Wrangling Messy CSV Files by Detecting Row and Type Patterns
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Architecture of the World Wide Web, First Edition Editor's Draft 14 October 2004
Architecture of the World Wide Web, First Edition Editor's Draft 14 October 2004 This version: http://www.w3.org/2001/tag/2004/webarch-20041014/ Latest editor's draft: http://www.w3.org/2001/tag/webarch/ Previous version: http://www.w3.org/2001/tag/2004/webarch-20040928/ Latest TR version: http://www.w3.org/TR/webarch/ Editors: Ian Jacobs, W3C Norman Walsh, Sun Microsystems, Inc. Authors: See acknowledgments (§8, pg. 42). Copyright © 2002-2004 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Your interactions with this site are in accordance with our public and Member privacy statements. Abstract The World Wide Web is an information space of interrelated resources. This information space is the basis of, and is shared by, a number of information systems. In each of these systems, people and software retrieve, create, display, analyze, relate, and reason about resources. The World Wide Web uses relatively simple technologies with sufficient scalability, efficiency and utility that they have resulted in a remarkable information space of interrelated resources, growing across languages, cultures, and media. In an effort to preserve these properties of the information space as the technologies evolve, this architecture document discusses the core design components of the Web. They are identification of resources, representation of resource state, and the protocols that support the interaction between agents and resources in the space. We relate core design components, constraints, and good practices to the principles and properties they support. Status of this document This section describes the status of this document at the time of its publication. -

Supplement 211: Dicomweb Support for the Application/Zip Payload
5 Digital Imaging and Communications in Medicine (DICOM) Supplement 211: 10 DICOMweb Support for the application/zip Payload 15 20 Prepared by: Bill Wallace, Brad Genereaux DICOM Standards Committee, Working Group 27 1300 N. 17th Street Rosslyn, Virginia 22209 USA 25 Developed in accordance with work item WI 2018 -09 -C VERSION: 19 January 16, 2020 Table of Contents Scope and Field of Application ........................................................................................................................................ iii 30 Open Questions ....................................................................................................................................................... iii Closed Questions .................................................................................................................................................... iiii 8.6.1.3.1 File Extensions ................................................................................................................................. viv 8.6.1.3.2 BulkData URI ................................................................................................................................... viv 8.6.1.3.3 Logical Format ........................................................................................................................................ viv 35 8.6.1.3.4 Metadata Representations ...................................................................................................................... viv Scope and Field of Application -

Fast and Scalable Pattern Mining for Media-Type Focused Crawling
Provided by the author(s) and NUI Galway in accordance with publisher policies. Please cite the published version when available. Title Fast and Scalable Pattern Mining for Media-Type Focused Crawling Author(s) Umbrich, Jürgen; Karnstedt, Marcel; Harth, Andreas Publication Date 2009 Jürgen Umbrich, Marcel Karnstedt, Andreas Harth "Fast and Publication Scalable Pattern Mining for Media-Type Focused Crawling", Information KDML 2009: Knowledge Discovery, Data Mining, and Machine Learning, in conjunction with LWA 2009, 2009. Item record http://hdl.handle.net/10379/1121 Downloaded 2021-09-27T17:53:57Z Some rights reserved. For more information, please see the item record link above. Fast and Scalable Pattern Mining for Media-Type Focused Crawling∗ [experience paper] Jurgen¨ Umbrich and Marcel Karnstedt and Andreas Harthy Digital Enterprise Research Institute (DERI) National University of Ireland, Galway, Ireland fi[email protected] Abstract 1999]) wants to infer the topic of a target page before de- voting bandwidth to download it. Further, a page’s content Search engines targeting content other than hy- may be hidden in images. pertext documents require a crawler that discov- ers resources identifying files of certain media types. Na¨ıve crawling approaches do not guaran- A crawler for media type targeted search engines is fo- tee a sufficient supply of new URIs (Uniform Re- cused on the document formats (such as audio and video) source Identifiers) to visit; effective and scalable instead of the topic covered by the documents. For a scal- mechanisms for discovering and crawling tar- able media type focused crawler it is absolutely essential geted resources are needed. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

2016 Technical Guidelines for Digitizing Cultural Heritage Materials
September 2016 Technical Guidelines for Digitizing Cultural Heritage Materials Creation of Raster Image Files i Document Information Title Editor Technical Guidelines for Digitizing Cultural Heritage Materials: Thomas Rieger Creation of Raster Image Files Document Type Technical Guidelines Publication Date September 2016 Source Documents Title Editors Technical Guidelines for Digitizing Cultural Heritage Materials: Don Williams and Michael Creation of Raster Image Master Files Stelmach http://www.digitizationguidelines.gov/guidelines/FADGI_Still_Image- Tech_Guidelines_2010-08-24.pdf Document Type Technical Guidelines Publication Date August 2010 Title Author s Technical Guidelines for Digitizing Archival Records for Electronic Steven Puglia, Jeffrey Reed, and Access: Creation of Production Master Files – Raster Images Erin Rhodes http://www.archives.gov/preservation/technical/guidelines.pdf U.S. National Archives and Records Administration Document Type Technical Guidelines Publication Date June 2004 This work is available for worldwide use and reuse under CC0 1.0 Universal. ii Table of Contents INTRODUCTION ........................................................................................................................................... 7 SCOPE .......................................................................................................................................................... 7 THE FADGI STAR SYSTEM ....................................................................................................................... -

Media Type Application/Vnd.Oracle.Resource+Json
New Media Type for Oracle REST Services to Support Specialized Resource Types O R A C L E WHITEPAPER | M A R C H 2 0 1 5 Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. Contents Introduction 3 Conventions and Terminology 3 Core terminology 3 Singular Resource 4 Collection Resource 8 Exception Detail Resource 13 Status Resource 14 Query Description Resource 15 create-form Resource 16 edit-form Resource 17 JSON Schema 18 IANA Considerations 28 References 28 Change Log 28 2 | ORACLE WHITEPAPER: NEW MEDIA TYPE FOR ORACLE REST SERVICES TO SUPPORT SPECIALIZED RESOURCE TYPES Introduction This document defines a new media type, application/vnd.oracle.resource+json, which can be used by REST services to support the specialized resource types defined in the following table. Resource Type Description Singular Single entity resource, such as an employee or a purchase order. For more information, see “Singular Resource.” Collection List of items, such as employees or purchase orders. See “Collection Resource.” Exception Detail Detailed information about a failed request. See “Exception Detail Resource.” Status Status of a long running job. See “Status Resource.” Query description Query syntax description used by client to build the "q" query parameter. -

Social Media Solution Guide
Social Media Solution Guide Deploy Social Messaging Server with an RSS Channel 9/30/2021 Deploy Social Messaging Server with an RSS Channel Deploy Social Messaging Server with an RSS Channel Contents • 1 Deploy Social Messaging Server with an RSS Channel • 1.1 Prepare the RSS Channel • 1.2 Configure the Options • 1.3 Interaction Attributes • 1.4 Next Steps Social Media Solution Guide 2 Deploy Social Messaging Server with an RSS Channel Warning The APIs and other features of social media sites may change with little warning. The information provided on this page was correct at the time of publication (22 February 2013). For an RSS channel, you need two installation packages: Social Messaging Server and Genesys Driver for Use with RSS. The Driver adds RSS-specific features to Social Messaging Server and does not require its own Application object in the Configuration Server database. You can also create a Custom Media Channel Driver. Important Unlike some other eServices components, Social Messaging Server does not require Java Environment and Libraries for eServices and UCS. Prepare the RSS Channel 1. Deploy Social Messaging Server. 2. Run the installation for Genesys Driver for Use with RSS, selecting the desired Social Messaging Server object: Social Media Solution Guide 3 Deploy Social Messaging Server with an RSS Channel Select your Social Messaging Server Object 3. Locate the driver-for-rss-options.cfg configuration file in the \<Social Messaging Server application>\media-channel-drivers\channel-rss directory. 4. In Configuration Manager, open your Social Messaging Server Application, go to the Options tab, and import driver-for-rss-options.cfg. -

Client-Side Web Technologies
Client-Side Web Technologies Introduction to HTTP MIME • Multipurpose Internet Mail Extensions • Introduced in 1996 • Created to extend email to http://www.maran.com/dictionary/m/mime/image.gif support: • Text in character sets other than ASCII • Non-text content • Multi-part message Bodies • Header info in non-ASCII character sets MIME Header Fields • MIME-Version • Declares version of message Body format standard in use • Content-Type • DescriBes the data contained in the Body • Content-Disposition • DescriBes how a Body part should Be presented (e.g. inline or attachment) • There are others But we won’t discuss them… MIME Content-Type • DescriBes the data in the Body of a MIME entity • Consists of: • Top level media type • Declares the general type of data • SuBtype • Specifies a specific format for that type of data • Parameters that modify the suBtype (optional) • Due to expanded use, now known as Internet Media Types • IANA maintains the list of registered Media Types: • http://www.iana.org/assignments/media-types Top-Level Media Types • Text • Textual information • Image • Image data • Audio • Audio data • Video • Video data • Application • Some other kind of data (typically Binary, to Be processed By some application) • Multipart • Data consisting of multiple entities of independent data types • SuBtypes such as mixed, alternative, byteranges, and form-data (for HTML forms) MIME Message Examples From: John Doe <[email protected]> Subject: Hello MIME-Version: 1.0 Content-Type: text/plain; This is a message in MIME format. From: -

Supplement 174: Restful Rendering Page 1
9 September 2015 Supplement 174: Restful Rendering Page 1 5 10 Digital Imaging and Communications in Medicine (DICOM) Supplement 174: RESTful Rendering 15 20 DICOM Standards Committee, Working Group 27: Web Technologies 1300 N. 17th Street Suite 900 Rosslyn, Virginia 22209 USA VERSION: Final Text Developed in accordance with work item 2014-04-A. 25 9 September 2015 Supplement 174: Restful Rendering Page 2 Table of Contents 1 Scope and Field of Application 3 2 Normative References 3 4 Terms and Definitions 3 30 6 Data Communication Requirements 4 6.1.1 Media Types 4 6.1.1.1 Multipart Media Types 5 6.1.1.2 DICOM Resource Categories 5 6.1.1.3 Rendered Media Types 6 35 6.1.1.4 Acceptable Media Types 7 6.1.1.5 Accept Query Parameter 7 6.1.1.6 Accept Header Field 8 6.1.1.7 Selected Media Type 8 6.1.2 Character Sets 9 40 6.1.2.1 Acceptable Character Sets 10 6.1.2.2 Character Set Query Parameter 10 6.1.2.3 Accept-Charset Header Field 10 6.1.2.4 Selected Character Set 10 6.2.2 List of Media Types Supported Acceptable in the Response 11 45 6.2.2.1 Query Parameters 11 6.2.2.1.1 Accept Query Parameter 11 6.2.2.1.2 Character Set Query Parameter 11 6.2.2.2 Header Fields 12 6.2.2.2.1 Accept 12 50 6.2.2.2.2 Accept-Charset 12 6.5 WADO-RS Request/Response 12 6.5.8 RS Retrieve Rendered Transaction 13 6.5.8.1 Request 13 6.5.8.1.1 Target Resources 13 55 6.5.8.1.2 Query Parameters 14 6.5.8.1.3 Header Fields 16 6.5.8.1.4 Payload 16 6.5.8.2 Behavior 16 6.5.8.2.1 Presentation State Instance 17 60 6.5.8.3 Response 17 6.5.8.3.1 Status Codes 18 6.5.8.3.2 Header Fields 18 6.5.8.3.3 Payload 18 6.5.8.4 Media Types 18 65 8.1.5 MIME Acceptable Media Types of the Response 18 8.1.6 Charset of the Response 19 Annex D IANA Character Set Mapping (Informative) 20 9 September 2015 Supplement 174: Restful Rendering Page 3 70 1 Scope and Field of Application This supplement defines rendering functionality for Restful Services (RS) that is largely equivalent to the functionality in the URI and WS services. -

MIME Media Types for GML
Open Geospatial Consortium Inc. Date: 2010-02-08 Reference number of this OGC® document: OGC 09-144r1 Version: 1.0 Category: OGC® TC Policies and Procedures Editor: Clemens Portele Technical Committee Policies and Procedures: MIME Media Types for GML Copyright © 2010. Open Geospatial Consortium, Inc. To obtain additional rights of use, visit http://www.opengeospatial.org/legal/ Warning This document is a Policies and Procedures Document. It is subject to change based on membership requirements. This document is an official position of the OGC membership. Document type: OpenGIS® Policy Document Document subtype: NA Document stage: Proposed version 1.0 Document language: English Table of Contents 1 Scope ............................................................................................................................. 6 2 The GML MIME Type specification ............................................................................ 6 2.1 General ................................................................................................................... 6 2.2 Encoding considerations ........................................................................................ 6 2.3 Security considerations .......................................................................................... 6 2.4 Interoperability considerations ............................................................................... 7 2.5 Published standard ................................................................................................ -

Digital Messaging Server Guide
Digital Messaging Server Guide Deploy Digital Messaging Server with an RSS Channel 9/25/2021 Contents • 1 Deploy Digital Messaging Server with an RSS Channel • 1.1 Prepare the RSS Channel • 1.2 Configure the Options • 1.3 Interaction Attributes • 1.4 Next Steps Digital Messaging Server Guide 2 Deploy Digital Messaging Server with an RSS Channel Deploy Digital Messaging Server with an RSS Channel Warning The APIs and other features of social media sites may change with little warning. The information provided on this page was correct at the time of publication (Feb. 22, 2013). For an RSS channel, you need two installation packages: • Digital Messaging Server • Genesys Driver for Use with RSS The Driver adds RSS-specific features to Digital Messaging Server and does not require its own Application object in the Configuration Server database. You can also create a Custom Media Channel Driver. Important Unlike some other eServices components, Digital Messaging Server does not require Java Environment and Libraries for eServices and UCS. Prepare the RSS Channel 1. Deploy Digital Messaging Server. 2. Run the installation for Genesys Driver for Use with RSS, selecting the desired Digital Messaging Server object. 3. Locate the driver-for-rss-options.cfg configuration file in the \<Digital Messaging Server application>\media- channel-drivers\channel-rss directory. 4. In Configuration Manager, open your Digital Messaging Server Application, go to the Options tab, and import driver- for-rss-options.cfg. Configure the Options Set the following options: -
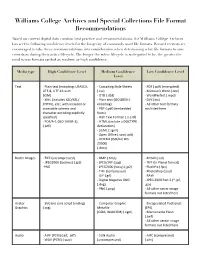
Williams College Archives and Special Collections File Format Recommendations
Williams College Archives and Special Collections File Format Recommendations Based on current digital data curation best practice and recommendations, the Williams College Archives has set the following confidence levels for the longevity of commonly used file formats. Record creators are encouraged to take these recommendations into consideration when determining what file formats to save records as during their active lifecycle. The longer the active lifecycle is anticipated to be, the greater the need to use formats ranked as medium or high confidence. Media type High Confidence Level Medium Confidence Low Confidence Level Level Text - Plain text (encoding: USASCII, - Cascading Style Sheets - PDF (.pdf) (encrypted) UTF-8, UTF-16 with (.css) - Microsoft Word (.doc) BOM) - DTD (.dtd) - WordPerfect (.wpd) - XML (includes XSD/XSL/ - Plain text (ISO 8859-1 - DVI (.dvi) XHTML, etc.; with included or encoding) - All other text forMats accessible schema and - PDF (.pdf) (eMbedded not listed here character encoding explicitly fonts) specified) - Rich Text ForMat 1.x (.rtf) - PDF/A-1 (ISO 19005-1) - HTML (include a DOCTYPE (.pdf) declaration) - SGML (.sgMl) - Open Office (.sxw/.odt) - OOXML (ISO/IEC DIS 29500) (.docx) Raster Images - TIFF (uncoMpressed) - BMP (.bMp) - MrSID (.sid) - JPEG2000 (lossless) (.jp2) - JPEG/JFIF (.jpg) - TIFF (in Planar forMat) -PNG - JPEG2000 (lossy) (.jp2) - FlashPix (.fpx) - TIFF (coMpressed) - PhotoShop (.psd) - GIF (.gif) - RAW - Digital Negative DNG - JPEG 2000 Part 2 (*.jpf, (.dng) .jpx) - PNG (.png) - All other