the ten male writers’ handwritings and their brief biography. The compilation of the facts and data for each individual is done chronologically. The research method used for this paper is mainly based on literature search method with a full observation. By studying this paper one can find out about the rare handwriting style, their achievements and other valuable information about the writers. Moreover, this research will help to scholars who are interested in studying in details about famous writers in Myanmar. Hopefully, it might be a part of efforts to collect and preserve the whole Myanmar writer’s handwriting which is essential in future for Myanmar writers. 1 Study on Selected Male Writers’ Handwritings Collected in The University of Yangon Library Introduction Each person has their own unique style of handwriting, whether it is everyday handwriting or their personal signature. The handwriting in a manuscript can provide considerable information about an individual manuscript, and how it relates to other manuscripts. There are many materials concerning with literature of writer’s original handwriting scripts in Myanmar libraries. -

Private Sector Development Activity Quarterly Report
PRIVATE SECTOR DEVELOPMENT ACTIVITY QUARTERLY REPORT QUARTER 3 FISCAL YEAR 2019 (APRIL 1 TO JUNE 30, 2019) ROBOLEAGUE COMPETITION JUNE 1, 2019 PHOTO CREDIT: PHANDEEYAR FOUNDATION DISCLAIMER Nathan Associates Inc. prepared this report for review by the United States Agency for International Development. The authors’ views expressed in this publication do not necessarily reflect the views of the United States Agency for International Development or the United States government. PRIVATE SECTOR DEVELOPMENT ACTIVITY QUARTERLY REPORT 3 FY2019 PRIVATE SECTOR DEVELOPMENT ACTIVITY QUARTERLY REPORT Fiscal Year 2019 Quarter 3: April 1, 2019 to June 30, 2019 Submitted To USAID/Burma Under Contract AID-482-C-15-00001 Submitted By Steve Parker Chief of Party August 15, 2019 DISCLAIMER Nathan Associates Inc. prepared this report for review by the United States Agency for International Development. The authors’ views expressed in this publication do not necessarily reflect the views of the United States Agency for International Development or the United States government. II Table of Contents Abbreviations ................................................................................................................................. v Program Overview ........................................................................................................................ 1 Program Description ................................................................................................................. 1 Q3 FY2019 Program Highlights .............................................................................................. -

China in Burma
CHINA IN BURMA : THE I NCREASING I NVESTMENT OF CHINESE MULTINATIONAL CORPORATIONS IN BURMA’S HYDROPOWER, OIL AND NATURAL GAS, AND MINING SECTORS UPDATED: September 2008 ACKNOWLEDGEMENTS EarthRights International would like to thank All Arakan Student & Youth Congress, Arakan Oil Watch, Burma Relief Center, Courier Research Associates, Images Asia E-Desk, Kachin Development Networking Group, Kachin Environmental Organization, Karen Rivers Watch, Karenni Development Research Group, Lahu National Developmen t Organization, Mon Youth Progressive Organization, Palaung Youth Network Group, Salween Watch Coalition, Shan Sapawa and Shwe Gas Movement, for providing invaluable research assistance and support for this report. Free reproduction rights with citation to the original. EarthRights International (ERI) is a non-government, non- profit organization that combines the power of the law and the power of people in defense of human rights and the environment, which we define as “earth rights.” We specialize in fact-finding, legal actions against perpetrators of earth rights abuses, training grassroots and community leaders, and advocacy campaigns. Through these strategies, ERI seeks to end earth rights abuses, to provide real solutions for real people, and t o promote and protect human rights and the environment in the communities where we work. Southeast Asia Office U.S. Office P.O. Box 123 1612 K Street NW, Suite 401 Chiang Mai University Washington, D.C. Chaing Mai, Thailand 20006 50202 Tel: 1-202-466-5188 Tel: 66-1-531-1256 Fax: 1-202-466-5189 -

A Study of How Myanmar Authors Take a Pen-Name
A Study of How Myanmar Authors Take a Pen-name Khin Thida Latt Abstract It is found what foreign authors write under a pseudonym is rare and they become famous for their real names. And, some also use a pen-name so that they may want to be secret themselves and with another name, they may want to create literature different from one they get used to writing. Nevertheless almost all Myanmar authors take a pen-name. It is very interesting for researchers even how began the practice Myanmar authors write under the pseudonym. The objective of this paper is to make researchers and librarians know how the Myanmar authors in the history of Myanmar literature used their interesting pen-name. This research covers (45) selected Myanmar authors take a pen-name. The method used in this paper is literature survey method. Key words: pseudonym; rare; real name; pen-name. Introduction Tetkatho Htin Gyi is the foremost author who wrote about pen-names in Myanmar literature. Saya Tetkatho Htin Gyi was the last chairman for Burma Research Society (1980), Director of Sarpay Beikman, National Literature Laureate for 1992, life time Achievement in Myanmar Literature by the Pakkoku U Ohn Pe literary prize laureate (Arts) (2003). He wrote pseudonym of Tetkatho Htin Gyi in the journal of Burma Writers Association, Vol.3. According to his friend‟s question how to get his pen-name, he explained about it and he was interested in pen-names. It is presented in this paper how the (45) writers took their pen-names differently. In the paper, the pen-names of (45) writers -

The Golden Rock at Kyaik-Hti-Yo
© 2008 SOAS Bulletin of Burma Research 1 THE GOLDEN ROCK AT KYAIK-HTI-YO Donald M. Stadtner The Golden Rock ranks with the Shwedagon and the Mahamuni as a solid member of Burma’s sacred triumvirate, yet its history is the most obscure. The hair relics of the Buddha believed to be inside the granite boulder are the objects of devotion, but the rock’s sanctity owes as much to its rich legacy. How this 611.45 ton granite boulder balancing on a cliff side in a remote mountain range came to achieve national veneration is testimony to not only the tenacious continuity of old legends but also their remarkable elasticity. If myths are to survive and flourish, then they must be nimble and able to change with new circumstances. The present modest and preliminary exploration sketches the major historical sources surrounding Kyaik-hti- yo and suggests how the Golden Rock grew to be one of Burma’s most sacred sites. Its history is plagued by gaps, but its general outline can be pieced together. The Kyaik-hti-yo tradition can be traced to an important fifteenth-century Mon myth centered on six hair relics the Buddha presented to six hermits. These unnamed recluses returned to their hermitages in locations between Rangoon and the Thaton area, but Kyaik-hti-yo was not among them. This basic Mon myth survived the loss of Pegu and Lower Burma to Burmese forces in the sixteenth century and provided a firm but fluid foundation on which many later myths in Lower Burma were constructed, often in unexpected ways. -
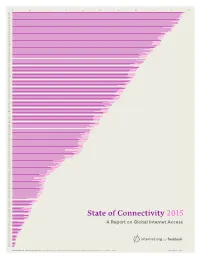
State of Connectivity SLB KHM COG MLI COM AFG a Report on Global Internet Access MOZ MWI TGO LBR BEN TZA CAF MDG GNB ZAR ETH TCD SLE MMR NER GIN SOM BDI TLS ERI
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ISL BMU NOR DNK AND LIE SWE LUX FRO NLD MCO FIN GBR QAT BHR JPN ARE USA CAN CHE DEU NZL BEL AUS KOR EST TWN ABW FRA SGP AUT SVK CZE IRL PRI KWT BHS BRB ESP HUN LVA LBN HKG CYM MLT CHL LTU SVN ISR RUS OMN NCL MAC CYP GUM BRN HRV MKD MYS GRL POL KNA TTO ARG PRT ATG SAU GRC DMA ITA URY MNE AZE BIH PYF ALB BLR BRA VEN MAR VCT BGR KAZ SYC ROM WBG SRB COL TUR LCA VIR DOM CRI CHN MDV ZAF GEO VNM MDA ARM TUN PAN MEX JOR UZB UKR KEN ECU PRY NGA FJI MUS JAM CPV PER SUR TON PHL IRN BOL BLZ GRD GUY THA BTN EGY CUB SLV FSM KGZ SYR SWZ MNG LKA SDN STP GTM YEM AGO WSM ZWE HND GHA GNQ VUT BWA DZA IND LBY UGA SEN NIC TJK ZMB IDN MHL SSD GMB NPL NAM CIV LAO PAK KIR TKM HTI IRQ CMR LSO DJI MRT RWA GAB BGD BFA PNG State of Connectivity SLB KHM COG MLI COM AFG A Report on Global Internet Access MOZ MWI TGO LBR BEN TZA CAF MDG GNB ZAR ETH TCD SLE MMR NER GIN SOM BDI TLS ERI PERCENTAGE OF POPULATION ONLINE (International Telecommunication Union, World Telecommunication/ICT Indicators Database, 2015) 2013 2014 Facebook released the inaugural State of Connectivity report1 last year, taking a close look at who was connected, who was not and why. -

The Journal of Burma Studies
The Journal of Burma Studies Volume 9 2004 Special Issue In Homage to U Pe Maung Tin Featuring Articles by: Anna Allott Denise Bernot Tilman Frasch Patricia Herbert Jacques Leider Alan Saw U U Tun Aung Chain The Journal of Burma Studies Volume 9 2004 President, Burma Studies Group Mary Callahan General Editor Catherine Raymond Center for Burma Studies Northern Illinois University Guest Editor Anna Allo� School of Oriental and African Studies University of London Production Editor Caroline Quinlan Center for Southeast Asian Studies Northern Illinois University Copy Editors/Proofreaders Liz Poppens Denius Christopher A. Miller Publications Assistants Beth Bjorneby Mishel Filisha With Special Assistance from U Win Pe U Saw Tun © 2004 Southeast Asia Publications The Center for Southeast Asian Studies Northern Illinois University DeKalb, Illinois 60115 USA ISSN # 1094-799X The Journal of Burma Studies is an annual scholarly journal jointly sponsored by the Burma Studies Group (Association for Asian Studies), the Center for Burma Studies (Northern Illinois University), and Northern Illinois University’s Center for Southeast Asian Studies. Articles are refereed by professional peers. For Submission Guidelines, please see our website: h�p://www.niu.edu/ cseas/seap/Submissions.htm or contact The Editor, Center for Southeast Asian Studies, Northern Illinois University, DeKalb, IL 60115. E-mail: [email protected] Subscriptions are $16 per volume delivered book rate (airmail add $10 per volume). Members of the Burma Studies Group receive the journal and two bulletins as part of their $30 annual membership. Send check or money order in U.S. dollars drawn on a U.S. bank made out to “Northern Illinois University” to Center for Burma Studies, Northern Illinois University, DeKalb, IL 60115. -

4 April 2021 1 4 April 21 Gnlm
EMPHASIZE PHYSICAL AND MENTAL WELL-BEING OF PEOPLE PAGE-8 (OPINION) Vol. VII, No. 353, 8th Waning of Tabaung 1382 ME www.gnlm.com.mm Sunday, 4 April 2021 Tatmadaw will strive for a genuine, disciplined and concrete democracy: Senior General Chairman of the State Administration Council Commander-in-Chief of Defence Services Senior General Min Aung Hlaing meets officers, other ranks and families of Meiktila Station yesterday. CHAIRMAN of the State Ad- election frauds, and instead, there The person one voted would elect ministration Council Command- were even attempts to convene the leaders of the State on his er-in-Chief of Defence Services the third Hluttaw and to take behalf, in the respective Hluttaws. Senior General Min Aung Hlaing over the respective branches of So, the elected person must be a The country’s democracy is just yesterday afternoon separate- State power by force. Hence, the true representative of the people. ly met officers, other ranks and Tatmadaw had to declare the During the election, Tatmadaw nascent. Therefore, some power- families of Meiktila Station. state of emergency and tempo- members ardently cast votes in Present at the meeting to- rarily shoulder the duties of the accord with the rules and under ful countries and organizations gether with the Senior General State transferred to it by the act- the systematic programmes ar- were members of the Council ing president. In every place he ranged by the Tatmadaw. attempted to import democracy General Maung Maung Kyaw, visited during the post-election Election is the essence of de- they wanted under various titles Lt-Gen Moe Myint Tun, Joint Sec- period, the Senior General spoke mocracy. -

The Journal of Burma Studies
The Journal of Burma Studies Volume 9 2004 Special Issue In Homage to U Pe Maung Tin Featuring Articles by: Anna Allott Denise Bernot Tilman Frasch Patricia Herbert Jacques Leider Alan Saw U U Tun Aung Chain The Journal of Burma Studies Volume 9 2004 President, Burma Studies Group Mary Callahan General Editor Catherine Raymond Center for Burma Studies Northern Illinois University Guest Editor Anna Allo� School of Oriental and African Studies University of London Production Editor Caroline Quinlan Center for Southeast Asian Studies Northern Illinois University Copy Editors/Proofreaders Liz Poppens Denius Christopher A. Miller Publications Assistants Beth Bjorneby Mishel Filisha With Special Assistance from U Win Pe U Saw Tun © 2004 Southeast Asia Publications The Center for Southeast Asian Studies Northern Illinois University DeKalb, Illinois 60115 USA ISSN # 1094-799X The Journal of Burma Studies is an annual scholarly journal jointly sponsored by the Burma Studies Group (Association for Asian Studies), the Center for Burma Studies (Northern Illinois University), and Northern Illinois University’s Center for Southeast Asian Studies. Articles are refereed by professional peers. For Submission Guidelines, please see our website: h�p://www.niu.edu/ cseas/seap/Submissions.htm or contact The Editor, Center for Southeast Asian Studies, Northern Illinois University, DeKalb, IL 60115. E-mail: [email protected] Subscriptions are $16 per volume delivered book rate (airmail add $10 per volume). Members of the Burma Studies Group receive the journal and two bulletins as part of their $30 annual membership. Send check or money order in U.S. dollars drawn on a U.S. bank made out to “Northern Illinois University” to Center for Burma Studies, Northern Illinois University, DeKalb, IL 60115.