Podgen Documentation Release 1.1.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Architecture of the World Wide Web, First Edition Editor's Draft 14 October 2004
Architecture of the World Wide Web, First Edition Editor's Draft 14 October 2004 This version: http://www.w3.org/2001/tag/2004/webarch-20041014/ Latest editor's draft: http://www.w3.org/2001/tag/webarch/ Previous version: http://www.w3.org/2001/tag/2004/webarch-20040928/ Latest TR version: http://www.w3.org/TR/webarch/ Editors: Ian Jacobs, W3C Norman Walsh, Sun Microsystems, Inc. Authors: See acknowledgments (§8, pg. 42). Copyright © 2002-2004 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements. Abstract The World Wide Web is an information space of interrelated resources. This information space is the basis of, and is shared by, a number of information systems. In each of these systems, people and software retrieve, create, display, analyze, relate, and reason about resources. The World Wide Web uses relatively simple technologies with sufficient scalability, efficiency and utility that they have resulted in a remarkable information space of interrelated resources, growing across languages, cultures, and media. In an effort to preserve these properties of the information space as the technologies evolve, this architecture document discusses the core design components of the Web. They are identification of resources, representation of resource state, and the protocols that support the interaction between agents and resources in the space. We relate core design components, constraints, and good practices to the principles and properties they support. Status of this document This section describes the status of this document at the time of its publication. -
Samsung Podcasts RSS Spec 060921
Samsung Podcasts RSS Spec June 2021 SAMSUNG C&S SAMSUNG CONFIDENTIAL Introduction The purpose of this document is to provide technical guidelines to podcasters for optimal exposure of their RSS feeds on Samsung Podcasts. Notes • Submitting feeds to Samsung Podcasts will not prevent submission to other platforms. • Samsung Podcasts will not re-cache or re-host audio content. • These guidelines are meant to reflect requirements used by other standard podcast platforms. • Some requirements are meant to support future V2 features, marked in red. Samsung Proprietary and Confidential 2 RSS Feed Requirements Samsung Proprietary and Confidential 3 Feed Requirements: Podcast “Podcast” is defined as an ordered collection of episodes. A podcast must: • Be described by a valid RSS feed that conforms to RSS 2.0 specifications • Be freely reachable, not requiring login, token, or similar information • Be uniquely defined by its <link> field (Samsung Podcasts will handle a podcast as a new podcast if this field changes) Samsung Podcasts will use podcast metadata accessed via the <link> field. Podcasters will need to ensure that artwork files are valid, reachable, and accurate. Samsung Podcasts may choose to cache artwork and metadata to optimize performance, but will not cache or re-host audio data. Unreachable or uninterpretable RSS feeds will be disabled by Samsung Podcasts. Please ensure that explicit words in Podcast titles and descriptions are censored in your metadata before submitting. Failure to censor explicit words could result in suspension of content from the platform. 4 Feed Requirements: Episode “Episode” is defined as an audio segment expressed through an audio file. Podcast episodes must: • Be uniquely defined by its <guid> field (Samsung Podcasts will handle an episode as new if the GUID is new or changed) • Be freely reachable, not requiring login, token, or similar information • Provide a supported audio file format (mp3, m4a, aac, wav, ogg) Samsung Podcasts will use episode metadata accessed via the <link> field and episode <guid> field. -

Supplement 211: Dicomweb Support for the Application/Zip Payload
5 Digital Imaging and Communications in Medicine (DICOM) Supplement 211: 10 DICOMweb Support for the application/zip Payload 15 20 Prepared by: Bill Wallace, Brad Genereaux DICOM Standards Committee, Working Group 27 1300 N. 17th Street Rosslyn, Virginia 22209 USA 25 Developed in accordance with work item WI 2018 -09 -C VERSION: 19 January 16, 2020 Table of Contents Scope and Field of Application ........................................................................................................................................ iii 30 Open Questions ....................................................................................................................................................... iii Closed Questions .................................................................................................................................................... iiii 8.6.1.3.1 File Extensions ................................................................................................................................. viv 8.6.1.3.2 BulkData URI ................................................................................................................................... viv 8.6.1.3.3 Logical Format ........................................................................................................................................ viv 35 8.6.1.3.4 Metadata Representations ...................................................................................................................... viv Scope and Field of Application -

Fast and Scalable Pattern Mining for Media-Type Focused Crawling
Provided by the author(s) and NUI Galway in accordance with publisher policies. Please cite the published version when available. Title Fast and Scalable Pattern Mining for Media-Type Focused Crawling Author(s) Umbrich, Jürgen; Karnstedt, Marcel; Harth, Andreas Publication Date 2009 Jürgen Umbrich, Marcel Karnstedt, Andreas Harth "Fast and Publication Scalable Pattern Mining for Media-Type Focused Crawling", Information KDML 2009: Knowledge Discovery, Data Mining, and Machine Learning, in conjunction with LWA 2009, 2009. Item record http://hdl.handle.net/10379/1121 Downloaded 2021-09-27T17:53:57Z Some rights reserved. For more information, please see the item record link above. Fast and Scalable Pattern Mining for Media-Type Focused Crawling∗ [experience paper] Jurgen¨ Umbrich and Marcel Karnstedt and Andreas Harthy Digital Enterprise Research Institute (DERI) National University of Ireland, Galway, Ireland fi[email protected] Abstract 1999]) wants to infer the topic of a target page before de- voting bandwidth to download it. Further, a page’s content Search engines targeting content other than hy- may be hidden in images. pertext documents require a crawler that discov- ers resources identifying files of certain media types. Na¨ıve crawling approaches do not guaran- A crawler for media type targeted search engines is fo- tee a sufficient supply of new URIs (Uniform Re- cused on the document formats (such as audio and video) source Identifiers) to visit; effective and scalable instead of the topic covered by the documents. For a scal- mechanisms for discovering and crawling tar- able media type focused crawler it is absolutely essential geted resources are needed. -

Reuters Institute Digital News Report 2020
Reuters Institute Digital News Report 2020 Reuters Institute Digital News Report 2020 Nic Newman with Richard Fletcher, Anne Schulz, Simge Andı, and Rasmus Kleis Nielsen Supported by Surveyed by © Reuters Institute for the Study of Journalism Reuters Institute for the Study of Journalism / Digital News Report 2020 4 Contents Foreword by Rasmus Kleis Nielsen 5 3.15 Netherlands 76 Methodology 6 3.16 Norway 77 Authorship and Research Acknowledgements 7 3.17 Poland 78 3.18 Portugal 79 SECTION 1 3.19 Romania 80 Executive Summary and Key Findings by Nic Newman 9 3.20 Slovakia 81 3.21 Spain 82 SECTION 2 3.22 Sweden 83 Further Analysis and International Comparison 33 3.23 Switzerland 84 2.1 How and Why People are Paying for Online News 34 3.24 Turkey 85 2.2 The Resurgence and Importance of Email Newsletters 38 AMERICAS 2.3 How Do People Want the Media to Cover Politics? 42 3.25 United States 88 2.4 Global Turmoil in the Neighbourhood: 3.26 Argentina 89 Problems Mount for Regional and Local News 47 3.27 Brazil 90 2.5 How People Access News about Climate Change 52 3.28 Canada 91 3.29 Chile 92 SECTION 3 3.30 Mexico 93 Country and Market Data 59 ASIA PACIFIC EUROPE 3.31 Australia 96 3.01 United Kingdom 62 3.32 Hong Kong 97 3.02 Austria 63 3.33 Japan 98 3.03 Belgium 64 3.34 Malaysia 99 3.04 Bulgaria 65 3.35 Philippines 100 3.05 Croatia 66 3.36 Singapore 101 3.06 Czech Republic 67 3.37 South Korea 102 3.07 Denmark 68 3.38 Taiwan 103 3.08 Finland 69 AFRICA 3.09 France 70 3.39 Kenya 106 3.10 Germany 71 3.40 South Africa 107 3.11 Greece 72 3.12 Hungary 73 SECTION 4 3.13 Ireland 74 References and Selected Publications 109 3.14 Italy 75 4 / 5 Foreword Professor Rasmus Kleis Nielsen Director, Reuters Institute for the Study of Journalism (RISJ) The coronavirus crisis is having a profound impact not just on Our main survey this year covered respondents in 40 markets, our health and our communities, but also on the news media. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

2016 Technical Guidelines for Digitizing Cultural Heritage Materials
September 2016 Technical Guidelines for Digitizing Cultural Heritage Materials Creation of Raster Image Files i Document Information Title Editor Technical Guidelines for Digitizing Cultural Heritage Materials: Thomas Rieger Creation of Raster Image Files Document Type Technical Guidelines Publication Date September 2016 Source Documents Title Editors Technical Guidelines for Digitizing Cultural Heritage Materials: Don Williams and Michael Creation of Raster Image Master Files Stelmach http://www.digitizationguidelines.gov/guidelines/FADGI_Still_Image- Tech_Guidelines_2010-08-24.pdf Document Type Technical Guidelines Publication Date August 2010 Title Author s Technical Guidelines for Digitizing Archival Records for Electronic Steven Puglia, Jeffrey Reed, and Access: Creation of Production Master Files – Raster Images Erin Rhodes http://www.archives.gov/preservation/technical/guidelines.pdf U.S. National Archives and Records Administration Document Type Technical Guidelines Publication Date June 2004 This work is available for worldwide use and reuse under CC0 1.0 Universal. ii Table of Contents INTRODUCTION ........................................................................................................................................... 7 SCOPE .......................................................................................................................................................... 7 THE FADGI STAR SYSTEM ....................................................................................................................... -
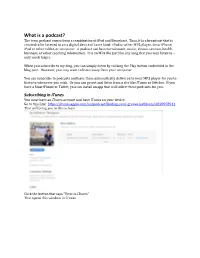
What Is a Podcast? the Term Podcast Comes from a Combination of Ipod and Broadcast
What is a podcast? The term podcast comes from a combination of iPod and Broadcast. Thus, it is a broadcast that is created to be listened to on a digital device of some kind: iPod or other MP3 player, SmartPhone, iPad or other tablet, or computer. A podcast can be entertainment, music, drama, sermon, health, business, or other coaching information. It is an MP3 file just like any song that you may listen to – only much larger. When you subscribe to my blog, you can simply listen by clicking the Play button embedded in the blog post. However, you may want to listen away from your computer. You can subscribe to podcasts and have them automatically delivered to your MP3 player for you to listen to whenever you wish. Or you can go out and listen from a site like iTunes or Stitcher. If you have a SmartPhone or Tablet, you can install an app that will collect these podcasts for you. Subscribing in iTunes You must have an iTunes account and have iTunes on your device. Go to this link: https://itunes.apple.com/us/podcast/finding-your-groove-kathleen/id829978911 That will bring you to this screen Click the button that says “View in iTunes” That opens this window in iTunes Click the Subscribe button just underneath the photo. To share this podcast with someone else, click the drop-down arrow just to the right of the Subscribe button. That will give you these share options: Tell a Friend, Share on Twitter, Share on Facebook, Copy Link (allows you to manually e-mail someone). -

A Nova Mídia Podcast: Um Estudo De Caso Do Programa Matando Robôs Gigantes
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO CENTRO DE FILOSOFIA E CIÊNCIAS HUMANAS JORNALISMO A NOVA MÍDIA PODCAST: UM ESTUDO DE CASO DO PROGRAMA MATANDO ROBÔS GIGANTES TÁBATA CRISTINA PIRES FLORES RIO DE JANEIRO 2014 UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO CENTRO DE FILOSOFIA E CIÊNCIAS HUMANAS JORNALISMO A NOVA MÍDIA PODCAST: UM ESTUDO DE CASO DO PROGRAMA MATANDO ROBÔS GIGANTES Monografia submetida à Banca de Graduação como requisito para obtenção do diploma de Comunicação Social/ Jornalismo. TÁBATA CRISTINA PIRES FLORES Orientador: Octávio Aragão RIO DE JANEIRO 2014 UNIVERSIDADE FEDERAL DO RIO DE JANEIRO ESCOLA DE COMUNICAÇÃO TERMO DE APROVAÇÃO A Comissão Examinadora, abaixo assinada, avalia a Monografia A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes, escrita por Tábata Flores. Monografia examinada: Rio de Janeiro, ___ de _______________ de 2014. Comissão Examinadora: Orientador: Prof. Octávio Aragão Doutor em Artes Visuais pela Escola de Belas Artes - UFRJ Departamento de Comunicação - UFRJ Prof. Fernando Mansur Doutor em Comunicação pela Escola de Comunicação - UFRJ Departamento de Comunicação - UFRJ Lúcio Luiz Corrêa da Silva Doutorando em Educação pela Universidade Estácio de Sá Programa de Pós-Graduação em Educação (Tecnologias de Informação e Comunicação nos Processos Educacionais) – Universidade Estácio de Sá RIO DE JANEIRO 2014 FICHA CATALOGRÁFICA FLORES, Tábata. A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes. Rio de Janeiro, 2014. Monografia (Graduação em Comunicação Social/Jornalismo) – Universidade Federal do Rio de Janeiro – UFRJ, Escola de Comunicação – ECO. Orientador: Octávio Aragão Orientadora: Raquel Paiva de Araújo Soares FLORES, Tábata. A nova mídia podcast: um estudo de caso do programa Matando Robôs Gigantes. -

Media Type Application/Vnd.Oracle.Resource+Json
New Media Type for Oracle REST Services to Support Specialized Resource Types O R A C L E WHITEPAPER | M A R C H 2 0 1 5 Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. Contents Introduction 3 Conventions and Terminology 3 Core terminology 3 Singular Resource 4 Collection Resource 8 Exception Detail Resource 13 Status Resource 14 Query Description Resource 15 create-form Resource 16 edit-form Resource 17 JSON Schema 18 IANA Considerations 28 References 28 Change Log 28 2 | ORACLE WHITEPAPER: NEW MEDIA TYPE FOR ORACLE REST SERVICES TO SUPPORT SPECIALIZED RESOURCE TYPES Introduction This document defines a new media type, application/vnd.oracle.resource+json, which can be used by REST services to support the specialized resource types defined in the following table. Resource Type Description Singular Single entity resource, such as an employee or a purchase order. For more information, see “Singular Resource.” Collection List of items, such as employees or purchase orders. See “Collection Resource.” Exception Detail Detailed information about a failed request. See “Exception Detail Resource.” Status Status of a long running job. See “Status Resource.” Query description Query syntax description used by client to build the "q" query parameter. -

Social Media Solution Guide
Social Media Solution Guide Deploy Social Messaging Server with an RSS Channel 9/30/2021 Deploy Social Messaging Server with an RSS Channel Deploy Social Messaging Server with an RSS Channel Contents • 1 Deploy Social Messaging Server with an RSS Channel • 1.1 Prepare the RSS Channel • 1.2 Configure the Options • 1.3 Interaction Attributes • 1.4 Next Steps Social Media Solution Guide 2 Deploy Social Messaging Server with an RSS Channel Warning The APIs and other features of social media sites may change with little warning. The information provided on this page was correct at the time of publication (22 February 2013). For an RSS channel, you need two installation packages: Social Messaging Server and Genesys Driver for Use with RSS. The Driver adds RSS-specific features to Social Messaging Server and does not require its own Application object in the Configuration Server database. You can also create a Custom Media Channel Driver. Important Unlike some other eServices components, Social Messaging Server does not require Java Environment and Libraries for eServices and UCS. Prepare the RSS Channel 1. Deploy Social Messaging Server. 2. Run the installation for Genesys Driver for Use with RSS, selecting the desired Social Messaging Server object: Social Media Solution Guide 3 Deploy Social Messaging Server with an RSS Channel Select your Social Messaging Server Object 3. Locate the driver-for-rss-options.cfg configuration file in the \<Social Messaging Server application>\media-channel-drivers\channel-rss directory. 4. In Configuration Manager, open your Social Messaging Server Application, go to the Options tab, and import driver-for-rss-options.cfg.