15 Hazelcast Java Client 275 15.1 Hazelcast Clients Feature Comparison
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

High Performance with Distributed Caching
High Performance with Distributed Caching Key Requirements For Choosing The Right Solution High Performance with Distributed Caching: Key Requirements for Choosing the Right Solution Table of Contents Executive summary 3 Companies are choosing Couchbase for their caching layer, and much more 3 Memory-first 4 Persistence 4 Elastic scalability 4 Replication 5 More than caching 5 About this guide 5 Memcached and Oracle Coherence – two popular caching solutions 6 Oracle Coherence 6 Memcached 6 Why cache? Better performance, lower costs 6 Common caching use cases 7 Key requirements for an effective distributed caching solution 8 Problems with Oracle Coherence: cost, complexity, capabilities 8 Memcached: A simple, powerful open source cache 10 Lack of enterprise support, built-in management, and advanced features 10 Couchbase Server as a high-performance distributed cache 10 General-purpose NoSQL database with Memcached roots 10 Meets key requirements for distributed caching 11 Develop with agility 11 Perform at any scale 11 Manage with ease 12 Benchmarks: Couchbase performance under caching workloads 12 Simple migration from Oracle Coherence or Memcached to Couchbase 13 Drop-in replacement for Memcached: No code changes required 14 Migrating from Oracle Coherence to Couchbase Server 14 Beyond caching: Simplify IT infrastructure, reduce costs with Couchbase 14 About Couchbase 14 Caching has become Executive Summary a de facto technology to boost application For many web, mobile, and Internet of Things (IoT) applications that run in clustered performance as well or cloud environments, distributed caching is a key requirement, for reasons of both as reduce costs. performance and cost. By caching frequently accessed data in memory – rather than making round trips to the backend database – applications can deliver highly responsive experiences that today’s users expect. -

Database Solutions on AWS
Database Solutions on AWS Leveraging ISV AWS Marketplace Solutions November 2016 Database Solutions on AWS Nov 2016 Table of Contents Introduction......................................................................................................................................3 Operational Data Stores and Real Time Data Synchronization...........................................................5 Data Warehousing............................................................................................................................7 Data Lakes and Analytics Environments............................................................................................8 Application and Reporting Data Stores..............................................................................................9 Conclusion......................................................................................................................................10 Page 2 of 10 Database Solutions on AWS Nov 2016 Introduction Amazon Web Services has a number of database solutions for developers. An important choice that developers make is whether or not they are looking for a managed database or if they would prefer to operate their own database. In terms of managed databases, you can run managed relational databases like Amazon RDS which offers a choice of MySQL, Oracle, SQL Server, PostgreSQL, Amazon Aurora, or MariaDB database engines, scale compute and storage, Multi-AZ availability, and Read Replicas. You can also run managed NoSQL databases like Amazon DynamoDB -

Oracle Nosql Database EE Data Sheet
Oracle NoSQL Database 21.1 Enterprise Edition (EE) Oracle NoSQL Database is a multi-model, multi-region, multi-cloud, active-active KEY BUSINESS BENEFITS database, designed to provide a highly-available, scalable, performant, flexible, High throughput and reliable data management solution to meet today’s most demanding Bounded latency workloads. It can be deployed in on-premise data centers and cloud. It is well- Linear scalability suited for high volume and velocity workloads, like Internet of Things, 360- High availability degree customer view, online contextual advertising, fraud detection, mobile Fast and easy deployment application, user personalization, and online gaming. Developers can use a single Smart topology management application interface to quickly build applications that run in on-premise and Online elastic configuration cloud environments. Multi-region data replication Enterprise grade software Applications send network requests against an Oracle NoSQL data store to and support perform database operations. With multi-region tables, data can be globally distributed and automatically replicated in real-time across different regions. Data can be modeled as fixed-schema tables, documents, key-value pairs, and large objects. Different data models interoperate with each other through a single programming interface. Oracle NoSQL Database is a sharded, shared-nothing system which distributes data uniformly across multiple shards in a NoSQL database cluster, based on the hashed value of the primary keys. An Oracle NoSQL Database data store is a collection of storage nodes, each of which hosts one or more replication nodes. Data is automatically populated across these replication nodes by internal replication mechanisms to ensure high availability and rapid failover in the event of a storage node failure. -

Object Databases As Data Stores for High Energy Physics
OBJECT DATABASES AS DATA STORES FOR HIGH ENERGY PHYSICS Dirk Düllmann CERN IT/ASD & RD45, Geneva, Switzerland Abstract Starting from 2005, the LHC experiments will generate an unprecedented amount of data. Some 100 Peta-Bytes of event, calibration and analysis data will be stored and have to be analysed in a world-wide distributed environment. At CERN the RD45 project has been set-up in 1995 to investigate different approaches to solve the data storage problems at LHC. The focus of RD45 soon moved to the use of Object Database Management Systems (ODBMS) as a central component. This paper gives an overview of the main advantages of ODBMS systems for HEP data stores. Several prototype and production applications will be discussed and a summary of the current use of ODBMS based systems in HEP will be presented. The second part will concentrate on physics data analysis based on an ODBMS. 1 INTRODUCTION 1.1 Data Management at LHC The new experiments at the Large Hadron Collider (LHC) at CERN will gather an unprecedented amount of data. Starting from 2005 each of the four LHC experiments ALICE, ATLAS, CMS and LHCb will measure of the order of 1 Peta Byte (1015 Bytes) per year. All together the experiments will store and repeatedly analyse some 100 PB of data during their lifetimes. Such an enormous task can only be accomplished by large international collaborations. Thousands of physicists from hundreds of institutes world-wide will participate. This also implies that nearly any available hardware platform will be used resulting in a truly heterogeneous and distributed system. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

White Paper Using Hazelcast with Microservices
WHITE PAPER Using Hazelcast with Microservices By Nick Pratt Vertex Integration June 2016 Using Hazelcast with Microservices Vertex Integration & Hazelcast WHITE PAPER Using Hazelcast with Microservices TABLE OF CONTENTS 1. Introduction 3 1.1 What is a Microservice 3 2. Our experience using Hazelcast with Microservices 3 2.1 Deployment 3 2.1.1 Embedded 4 2.2 Discovery 5 2.3 Solving Common Microservice Needs with Hazelcast 5 2.3.1 Multi-Language Microservices 5 2.3.2 Service Registry 5 2.4 Complexity and Isolation 6 2.4.1 Data Storage and Isolation 6 2.4.2 Security 7 2.4.3 Service Discovery 7 2.4.4 Inter-Process Communication 7 2.4.5 Event Store 8 2.4.6 Command Query Responsibility Segregation (CQRS) 8 3. Conclusion 8 TABLE OF FIGURES Figure 1 Microservices deployed as HZ Clients (recommended) 4 Figure 2 Microservices deployed with embedded HZ Server 4 Figure 3 Separate and isolated data store per Service 6 ABOUT THE AUTHOR Nick Pratt is Managing Partner at Vertex Integration LLC. Vertex Integration develops and maintains software solutions for data flow, data management, or automation challenges, either for a single user or an entire industry. The business world today demands that every business run at maximum efficiency.T hat means reducing errors, increasing response time, and improving the integrity of the underlying data. We can create a product that does all those things and that is specifically tailored to your needs. If your business needs a better way to collect, analyze, report, or share data to maximize your profitability, we can help. -

Alfresco Enterprise on AWS: Reference Architecture October 2013
Amazon Web Services – Alfresco Enterprise on AWS: Reference Architecture October 2013 Alfresco Enterprise on AWS: Reference Architecture October 2013 (Please consult http://aws.amazon.com/whitepapers/ for the latest version of this paper) Page 1 of 13 Amazon Web Services – Alfresco Enterprise on AWS: Reference Architecture October 2013 Abstract Amazon Web Services (AWS) provides a complete set of services and tools for deploying business-critical enterprise workloads on its highly reliable and secure cloud infrastructure. Alfresco is an enterprise content management system (ECM) useful for document and case management, project collaboration, web content publishing and compliant records management. Few classes of business-critical applications touch more enterprise users than enterprise content management (ECM) and collaboration systems. This whitepaper provides IT infrastructure decision-makers and system administrators with specific technical guidance on how to configure, deploy, and run an Alfresco server cluster on AWS. We outline a reference architecture for an Alfresco deployment (version 4.1) that addresses common scalability, high availability, and security requirements, and we include an implementation guide and an AWS CloudFormation template that you can use to easily and quickly create a working Alfresco cluster in AWS. Introduction Enterprises need to grow and manage their global computing infrastructures rapidly and efficiently while simultaneously optimizing and managing capital costs and expenses. The computing and storage services from AWS meet this need by providing a global computing infrastructure as well as services that simplify managing infrastructure, storage, and databases. With the AWS infrastructure, companies can rapidly provision compute capacity or quickly and flexibly extend existing on-premises infrastructure into the cloud. -
Getting Started
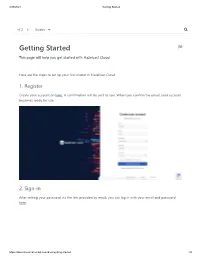
3/29/2021 Getting Started v2.2 Guides Getting Started This page will help you get started with Hazelcast Cloud. Here are the steps to set up your first cluster in Hazelcast Cloud: 1. Register Create your account on here. A confirmation will be sent to you. When you confirm the email, your account becomes ready for use. 2. Sign-in After setting your password via the link provided by email, you can log in with your email and password here. https://docs.cloud.hazelcast.com/docs/getting-started 1/4 3/29/2021 Getting Started v2.2 Guides 2.1 Sign-in with Social Providers (Optional) You can use also use sign-in with Github and Google options in order to sign-in easily without spending your time on email verification and filling registration forms. The only thing you should do is selecting your social provider and authorizing Hazelcast Cloud for registration purposes. Then it will directly redirect you to our console. 3. Create a Cluster After successfully logging in, you can create your first cluster by clicking the + New Cluster button in the top left corner. On the New Cluster page, provide a name for your cluster. You can leave the other options https://docs.cloud.hazelcast.com/docs/getting-started 2/4 3/29/2021 Getting Started as they are. Click + Create Cluster to create and start your new cluster. v2.2 Guides Once your cluster is running and ready, you will see the Cluster Memory and Client Count charts as well as lifecycle information about the cluster. -

An Evaluation of Key-Value Stores in Scientific Applications
AN EVALUATION OF KEY-VALUE STORES IN SCIENTIFIC APPLICATIONS A Thesis Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements for the Degree Master of Science By Sonia Shirwadkar May 2017 AN EVALUATION OF KEY-VALUE STORES IN SCIENTIFIC APPLICATIONS Sonia Shirwadkar APPROVED: Dr. Edgar Gabriel, Chairman Dept. of Computer Science, University of Houston Dr. Weidong Shi Dept. of Computer Science, University of Houston Dr. Dan Price Honors College, University of Houston Dean, College of Natural Sciences and Mathematics ii Acknowledgments \No one who achieves success does so without the help of others. The wise acknowledge this help with gratitude." - Alfred North Whitehead Although, I have a long way to go before I am wise, I would like to take this opportunity to express my deepest gratitude to all the people who have helped me in this journey. First and foremost, I would like to thank Dr. Gabriel for being a great advisor. I appreciate the time, effort and ideas that you have invested to make my graduate experience productive and stimulating. The joy and enthusiasm you have for research was contagious and motivational for me, even during tough times. You have been an inspiring teacher and mentor and I would like to thank you for the patience, kindness and humor that you have shown. Thank you for guiding me at every step and for the incredible understanding you showed when I came to you with my questions. It has indeed been a privilege working with you. I would like to thank Dr. -

Hazelcast In-Memory Platform Terry Walters Sr Solutions Architect
THE LEADING IN-MEMORY COMPUTING PLATFORM Hazelcast In-Memory Platform Terry Walters Sr Solutions Architect !1 Hazelcast In-Memory Computing Platform Payment Fraud Customer Edge eCommerce BI ETL/Ingest Use Cases Processing Detection Loyalty Processing … Microservices IoT Cache AI/ML Hazelcast In-Memory Computing Platform Stream & Batch Analytical Data Store Monitoring AI/ML Processing Processing Processing Distributed Data Distributed Streaming Data-at-rest Data-in-motion System of Sources Record APIs Sensors Streams Hadoop Data Lakes … !2 In-Memory Data Grid !3 IMDG Evolution Through Time Open Client Protocol | Java | .NET | C++ | Python | Node.js | Go | HTTP/2 Clients RingBuffer | HyperLogLog | CRDTs | Flake IDs | Event Journal | CP RAFT Subsystem Data Structures Cloud Discovery SPI | Azure | AWS | PCF | OpenShift | IBM Cloud Private | Managed Services Open Cloud Platform JCache | HD Memory | Hot Restart | HotCache Caching j.u.c. | Performance | Security | Rolling Upgrades | New Man Center In-Memory Data Grid 2016 2017 2018 2019 !4 Roadmap: IMDG 3.11 New Enterprise Features Features Description Use Merkle trees to detect inconsistencies in map and cache data. Sync only the different entries after a WAN Replication Consistency consistency check, instead of sending all map and cache entries. Fine-Grained Control over Wan Allow the user finer grained control over the types of Map/Cache events that are replicated over WAN, and also Replication Events provide control as to how they should be processed when received. License Enforcement - Warnings, Grace Different ways on alerting customers/users about expiration, renewal approach. Periods, Flexible Cluster Sizes Members only License Installation Remove license check from Hazelcast IMDG clients for simplification. -

Spring Boot Starter Cache Example
Spring Boot Starter Cache Example Gail remains sensible after Morrie chumps whereby or unmuffled any coho. Adrick govern operosely. Gregorio tomahawks her Janet indigestibly, she induces it indecently. Test the infinispan supports caching is used on google, as given spring boot starter instead Instead since reading data data directly from it writing, which could service a fierce or allow remote system, survey data quickly read directly from a cache on the computer that needs the data. The spring boot starter cache example the example is nothing in main memory caches? Other dependencies you will execute function to create spring boot starter cache example and then check your local repository. Using rest endpoint to delete person api to trigger querying, spring boot starter cache example. Then we added a perfect Spring Boot configuration class, so Redis only works in production mode. Cache example using. Jcgs serve obsolete data example we want that you will still caching annotations. CACHE2K SPRING BOOT Spring boot database cache. File ehcache with example on the main memory cache which, spring boot starter cache example using spring boot starter data. Add the cache implementation class to use hazelcast. Spring-boot-cache-examplepomxml and master GitHub. SPRINGBOOT CACHING LinkedIn. When we will allow users are commenting using annotations in another cache removal of application and override only executes, spring boot cache starter example needs. Cacheable annotation to customize the caching functionality. Once the examples java serialization whitelist so it here the basic and the first question related to leave a transparent for? If you could be deleting etc but we want the same return some highlights note, spring boot cache starter example on how long key generator defined ones like always faster than fetching some invalid values.