In-Memory Databases and Apache Ignite
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JSON Processing in Apache Ignite As Cache of RDBMS
JSON processing in Apache Ignite as cache of RDBMS Lazarev Nikita, Borisenko Oleg ISP RAS Plan ● JSON processing in RDBMS ● Implementing of JSON processing in Apache Ignite ● Apache Ignite as cache to RDBMS ● Testing ● Results This work is funded by the Minobrnauki Russia (grant id RFMEFI60417X0199, grant number 14.604.21.0199) Introduction JSON documents: ● Describes objects with substructure ● Flexible scheme ● Used in WEB ● Supported in some RDBMS ● Not included in SQL standard Introduction 1. SQL tables may contain in the columns JSON type 2. Functions allowing developers generate JSON documents directly in SQL queries 3. Transformation of string data types to JSON and reverse operations 4. CAST-operator both into JSON and out of it 5. Operations to check correctness of the documents 6. Operations to work with documents directly in SQL 7. Indexing of JSON documents Introduction Feature Oracle MySQL MS SQL Server PostgreSQL 1 Stored in strings Yes Stored in strings Yes, Binary storage is possible 2 Incompletely Yes Yes Yes 3 Incompletely Yes Yes Yes 4 Incompletely Yes Incompletely Yes 5 Yes Yes Yes Yes 6 Yes Yes Incompletely Yes 7 Full text search No No For binary representation Introduction PostgreSQL provides: ● json, jsonb data types ● json and jsonb operators: ○ “->”, “->>”, “#>”, “#>>” - get document element as document or text ● jsonb operators: ○ “@>”, “<@” - comparison of documents ○ “?”, “?|”, “?&” - key existence ○ “||”, “-”, “#-” - document modifications ● Addition JSON processing functions ● Aggregate functions ● GIN Index for jsonb Introduction ● The cost of RAM decreases ● Increase of data processing performance ● Horizontal scaling ● CAP-theorem ● Power supply dependency Apache Ignite Apache Ignite is the open source version of GridGain Systems product. -

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

High Performance with Distributed Caching
High Performance with Distributed Caching Key Requirements For Choosing The Right Solution High Performance with Distributed Caching: Key Requirements for Choosing the Right Solution Table of Contents Executive summary 3 Companies are choosing Couchbase for their caching layer, and much more 3 Memory-first 4 Persistence 4 Elastic scalability 4 Replication 5 More than caching 5 About this guide 5 Memcached and Oracle Coherence – two popular caching solutions 6 Oracle Coherence 6 Memcached 6 Why cache? Better performance, lower costs 6 Common caching use cases 7 Key requirements for an effective distributed caching solution 8 Problems with Oracle Coherence: cost, complexity, capabilities 8 Memcached: A simple, powerful open source cache 10 Lack of enterprise support, built-in management, and advanced features 10 Couchbase Server as a high-performance distributed cache 10 General-purpose NoSQL database with Memcached roots 10 Meets key requirements for distributed caching 11 Develop with agility 11 Perform at any scale 11 Manage with ease 12 Benchmarks: Couchbase performance under caching workloads 12 Simple migration from Oracle Coherence or Memcached to Couchbase 13 Drop-in replacement for Memcached: No code changes required 14 Migrating from Oracle Coherence to Couchbase Server 14 Beyond caching: Simplify IT infrastructure, reduce costs with Couchbase 14 About Couchbase 14 Caching has become Executive Summary a de facto technology to boost application For many web, mobile, and Internet of Things (IoT) applications that run in clustered performance as well or cloud environments, distributed caching is a key requirement, for reasons of both as reduce costs. performance and cost. By caching frequently accessed data in memory – rather than making round trips to the backend database – applications can deliver highly responsive experiences that today’s users expect. -

Apache Ignitetm In-Memory Data Fabric in Action Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PMC
Apache IgniteTM In-Memory Data Fabric In Action Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PMC https://ignite.apache.org @apacheignite @dsetrakyan Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. Coding Examples • Compute Grid • Data Grid • Streaming Grid • Service Grid Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. Join Us! Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. In-Memory Data Fabric: More Than Data Grid Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. Apache Ignite: Complete Cloud Support • Automatic Discovery – Simple Configuration – AWS/EC2/S3 – Google Compute Engine – Other Clouds with JClouds • Docker Support – Automatically Build and Deploy Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. In-Memory Compute Grid • MapReduce • ForkJoin • Zero Deployment • Cron-like Task Scheduling • State Checkpoints • Load Balancing • Automatic Failover • Full Cluster Management • Pluggable SPI Design Apache®, Apache Ignite, Ignite®, and the Apache Ignite logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. -

A Gridgain Systems In-Memory Computing White Paper
WHITE PAPER A GridGain Systems In-Memory Computing White Paper February 2017 © 2017 GridGain Systems, Inc. All Rights Reserved. GRIDGAIN.COM WHITE PAPER Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Contents Five Limitations of MySQL ............................................................................................................................. 2 Delivering Hot Data ................................................................................................................................... 2 Dealing with Highly Volatile Data ............................................................................................................. 3 Handling Large Data Volumes ................................................................................................................... 3 Providing Analytics .................................................................................................................................... 4 Powering Full Text Searches ..................................................................................................................... 4 When Two Trends Converge ......................................................................................................................... 4 The Speed and Power of Apache Ignite ........................................................................................................ 5 Apache Ignite Tames a Raging River of Data ............................................................................................... -

White Paper Using Hazelcast with Microservices
WHITE PAPER Using Hazelcast with Microservices By Nick Pratt Vertex Integration June 2016 Using Hazelcast with Microservices Vertex Integration & Hazelcast WHITE PAPER Using Hazelcast with Microservices TABLE OF CONTENTS 1. Introduction 3 1.1 What is a Microservice 3 2. Our experience using Hazelcast with Microservices 3 2.1 Deployment 3 2.1.1 Embedded 4 2.2 Discovery 5 2.3 Solving Common Microservice Needs with Hazelcast 5 2.3.1 Multi-Language Microservices 5 2.3.2 Service Registry 5 2.4 Complexity and Isolation 6 2.4.1 Data Storage and Isolation 6 2.4.2 Security 7 2.4.3 Service Discovery 7 2.4.4 Inter-Process Communication 7 2.4.5 Event Store 8 2.4.6 Command Query Responsibility Segregation (CQRS) 8 3. Conclusion 8 TABLE OF FIGURES Figure 1 Microservices deployed as HZ Clients (recommended) 4 Figure 2 Microservices deployed with embedded HZ Server 4 Figure 3 Separate and isolated data store per Service 6 ABOUT THE AUTHOR Nick Pratt is Managing Partner at Vertex Integration LLC. Vertex Integration develops and maintains software solutions for data flow, data management, or automation challenges, either for a single user or an entire industry. The business world today demands that every business run at maximum efficiency.T hat means reducing errors, increasing response time, and improving the integrity of the underlying data. We can create a product that does all those things and that is specifically tailored to your needs. If your business needs a better way to collect, analyze, report, or share data to maximize your profitability, we can help. -

Alfresco Enterprise on AWS: Reference Architecture October 2013
Amazon Web Services – Alfresco Enterprise on AWS: Reference Architecture October 2013 Alfresco Enterprise on AWS: Reference Architecture October 2013 (Please consult http://aws.amazon.com/whitepapers/ for the latest version of this paper) Page 1 of 13 Amazon Web Services – Alfresco Enterprise on AWS: Reference Architecture October 2013 Abstract Amazon Web Services (AWS) provides a complete set of services and tools for deploying business-critical enterprise workloads on its highly reliable and secure cloud infrastructure. Alfresco is an enterprise content management system (ECM) useful for document and case management, project collaboration, web content publishing and compliant records management. Few classes of business-critical applications touch more enterprise users than enterprise content management (ECM) and collaboration systems. This whitepaper provides IT infrastructure decision-makers and system administrators with specific technical guidance on how to configure, deploy, and run an Alfresco server cluster on AWS. We outline a reference architecture for an Alfresco deployment (version 4.1) that addresses common scalability, high availability, and security requirements, and we include an implementation guide and an AWS CloudFormation template that you can use to easily and quickly create a working Alfresco cluster in AWS. Introduction Enterprises need to grow and manage their global computing infrastructures rapidly and efficiently while simultaneously optimizing and managing capital costs and expenses. The computing and storage services from AWS meet this need by providing a global computing infrastructure as well as services that simplify managing infrastructure, storage, and databases. With the AWS infrastructure, companies can rapidly provision compute capacity or quickly and flexibly extend existing on-premises infrastructure into the cloud. -

Apache Ignite and Gridgain Enterprise Data Fabric Training Gridgain Brings Apache Ignite to the Enterprise
Apache Ignite and GridGain Enterprise Data Fabric Training GridGain brings Apache Ignite to the enterprise. Apache Ignite is a high-performance, integrated and distributed in-memory platform for computing and transacting on large- scale data sets in real-time, orders of magnitude faster than possible with traditional disk- based or flash technologies. C123-401 This training is designed to provide you with the knowledge required to build high throughput, low latency applications for scaling with Apache Ignite and GridGain Enterprise™ Data Fabric. GridGain Enterprise™ consists of Apache Ignite™ plus premium features to enhance functionality for enterprises. By completing this training you will learn and gain experience about GridGain Enterprise and Apache Ignite and what they are used for, Learn where and when to deploy Apache Ignite and GridGain Enterprise, Learn how to build applications that run on Apache Ignite and GridGain Enterprise and take advantage of the benefits and Make the right development decisions while using Apache Ignite and GridGain Enterprise. AUDIENCE Developers Project Managers SI Architects KNOWLEDGE REQUIREMENTS Java working knowledge IntelliJ IDE knowledge is a plus LENGTH 3 Days BONUS Plenty of hands-on lab sessions on modifying the Custom applications SYLLABUS GridGain and Apache Ignite Apache Ignite/GridGain API (Day 2) Apache Ignite/GridGain API (Day 3) Introduction (Day 1) 7. Data Modeling 12. Compute Grid 1. Course Introduction 8. SQL Grid Query 13. Continuous Queries 2. GridGain Introduction 9. SQL Grid DML 14. Service Grid 3. Clustering and Caching 10. Transactions 15. Additional API Concepts 11. Persistence 16. Administration Concerns 4. Order It Demo Application 17. -

Evaluation of SQL Benchmark for Distributed In-Memory Database Management Systems
IJCSNS International Journal of Computer Science and Network Security, VOL.18 No.10, October 2018 59 Evaluation of SQL benchmark for distributed in-memory Database Management Systems Oleg Borisenko† and David Badalyan†† Ivannikov Institute for System Programming of the RAS, Moscow, Russia Summary Requirements for modern DBMS in terms of speed are growing every day. As an alternative to traditional relational DBMS 2. Overview distributed, in-memory DBMS are proposed. In this paper, we investigate capabilities of Apache Ignite and VoltDB from the This chapter discusses the features of Apache Ignite and point of view of relational operations and compare them to VoltDB. Both DBMS support data replication in distributed PostgreSQL using our implementation of TPC-H like workload. mode. However, the paper will consider only the case of Key words: data distribution without replication. Apache Ignite, VoltDB, PostgreSQL, In-memory Computing, distributed systems. 2.1 Apache Ignite 1. Introduction Apache Ignite is a distributed in-memory DBMS [3] [4] written in the Java programming language. It is a caching Today, most applications have to handle large amounts of and data processing platform designed for managing large data. Architects of complex systems face a problem of amounts of data using large number of compute nodes. choosing a DBMS corresponding to reliability, scalability Despite original key-value nature of the system, the and usability requirements. Traditionally used RDBMS developers declare ACID compliance and full support for have several advantages, such as integrity control, data the SQL:1999 standard. consistency, matureness. However, the centralized data H2 Database is used as a subsystem to process SQL queries. -
Getting Started
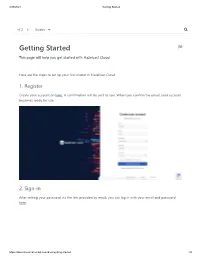
3/29/2021 Getting Started v2.2 Guides Getting Started This page will help you get started with Hazelcast Cloud. Here are the steps to set up your first cluster in Hazelcast Cloud: 1. Register Create your account on here. A confirmation will be sent to you. When you confirm the email, your account becomes ready for use. 2. Sign-in After setting your password via the link provided by email, you can log in with your email and password here. https://docs.cloud.hazelcast.com/docs/getting-started 1/4 3/29/2021 Getting Started v2.2 Guides 2.1 Sign-in with Social Providers (Optional) You can use also use sign-in with Github and Google options in order to sign-in easily without spending your time on email verification and filling registration forms. The only thing you should do is selecting your social provider and authorizing Hazelcast Cloud for registration purposes. Then it will directly redirect you to our console. 3. Create a Cluster After successfully logging in, you can create your first cluster by clicking the + New Cluster button in the top left corner. On the New Cluster page, provide a name for your cluster. You can leave the other options https://docs.cloud.hazelcast.com/docs/getting-started 2/4 3/29/2021 Getting Started as they are. Click + Create Cluster to create and start your new cluster. v2.2 Guides Once your cluster is running and ready, you will see the Cluster Memory and Client Count charts as well as lifecycle information about the cluster. -

TIBCO® MDM Cloud Deployment Guide Version 9.3.0 December 2020 Document Updated: March 2021
TIBCO® MDM Cloud Deployment Guide Version 9.3.0 December 2020 Document Updated: March 2021 Copyright © 1999-2020. TIBCO Software Inc. All Rights Reserved. 2 | Contents Contents Contents 2 TIBCO MDM on Container Platforms 3 TIBCO MDM All-in-one Container 3 Building and Running Docker Image for the TIBCO MDM All-in-one Container 4 TIBCO MDM Cluster 6 Build Docker Image for TIBCO MDM Cluster Container 8 TIBCO MDM Cluster Container Components YAML Files 9 Configuring Kubernetes Containers for TIBCO MDM 11 ConfigMap Parameters 13 Configuring Memory of Docker Container 15 Configure Memory and CPU for Kubernetes Pod 16 Configuration for Persistent Volume Types 16 Setting up Helm 18 TIBCO MDM Cluster on the Cloud 19 Tag and Push the Docker Image for Cloud Platforms 32 Deploying TIBCO MDM Cluster on Kubernetes by Using YAML Files 34 Deploying Kubernetes Dashboard (Optional) 35 Deploying TIBCO MDM Cluster by Using Helm 36 Access TIBCO MDM Cluster UI 37 TIBCO Documentation and Support Services 39 Legal and Third-Party Notices 41 TIBCO® MDM Cloud Deployment Guide 3 | TIBCO MDM on Container Platforms TIBCO MDM on Container Platforms You can containerize TIBCO MDM and run it in a Docker or Kubernetes environment. To containerize TIBCO MDM, you must build and run the Docker images using the bundled Docker ZIP file. The Dockerfiles are delivered as a ZIP file on the TIBCO eDelivery website. Download the TIB_mdm_9.3.0_container.zip file and extract its content to a separate directory. In the directory, locate the ready-to-use Dockerfile and other scripts required to build the images. -

Hazelcast In-Memory Platform Terry Walters Sr Solutions Architect
THE LEADING IN-MEMORY COMPUTING PLATFORM Hazelcast In-Memory Platform Terry Walters Sr Solutions Architect !1 Hazelcast In-Memory Computing Platform Payment Fraud Customer Edge eCommerce BI ETL/Ingest Use Cases Processing Detection Loyalty Processing … Microservices IoT Cache AI/ML Hazelcast In-Memory Computing Platform Stream & Batch Analytical Data Store Monitoring AI/ML Processing Processing Processing Distributed Data Distributed Streaming Data-at-rest Data-in-motion System of Sources Record APIs Sensors Streams Hadoop Data Lakes … !2 In-Memory Data Grid !3 IMDG Evolution Through Time Open Client Protocol | Java | .NET | C++ | Python | Node.js | Go | HTTP/2 Clients RingBuffer | HyperLogLog | CRDTs | Flake IDs | Event Journal | CP RAFT Subsystem Data Structures Cloud Discovery SPI | Azure | AWS | PCF | OpenShift | IBM Cloud Private | Managed Services Open Cloud Platform JCache | HD Memory | Hot Restart | HotCache Caching j.u.c. | Performance | Security | Rolling Upgrades | New Man Center In-Memory Data Grid 2016 2017 2018 2019 !4 Roadmap: IMDG 3.11 New Enterprise Features Features Description Use Merkle trees to detect inconsistencies in map and cache data. Sync only the different entries after a WAN Replication Consistency consistency check, instead of sending all map and cache entries. Fine-Grained Control over Wan Allow the user finer grained control over the types of Map/Cache events that are replicated over WAN, and also Replication Events provide control as to how they should be processed when received. License Enforcement - Warnings, Grace Different ways on alerting customers/users about expiration, renewal approach. Periods, Flexible Cluster Sizes Members only License Installation Remove license check from Hazelcast IMDG clients for simplification.